
Zeppelin是什么?
1.1 概述
Zeppelin是基于 Notebook技术开发的大数据交互分析服务软件,可以基于Web界面组合多个大数据分析引擎的处理能力,并内置提供了基于Web的可视化界面,可以连接几乎所有的Apache大数据处理服务系统。
1.2 功能
Zeppelin可以满足你的数据接入、数据挖掘、数据分析、数据可视化及协同开发的需求。
1.2.1数据可视化
一些基本图表都已经包含在zeppelin。可视化不限于sparksql查询,任何语言的任何输出端可以被识别和可视化。如图1-2-1
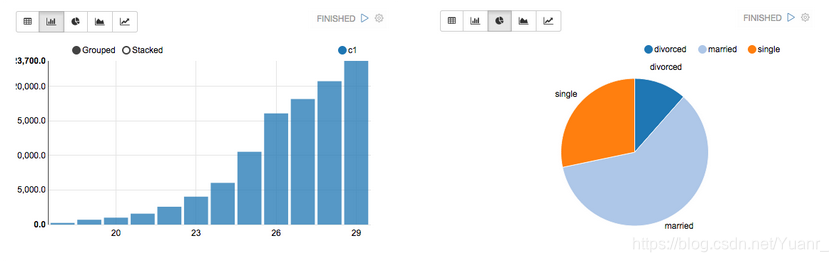 图1-2-1
图1-2-1
1.2.2 数据透视表
zeppelin采用简单的拖放方式对数据进行聚合并生成数据透视表图表。并且可以创建包括求和、计数、平均、最小值、最大值等多个值的集合的数据透视图表。如图1-2-2
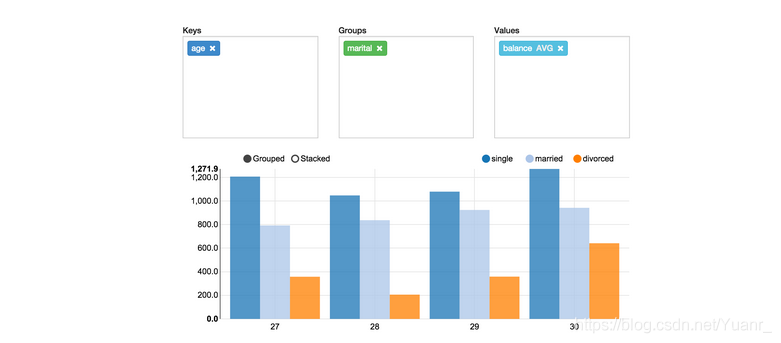
图1-2-2
1.2.3 动态表单
Zeppelin可以动态地创建一些表格。如图1-2-3
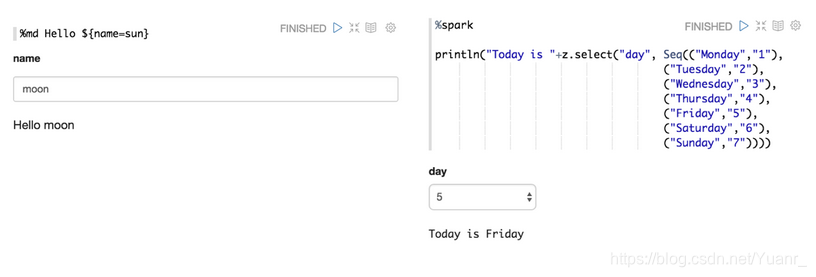 图1-2-3
图1-2-3
1.2.4 协同开发
通过共享NoteBook的URL,你可以和你的朋友协同开发,Zeepelin会实时同步NoteBook的任何改动。
Zeppelin提供只显示该结果URL。可以通过iframe嵌入您的网页。
1.3支持的语言
Zeppelin interpreter(Zeppelin解析器)概念上允许任何语言及数据接口接入,目前zeppelin支持诸如Spark,Python,JDBC,Markdown和shell等多门语言解析器。如图1-3-1

图1-3-1
2. Zeeplin下载与安装
注:本文采用的是centos6.9,zeppelin-0.8.0,jdk1.8
2.1下载
①在win浏览器下打开 http://zeppelin.apache.org/download.html,选择

进行下载,下载完成之后通过pscp等工具将zeppelin-0.8.0-bin-all.tgz拷贝到
Centos的/opt 目录下
②采用wget下载
$ wget http://mirror.bit.edu.cn/apache/zeppelin/zeppelin-0.8.0/zeppelin-0.8.0-bin-all.tgz
注:
zeppelin-0.8.0-bin-netinst.tgz 默认只会提供Spark的Interpreter
zeppelin-0.8.0-bin-all.tgz 会提供各种各样的Interpreter(MySQL,ElasticSearch等等)
本文使用的是zeppelin-0.8.0-bin-all.tgz
③采用命令 $ tar –zxvf zeppelin-0.8.0-bin-all.tgz 进行解压
$ mv zeppelin-0.8.0-bin-all zeepelin 重命名
2.2 安装与配置
①请按下述命令操作
$ vim /etc/profile
#在文件末尾添加如下内容
#zeppelin
export ZEPPELIN_HOME=/opt/zeppelin
export PATH=ZEPPELIN_HOME/bin
$ cd /opt/zeppelin/conf/
#修改配置文件
$ cp zeppelin-site.xml.template zeppelin-site.xml
#默认服务器ADDR是0.0.0.0,端口8080 ,可自行修改下述配置
<property>
<name>zeppelin.server.addr</name>
<value>0.0.0.0</value>
<description>Server address</description>
</property>
<property>
<name>zeppelin.server.port</name>
<value>8080</value>
<description>Server port.</description>
</property>
#修改zeepelin的环境变量
$ cp zeppelin-env.sh.template zeppelin-env.sh
#添加hadoop与jdk环境
export JAVA_HOME=/usr/java/jdk1.8.0_181
export HADOOP_CONF_DIR=/opt/hadoop/etc/Hadoop
$ vim ./zeppelin-env.sh
#开启zeppelin
$ zeppelin-daemon.sh start
Zeppelin start [ OK ]
#查看zeppelin的状态
$ zeppelin-daemon.sh status
zeppelin-daemon.sh status
Zeppelin is running [ OK ]
#关闭zeppelin
$ zeppelin-daemon.sh stop
Zeppelin stop [ OK ]
②启动zepplin之后,在浏览器地址栏键入 http://主机IP:端口号 (如果zeppelin-site.xml未修改,默认为http://主机IP:8080)
当你看到如下界面,恭喜你配置成功!
