
随着信息化时代的加深,国家人力资源和社会保障部新规定了13个新型职业,大数据工程技术人员赫然在列,下面我将从一个初学者的态度,搭建我们的大数据平台。系统和软件版本如下:
| 软件 | 相应版本 |
|---|---|
| 操作系统 | CentOS 6.7 |
| JAVA | JDK 1.8.0.131 |
| SCALA | SCALA 2.11.2 |
| Hadoop | Hadoop 2.7.3 |
| Spark | Spark 2.0.2 |
| Zeppelin | Zeppelin 0.6.2 |
一、环境准备
-
卸载并安装JDK
由于CentOS默认安装的是OpenJDK,不满足我们的要求,所以需要我们先卸载,再重新安装上Oracle版本的JDK。
1.1. 查询java版本:rpm -qa|grep java
1.2. 卸载openjdk:yum -y remove java-xxx-openjdk-xxx(tzdata-java也需要卸载,卸载完之后用1.1命令查询不出包就可以)
1.3. 配置java环境变量:export JAVA_HOME=/usr/java/jdk1.8.0_131
export CLASSPATH=.: J A V A H O M E / l i b / d t . j a r : JAVA_HOME/lib/dt.jar: JAVAHOME/lib/dt.jar:JAVA_HOME/lib/tools.jar
export PATH= P A T H : PATH: PATH:JAVA_HOME/bin配置完之后可以通过
java -version或javac -version查看是否配置成功。 -
修改hostname
查看hostname:vim /etc/sysconfig/network将HOSTNAME修改成需要设置的名称,需要重启服务器生效。
修改hosts:vim /etc/hosts
ip1 master worker0 namenode
ip2 worker1 datanode1
ip3 worker2 datanode2

-
配置ntp服务
