
一、电商业务简介
1.1 电商业务流程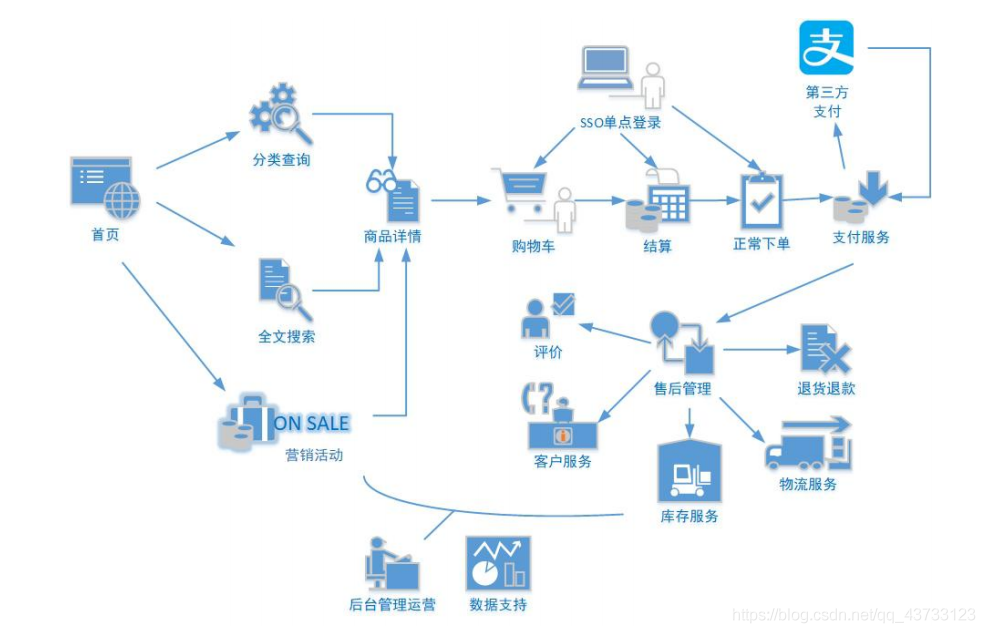
1.2 电商常识(SKU、SPU)
SKU=Stock Keeping Unit(库存量基本单位)。现在已经被引申为产品统一编号的简称,每种产品均对应有唯一的 SKU 号
SPU(Standard Product Unit):是商品信息聚合的最小单位,是一组可复用、易检索的标准化信息集合
例如:iPhoneX 手机就是 SPU。一台银色、128G 内存的、支持联通网络的 iPhoneX,就是 SKU
SPU 表示一类商品。好处就是:可以共用商品图片,海报、销售属性等
1.3 电商业务表结构
电商表结构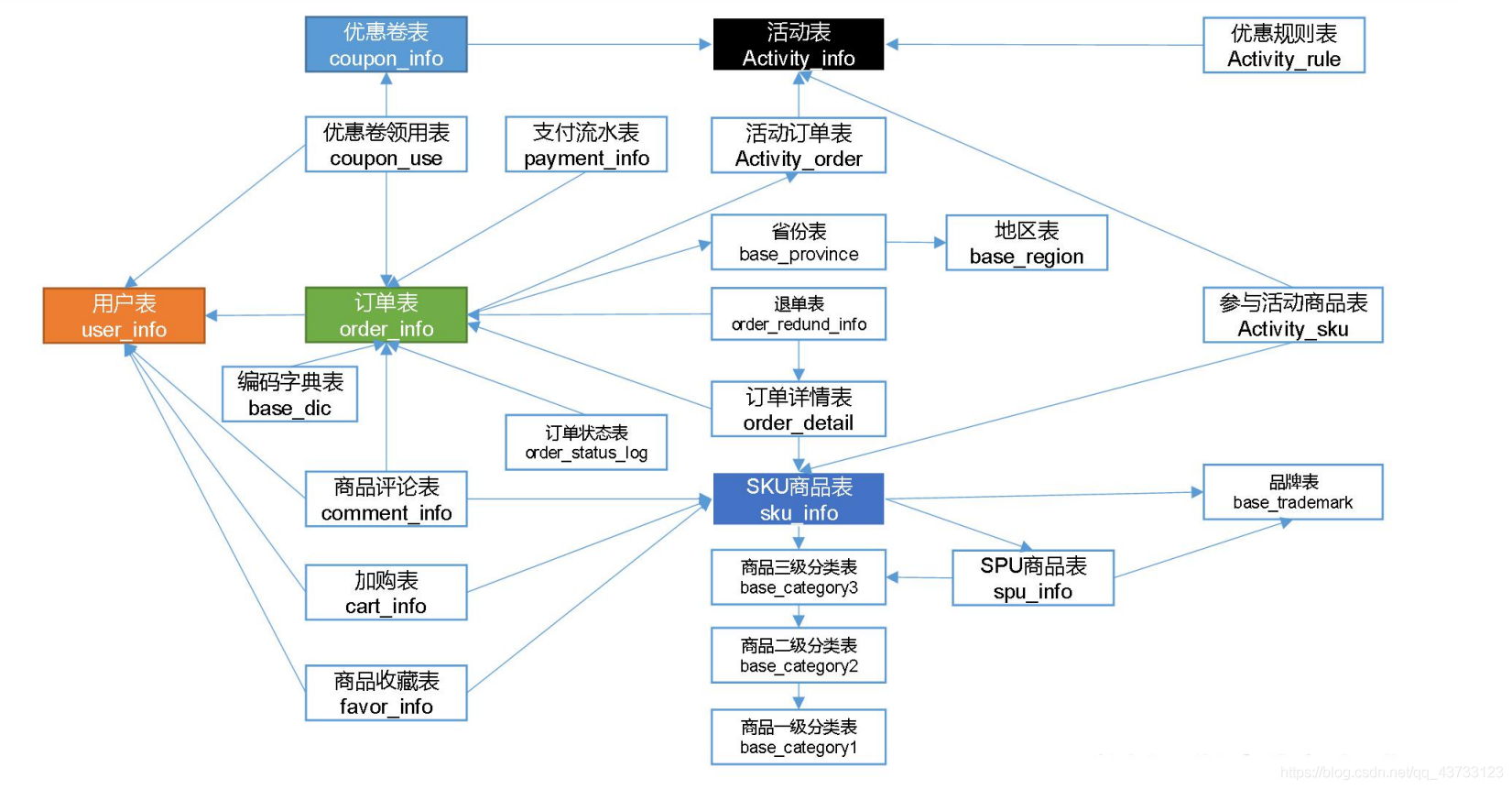
1.3.1 订单表(order_info)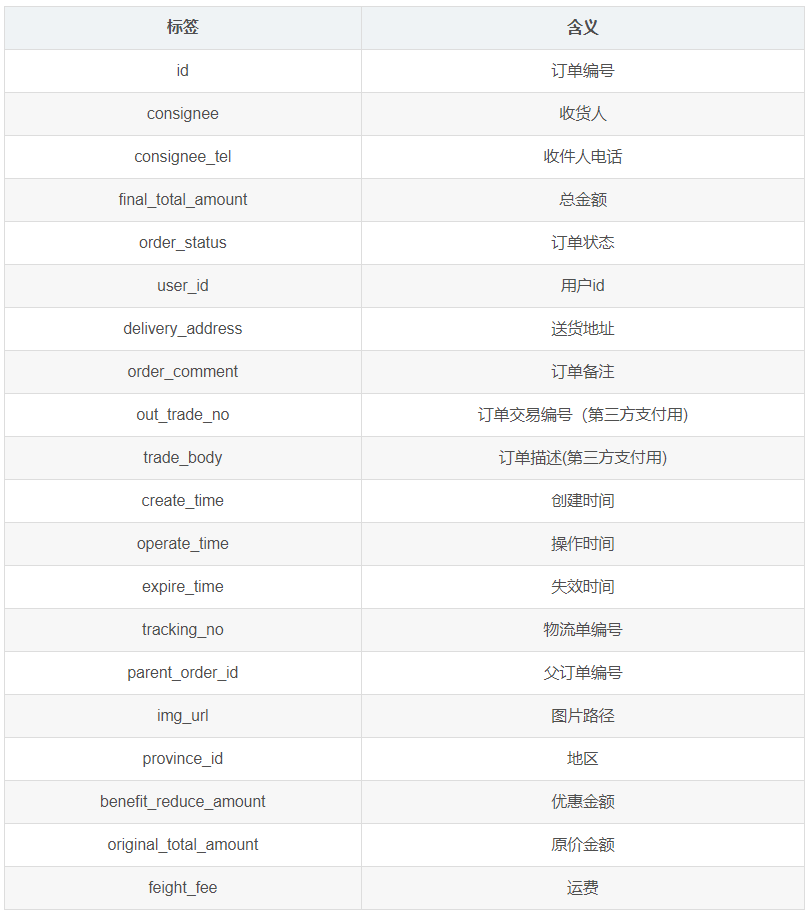
1.3.2 订单详情表(order_detail)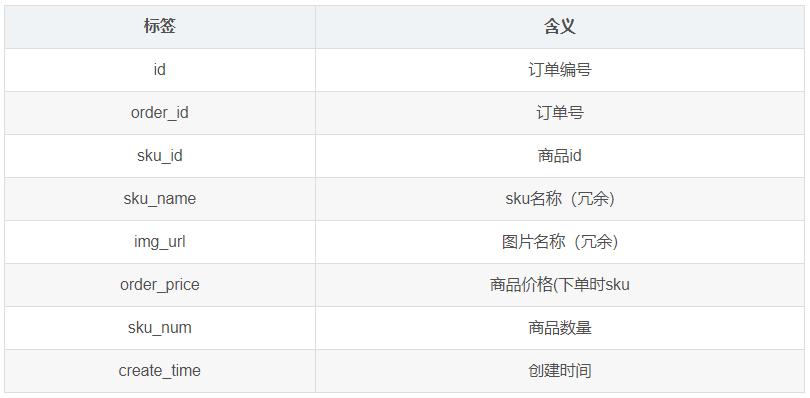
1.3.3 SKU 商品表(sku_info)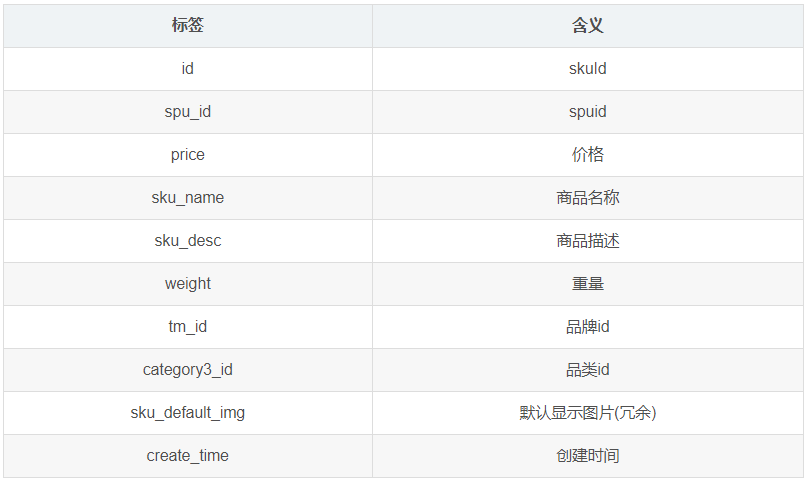
1.3.4 用户表(user_info)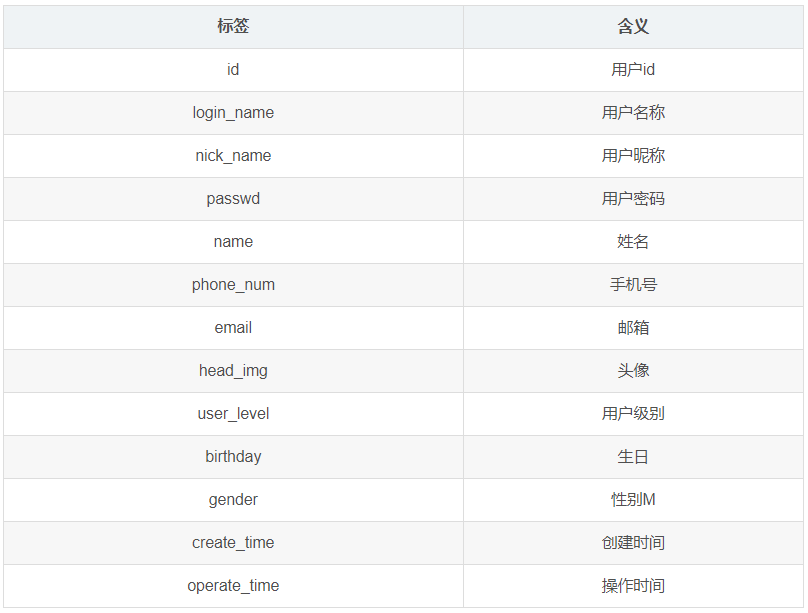
1.3.5 商品一级分类表(base_category1)
1.3.6 商品二级分类表(base_category2)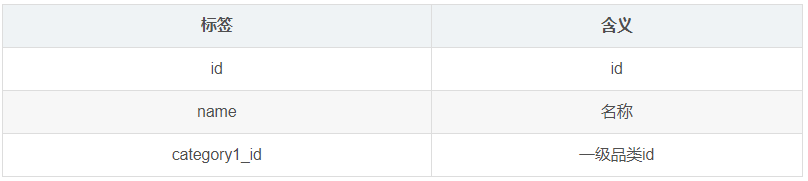