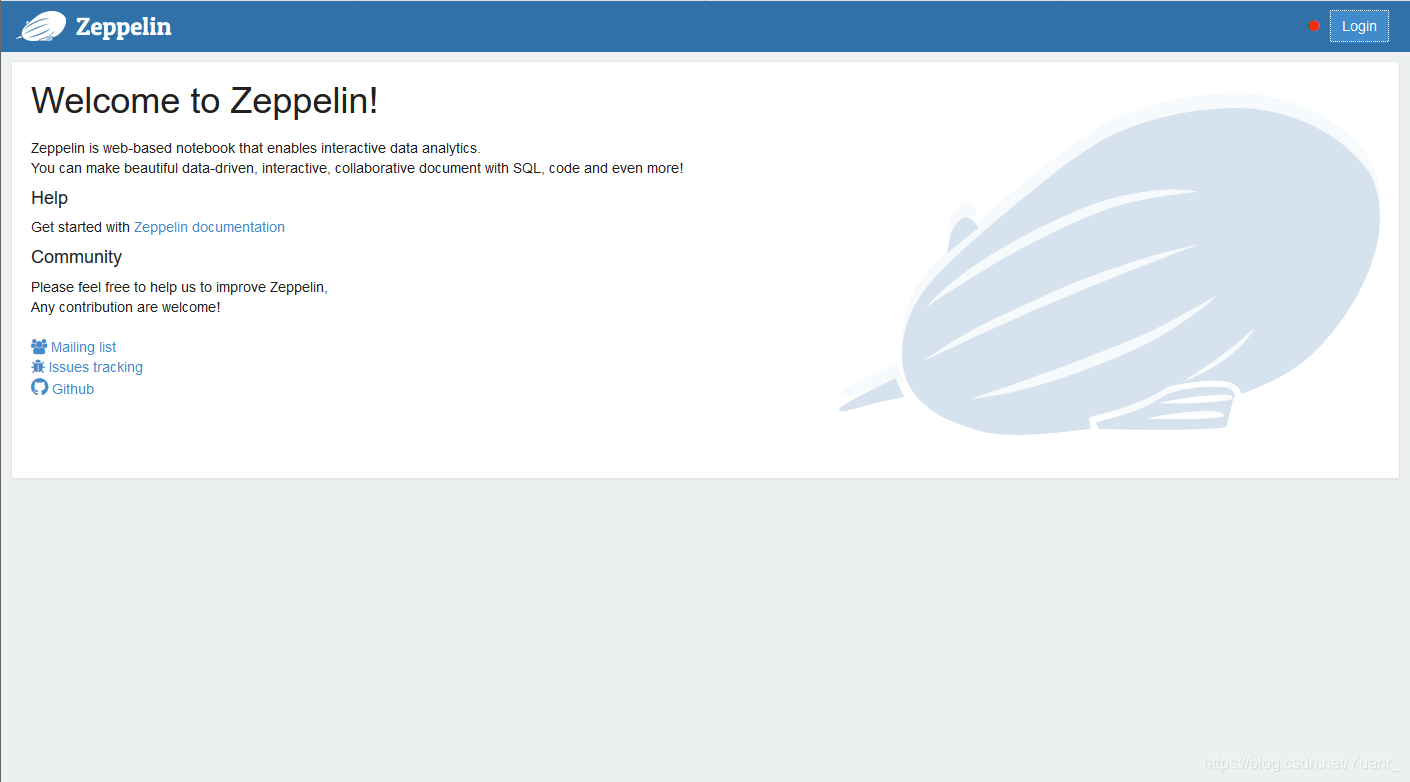
3. Interperter解析器配置与使用
Zeppelin的后台数据引擎可以是Spark(目前只支持Spark),开发者可以通过实现更多的解析器来为Zeppelin添加数据引擎,官方支持的解析器请见图1-3-1;
Notebook中记录了我们的业务代码(如:hql,sql,sparksql等)及数据显示依据(key,group,value等,下文会对这部分详解);
