
1、概述
- 场景
在数据开发中,由于各程序员风格不一、部分程序员代码太烂、代码注释过少等原因,导致代码维护时困难重重
同事A请假去生娃,此时Ta的代码出了问题需要同事B去修改,但由于代码太烂,同事B改不动 - 代码评审:通过 阅读代码 来 检查代码质量
目的:降低代码维护成本 - 使用代码评审自动化脚本(Python3实现),可提高代码评审的效率
2、代码规范
以下规范按照高危、强制、建议3个级别进行标注,优先级从高到低
2.1、通用代码规范
- 注释
【建议】中文注释≥1行
【建议】注释不用太多,代码即注释 - 命名规范
【建议】用纯英文
【建议】查词典用英文全称;当 名称过长 或 关键字冲突 时,可使用缩写
【建议】变量、参数、类使用[形容词+]名词
【建议】方法、函数使用动词[+名词]
【强制】禁止数字开头
【强制】禁止拼音和英文混用
【建议】不使用保留字
| 时间命名规范 | 【强制】格式 | 示例 | 【强制】变量名 |
|---|---|---|---|
| 年 | yyyy |
2022 |
|
| 年月 | yyyy-mm |
2021-01 |
|
| 年月日 | yyyy-mm-dd |
2020-02-02 |
ymd |
| 季度 | yyyyQq |
2021Q4、2022Q1 |
|
| 时分秒 | hh:mm:ss |
08:00:00 |
|
| 年月日时分秒 | yyyy-mm-dd hh:mm:ss |
2022-02-01 08:00:00 |
| 常见缩写 | 全称 | 中文 | 常见缩写 | 全称 | 中文 |
|---|---|---|---|---|---|
fn |
function | 函数 | ymd |
Year Month Day | 日期 |
txt |
textfile | 文本文件 | cnt |
count | v. 计数;n. 总数 |
obj |
object | 对象 | num |
number | 数字;号码 |
ls |
list | n. 列表;v. 列清单 | lvl |
level | 等级 |
lib |
library | 软件库 | dw |
data warehouse | 数据仓库 |
str |
string | 字符串 | bak |
backup | 备份 |
prob |
probability | 概率 | sku |
Stock Keeping Unit | 库存单位 |
conf |
configuration file | 配置文件 | idx |
index file | 索引文件 |
calc |
calculation | n. 计算 | uv |
unique visitor | 独立访客 |
regexp |
regular expression | 正则表达式 | pv |
page view | 页面浏览量 |
app |
application | 应用程序 | ai |
Artificial Intelligence | 人工智能 |
dept |
department | 部;科;处 | addr |
address | 地址 |
db |
database | 数据库 | pwd |
password | 密码 |
mkt |
market | 市场 | biz |
business | 商业 |
- 括号
【强制】左括号前不换行
【强制】当行过长时,左括号后换行,换行后要缩进
【强制】当右括号后还没结束时,不允许换行
{
"timestamp": 1585744376001,
"page": {
"page_id": "页面ID",
"last_page_id": "上个页面ID",
"page_type": "登录页"
},
"actions": [{
"action": "拖动",
"item": "拼图验证码",
"timestamp": 1585744376605
}, {
"action": "点击",
"item": "登录键",
"timestamp": 1585744377778
}]
}
- 其它
【建议】代码中不得出现生产环境的明文密码
【建议】单行代码不可太长(例外:长URL、长import)
【建议】项目要有说明文档,名为README.md
2.2、配置文件和传参规范
- 配置文件通常用于存储数据库连接参数
- 通常是时间传参
https://yellow520.blog.csdn.net/article/details/122088401
2.3、Python代码规范
Python代码规范 继承 通用代码规范
| 命名规范 | 说明 | 示例 |
|---|---|---|
| 变量、方法、函数、包 | 【强制】全小写,下划线分隔单词 | function_name |
