
第一次个人编程作业
一、作业声明
这个作业属于哪个课程 | 信安1912-软件工程(广东工业大学 - 计算机学院)
--|--|--
这个作业要求在那里 | 个人项目作业
这个作业的目标 | 论文查重:实现论文查重算法+PSP表格+使用Profiler性能分析)
- 作业github链接
https://github.com/litternannan/litternannan
| PSP2.1 | Personal Software Process Stages | 预计耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 5 |
| Estimate | 估计这个任务需要多少时间 | 10 | 5 |
| Development | 开发 | 180 | 200 |
| Analysis | 需求分析(包括学习新技术) | 180 | 180 |
| Design Spec | 生成设计文档 | 30 | 50 |
| Design Review | 设计复审 | 15 | 25 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 30 | 45 |
| Design | 具体设计 | 30 | 45 |
| Coding | 具体编码 | 180 | 120 |
| Code Review | 代码复审 | 30 | 15 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 25 |
| Reporting | 报告 | 30 | 45 |
| Test Reporting | 测试报告 | 30 | 10 |
| Size Measurement | 计算工作量 | 15 | 5 |
| Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 15 | 25 |
| 合计 | 845 | 800 |
二、计算模块接口的设计与实现过程
- jieba包
中文文本是通过分词获得单个的词语,它的原理是利用一个中文词库,确定汉字之间的关联概率,在这一次项目中,我使用全模式,把文字中所有可能的词语都扫描出来。
- cosine_similarity包