执行引擎的作用是执行NoteBook中的对应的代码,下面我们将讲述部分解析器的配置及其使用。
3.1 mysql解析器配置
①如图3-1-1 点击右上用户名选择‘Interperter’;
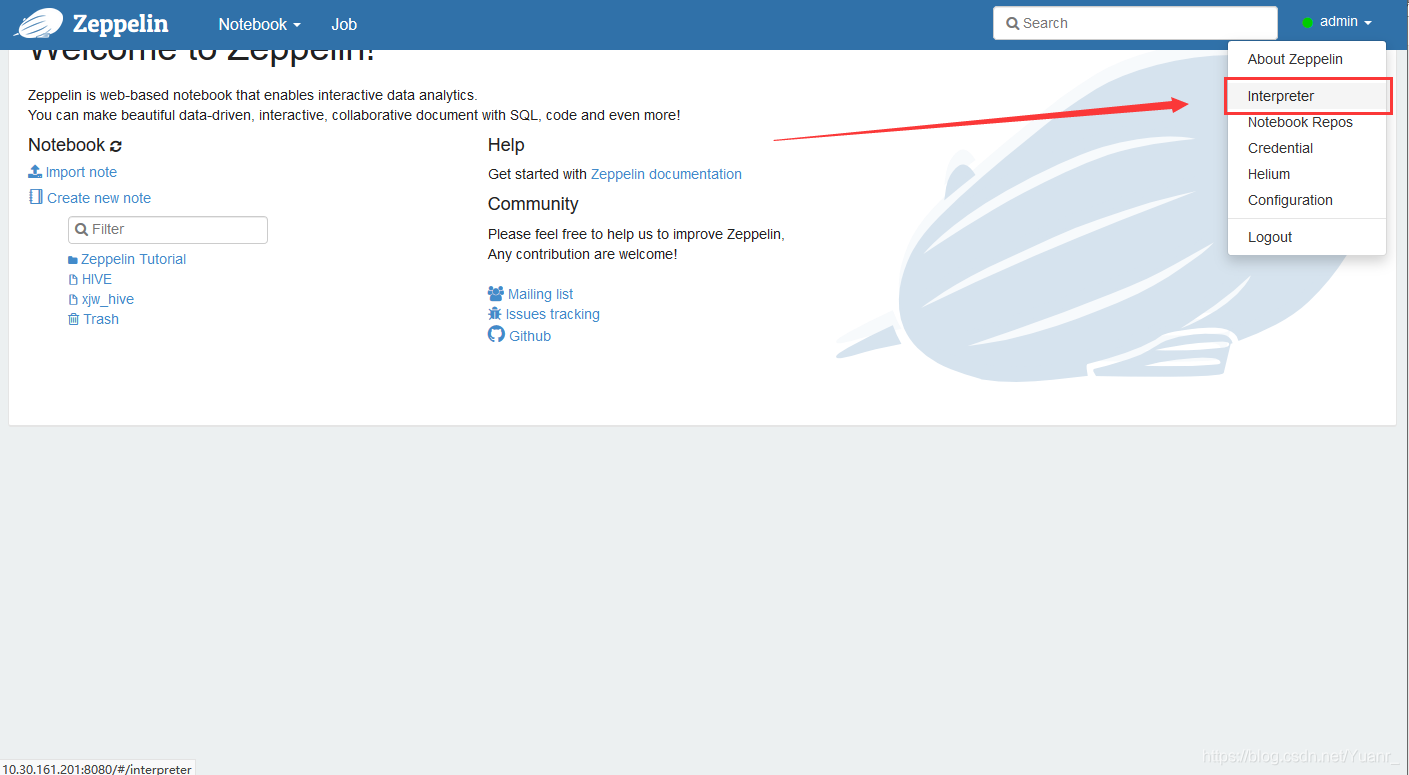
图3-1-1
②如图3-1-2 点击右上‘Create’,按照图3-1-3进行配置,配置完成保存。至此,我们的mysql的解析器配置完成,
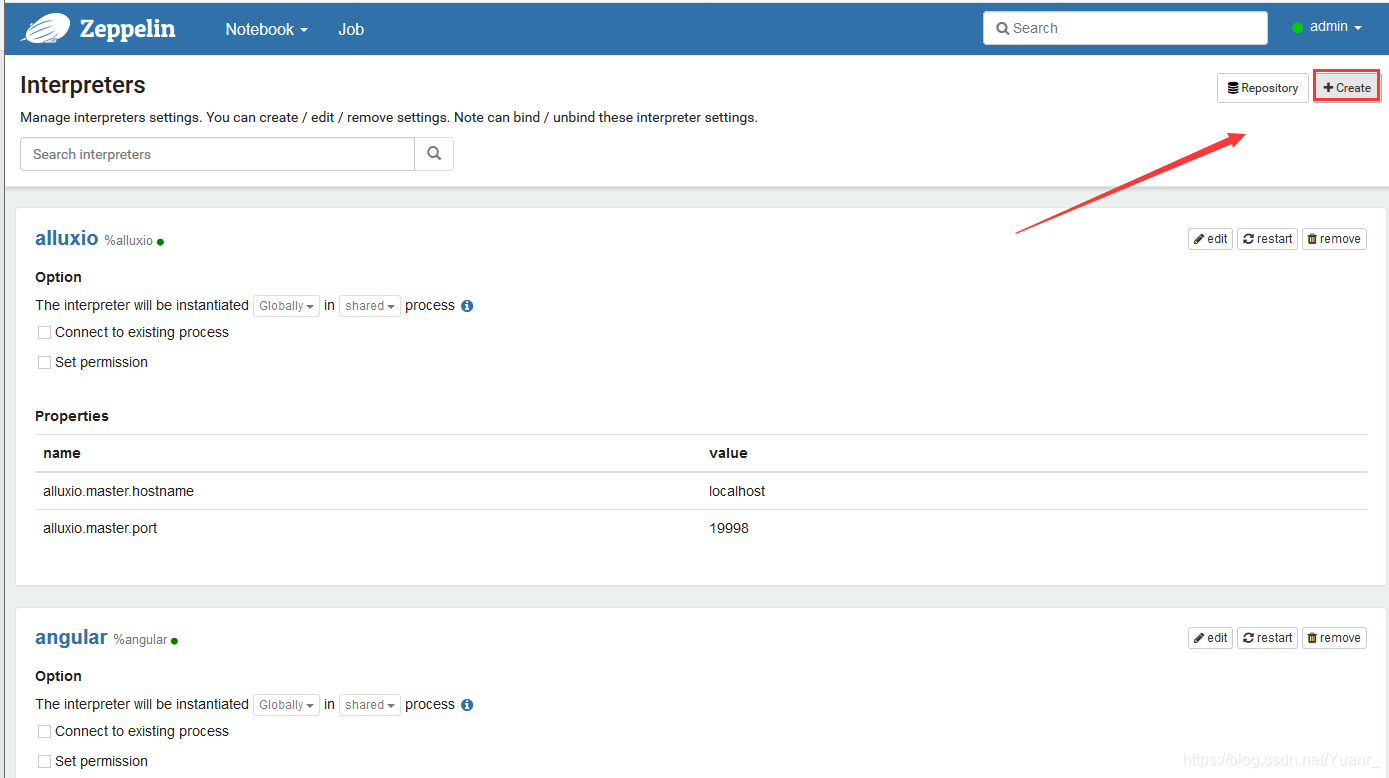
