
一、准备工作
1.zepeelin简介
Zeppelin是一个基于Web的notebook,提供交互数据分析和可视化。后台支持接入多种数据处理引擎,如spark,hive等。支持多种语言: Scala(Apache Spark)、Python(Apache Spark)、SparkSQL、 Hive、 Markdown、Shell等。
2.安装包下载
链接:http://zeppelin.apache.org/download.html
选择 zeppelin-0.8.1-bin-all.tgz
3.环境要求
本文使用zepplin连接hive,所以需要虚拟机提前安装好hadoop以及hive
安装hadoop参考:https://blog.csdn.net/and52696686/article/details/107287066
安装hive参考:https://blog.csdn.net/and52696686/article/details/107007007
二、解压安装
将下载好的安装包文件拖拽至之前创建好的linux系统 /opt/software 目录下
解压并重命名:
tar -zxvf zeppelin-0.8.1-bin-all.tgz -C /opt/install/
mv zeppelin-0.8.1-bin-all/ zeppelin081三、修改配置文件
切换至zeppelin配置文件conf目录下
cd /opt/install/zeppelin/conf1.修改配置文件zeppelin-site.xml
复制并重命名
cp zeppelin-site.xml.template zeppelin-site.xml
vi zeppelin-site.xml进入文件需修改两处
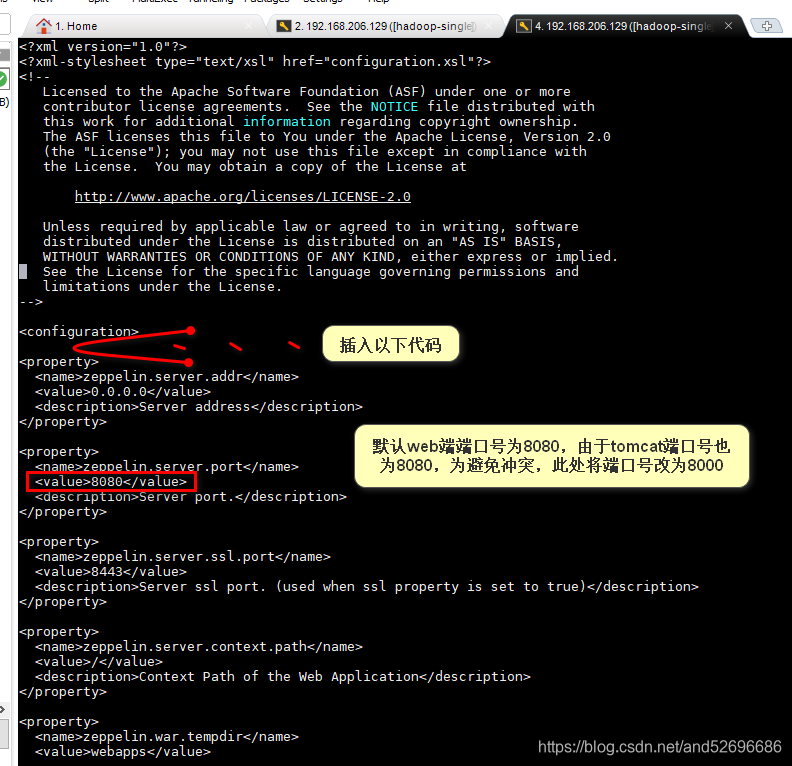
在下插入以下代码:
<!-- 修改端口配置,便于访问国外网站 -->
<property>
<name>zeppelin.helium.registry</name>
<value>helium</value>
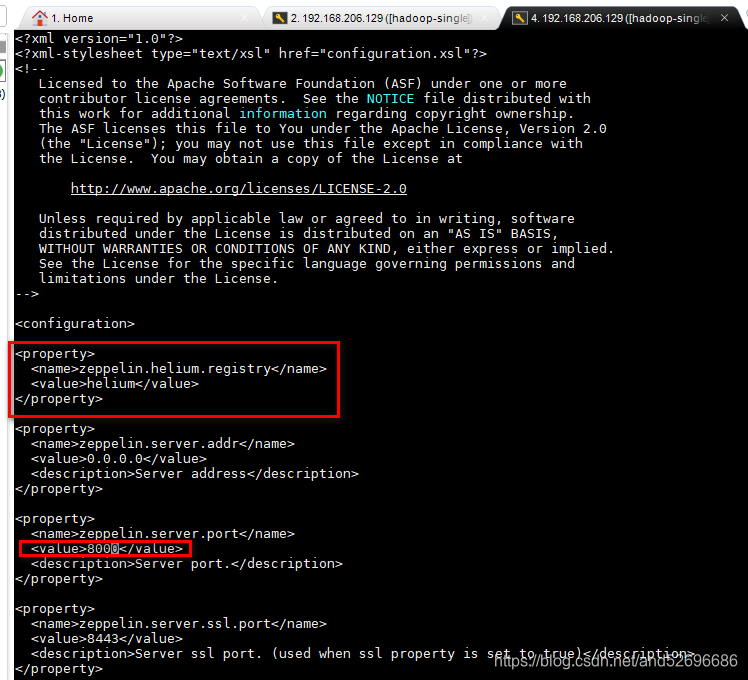
</property>修改端口号:默认是8080,为避免冲突,修改为其他端口号
修改后如图