1.3.7 商品三级分类表(base_category3)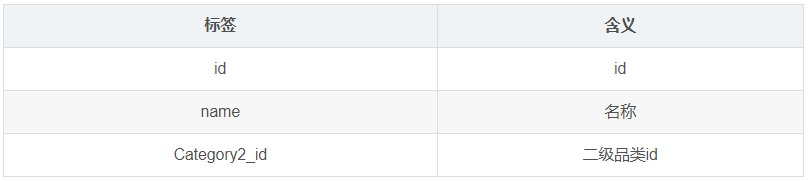
1.3.8 支付流水表(payment_info)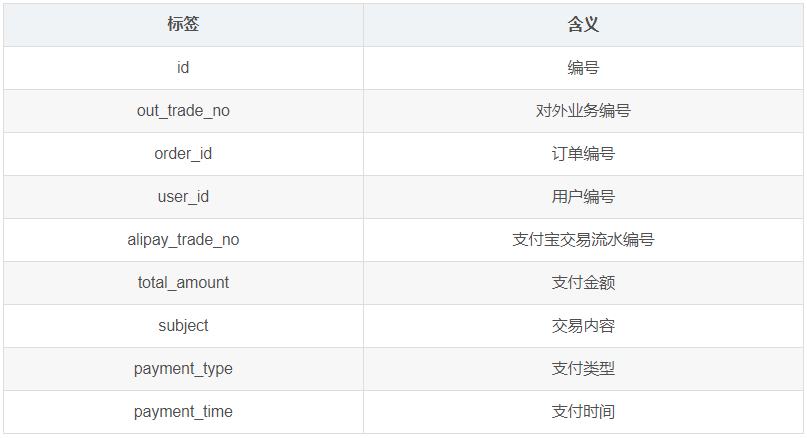
1.3.9 省份表(base_province)
1.3.10 地区表(base_region)
1.3.11 品牌表(base_trademark)
1.3.12 订单状态表(order_status_log)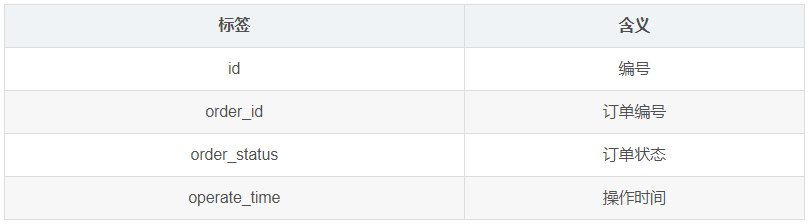
1.3.13 SPU 商品表(spu_info)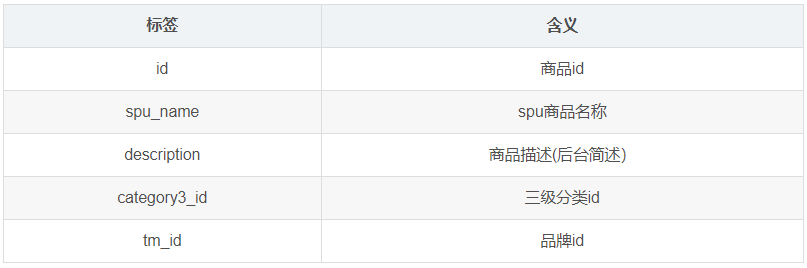
1.3.14 商品评论表(comment_info)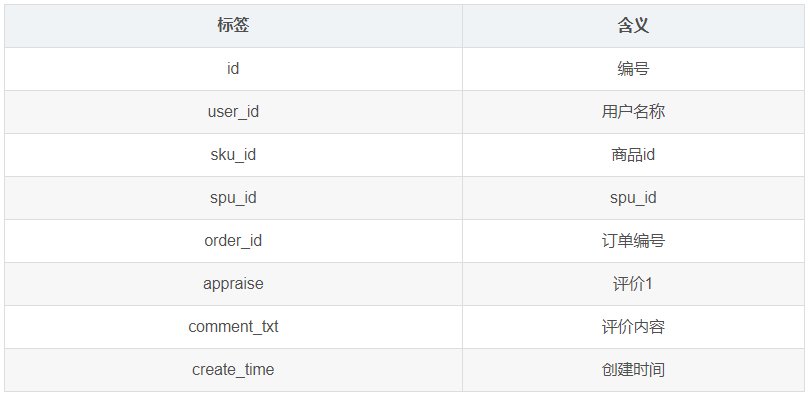
1.3.15 退单表(order_refund_info)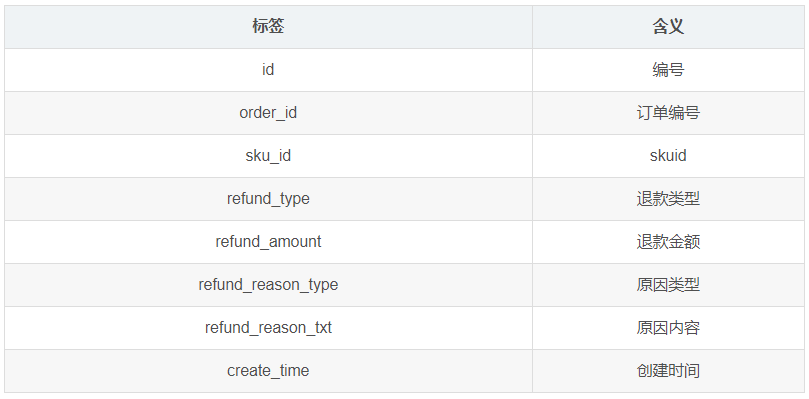
1.3.16 加购表(cart_info)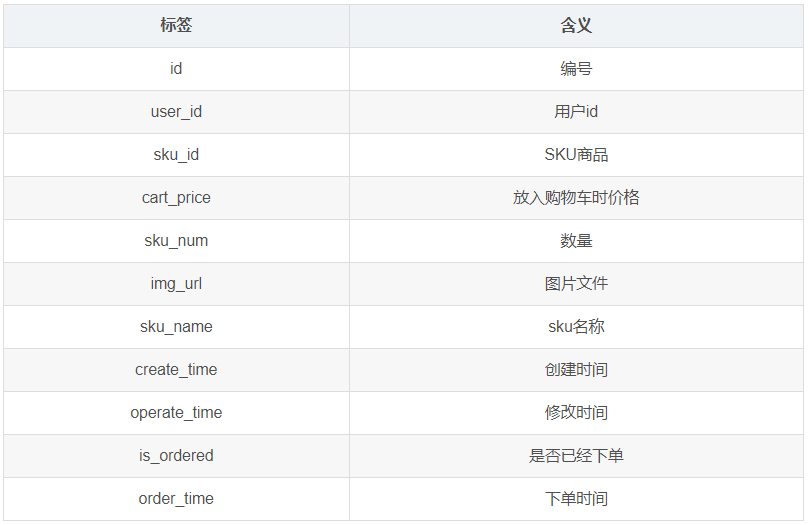
1.3.17 商品收藏表(favor_info)
1.3.18 优惠券领用表(coupon_use)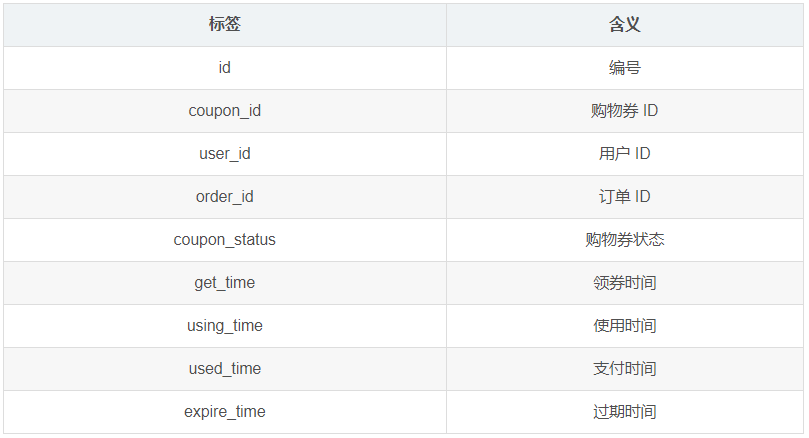
1.3.19 优惠券表(coupon_info)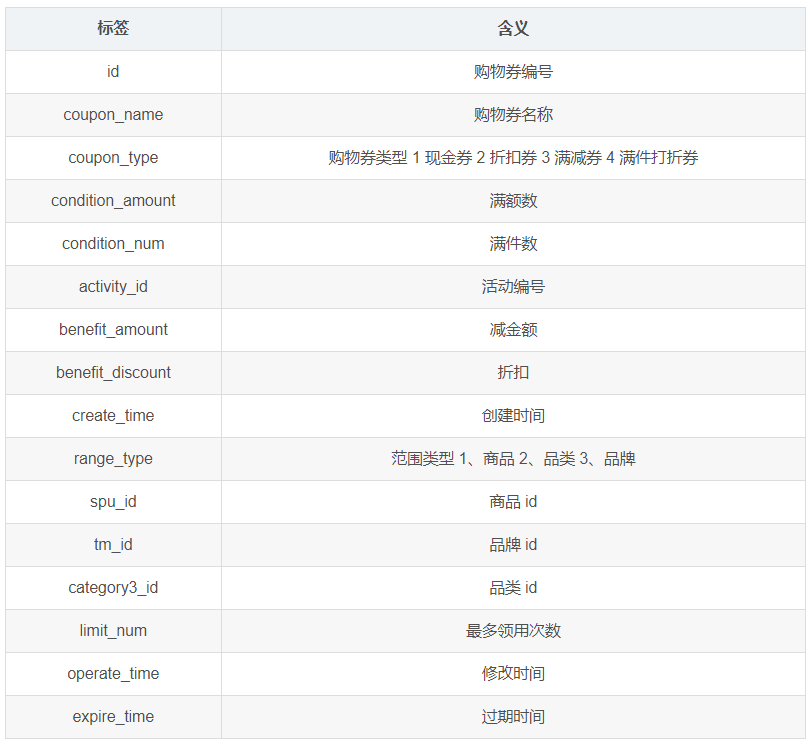