安装ntp软件包:yum -y install ntp(安装ntp和ntpdate两个包)
启动ntp服务:service ntpd start
查看ntp时间服务器:vim /etc/ntp.conf

从上面找一个可用的时间源,手动同步时间源:ntpdate 0.centos.pool.ntp.org
另外,如果不能上外网的话,也可以配置内网服务器。 -
scala安装
解压scala压缩包:tar zxvf scala-2.11.2.tgz -C /home
在/etc/profile文件中配置scala环境变量:export PATH=$PATH:$JAVA_HOME/bin:/home/scala/bin -
集群间免密登录
每个节点生成公私钥:ssh-keygen -t rsa -P ''
将所有id_rsa.pub公钥内容拷贝到master节点authorized_keys文件中:cat id_rsa.pub >> authorized_keysssh-copy-id -i master #登录worker1,将公钥拷贝到master的authorized_keys中
ssh-copy-id -i master #登录worker2,将公钥拷贝到master的authorized_keys中,最终authorized_keys文件内容如下:
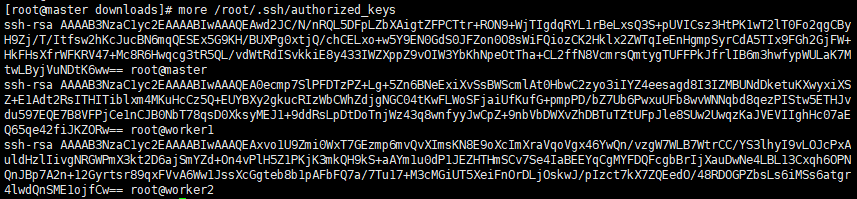
登录master节点,修改authorized_keys的权限:chmod 600 authorized_keys
将授权后的文件authorized_keys拷贝到worker1、worker2节点上,命令如下:scp /root/.ssh/authorized_keys worker1:/root/.ssh/ #拷贝到worker1上
scp /root/.ssh/authorized_keys worker2:/root/.ssh/ #拷贝到worker2上
至此,免密码登录已经设定完成,注意第一次ssh登录时需要输入密码,再次访问时即可免密码登录。
- 关闭SELinux
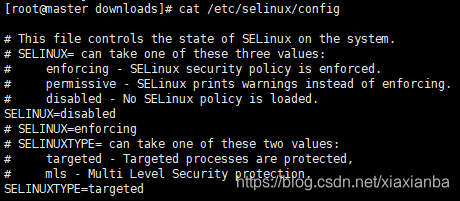