| 类中的方法和函数(不被外部直接调用的) | 【强制】双下划线开头,全小写,下划线分隔单词 | __method_name |
| 常量 | 【强制】全大写 和 下划线 | PUBLIC_CONSTANT |
| 模块 | 【强制】全小写,下划线分隔单词 | module_name.py |
| 类 | 【强制】每个单词首字母大写 | ClassName |
| 项目名 | 【建议】每个单词首字母大写 | ProjectName |
| 注释规范 | 注释建议 |
|---|---|
| 模块注释、函数注释、类注释、方法注释… | 【强制】三双引号,注释的前面没有空行 |
| 单行代码和多行代码 的 单行注释 | 【强制】井号 |
| 单行代码后 的 单行注释 | 【强制】两个空格+井号 |
| 多行注释(单行注释太长时,建议写成多行) | 【建议】井号(连续行) |
| 其它规范 | 说明 |
|---|---|
| 缩进、空行、空格 | 【强制】Tab缩进量:4个空格 【建议】把Pycharm更到最新,用 Ctrl+Alt+l来规范代码 |
| 字符串 | 【建议】单行优先用单引号 【建议】单行子字符串里有单引号时用双引号,如: sql = "SELECT '2021-12-02'"【强制】多行用三单引号 【建议】不使用三双引号 |
"""
模块注释
"""
from time import time
# 多行代码的
# 多行注释(一行写不下的时候才写多行)
NUM = 5
CNT = 1000
def function1():
"""函数注释"""
return time() # 单行代码后 的 单行注释
class ClassName:
"""类注释"""
@classmethod
def method4(cls):
"""方法注释"""
if __name__ == '__main__':
print(__doc__)
print(function1.__doc__)
print(ClassName.__doc__)
print(ClassName.method4.__doc__)2.4、SQL代码规范
SQL代码规范 继承 通用代码规范
- 命名
【强制】库、表、字段、视图:全小写,下划线分隔单词
【强制】视图:view_作为前缀
【强制】临时表:temp_作为前缀
【强制】备份表:bak_作为前缀
【建议】库名和表名不使用复数名词,正例user_info,负例users_info和user_informations - 建表
【强制】创建 表和字段 要添加中文注释
【强制】涉及外键关联的字段,须添加外键注释
【强制】建表时,主键字段排在所有字段的第一行 - 查询
【建议】关键字:全大写
【建议】使用别称时不要省略AS
【强制】注释用--(双减号+空格,MySQL和HIVE都支持)
【建议】子查询用WITH AS,每个子查询都附带中文注释
-- 整个查询的注释
WITH
-- 子查询注释
t1 AS (
SELECT a FROM t0
),
-- 子查询注释
t2 AS (
SELECT a FROM t1
)
-- 查询注释
SELECT a FROM t2;- 换行和缩进
【建议】缩进量:4空格或2空格
【建议】单行过长时,按允许换行的关键字换行
| 【强制】关键字前后是否允许换行 | 前 | 后 |
|---|---|---|
AS |
不允许 | |
SELECT |
允许 | |
FROM |
允许 | 不允许 |
[LEFT/RIGHT/...] JOIN |
允许 | 不允许 |
ON |
不允许 | |
WHERE |
允许 | 不允许 |
GROUP BY |
允许 | |
HAVING |
允许 | |
ORDER BY |
允许 | |
LIMIT |
允许 | 不允许 |
SELECT t1.f1
,t2.f2
,t2.f3
FROM t1
LEFT JOIN t2 ON t1.f1=t2.f4
WHERE t2.f1>4
AND t2.f2<5
AND t2.f3<>1
ORDER BY t1.f1;- 【建议】代码头部添加 日期、需求、业务、作者 等信息
-- 名称:A9527
-- 所属业务:A
-- 需求文档:链接
-- 创建者:小基基
-- 创建日期: 2021-10-24
-- 修改日志(修改日期,修改人,修改内容):
-- 2021-12-12,小黄,添加xxx指标2.4.1、MySQL代码规范(待完善)
MySQL代码规范 继承 SQL代码规范
-
库、表、字段
【建议】建库时显式指定字符集utf8或utf8mb4
示例:CREATE DATABASE db1 DEFAULT CHARACTER SET utf8mb4; -
表、字段
【强制】非负数必须UNSIGNED
【建议】主键 以pk_开头,唯一索引 以uq_开头,普通索引 以idx_开头