1.3.20 活动表(activity_info)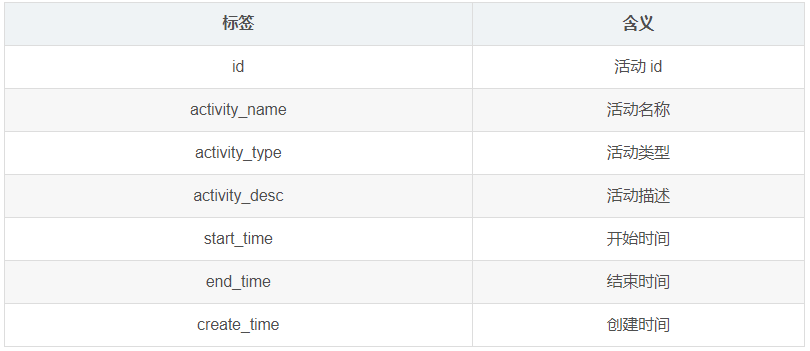
1.3.21 活动订单关联表(activity_order)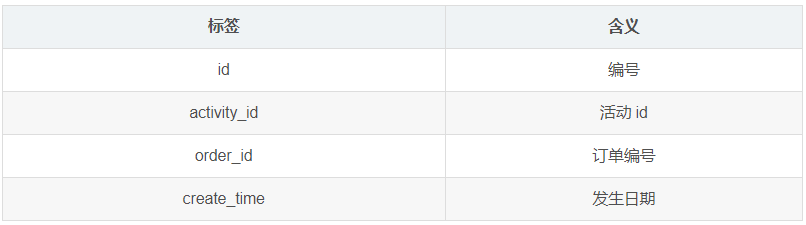
1.3.22 优惠规则表(activity_rule)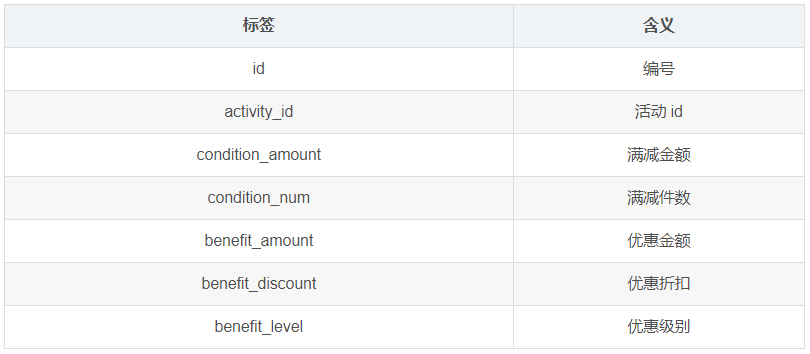
1.3.23 编码字典表(base_dic)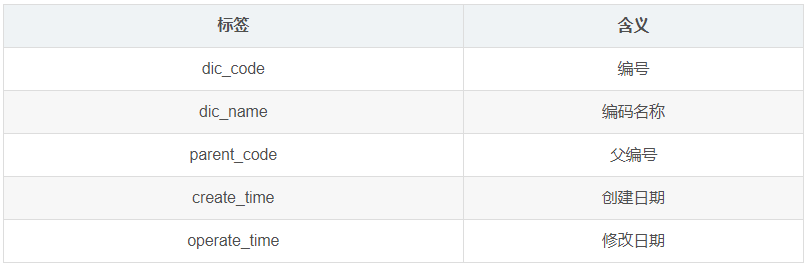
1.3.24 活动参与商品表(activity_sku)(暂不导入)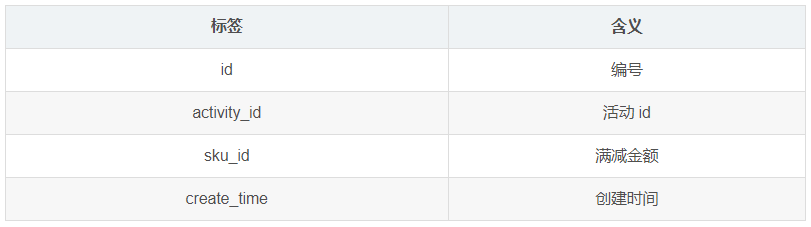
1.4 时间相关表
1.4.1 时间表(date_info)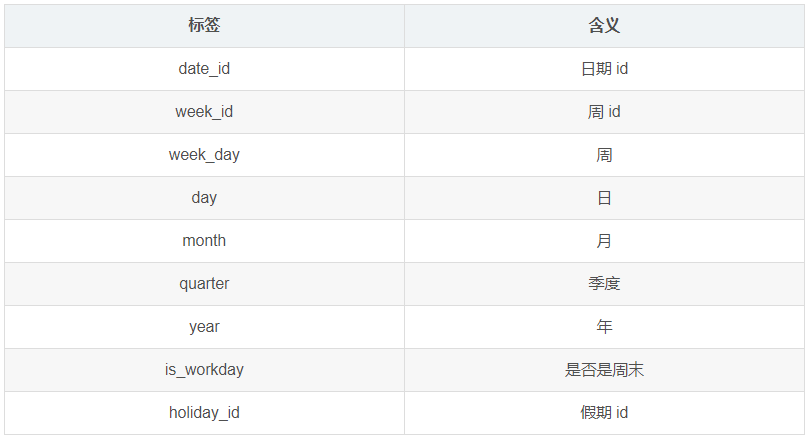
1.4.2 假期表(holiday_info)
1.4.3 假期年表(holiday_year)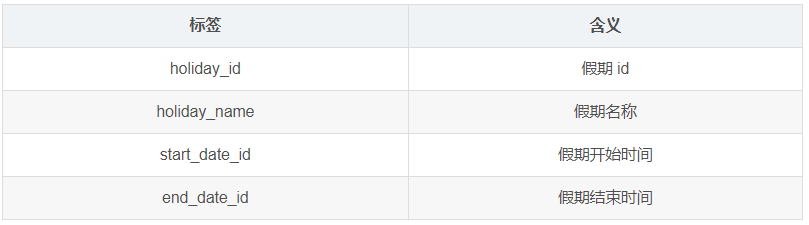
二、业务数据采集模块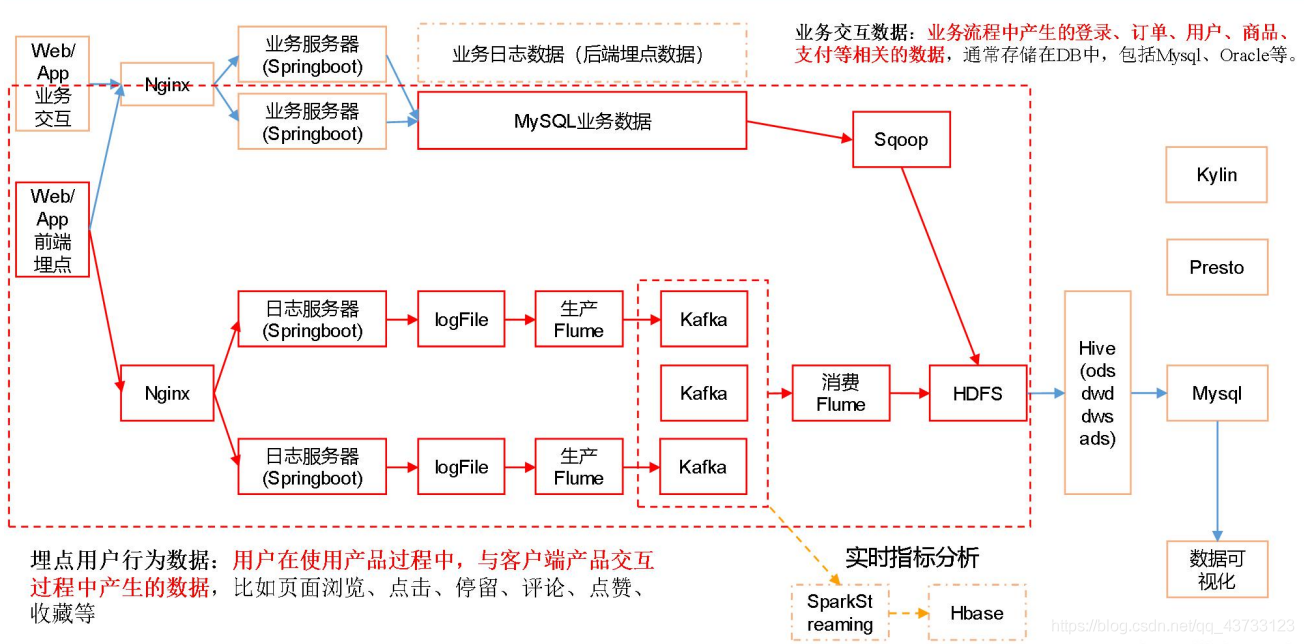
2.1 MySQL 安装
MySQL详细安装步骤请点击博客【Linux】MySQL安装
前提:务必使用root用户安装
2.1.1 安装包准备
需要使用的安装包为:mysql-libs.zip
1)查看 MySQL 是否安装,如果安装了,卸载 MySQL
[zsy@node01 ~]$ rpm -qa | grep mysql