余弦距离使用两个向量夹角的余弦值作为衡量两个个体间差异的大小。相比欧氏距离,余弦距离更加注重两个向量在方向上的差异。余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,夹角等于0,即两个向量相等,叫"余弦相似性"。
我们在设计查重的功能时,使用余弦相似度,通过分词,列词,计算词频,得到词频向量。
所以我处理文本相似度的流程是:
(1)找出两篇文章的关键词;
(2)每篇文章各取出若干个关键词,合并成一个集合,计算每篇文章对于这个集合中的词的词频
(3)生成两篇文章各自的词频向量;
(4)计算两个向量的余弦相似度,值越大就表示越相似。
- 实现过程
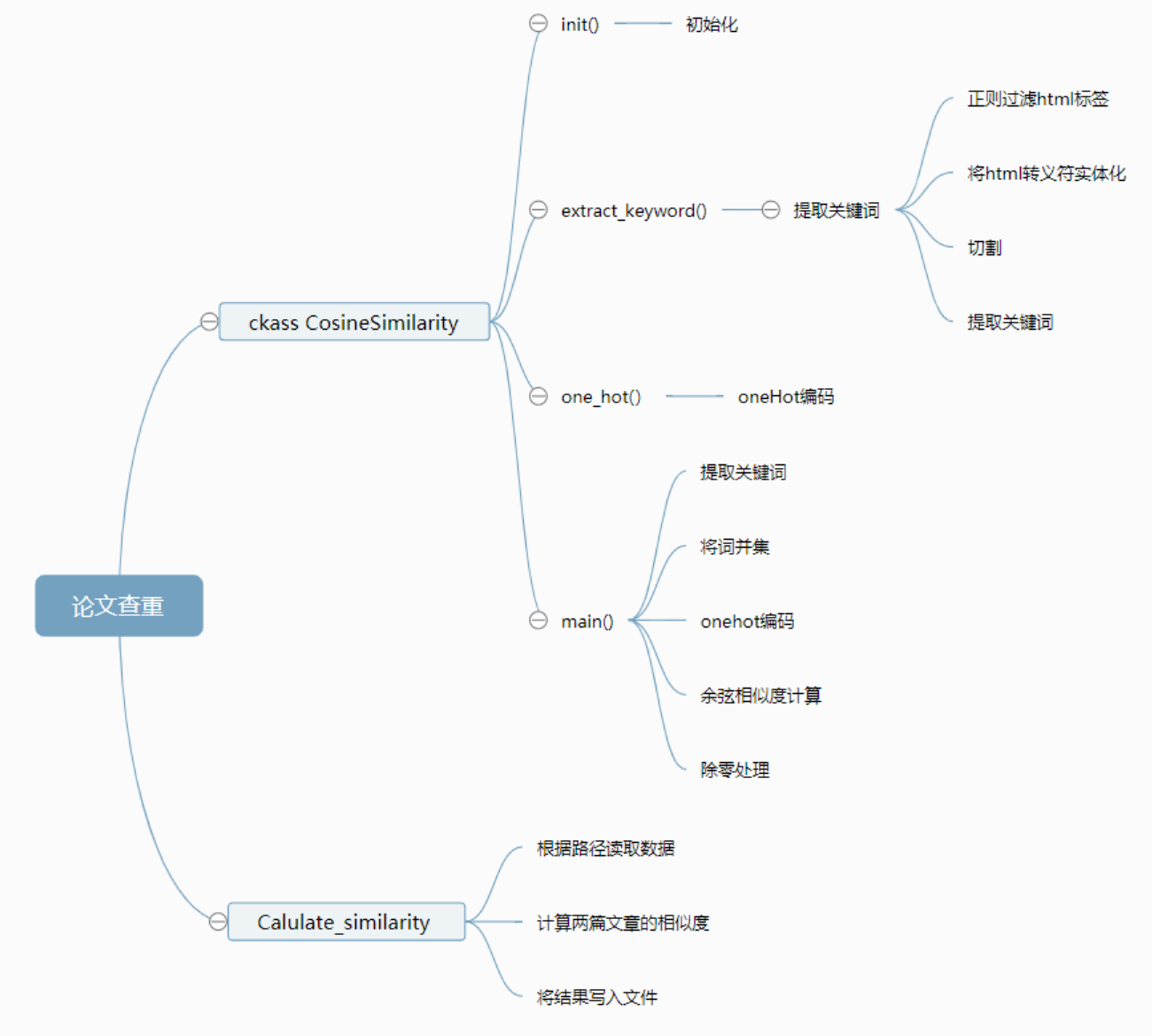
三、计算模块接口部分的性能改进
- 一开始在对词的编码中,我选择的是Index编码,但是通过Index编码得到得词向量,在调用模型得时候需要时间长达8秒,并且在提取关键词中报错。如下图:
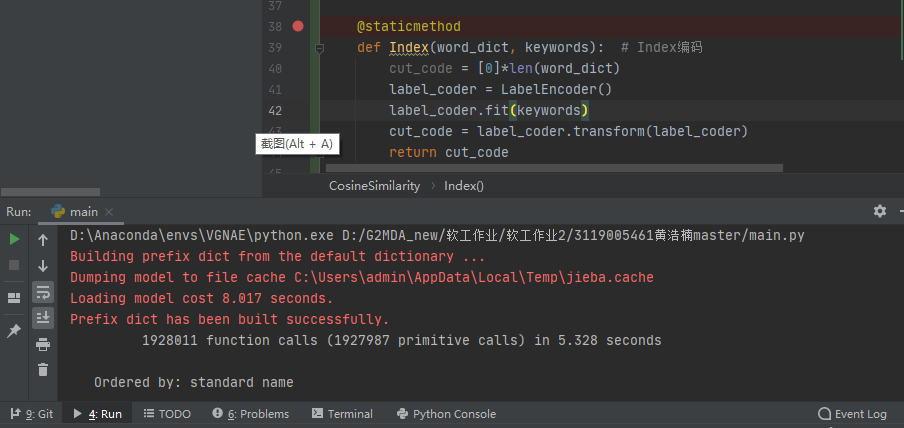
-
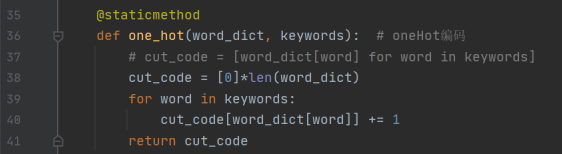