【建议】建立组合索引,把区分度高的字段放在前面
【强制】手机号存储不得使用数字,而使用VARCHAR(支持开头0及模糊查询)
【建议】金额存储用INT,程序端乘以和除以100进行存取,因为INT占4字节,而DOUBLE占8字节
【强制】高并发或分布式场景不允许外键约束 -
【建议】字段允许适当 冗余,以减少联表来提高查询性能,但必须考虑数据一致性
冗余字段应遵循:不是频繁修改的字段,不是text等较长字段
-- 表必备字段,这些字段起到似metadata的作用;在数据分析的时候,可用update_time作为数据抽取的增量标识
CREATE TABLE `xxx_info` (
`id` BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键',
`create_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`delete_flag` TINYINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '逻辑删除标识:1=删除,0=未删',
PRIMARY KEY (`id`) USING BTREE
) DEFAULT CHARSET=utf8mb4 COMMENT 'xxx信息表';2.4.2、HIVE代码规范(待完善)
HIVE代码规范 继承 SQL代码规范
- 命名
【强制】自定义函数以udf_开头
【强制】表名以分层名作为前缀,分层仅仅是逻辑上的区分,所有分层都在同一个库
| 分层 | 命名规范 | 说明 | 例 |
|---|---|---|---|
ODSOperation Data Store 原始数据 |
ods+源类型+源表名+full/i |
full:全量同步i:增量同步 |
ods_postgresql_sku_fullods_mysql_order_detail_iods_frontend_log |
DIMDimension 合并维度 |
dim+维度+full/zip |
full:全量表zip:拉链表日期维度表没有后缀 |
dim_sku_fulldim_user_zipdim_date |
DWDData Warehouse Detail 维度建模 |
dwd+事实+full/i |
full:全量事实i:增量事实 |
dwd_inventory_fulldwd_order_detail_i |
DWSData Warehouse Service 聚合 |
dws+原子指标 |
时间粒度有1d、1h…1d:按1天1h:按1小时 |
dws_page_visitor_1d |
DWTData Warehouse Topic 累积 |
dwt_consumer |
||
ADSApplication Data Store 最终指标 |
ads+衍生指标/派生指标 |
- 建库
【强制】建库必须加上注释
【强制】建库不要添加LOCATION,而使用hive-site.xml中配置的默认值
【建议】库按业务划分,不同库的表不会有关联(JOIN) - 建表
【强制】普通表使用外部表(EXTERNAL_TABLE),临时表使用内部表(MANAGED_TABLE)
【强制】创建内部表无需指定LOCATION
【建议】ADS层使用\t或,作为列分隔符,行存\n分隔,不压缩,方便Sqoop导出 - 分区
【强制】日期分区使用ymd,数据类型STRING,格式yyyy-MM-dd,例如2022-02-02
【强制】月分区使用ym,数据类型STRING,格式yyyy-MM,例如2022-02
【建议】小时分区使用(ymd,h)多级分区,数据类型STRING,格式(yyyy-MM-dd,HH),日期在小时前
【建议】ADS层不分区 - 查询
【建议】慎用DISTINCT,性能较差;不过在高版本HIVE可能会被优化,具体还要看执行计划
【建议】慎用多个OR,避免笛卡尔乘积,可用UNION ALL代替(前提是不影响逻辑,因为UNION ALL不去重)
【建议】慎用ORDER BY,ORDER BY为全局排序,只有1个Reducer
2.5、其它
2.5.1、Java和Scala(待完善)
- 【强制】文档注释
/** */;多行注释/* */;单行注释// - 【强制】缩进量:2或4个空格
| 命名规范 | 说明 | 示例 |
|---|---|---|
| 变量、方法 | 【强制】第一个单词全小写,后续单词首字母大写 | methodName |
| 类 | 【强制】每个单词首字母大写 | ClassName |
| 包、项目名 | 【强制】全小写 | |
| 常量 | 【强制】全大写 和 下划线 | PUBLIC_CONSTANT |
2.5.2、JSON (待完善)