图3-1-2
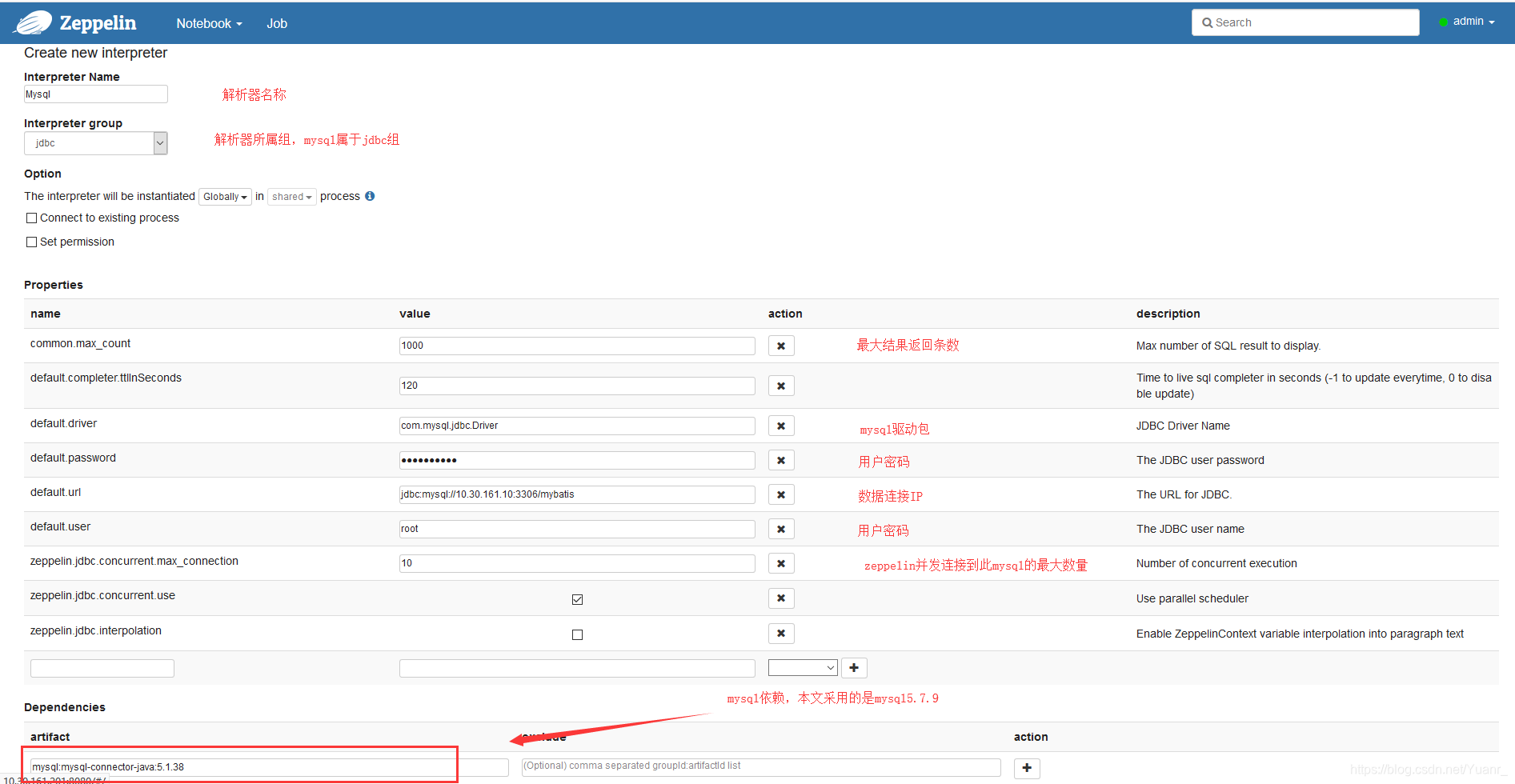
图3-1-3
3.2 mysql解析器使用
①首先我们新建一个NoteBook:点击网页顶部的‘notebook’,选择‘Create new note’如图3-2-1,填写弹窗信息,如图3-2-2;
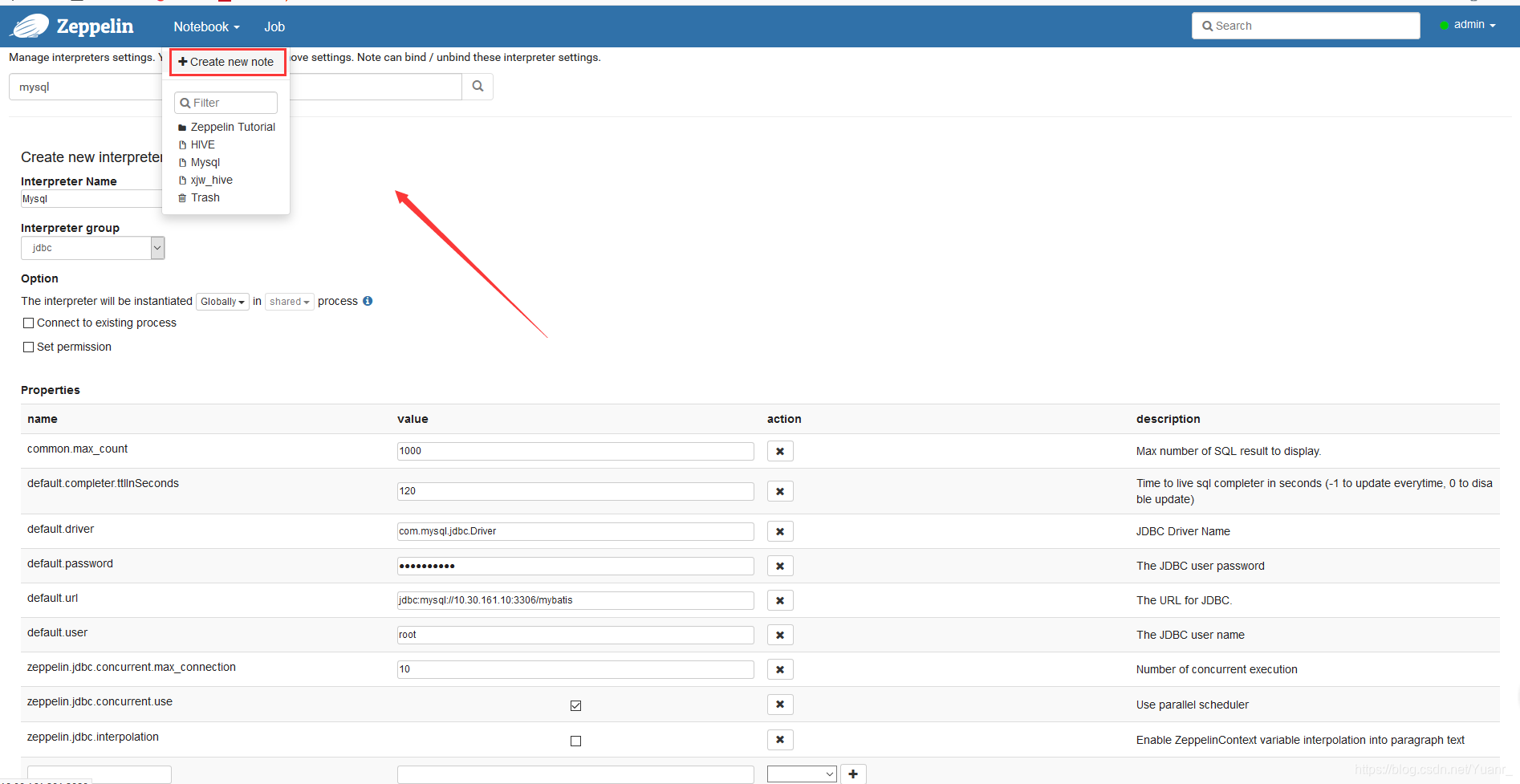
图3-2-1
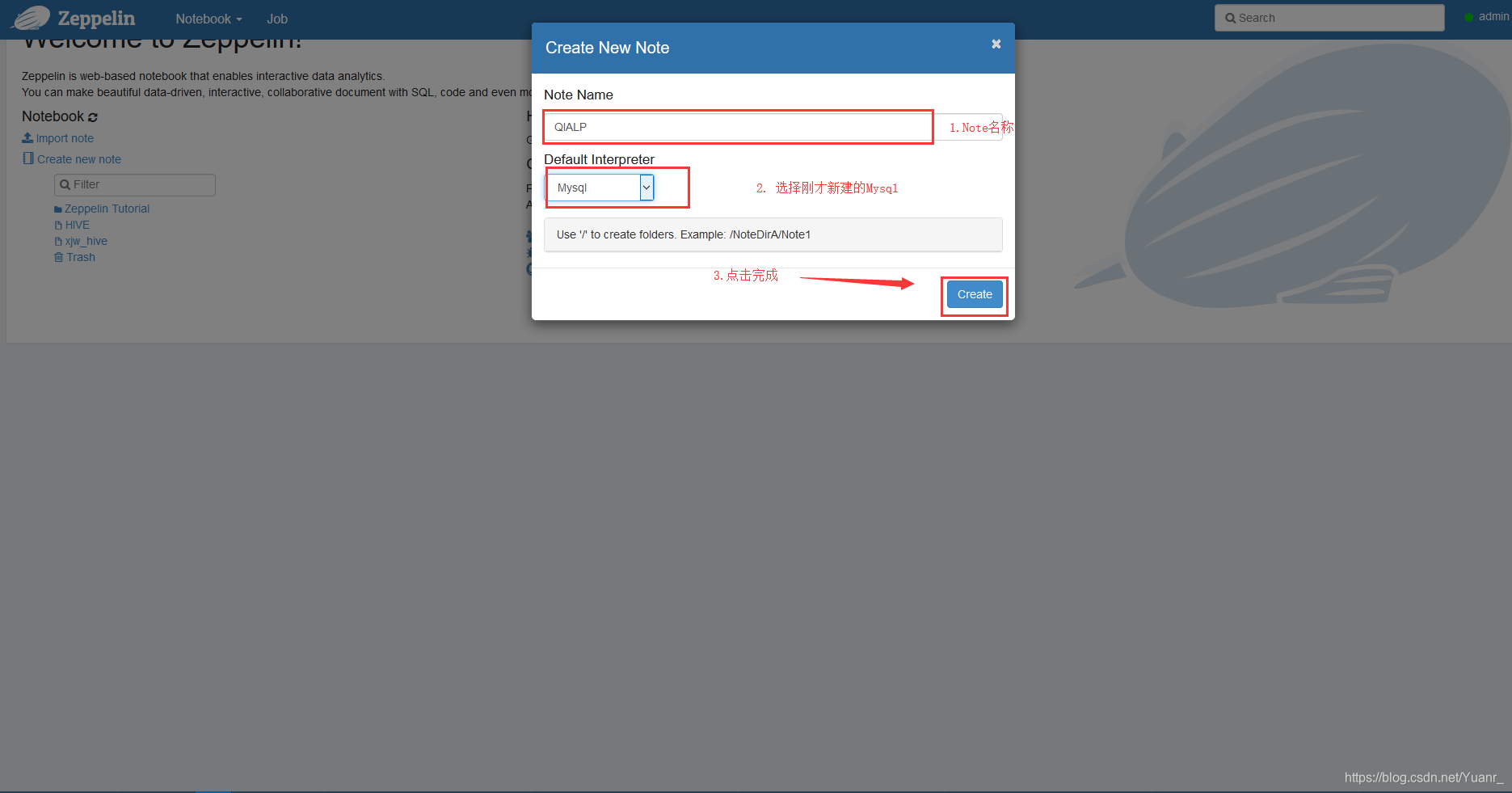