获取SELinux运行状态:getenforce
修改/etc/selinux/config文件,将SELINUX=disabled,如下图所示:
- 关闭防火墙
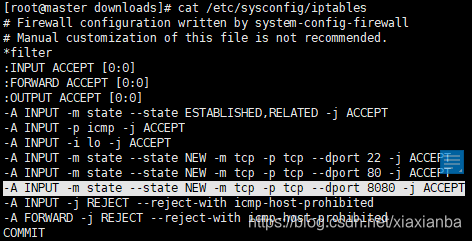
查看防火墙状态:service iptables status
永久关闭防火墙:chkconfig iptables off
开放某个端口,需要编辑/etc/sysconfig/iptables,增添一条 -A INPUT -m state --state NEW -m tcp -p tcp --dport 8080 -j ACCEPT,/etc/init.d/iptables restart 命令将iptables服务重启:
二、Hadoop安装部署
-
解压并重命名文件目录
解压并移动至相应目录:tar zxvf hadoop-2.7.3.tar.gz -C /home(将所有软件都放置在/home目录下)
进入/home重命名文件目录:mv hadoop-2.7.3 hadoop -
修改配置文件
2.1 /etc/profile文件,配置环境变量:
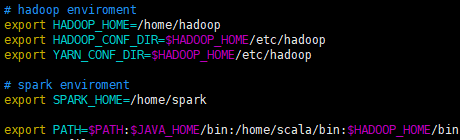
2.2 $HADOOP_HOME/etc/hadoop/hadoop-env.sh,修改JAVA_HOME:export JAVA_HOME=/usr/java/jdk1.8.0_131
2.3 $HADOOP_HOME/etc/hadoop/slaves,配置hadoop工作节点

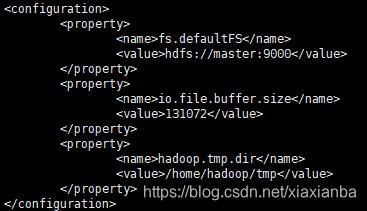
2.4 $HADOOP_HOME/etc/hadoop/core-site.xml
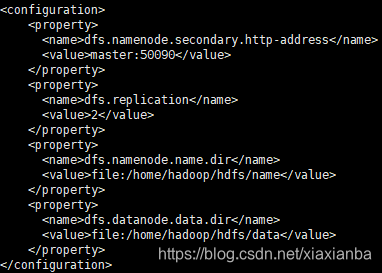
2.5 $HADOOP_HOME/etc/hadoop/hdfs-site.xml
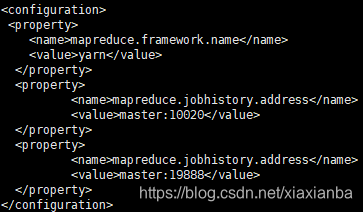
2.6 $HADOOP_HOME/etc/hadoop/mapred-site.xml,复制template,生成xml:cp mapred-site.xml.template mapred-site.xml