mysql-libs-5.1.73-8.el6_8.x86_64
[zsy@node01 ~]$ su root
密码:
[root@node01 zsy]# rpm -e --nodeps mysql-libs-5.1.73-8.el6_8.x86_64
[root@node01 zsy]# rpm -qa | grep mysql
[root@node01 zsy]# 2)解压 mysql-libs.zip 文件到当前目录
[root@node01 software]# unzip mysql-libs.zip
Archive: mysql-libs.zip
creating: mysql-libs/
inflating: mysql-libs/MySQL-client-5.6.24-1.el6.x86_64.rpm
inflating: mysql-libs/mysql-connector-java-5.1.27.tar.gz
inflating: mysql-libs/MySQL-server-5.6.24-1.el6.x86_64.rpm 3)进入到 mysql-libs 文件夹下
[root@node01 software]# ll
总用量 75992
drwxr-xr-x 2 root root 4096 6月 26 2015 mysql-libs
-rw-rw-r-- 1 zsy zsy 77807942 3月 3 2017 mysql-libs.zip
[root@node01 software]# cd mysql-libs
[root@node01 mysql-libs]# ll
总用量 76048
-rw-r--r-- 1 root root 18509960 3月 26 2015 MySQL-client-5.6.24-1.el6.x86_64.rpm
-rw-r--r-- 1 root root 3575135 12月 1 2013 mysql-connector-java-5.1.27.tar.gz
-rw-r--r-- 1 root root 55782196 3月 26 2015 MySQL-server-5.6.24-1.el6.x86_64.rpm2.1.2 安装 MySql 服务器
1)安装 mysql 服务端
[root@node01 mysql-libs]# rpm -ivh MySQL-server-5.6.24-1.el6.x86_64.rpm 2)查看产生的随机密码
[root@node01 mysql-libs]# cat /root/.mysql_secret
# The random password set for the root user at Wed Mar 11 12:27:14 2020 (local time): Ad8YjoCm9eRhdE6Y3)查看 mysql 状态
[root@node01 mysql-libs]# service mysql status
MySQL is not running [失败]4)启动 mysql
[root@node01 mysql-libs]# service mysql start
Starting MySQL.. [确定]2.1.3 安装 MySql 客户端
1)安装 mysql 客户端
