
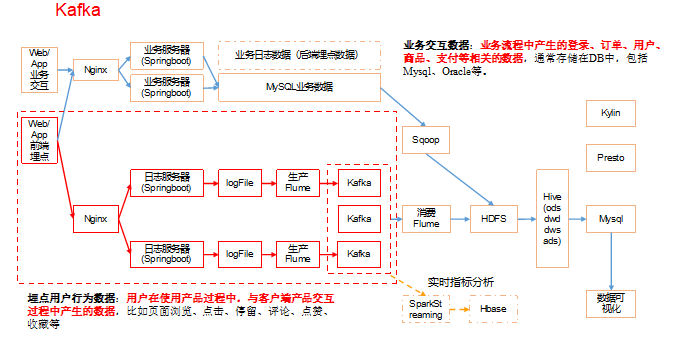
4.5.1 Kafka集群安装
集群规划:

4.5.2 Kafka集群启动停止脚本
1)在/home/kgg/bin目录下创建脚本kf.sh
[kgg@hadoop101 bin]$ vim kf.sh
在脚本中填写如下内容
说明:启动Kafka时要先开启JMX端口,是用于后续KafkaManager监控。 2)增加脚本执行权限
[kgg@hadoop101 bin]$ chmod 777 kf.sh
3)kf集群启动脚本
[kgg@hadoop101 module]$ kf.sh start
4)kf集群停止脚本
[kgg@hadoop101 module]$ kf.sh stop
4.5.3 查看Kafka Topic列表
[kgg@hadoop101 kafka]$ bin/kafka-topics.sh --zookeeper hadoop101:2181 --list
4.5.4 创建Kafka Topic
进入到/opt/module/kafka/目录下分别创建:启动日志主题、事件日志主题。 1)创建启动日志主题
[kgg@hadoop101 kafka]$ bin/kafka-topics.sh --zookeeper hadoop101:2181,hadoop102:2181,hadoop103:2181 --create --replication-factor 1 --partitions 1 --topic topic_start
2)创建事件日志主题
[kgg@hadoop101 kafka]$ bin/kafka-topics.sh --zookeeper hadoop101:2181,hadoop102:2181,hadoop103:2181 --create --replication-factor 1 --partitions 1 --topic topic_event
4.5.5 删除Kafka Topic
1)删除启动日志主题
[kgg@hadoop101 kafka]$ bin/kafka-topics.sh --delete --zookeeper hadoop101:2181,hadoop102:2181,hadoop103:2181 --topic topic_start
2)删除事件日志主题
[kgg@hadoop101 kafka]$ bin/kafka-topics.sh --delete --zookeeper hadoop101:2181,hadoop102:2181,hadoop103:2181 --topic topic_event
4.5.6 Kafka生产消息
[kgg@hadoop101 kafka]$ bin/kafka-console-producer.sh \
--broker-list hadoop101:9092 --topic topic_start
>hello world
>kgg kgg
4.5.7 Kafka消费消息
[kgg@hadoop101 kafka]$ bin/kafka-console-consumer.sh \
--bootstrap-server hadoop101:9092 --from-beginning --topic topic_start
--from-beginning:会把主题中以往所有的数据都读取出来。根据业务场景选择是否增加该配置。
4.5.8 查看Kafka Topic详情
[kgg@hadoop101 kafka]$ bin/kafka-topics.sh --zookeeper hadoop101:2181 \
--describe --topic topic_start
4.5.9 项目经验之Kafka压力测试
1)Kafka压测 用Kafka官方自带的脚本,对Kafka进行压测。Kafka压测时,可以查看到哪个地方出现了瓶颈(CPU,内存,网络IO)。一般都是网络IO达到瓶颈。
kafka-consumer-perf-test.sh
kafka-producer-perf-test.sh
2)Kafka Producer压力测试 (1)在/opt/module/kafka/bin目录下面有这两个文件。我们来测试一下
[kgg@hadoop101 kafka]$ bin/kafka-producer-perf-test.sh --topic test --record-size 100 --num-records 100000 --throughput 1000 --producer-props bootstrap.servers=hadoop101:9092,hadoop102:9092,hadoop103:9092
说明:record-size是一条信息有多大,单位是字节。num-records是总共发送多少条信息。throughput 是每秒多少条信息。
(2)Kafka会打印下面的信息
5000 records sent, 999.4 records/sec (0.10 MB/sec), 1.9 ms avg latency, 254.0 max latency.
5002 records sent, 1000.4 records/sec (0.10 MB/sec), 0.7 ms avg latency, 12.0 max latency.
5001 records sent, 1000.0 records/sec (0.10 MB/sec), 0.8 ms avg latency, 4.0 max latency.
5000 records sent, 1000.0 records/sec (0.10 MB/sec), 0.7 ms avg latency, 3.0 max latency.
5000 records sent, 1000.0 records/sec (0.10 MB/sec), 0.8 ms avg latency, 5.0 max latency.
参数解析:本例中一共写入10w条消息,每秒向Kafka写入了0.10MB的数据,平均是1000条消息/秒,每次写入的平均延迟为0.8毫秒,最大的延迟为254毫秒。
3)Kafka Consumer压力测试 Consumer的测试,如果这四个指标(IO,CPU,内存,网络)都不能改变,考虑增加分区数来提升性能。
[kgg@hadoop101 kafka]$
bin/kafka-consumer-perf-test.sh --zookeeper hadoop101:2181 --topic test --fetch-size 10000 --messages 10000000 --threads 1
参数说明: --zookeeper 指定zookeeper的链接信息 --topic 指定topic的名称 --fetch-size 指定每次fetch的数据的大小 --messages 总共要消费的消息个数
测试结果说明: start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec 2019-02-19 20:29:07:566, 2019-02-19 20:29:12:170, 9.5368, 2.0714, 100010, 21722.4153 开始测试时间,测试结束数据,最大吞吐率9.5368MB/s,平均每秒消费2.0714MB/s,最大每秒消费100010条,平均每秒消费21722.4153条。
4.5.10 项目经验之Kafka机器数量计算
Kafka机器数量(经验公式)=2(峰值生产速度副本数/100)+1 先拿到峰值生产速度,再根据设定的副本数,就能预估出需要部署Kafka的数量。 比如我们的峰值生产速度是50M/s。副本数为2。 Kafka机器数量=2(502/100)+ 1=3台
4.6 消费Kafka数据Flume
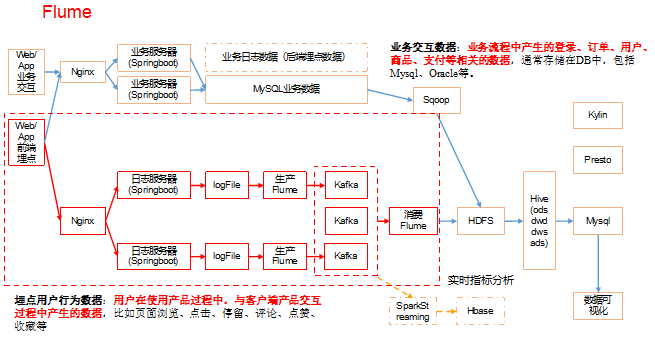
集群规划