经过查阅资料学习到,Index编码适用于不连续的文本编码。而我们的测试文本是连续文本,最后我采用了独热编码oneHot,将离散特征的取值扩展到了欧式空间,离散特征的某个取值就对应欧式空间的某个点。
-
将Index编码改成oneHot编码,编程如下:
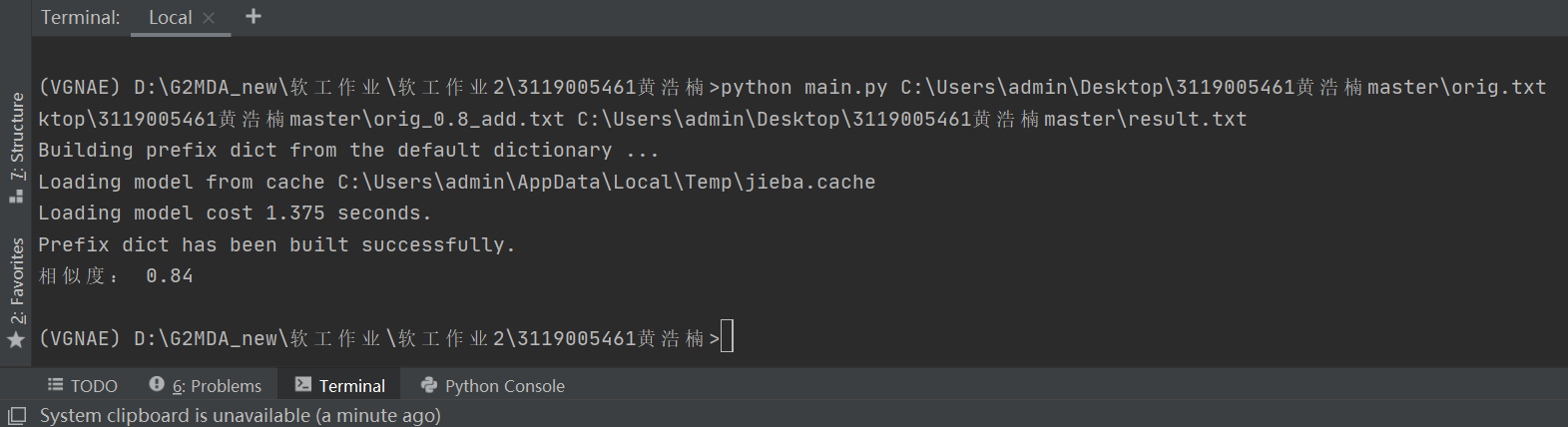
- 测试结果如下,运行时间和运行结果符合预期。
四、计算模块部分单元测试
- 运行程序,采用profile的模块进行单元测试
运行结果如图:
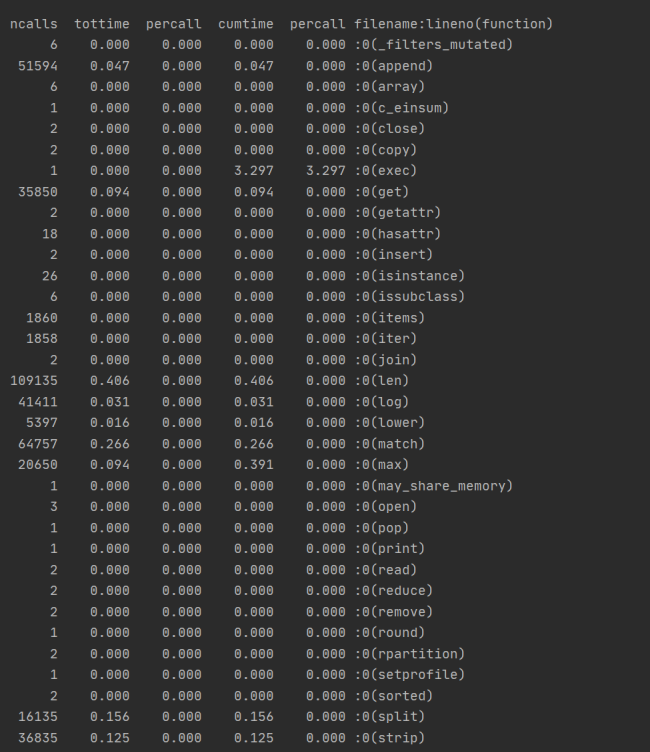
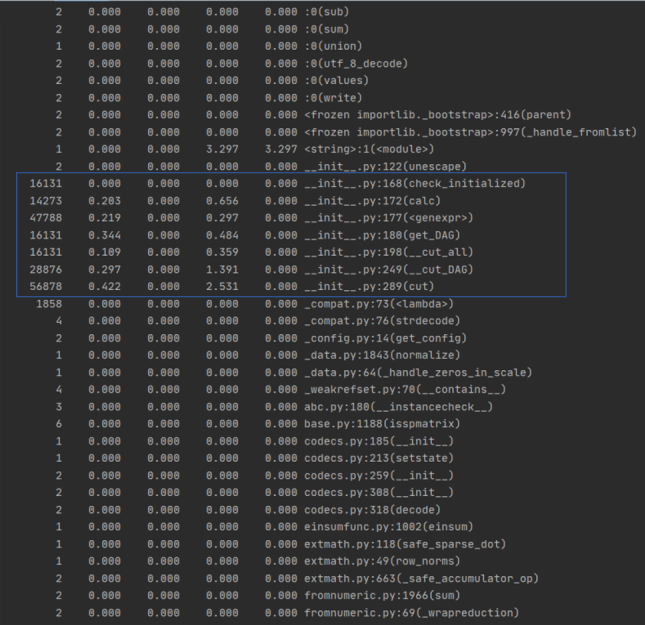
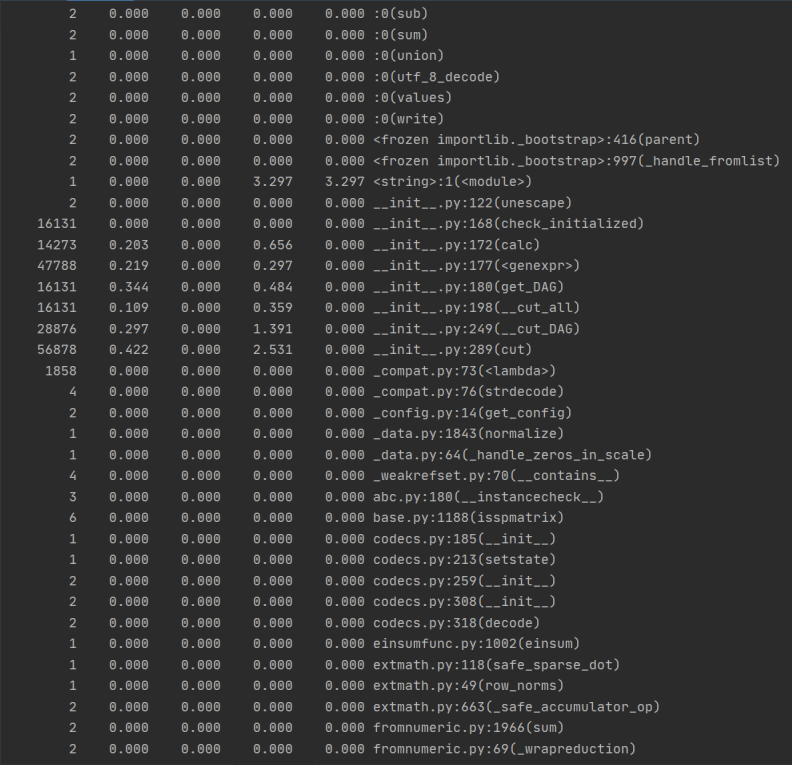
由times可得运行时间最长的部分用于文本的分词,构建DAG这一模块,以及列词,计算词频,构建词向量。
五、计算模块部分单元测试展
-
代码提交
-
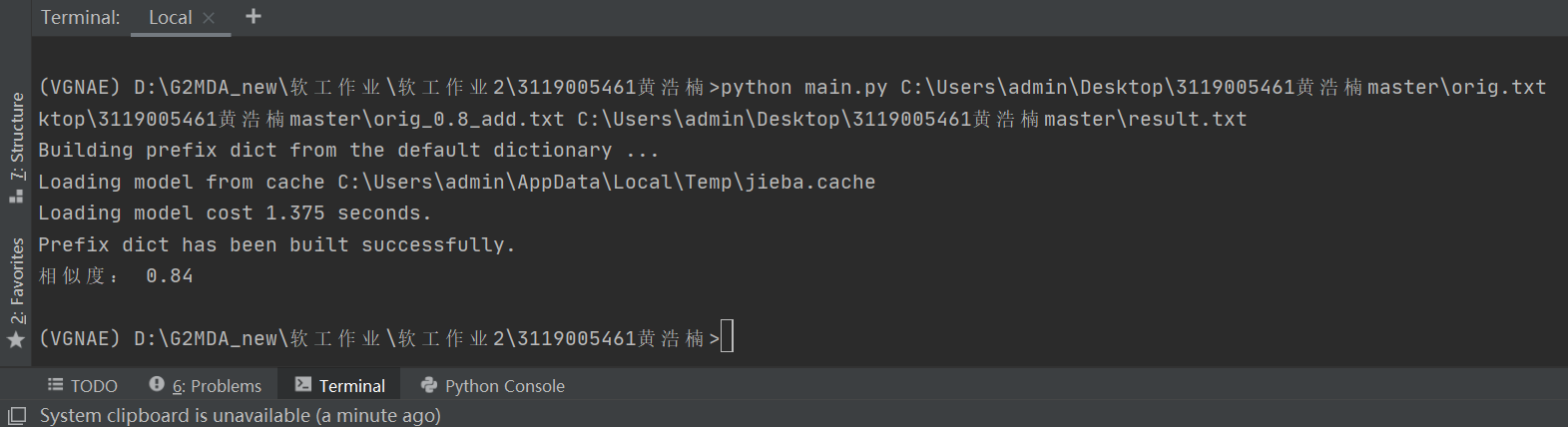
原文本与测试文本orig_0.8_add.txt:相似度为0.84,符合预期