| 命名规范 | 说明 | 示例 |
|---|---|---|
| 键 | 【强制】第一个单词全小写,后续单词首字母大写 | cityId |
2.5.3、Shell(待完善)
- 【强制】脚本头:
#!/usr/bin/sh - 【强制】注释方式:井号+空格,例如
# 这是注释 - 【建议】缩进量:4个空格
| 命名规范 | 说明 | 示例 |
|---|---|---|
| 变量、函数 | 【强制】全小写,下划线分隔单词 | function_name |
| 常量 | 【强制】全大写 和 下划线 | PUBLIC_CONSTANT |
| 脚本名 | 【建议】全小写,下划线分隔单词 | sqoop_mysql2hive.sh |
3、代码评审 自动化脚本
-
功能:
整体代码扫描、单个代码文件扫描 -
使用方法:
将(不含外部包)的代码 和 该代码扫描脚本 放到同级目录,使用Python3运行
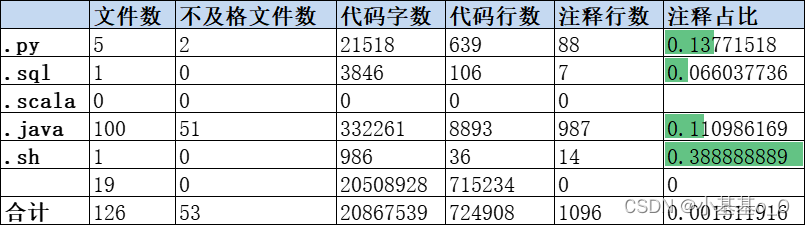
代码扫描报告示例:

import os
import re
from collections import defaultdict
from pandas import DataFrame
class File:
class Compile:
@staticmethod
def findall(string):
return []
@staticmethod
def match(string):
return not None
# 文件名后缀
SUFFIX = ''
# 提取注释的正则表达式
COMMENT_PATTERN = Compile
# 合格代码的最低注释占比
COMMENT_PROPORTION_THRESHOLD = 0
# 代码头部模板
HEAD_PATTERN = Compile
# 单行代码最大长度
LINE_LENGTH_LIMIT = 120
# 不合规的代码语句
UNQUALIFIED_CODE_PATTERN = Compile
def __init__(self, file_name):
self.file_name = file_name
# 读取文件
txt = self.read_file()
# 字数
self.number_of_words = len(txt)
# 行数
self.number_of_lines = len(txt.split('\n'))
# 注释抽取
comments = self.COMMENT_PATTERN.findall(txt)
# 注释行数
self.number_of_comments = sum(len(c.strip().split('\n')) for c in comments)
# 注释个数的占比
self.comment_proportion = self.number_of_comments / self.number_of_lines
# 不及格原因
self.reason_for_failings = []
if self.comment_proportion < self.COMMENT_PROPORTION_THRESHOLD:
self.reason_for_failings.append('注释太少')
if self.HEAD_PATTERN.match(txt) is None:
self.reason_for_failings.append('代码头部没有按照指定模板')
if max(len(line) for line in txt.split('\n')) > self.LINE_LENGTH_LIMIT:
self.reason_for_failings.append('单行代码过长')
if self.UNQUALIFIED_CODE_PATTERN.findall(txt):
self.reason_for_failings.append('含有不合格的代码语句')
def read_file(self):
with open(self.file_name, encoding='utf-8') as f:
return f.read().strip()
def report(self):
print('文件名称', self.file_name)
print('字数', self.number_of_words)
print('行数', self.number_of_lines)
print('注释行数', self.number_of_comments)
print('注释行数占比', self.comment_proportion)
print('不及格原因:' if self.reason_for_failings else '代码及格!')