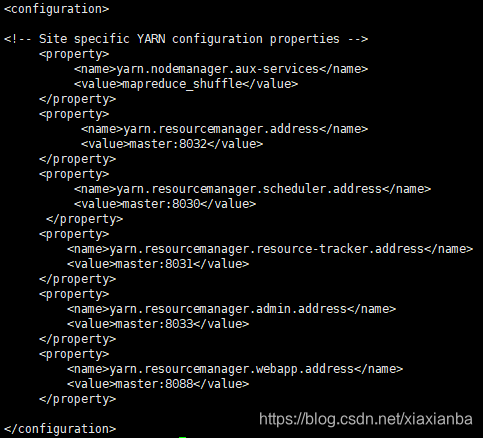
2.7 $HADOOP_HOME/etc/hadoop/yarn-site.xml
至此master节点的hadoop搭建完毕,复制master节点的hadoop文件夹到worker上:scp -r /home/hadoop root@wokerN:/opt #注意这里的N要改为1或者2,工作节点上也需要修改/etc/profile文件。
修改完/etc/profile文件之后,如果需要马上生效的话,一定要执行:source /etc/profile -
启动并验证
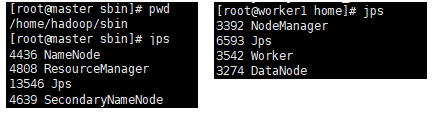
3.1 进入$HADOOP_HOME/sbin命令,执行start-all.sh脚本,服务启动之后,可以通过jsp命令查看本地的java程序进程,master节点和worker节点查看到的进程如下:
在使用hadoop之前,我们需要格式化namenode:hadoop namenode -format
3.2 验证hadoop集群
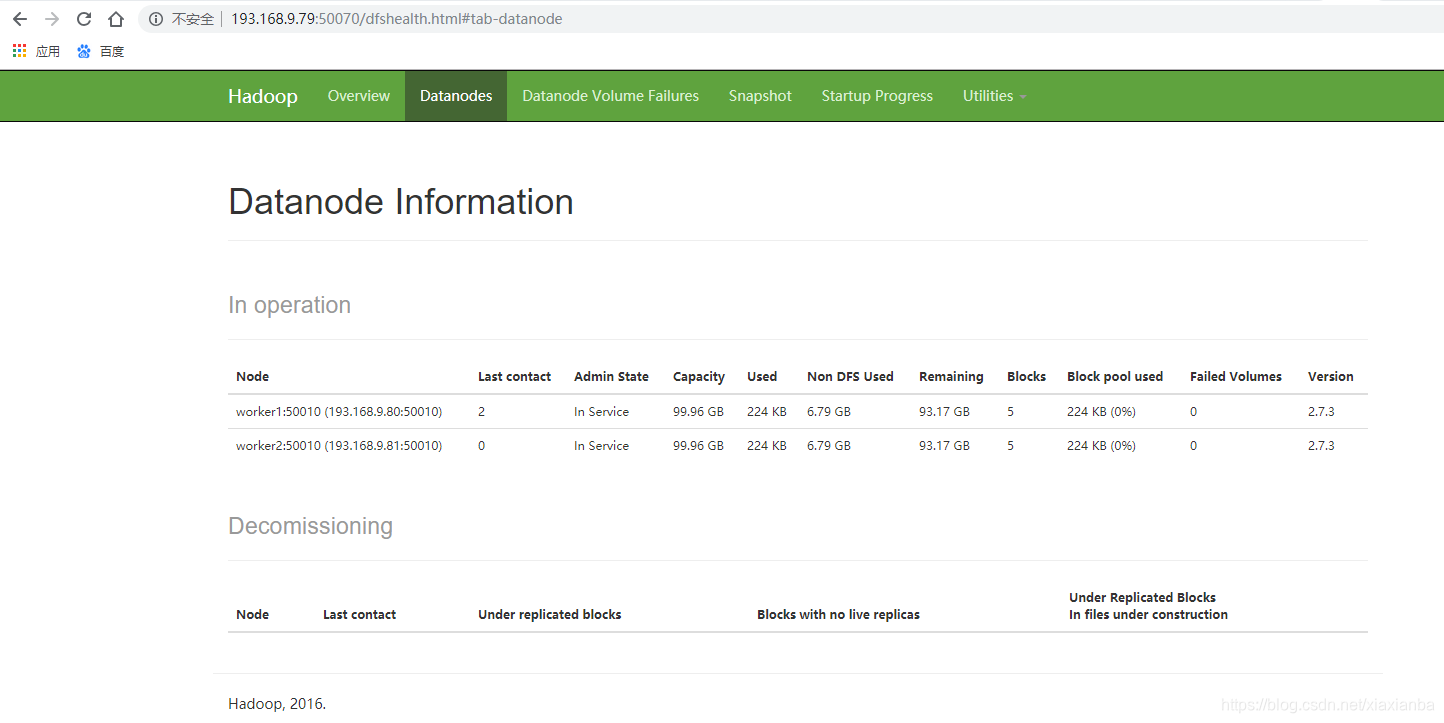
通过web的50070端口访问,可以查询到node接口信息
向hadoop集群系统提交第一个mapreduce任务(wordcount):
3.2.1hdfs dfs -mkdir -p /data/input在虚拟分布式文件系统上创建一个测试目录/data/input
3.2.2hdfs dfs -put README.txt /data/input将当前目录下的README.txt 文件复制到虚拟分布式文件系统中
3.2.3hdfs dfs -ls /data/input查看文件系统中是否存在我们所复制的文件
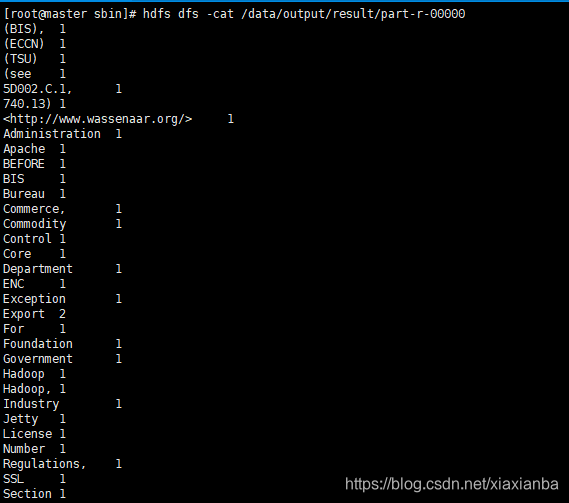