2.修改zeppelin的环境文件
在当前conf目录下拷贝zeppelin系统脚本并重命名
cp zeppelin-env.sh.template zeppelin-env.sh编辑
vi zeppelin-env.sh修改下图;两处红框位置 "JAVA_HOME路径"和 “HADOOP_CONF_DIR配置文件路径”
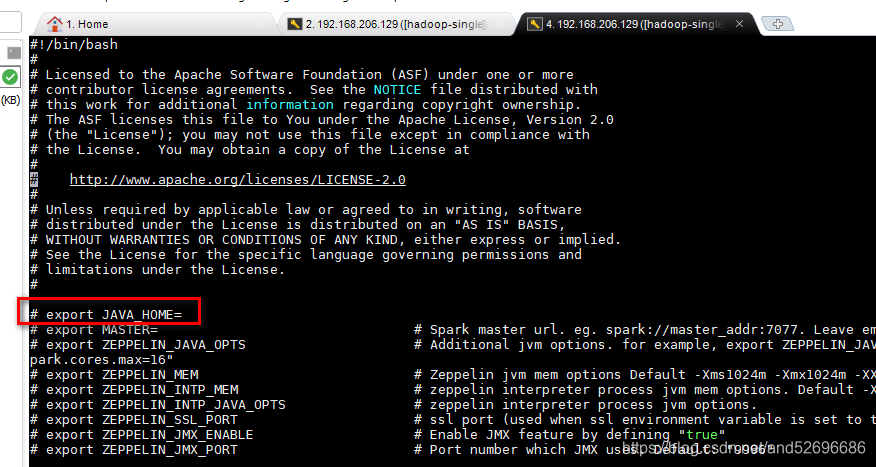

修改后:


四、启动zepeelin
切换至zeppelin/bin目录下,启动:
cd /opt/install/zeppelin081/bin
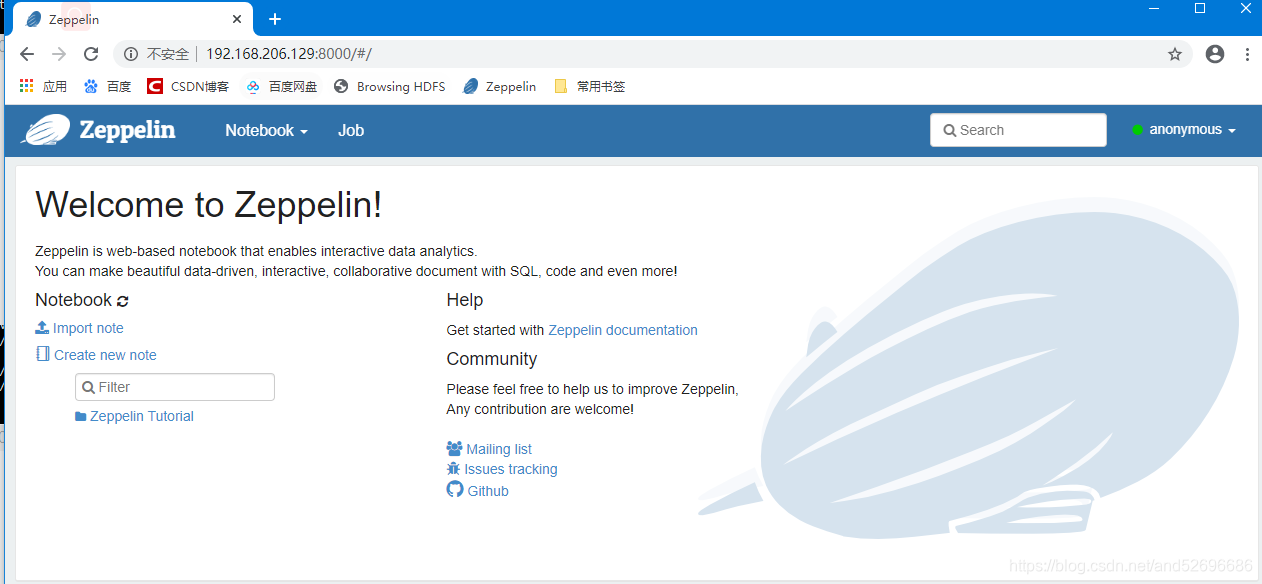
./zeppelin-daemon.sh start启动成功如下图:会提示ok

在web端输入: 192.168.206.129:8000
zeppeline启动较慢,虚拟机界面提示启动成功需耐心等待一会才可以打开网页:
关闭 zeppelin:
./zeppelin-daemon.sh stop五、配置hive解释器
Zepplin中没有默认的hive解释器,所以需要通过jdbc解释器进行添加
1.配置hive的环境变量至zeppelin中
①:拷贝 hive/conf 文件夹下的 hive-site.xml 到zeppelin081/conf目录下
cp /opt/install/hive/conf/hive-site.xml /opt/install/zeppelin081/conf②:拷贝jar包
拷贝下面两个jar包到zeppelin安装目录下 interperter/jdbc 中
hadoop/share/hadoop/common/hadoop-common-2.6.0-cdh5.14.2.jar
hive/lib/hive-jdbc-1.1.0-cdh5.14.2-standalone.jar
cp /opt/install/hadoop260/share/hadoop/common/hadoop-common-2.6.0-cdh5.14.2.jar /opt/install/zeppelin081/interpreter/jdbc/cp /opt/install/hive/lib/hive-jdbc-1.1.0-cdh5.14.2-standalone.jar /opt/install/zeppelin081/interpreter/jdbc/2.在web页面配置集成hive