4.6.1 日志消费Flume配置
1)Flume配置分析
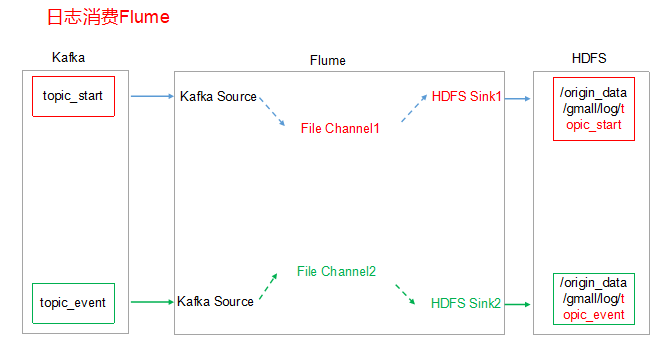
2)Flume的具体配置如下: (1)在hadoop103的/opt/module/flume/conf目录下创建kafka-flume-hdfs.conf文件
[kgg@hadoop103 conf]$ vim kafka-flume-hdfs.conf
在文件配置如下内容
## 组件
a1.sources=r1 r2
a1.channels=c1 c2
a1.sinks=k1 k2
## source1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = hadoop101:9092,hadoop102:9092,hadoop103:9092
a1.sources.r1.kafka.topics=topic_start
## source2
a1.sources.r2.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r2.batchSize = 5000
a1.sources.r2.batchDurationMillis = 2000
a1.sources.r2.kafka.bootstrap.servers = hadoop101:9092,hadoop102:9092,hadoop103:9092
a1.sources.r2.kafka.topics=topic_event
## channel1
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior1
a1.channels.c1.dataDirs = /opt/module/flume/data/behavior1/
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.capacity = 1000000
a1.channels.c1.keep-alive = 6
## channel2
a1.channels.c2.type = file
a1.channels.c2.checkpointDir = /opt/module/flume/checkpoint/behavior2
a1.channels.c2.dataDirs = /opt/module/flume/data/behavior2/
a1.channels.c2.maxFileSize = 2146435071
a1.channels.c2.capacity = 1000000
a1.channels.c2.keep-alive = 6
## sink1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_start/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = logstart-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = second
##sink2
a1.sinks.k2.type = hdfs
a1.sinks.k2.hdfs.path = /origin_data/gmall/log/topic_event/%Y-%m-%d
a1.sinks.k2.hdfs.filePrefix = logevent-
a1.sinks.k2.hdfs.round = true
a1.sinks.k2.hdfs.roundValue = 10
a1.sinks.k2.hdfs.roundUnit = second
## 不要产生大量小文件
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k2.hdfs.rollInterval = 10
a1.sinks.k2.hdfs.rollSize = 134217728
a1.sinks.k2.hdfs.rollCount = 0
## 控制输出文件是原生文件。
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k2.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = lzop
a1.sinks.k2.hdfs.codeC = lzop
## 拼装
a1.sources.r1.channels = c1
a1.sinks.k1.channel= c1
a1.sources.r2.channels = c2
a1.sinks.k2.channel= c2