3.2.4hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /data/input /data/output/result查看result,结果在result下面的part-r-00000中:hdfs dfs -cat /data/output/result/part-r-00000
通过上面的jsp进程、web界面和执行一个任务,可以验证hadoop集群搭建成功。
三、Spark安装部署
- 解压并重命名目录
解压到指定目录:tar zxvf spark-2.0.2-bin-hadoop2.7.tgz -C /home
重命名目录:mv spark-2.0.2-bin-hadoop2.7 spark - 修改配置文件
2.1 /etc/profie

2.2 $SPARK_HOME/conf/spark-env.sh
复制模板文件生成新文件:cp spark-env.sh.template spark-env.sh
2.3 $SPARK_HOME/conf/slaves
复制模板文件并生成新文件:cp slaves.template slaves

- 将配置好的spark文件复制到workerN节点
scp -r spark root@worker1:/home
scp -r spark root@worker2:/home
修改/etc/profile,增加spark相关的配置,如Master节点一样。
- Hadoop+Spark启动服务、关闭服务脚本
启动脚本:start-cluster.sh
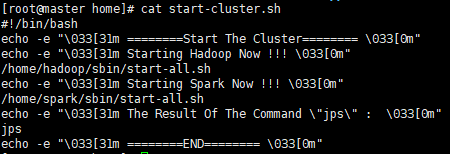
关闭脚本:stop-cluster.sh
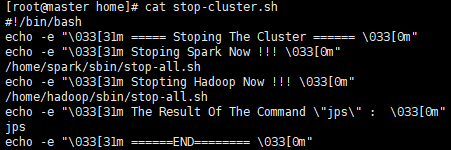
- 启动验证Spark集群
5.1 通过web网页访问:http://master:8080,可以查看到节点信息。
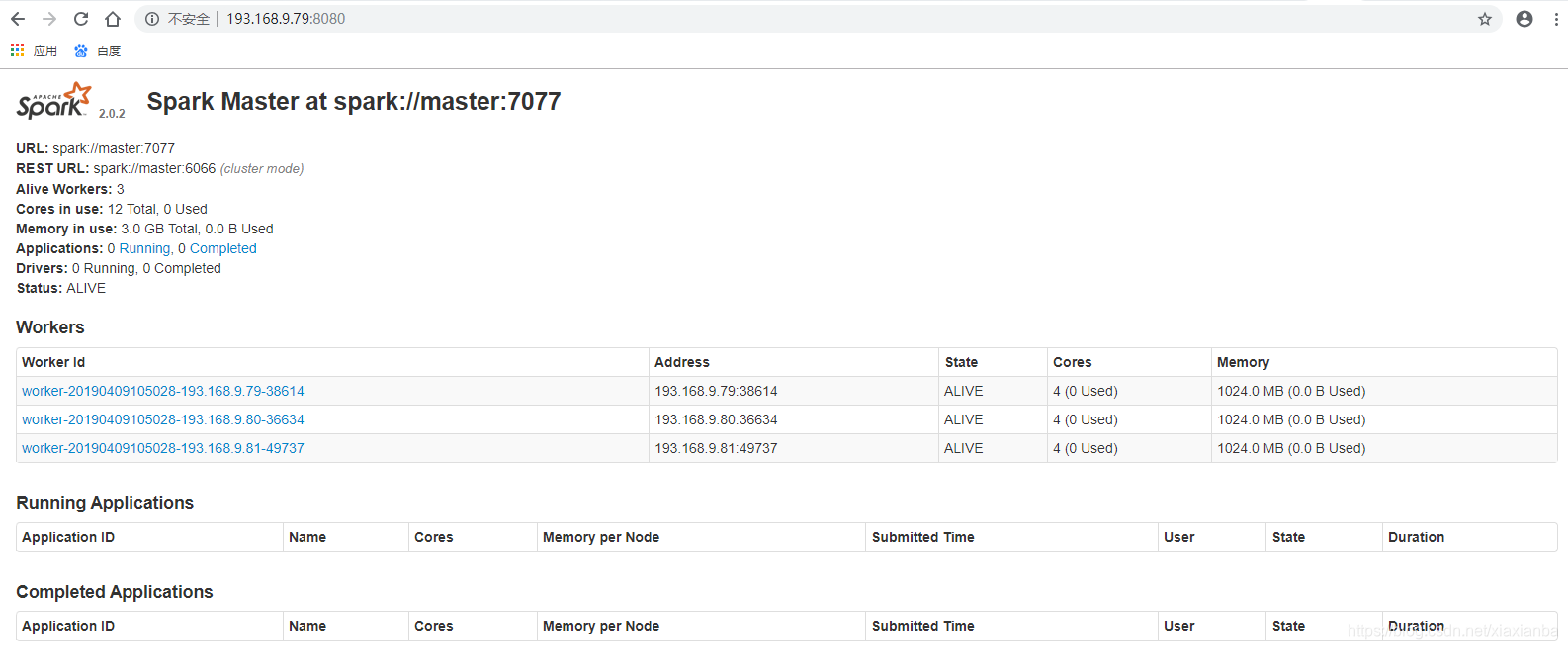
5.2 通过在启动spark-shell程序,没有报错信息,并执行一个任务

val file=sc.textFile(“hdfs://master:9000/data/input/README.txt”)