2.1需先启动hadoop和hive服务
start-all.sh
zkServer.sh start
service mysql start
hive --service metastore #进程需独占一窗口
nohup hive --service hiveserver2 & #进程需独占一窗口配置hive坏境前一定要确认beelin服务能正常启动,因为zeppelin中搭载hive环境是通过beeine来连接的
2.2启动zeppelin服务
若之前启动过没有关闭不用再次启动
cd /opt/install/zeppelin081/bin
./zeppelin-daemon.sh start2.3打开网页创建hive集成环境
网址:192.168.206.129:8000
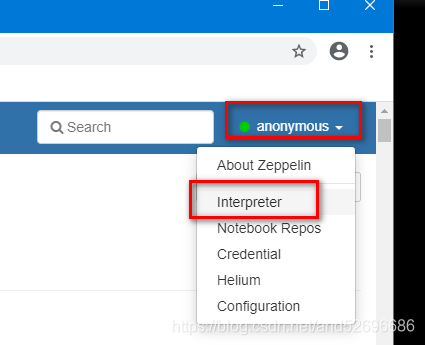
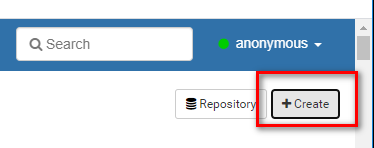
①:右上角anonymous --> interpreter --> +Create新建一个叫做hive的集成环境
②:设置properties
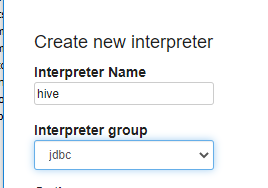
创建分组名就叫做 hive ,分组为 jdbc
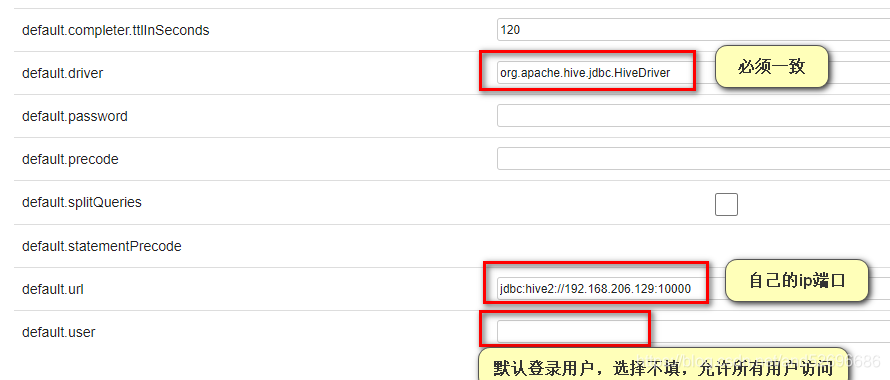
设置下图三处红框位置内容即可
default.driver : org.apache.hive.jdbc.HiveDriver
default.url : jdbc:hive2://192.168.42.200:10000
default.user : null
设置完成保存即可
六、使用Zepplin的hive解释器
1.创建notebook节点
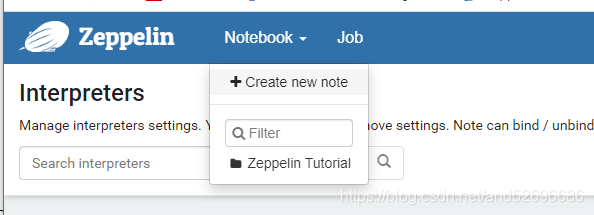
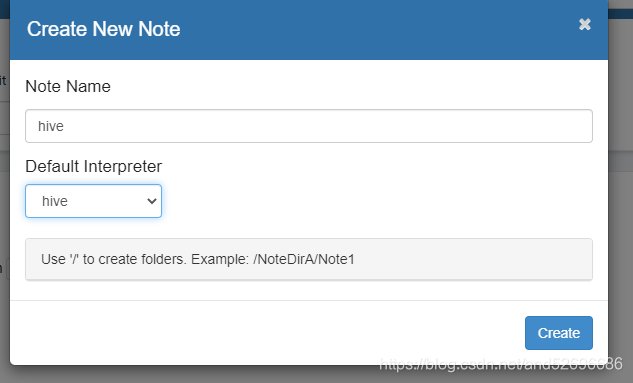
在zepplin中,点击notebook,通过create new note创建一个notebook.