- 原文本与测试文本orig_0.8_del.txt:相似度为0.73,符合预期

-
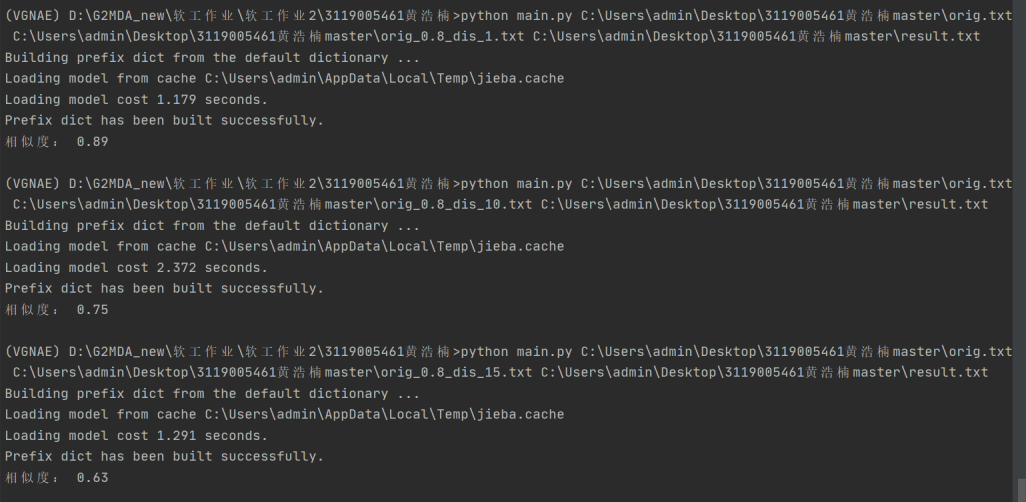
原文本分别与测试文本orig_0.8_dis_1.txt, orig_0.8_dis_10.txt, orig_0.8_dis_15.txt进行实验,
相似度分别是:0.89,0.75,0.63,均符合预期
六、计算模块部分异常处理说明
- 当测试文档为空白文档时,本程序仍能得出文本相似度为:0.0

七、总结
由于之前自学过NLP的相关内容,于是看到项目题目之后自然选择了python来处理。python的好处在于本身有很强大的库功能,大大减少代码量。但是除此之外,在github上传代码的学习,profile做单元测试的学习也投入了不少的时间,通过本次学习,我熟悉了开发一个项目需要做好规划,确保自己按照进度进行,除此之外,github上的代码管理也尤为重要,可以让我们在代码出错时回溯,更方便地管理自己的代码,知道自己每一次上交更新了什么功能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号