val rdd = file.flatMap(line => line.split(" ")).map(word =>(word,1)).reduceByKey(+)
rdd.collect()
rdd.foreach(println)
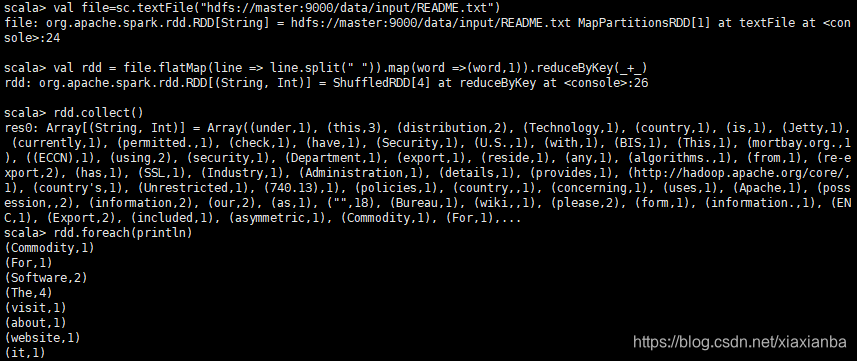
通过上面的web界面和spark-shell启动和任务执行,可以验证spark集群搭建成功。
四、Zeppelin安装部署
-
解压并重命名目录
解压到指定目录:tar zxvf zeppelin-0.6.2-bin-all.tgz -C /home
重命名文件目录:mv zeppelin-0.6.2-bin-all/ zeppelin -
修改配置文件
2.1 $ZEPPELIN_HOME/conf/zeppelin-env.shexport JAVA_HOME=/usr/java/jdk1.8.0_112/
export MASTER=“spark://master:7077”
export SPARK_HOME=/opt/spark-2.0.2-bin-hadoop2.7/
export HADOOP_HOME=/opt/hadoop-2.7.3/
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop2.2 $ZEPPELIN_HOME/conf/zeppelin-site.xml
为防止端口冲突,修改zeppelin访问端口
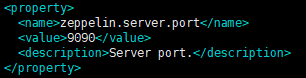
-
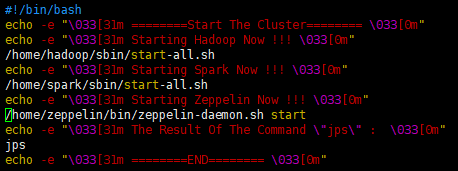
Hadoop+Spark+Zeppelin集群启动服务、关闭服务脚本
启动服务脚本:start-cluster.sh
关闭服务脚本:stop-cluster.sh
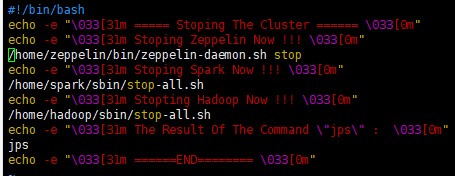
-
启动验证Zeppelin服务
登录zeppelin web界面:http://zeppelin:9090 (访问安装zeppelin服务的服务器)