[root@node01 mysql-libs]# rpm -ivh MySQL-client-5.6.24-1.el6.x86_64.rpm
Preparing... ########################################### [100%]
1:MySQL-client ########################################### [100%]2)连接 mysql
[root@node01 mysql-libs]# mysql -uroot -pAd8YjoCm9eRhdE6Y3)修改密码
mysql> SET PASSWORD=PASSWORD('hadoop');
Query OK, 0 rows affected (0.00 sec)4)退出 mysql
mysql> exit2.1.4 MySql 中 user 表中主机配置
需求:配置只要是 root 用户+密码,在任何主机上都能登录 MySQL 数据库
1)进入 mysql
[root@node01 mysql-libs]# mysql -uroot -phadoop2)显示数据库
mysql>show databases;3)使用 mysql 数据库
mysql>use mysql;4)展示 mysql 数据库中的所有表
mysql>show tables;5)查询 user 表
mysql>select User, Host, Password from user;6)修改 user 表,把 Host 表内容修改为%
mysql>update user set host='%' where host='localhost';7)删除 root 用户的其他 host
mysql>
delete from user where Host='hadoop102';
delete from user where Host='127.0.0.1';
delete from user where Host='::1';8)刷新
mysql>flush privileges;9)退出
mysql>quit;2.2 Sqoop 安装
一、Sqoop概述
【1】简介
- Apache Sqoop是在
Hadoop生态体系和RDBMS体系之间传送数据的一种工具,来自于Apache软件基金会提供 - 核心的功能有两个:
导入、迁入
导出、迁出
导入数据:MySQL,Oracle 导入数据到 Hadoop 的 HDFS、HIVE、HBASE 等数据存储系统
导出数据:从 Hadoop 的文件系统中导出数据到关系数据库 MySQL等 Sqoop 的本质还是一个命令行工具,和 HDFS,Hive 相比,并没有什么高深的理论 - Sqoop工作机制:
是将导入或导出命令翻译成MapReduce程序来实现,在翻译出的MapReduce中主要是对InputFormat和OutputFormat进行定制 - Hadoop生态系统包括:HDFS、Hive、HBase等
RDBMS体系包括:Mysql、Oracle、DB2等
Sqoop可以理解为:“SQL 到 Hadoop 和 Hadoop 到SQL”

二、Sqoop安装
前提概述:将来Sqoop在使用的时候有可能会跟那些系统或者组件打交道?