图3-2-2
②在Notebook中新建一条记录,填写的业务代码(图3-1-6 步骤1)运行并查看结果,如图3-2-3;
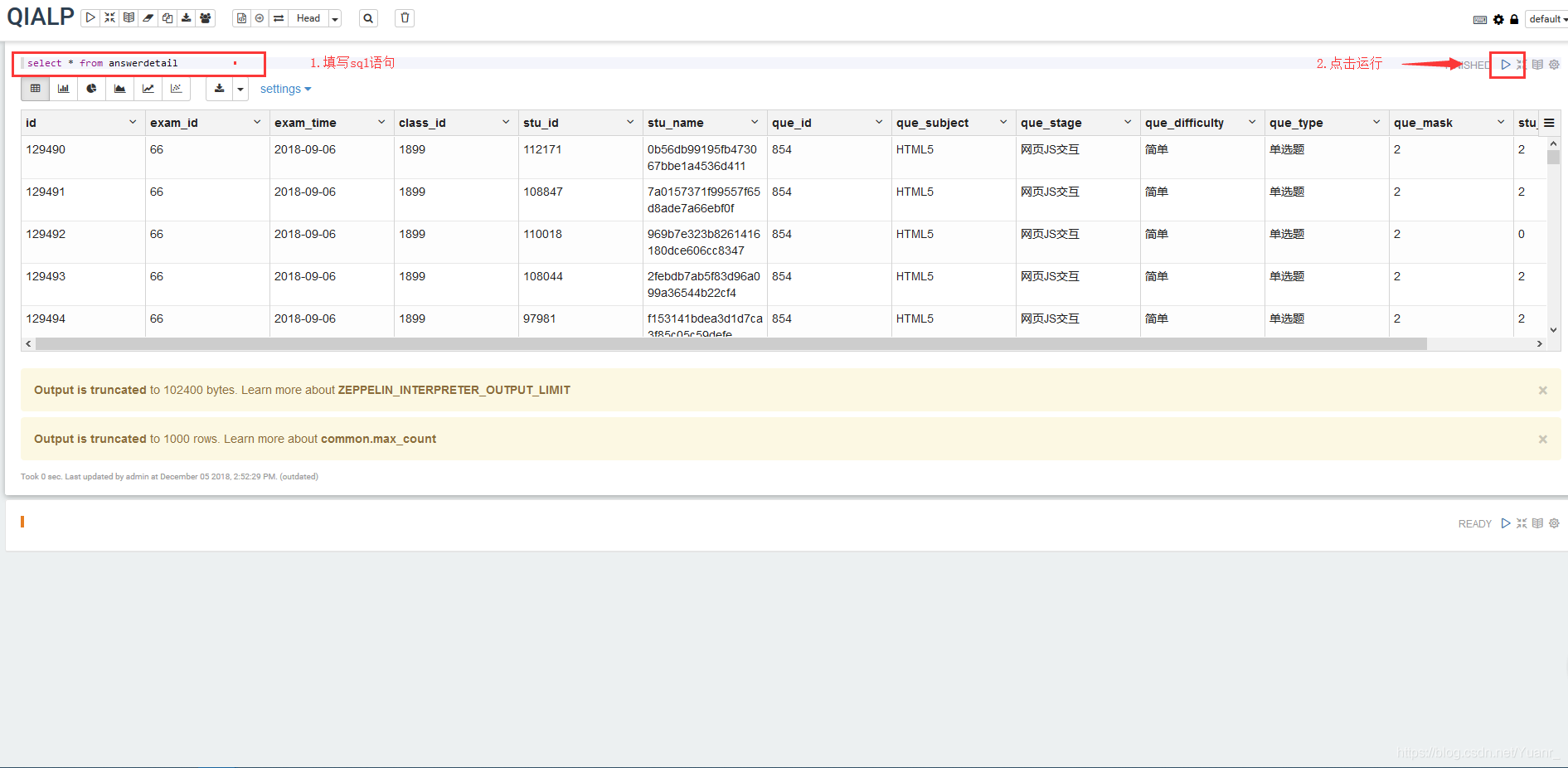
图3-2-3
③ 自定义显示图表信息,如图3-2-4。
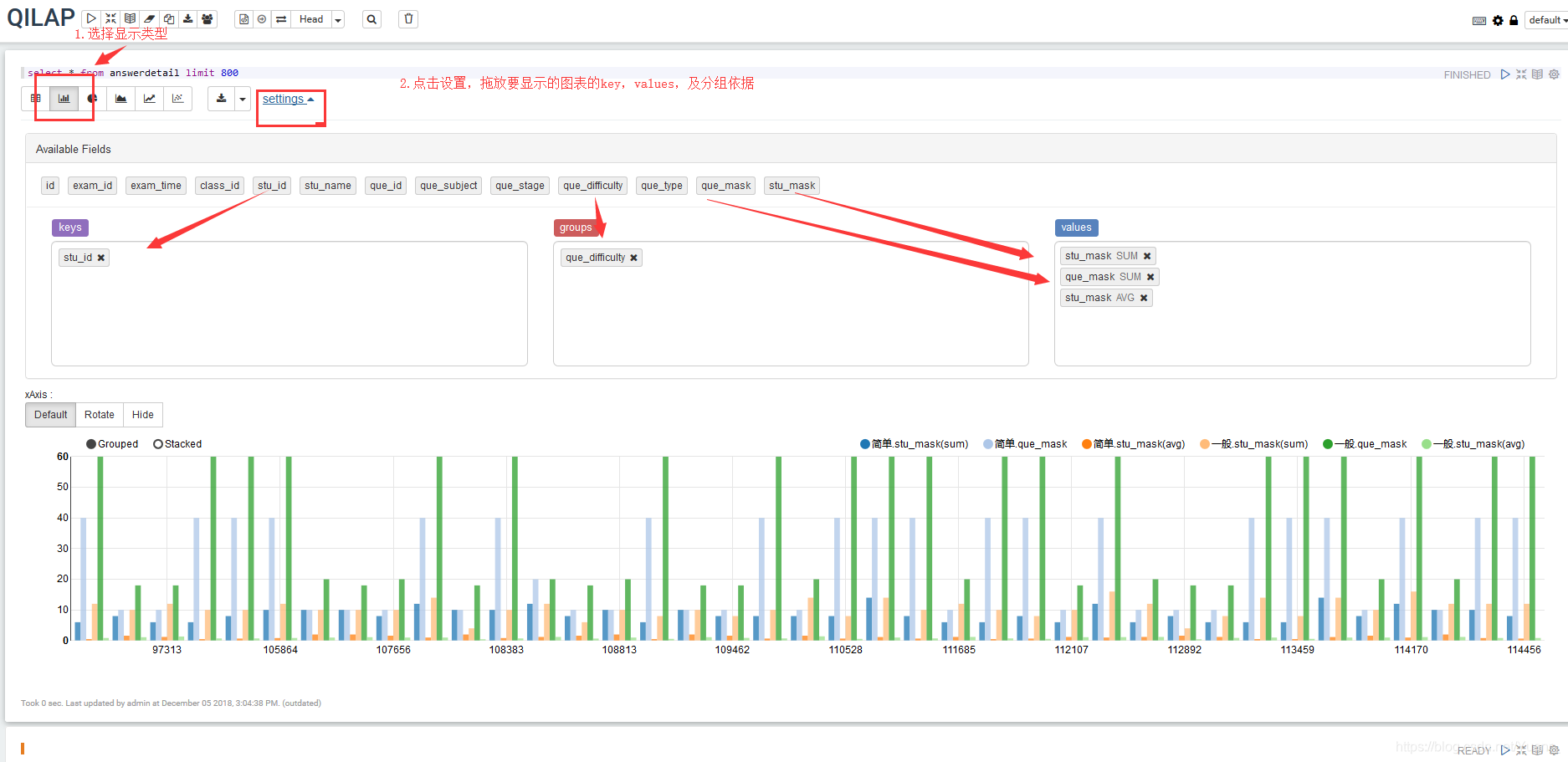
图3-2-4
③keys是指横坐标轴要显示的数据,当多个key并存时,所有key会做笛卡尔积,产生key1[0].key2[0].key3[0].