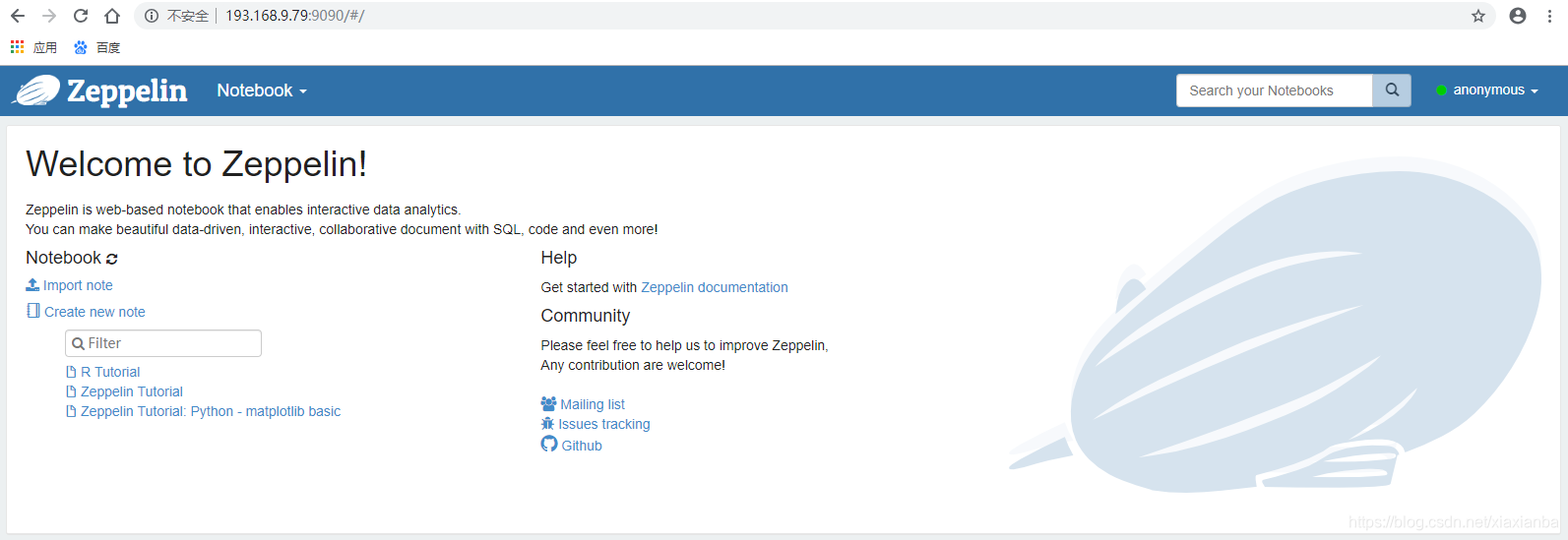
访问Zeppelin实例,运行截图。
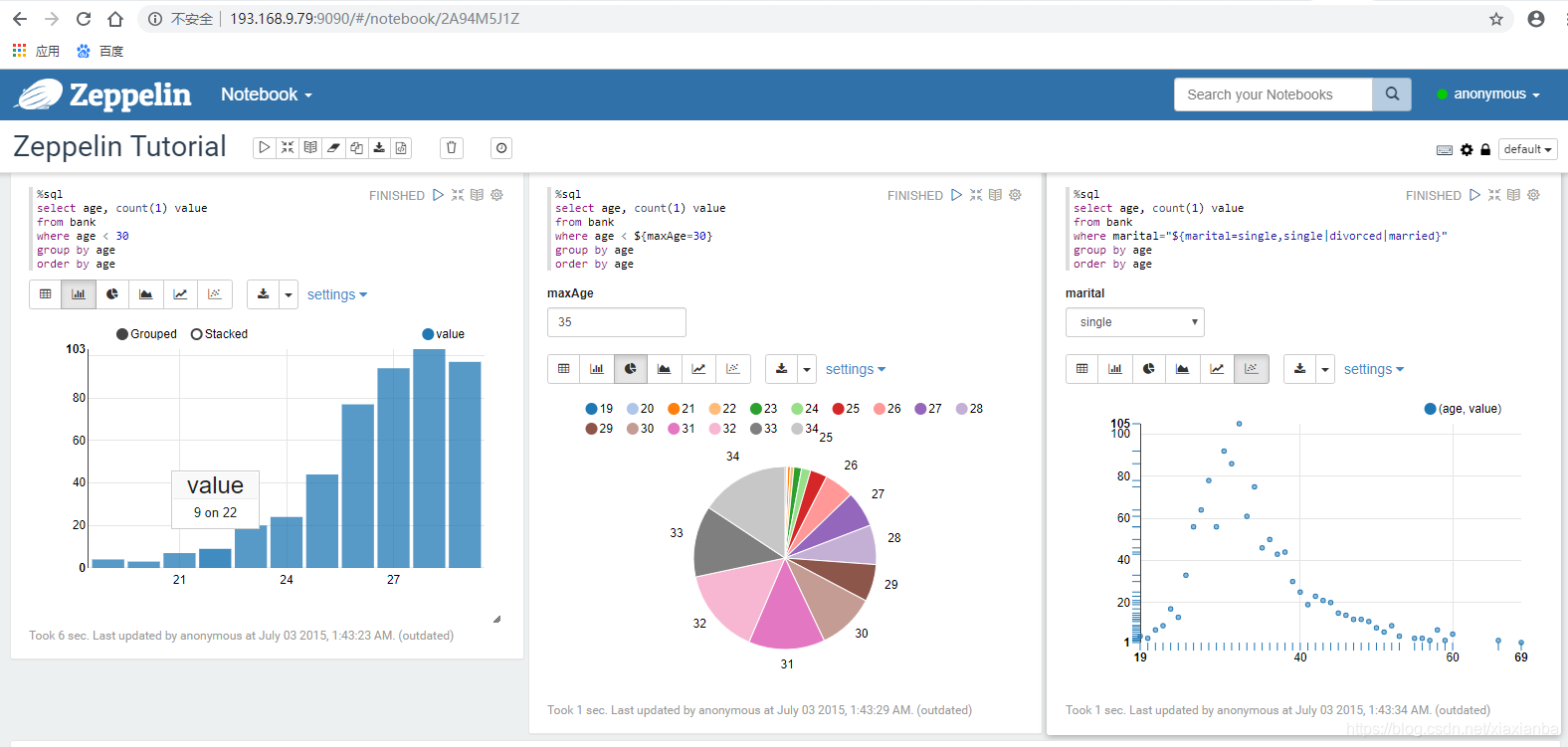
如果能够通过web访问,并可以执行zeppelin实例,可以验证系统搭建成功。
至此,大数据环境(hadoop+spark+zeppelin)集成搭建成功。
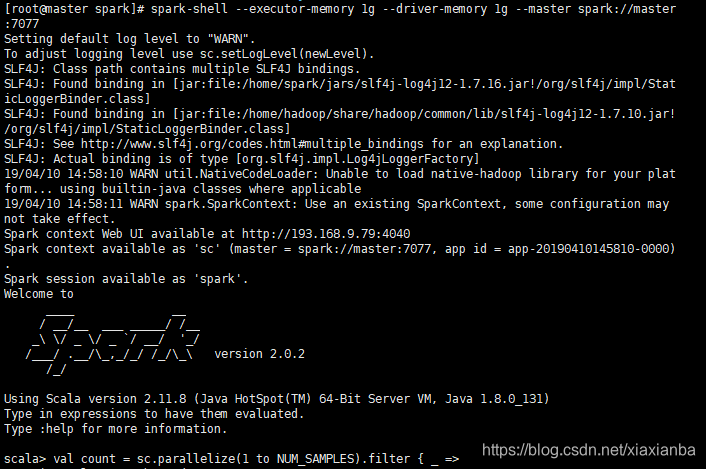
20190410:问题1:之前执行spark-shell的时候没有问题,但spark-shell后面带上参数spark-shell --executor-memory 1g --driver-memory 1g --master spark://master:7077控制台就会报错,执行完之后,spark web界面也没有相应执行任务的信息,所以怀疑还是单机版执行。
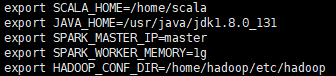
问题出在spark配置文件上没有配置清楚,基于上面的/home/spark/conf/spark-env.sh配置,增加节点信息配置如下:
export SCALA_HOME=/home/scala
export JAVA_HOME=/usr/java/jdk1.8.0_131
export SPARK_MASTER_IP=master
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/home/hadoop/etc/hadoop
export HADOOP_HOME=/home/hadoop
export SPARK_MASTER_IP=193.168.9.79
export SPARK_MASTER_HOST=193.168.9.79
export SPARK_LOCAL_IP=193.168.9.79
export SPARK_WORKER_MEMORY=1g
export SPARK_WORKER_CORES=2
export SPARK_HOME=/home/spark
export SPARK_DIST_CLASSPATH=$(/home/hadoop/bin/hadoop classpath)
