
4.1 Hadoop安装
1)集群规划: 
注意:尽量使用离线方式安装
4.1.1 项目经验之HDFS存储多目录
若HDFS存储空间紧张,需要对DataNode进行磁盘扩展。 1)在DataNode节点增加磁盘并进行挂载。
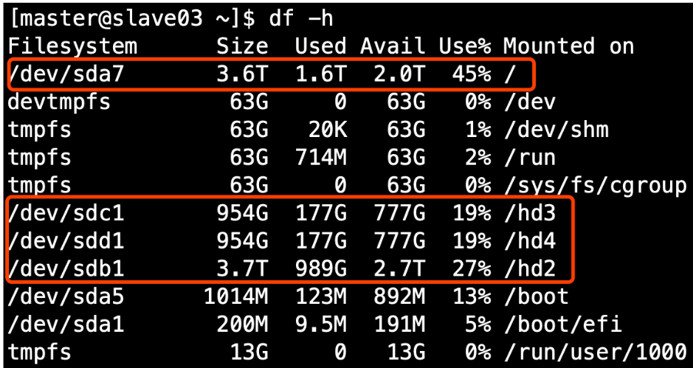 2)在hdfs-site.xml文件中配置多目录,注意新挂载磁盘的访问权限问题。
2)在hdfs-site.xml文件中配置多目录,注意新挂载磁盘的访问权限问题。
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///${hadoop.tmp.dir}/dfs/data1,file:///hd2/dfs/data2,file:///hd3/dfs/data3,file:///hd4/dfs/data4</value>
</property>
4.1.2 项目经验之支持LZO压缩配置
1)hadoop本身并不支持lzo压缩,故需要使用twitter提供的hadoop-lzo开源组件。hadoop-lzo需依赖hadoop和lzo进行编译,编译步骤如下。
2)将编译好后的hadoop-lzo-0.4.20.jar 放入hadoop-2.7.2/share/hadoop/common/
[kgg@hadoop101 common]$ pwd
/opt/module/hadoop-2.7.2/share/hadoop/common
[kgg@hadoop101 common]$ ls
hadoop-lzo-0.4.20.jar
3)同步hadoop-lzo-0.4.20.jar到hadoop102、hadoop103
[kgg@hadoop101 common]$ xsync hadoop-lzo-0.4.20.jar
4)core-site.xml增加配置支持LZO压缩
5)同步core-site.xml到hadoop102、hadoop103
[kgg@hadoop101 hadoop]$ xsync core-site.xml
6)启动及查看集群
[kgg@hadoop101 hadoop-2.7.2]$ sbin/start-dfs.sh
[kgg@hadoop102 hadoop-2.7.2]$ sbin/start-yarn.sh
7)测试
yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount -Dmapreduce.output.fileoutputformat.compress=true -Dmapreduce.output.fileoutputformat.compress.codec=com.hadoop.compression.lzo.LzopCodec /input /output
8)为lzo文件创建索引
hadoop jar ./share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /output
4.1.3 项目经验之基准测试
1) 测试HDFS写性能 测试内容:向HDFS集群写10个128M的文件
[kgg@hadoop101 mapreduce]$ hadoop jar /opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.2-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 128MB
19/05/02 11:44:26 INFO fs.TestDFSIO: TestDFSIO.1.8
19/05/02 11:44:26 INFO fs.TestDFSIO: nrFiles = 10
19/05/02 11:44:26 INFO fs.TestDFSIO: nrBytes (MB) = 128.0
19/05/02 11:44:26 INFO fs.TestDFSIO: bufferSize = 1000000
19/05/02 11:44:26 INFO fs.TestDFSIO: baseDir = /benchmarks/TestDFSIO
19/05/02 11:44:28 INFO fs.TestDFSIO: creating control file: 134217728 bytes, 10 files
19/05/02 11:44:30 INFO fs.TestDFSIO: created control files for: 10 files
19/05/02 11:44:30 INFO client.RMProxy: Connecting to ResourceManager at hadoop102/192.168.1.103:8032
19/05/02 11:44:31 INFO client.RMProxy: Connecting to ResourceManager at hadoop102/192.168.1.103:8032
19/05/02 11:44:32 INFO mapred.FileInputFormat: Total input paths to process : 10
19/05/02 11:44:32 INFO mapreduce.JobSubmitter: number of splits:10
19/05/02 11:44:33 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1556766549220_0003
19/05/02 11:44:34 INFO impl.YarnClientImpl: Submitted application application_1556766549220_0003
19/05/02 11:44:34 INFO mapreduce.Job: The url to track the job: http://hadoop102:8088/proxy/application_1556766549220_0003/
19/05/02 11:44:34 INFO mapreduce.Job: Running job: job_1556766549220_0003
19/05/02 11:44:47 INFO mapreduce.Job: Job job_1556766549220_0003 running in uber mode : false
19/05/02 11:44:47 INFO mapreduce.Job: map 0% reduce 0%
19/05/02 11:45:05 INFO mapreduce.Job: map 13% reduce 0%
19/05/02 11:45:06 INFO mapreduce.Job: map 27% reduce 0%
19/05/02 11:45:08 INFO mapreduce.Job: map 43% reduce 0%
19/05/02 11:45:09 INFO mapreduce.Job: map 60% reduce 0%
19/05/02 11:45:10 INFO mapreduce.Job: map 73% reduce 0%
19/05/02 11:45:15 INFO mapreduce.Job: map 77% reduce 0%
19/05/02 11:45:18 INFO mapreduce.Job: map 87% reduce 0%
19/05/02 11:45:19 INFO mapreduce.Job: map 100% reduce 0%
19/05/02 11:45:21 INFO mapreduce.Job: map 100% reduce 100%
19/05/02 11:45:22 INFO mapreduce.Job: Job job_1556766549220_0003 completed successfully
19/05/02 11:45:22 INFO mapreduce.Job: Counters: 51
File System Counters
FILE: Number of bytes read=856
FILE: Number of bytes written=1304826
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=2350
HDFS: Number of bytes written=1342177359
HDFS: Number of read operations=43
HDFS: Number of large read operations=0
HDFS: Number of write operations=12
Job Counters
Killed map tasks=1
Launched map tasks=10
Launched reduce tasks=1
Data-local map tasks=8
Rack-local map tasks=2
Total time spent by all maps in occupied slots (ms)=263635
Total time spent by all reduces in occupied slots (ms)=9698
Total time spent by all map tasks (ms)=263635
Total time spent by all reduce tasks (ms)=9698
Total vcore-milliseconds taken by all map tasks=263635
Total vcore-milliseconds taken by all reduce tasks=9698
Total megabyte-milliseconds taken by all map tasks=269962240
Total megabyte-milliseconds taken by all reduce tasks=9930752
Map-Reduce Framework
Map input records=10
Map output records=50
Map output bytes=750
Map output materialized bytes=910
Input split bytes=1230
Combine input