其中name可以任意,Default Interpreter选择hive
2.验证hive解释器
注意,zepplin中操作hive不能有分号
%hive
show databases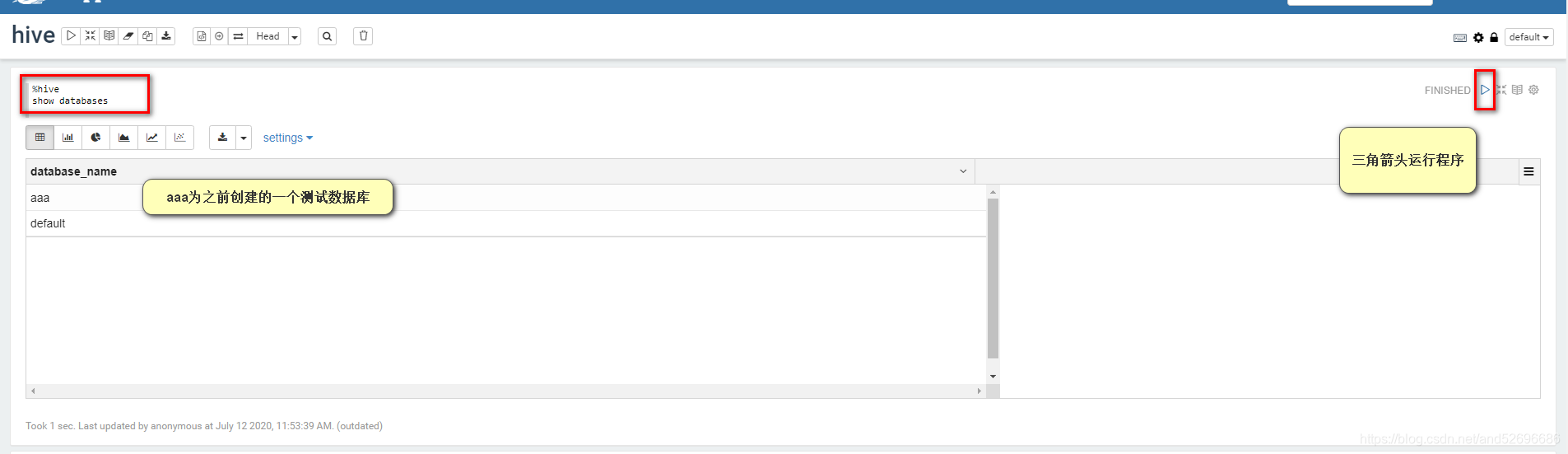
继续测试
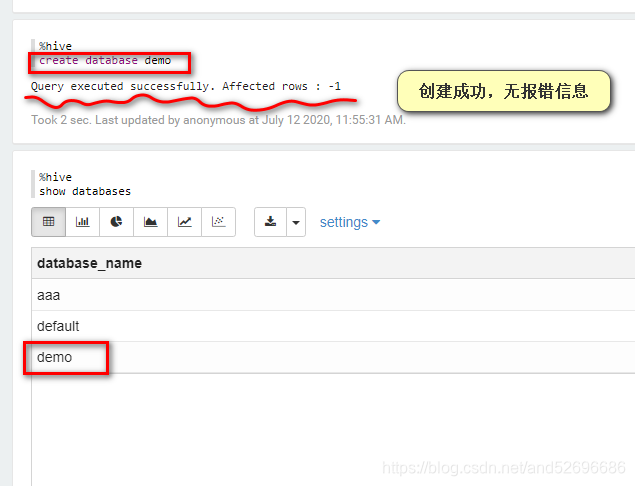
以上测试无报错信息,说明zeppelin连接hive成功!
本文来自博客园,作者:大码王,转载请注明原文链接:https://www.cnblogs.com/huanghanyu/

 posted on
posted on










【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具