······,key1[0].key2[1].key[0].······,,key1[0].key2[1].key[2].······如图3-2-5
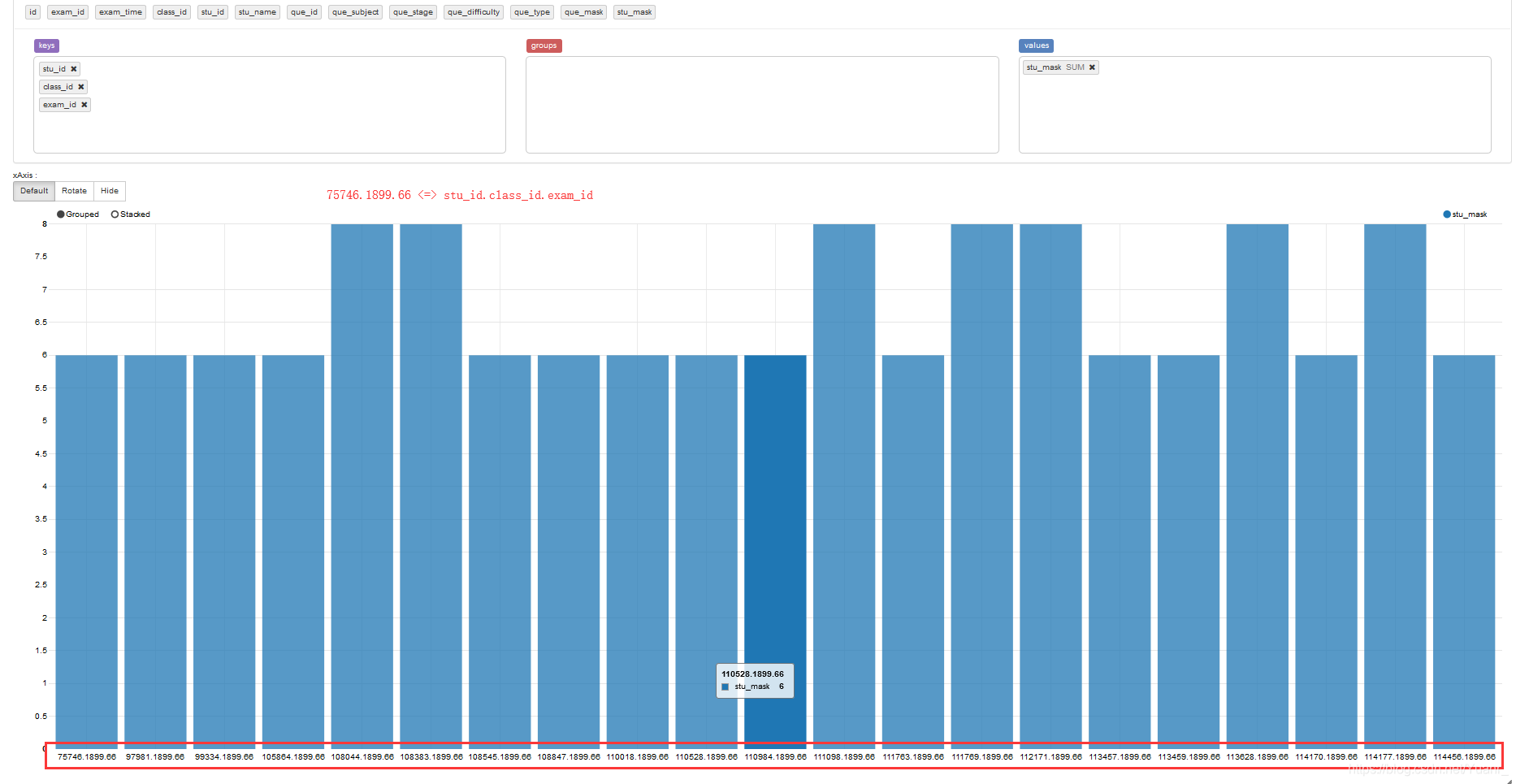
图3-2-5
④ values是纵坐标所要显示的数据,与它key对应,当存在多个value时,一个key对应多个value(key与value的关系是1:n)。value可选属性有max,min,sum,count,avg。如图3-2-6