for e, r in enumerate(self.reason_for_failings, 1):
print(e, r)
class PyFile(File):
SUFFIX = '.py'
COMMENT_PATTERN = re.compile(r'"""[\s\S]+?"""|# .+')
COMMENT_PROPORTION_THRESHOLD = 0.05
class SqlFile(File):
SUFFIX = '.sql'
COMMENT_PATTERN = re.compile('-- .+')
COMMENT_PROPORTION_THRESHOLD = 0.05
UNQUALIFIED_CODE_PATTERN = re.compile(r'select\s+\*', re.I)
class JavaFile(File):
SUFFIX = '.java'
COMMENT_PATTERN = re.compile(r'/\*[\s\S]+?\*/|//.+')
COMMENT_PROPORTION_THRESHOLD = 0.1
class ScalaFile(JavaFile):
SUFFIX = '.scala'
class ShFile(File):
SUFFIX = '.sh'
COMMENT_PATTERN = re.compile('# .+')
COMMENT_PROPORTION_THRESHOLD = 0.1
HEAD_PATTERN = re.compile('#!/usr/bin/sh')
class Files:
FILES = (PyFile, SqlFile, ScalaFile, JavaFile, ShFile)
def __init__(self):
self.statistic = {t.SUFFIX: [] for t in self.FILES}
def traversal(self, path=os.path.dirname(__file__)):
"""递归遍历文件"""
for file_name in os.listdir(path):
abs_path = os.path.join(path, file_name)
if os.path.isdir(abs_path):
for p in self.traversal(abs_path):
yield p
elif os.path.isfile(abs_path):
yield abs_path
def calculate(self):
"""计算 文件数、代码量、注释量…"""
for abs_path in self.traversal():
if abs_path == __file__:
continue
for f in self.FILES:
if abs_path.endswith(f.SUFFIX):
self.statistic[f.SUFFIX].append(f(abs_path))
break
@property
def failed_codes(self):
"""不及格代码"""
return (f.file_name for files in self.statistic.values() for f in files if f.reason_for_failings)
def files_report(self):
"""分析全部代码"""
self.calculate()
df = defaultdict(list)
index = []
for suffix, files in self.statistic.items():
index.append(suffix)
df['文件数'].append(len(files))
df['不及格文件数'].append(sum(1 if f.reason_for_failings else 0 for f in files))
df['代码字数'].append(sum(f.number_of_words for f in files))
df['代码行数'].append(sum(f.number_of_lines for f in files))
df['注释行数'].append(sum(f.number_of_comments for f in files))
df = DataFrame(df, index)
df.loc['合计'] = df.sum()
df['注释占比'] = df['注释行数'] / df['代码行数']
df['不及格率'] = df['不及格文件数'] / df['文件数']
print(df)
# df.to_excel('代码扫描报告.xlsx')
print('不及格代码:')
for f in self.failed_codes:
print(f)
def single_file_report(self, the_file):
"""单个文件分析"""
for f in self.FILES:
if the_file.endswith(f.SUFFIX):
f(the_file).report()
break
if __name__ == '__main__':
Files().files_report()
Files().single_file_report(__file__) # 检查自己
# Files().single_file_report(r'')4、数据逻辑校验机制
-
数据开发不同于后端开发之处是:后端开发可是有测试妹子帮忙进行功能测试的噢~
而数据开发工程师却没有😰😂😭 -
数据逻辑错误不像功能bug那么明显,计算结果错误并不会使程序报错
对此建立数据逻辑校验机制
- 主键重复值检验
- 主键NULL值检验
- 左联前后数量校验(联表后数据量=左表数据量)
- 时间数据类型校验,注意时区
- 度量值是否可加
- 数值类型校验,是否越界,是否损失精度
本文来自博客园,作者:大码王,转载请注明原文链接:https://www.cnblogs.com/huanghanyu/

 posted on
posted on










【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具