重新调用下关闭集群脚本,再调用启动集群脚本,这个时候的界面没有任何报错信息,如下图:
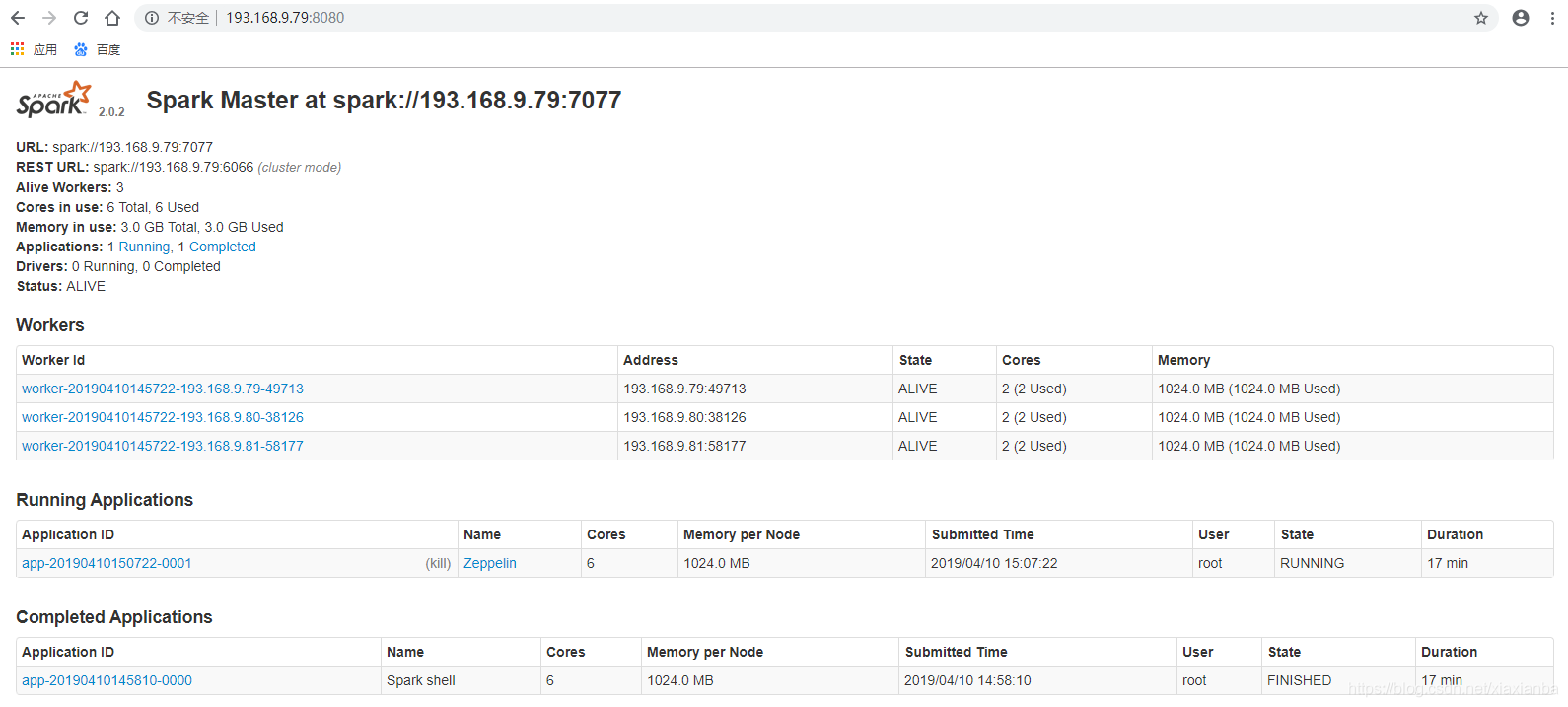
执行完任务之后,spark web界面有执行任务的信息,如下图:
问题2: Zeppelin页面上执行查询任务,出现的SparkContext问题。

原因是Zeppelin调用Spark查询失败后,Spark Interpreter就被一直占用,需要重新启动zeppelin服务才能解决这个问题。(由于采用的zeppelin0.6.2版本,据说0.7版本之后问题就解决了)
问题3: Zeppelin执行查询任务的时候提示Jackson版本太低。

Zeppelin版本所有的库都放在${ZEPPELIN_HOME}/lib下面,找到Jackson的三个包:
jackson-core-2.5.3.jar
jackson-annotations-2.5.0.jar
jackson-databind-2.5.3.jar
到jackson网站上去下载更新版本的jar包,作者下载的是2.6.0版本,2.9.x版本存在兼容性问题。
问题4: Spark On Yarn提示ERROR client.TransportClient:Failed to send RPC …
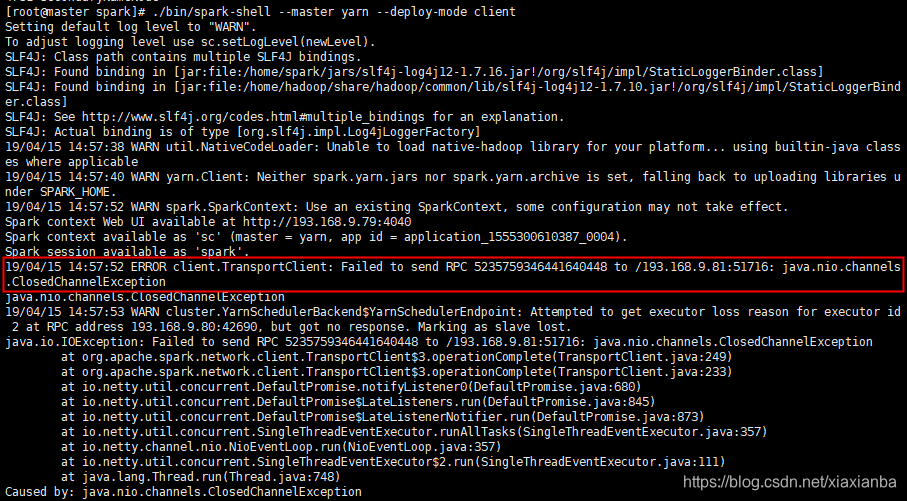
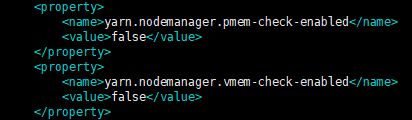
原因:主要是给节点分配的内存少,yarn kill了spark application,解决方法是给yarn-site.xml增加配置:
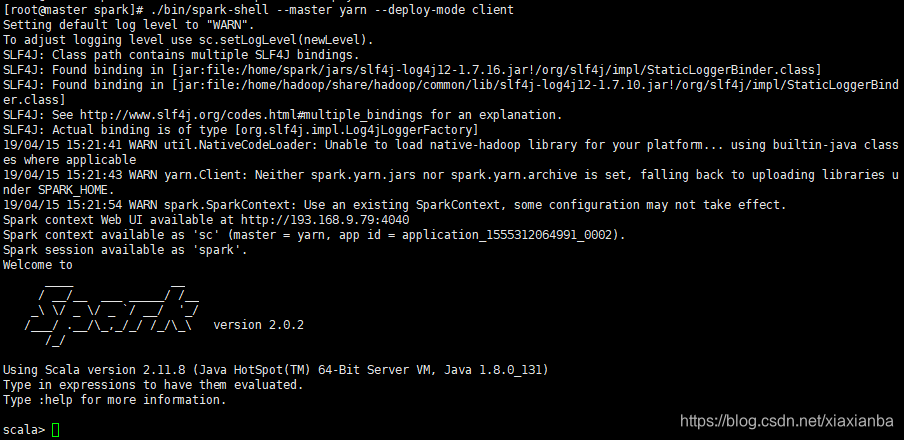
正常无错误运行截图
引用:
本文来自博客园,作者:大码王,转载请注明原文链接:https://www.cnblogs.com/huanghanyu/

 posted on
posted on










【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具