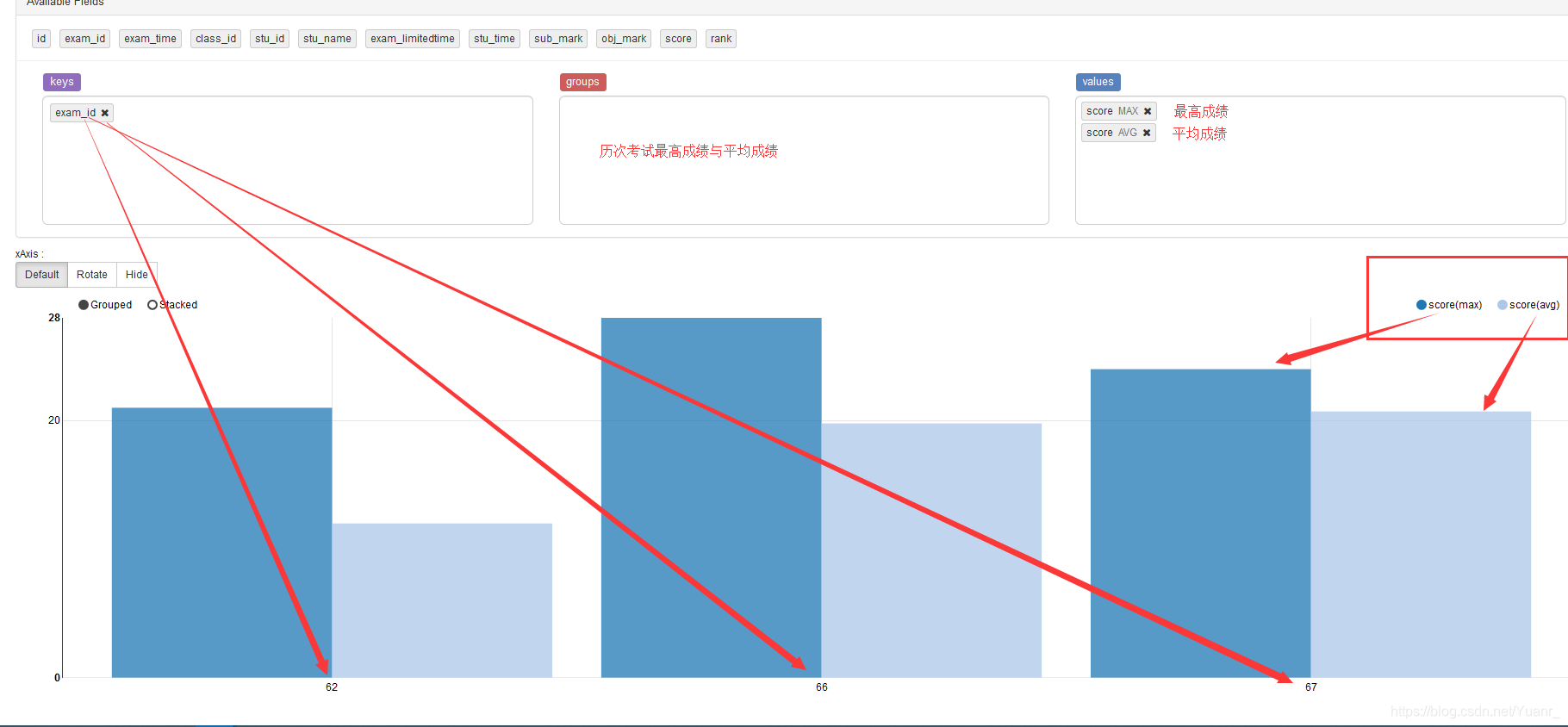
图3-2-6
⑤groups 根据group内容对value再次分组,当存在多个group时 ,value为
Group1[0].group2[0].······.value, Group1[0].group2[1].······.value
, Group1[0].group2[2].······.value,······。如图3-2-7、图3-2-8