4.6.2 项目经验之Flume内存优化
1)问题描述:如果启动消费Flume抛出如下异常
ERROR hdfs.HDFSEventSink: process failed
java.lang.OutOfMemoryError: GC overhead limit exceeded
2)解决方案步骤: (1)在hadoop101服务器的/opt/module/flume/conf/flume-env.sh文件中增加如下配置
export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
(2)同步配置到hadoop102、hadoop103服务器
[kgg@hadoop101 conf]$ xsync flume-env.sh
3)Flume内存参数设置及优化 JVM heap一般设置为4G或更高,部署在单独的服务器上(4核8线程16G内存) -Xmx与-Xms最好设置一致,减少内存抖动带来的性能影响,如果设置不一致容易导致频繁fullgc。
4.6.3 项目经验之Flume组件
1)FileChannel和MemoryChannel区别 MemoryChannel传输数据速度更快,但因为数据保存在JVM的堆内存中,Agent进程挂掉会导致数据丢失,适用于对数据质量要求不高的需求。 FileChannel传输速度相对于Memory慢,但数据安全保障高,Agent进程挂掉也可以从失败中恢复数据。
2)FileChannel优化 通过配置dataDirs指向多个路径,每个路径对应不同的硬盘,增大Flume吞吐量。 官方说明如下:
Comma separated list of directories for storing log files. Using multiple directories on separate disks can improve file channel peformance
checkpointDir和backupCheckpointDir也尽量配置在不同硬盘对应的目录中,保证checkpoint坏掉后,可以快速使用backupCheckpointDir恢复数据
3)Sink:HDFS Sink (1)HDFS存入大量小文件,有什么影响? 元数据层面:每个小文件都有一份元数据,其中包括文件路径,文件名,所有者,所属组,权限,创建时间等,这些信息都保存在Namenode内存中。所以小文件过多,会占用Namenode服务器大量内存,影响Namenode性能和使用寿命 计算层面:默认情况下MR会对每个小文件启用一个Map任务计算,非常影响计算性能。同时也影响磁盘寻址时间。 (2)HDFS小文件处理 官方默认的这三个参数配置写入HDFS后会产生小文件,hdfs.rollInterval、hdfs.rollSize、hdfs.rollCount 基于以上hdfs.rollInterval=3600,hdfs.rollSize=134217728,hdfs.rollCount =0几个参数综合作用,效果如下: (1)文件在达到128M时会滚动生成新文件 (2)文件创建超3600秒时会滚动生成新文件
4.6.4 日志消费Flume启动停止脚本
1)在/home/kgg/bin目录下创建脚本f2.sh
[kgg@hadoop101 bin]$ vim f2.sh
在脚本中填写如下内容
2)增加脚本执行权限
[kgg@hadoop101 bin]$ chmod 777 f2.sh
3)f2集群启动脚本
[kgg@hadoop101 module]$ f2.sh start
4)f2集群停止脚本
[kgg@hadoop101 module]$ f2.sh stop
4.7 采集通道启动/停止脚本
1)在/home/kgg/bin目录下创建脚本cluster.sh
[kgg@hadoop101 bin]$ vim cluster.sh
2)增加脚本执行权限
[kgg@hadoop101 bin]$ chmod 777 cluster.sh
3)cluster集群启动脚本
[kgg@hadoop101 module]$ cluster.sh start
4)cluster集群停止脚本
[kgg@hadoop101 module]$ cluster.sh stop
本文来自博客园,作者:大码王,转载请注明原文链接:https://www.cnblogs.com/huanghanyu/

 posted on
posted on










【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具