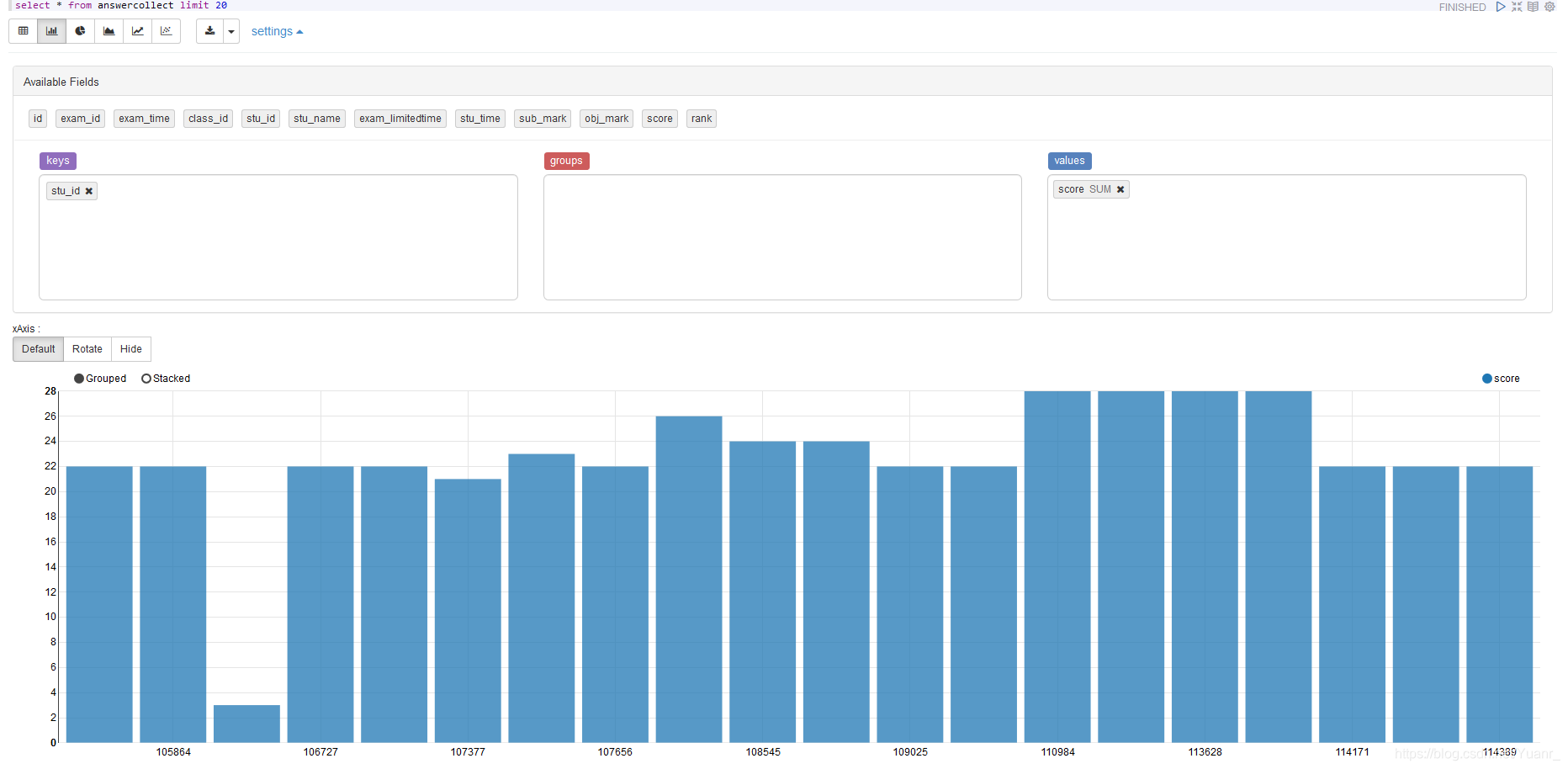
图3-2-7
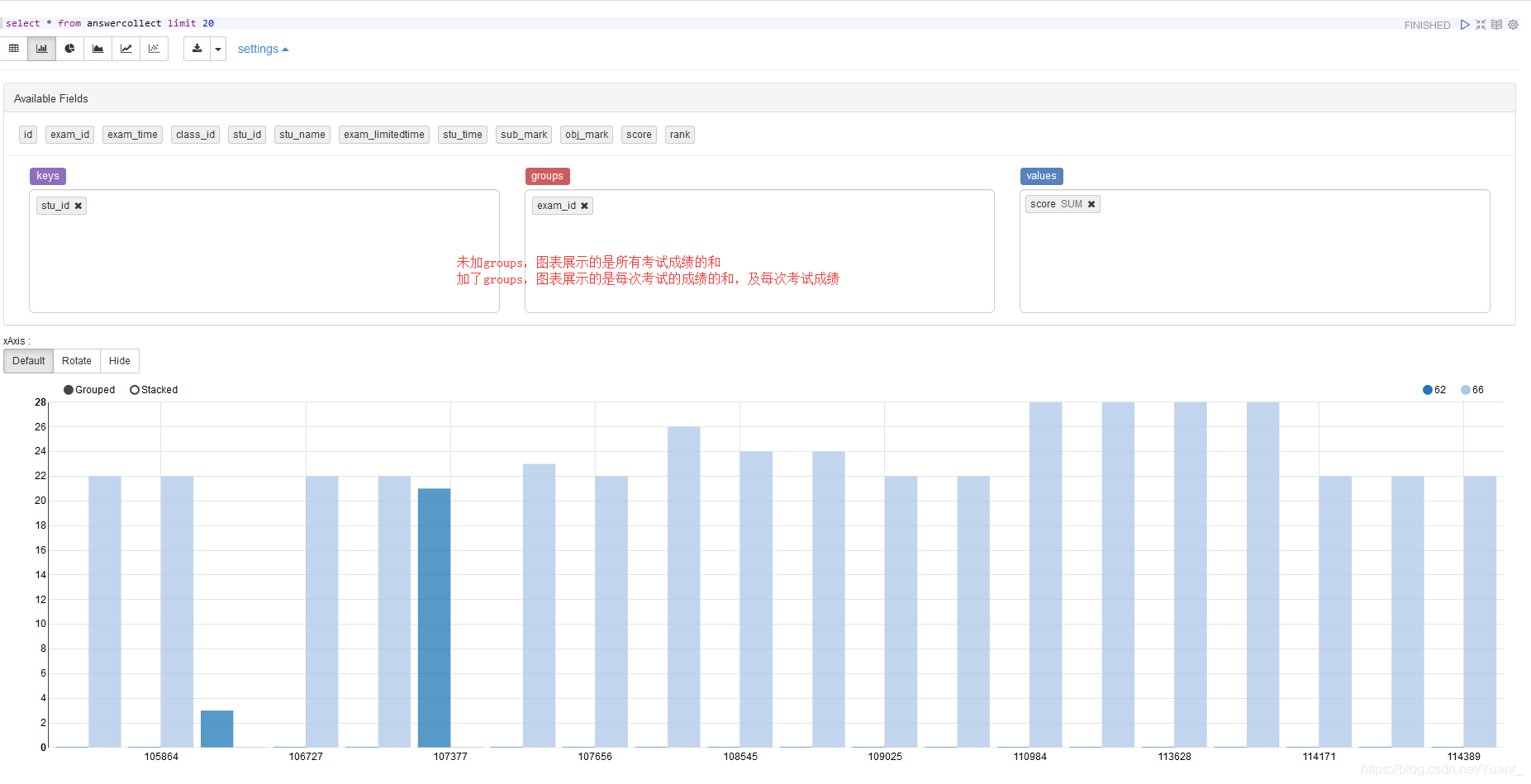
图3-2-8
本文来自博客园,作者:大码王,转载请注明原文链接:https://www.cnblogs.com/huanghanyu/

 posted on
posted on










【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具