HDFS, MapReduce, YARN, ZooKeeper, Hive, HBase, MySQL
Sqoop就是一个工具, 只需要在一个节点上进行安装即可
1.上传Sqoop包和mysql驱动包

2.解压
tar -zxf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C ../servers/3.配置环境变量
vim /etc/profile/sqoop.sh
添加如下内容↓↓↓ (记得
source /etc/profile)export SQOOP_HOME=/export/servers/sqoop-1.4.6.bin__hadoop-2.0.4-alpha export PATH=$PATH:$SQOOP_HOME/bin4.进入sqoop的conf目录,配置sqoop-env.sh
1.cp sqoop-env-template.sh sqoop-env.sh 2.vim sqoop-env.sh export HADOOP_COMMON_HOME=/export/servers/hadoop export HADOOP_MAPRED_HOME=/export/servers/hadoop export HIVE_HOME=/export/servers/hive export ZOOKEEPER_HOME=/export/servers/zookeeper export ZOOCFGDIR=/export/servers/zookeeper export HBASE_HOME=/export/servers/hbase5.加入mysql的jdbc驱动包
`cp /hive/lib/mysql-connector-java-5.1.32.jar $SQOOP_HOME/lib/`6.验证安装是否成功
sqoop-version 或者 sqoop version
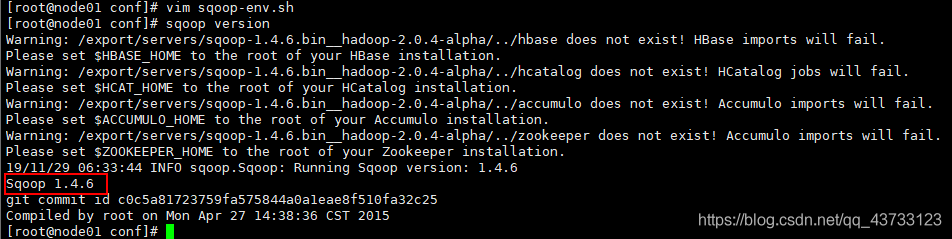
三、Sqoop使用场景及常用参数
业务需求分析
Sqoop可以在HDFS/Hive和关系型数据库之间进行数据的导入导出,其中主要使用了import和export这两个工具。这两个工具非常强大,提供了很多选项帮助我们完成数据的迁移和同步。比如,下面两个潜在的需求:
- 业务数据存放在关系数据库中,如果数据量达到一定规模后需要对其进行分析或同统计,单纯使用关系数据库可能会成为瓶颈,这时可以将数据从业务数据库数据导入(import)到Hadoop平台进行离线分析
- 对大规模的数据在Hadoop平台上进行分析以后,可能需要将结果同步到关系数据库中作为业务的辅助数据,这时候需要将Hadoop平台分析后的数据导出(export)到关系数据库
这里,我们介绍Sqoop完成上述基本应用场景所使用的import和export工具,通过一些简单的例子来说明这两个工具是如何做到的
工具通用选项
import 和 export工具有些通用的选项,如下表所示:
| 选项 | 含义说明 |
|---|---|
--connect <jdbc-uri> |
指定JDBC连接字符串 |
--connection-manager <class-name> |
指定要使用的连接管理器类 |
--driver <class-name> |
指定要使用的JDBC驱动类 |
--hadoop-mapred-home <dir> |
指定$HADOOP_MAPRED_HOME路径 |
--help |
打印用法帮助信息 |
--password-file |
设置用于存放认证的密码信息文件的路径 |
-P |
从控制台读取输入的密码 |
--password <password> |
设置认证密码 |
--username <username> |
设置认证用户名 |
--verbose |
打印详细的运行信息 |
--connection-param-file <filename> |
可选,指定存储数据库连接参数的属性文件 |
数据导入工具import
import工具,是将HDFS平台外部的结构化存储系统中的数据导入到Hadoop平台,便于后续分析;我们先看一下import工具的基本选项及其含义,如下表所示:
| 选项 | 含义说明 |
|---|---|
--append |
将数据追加到HDFS上一个已存在的数据集上 |
--as-avrodatafile |
将数据导入到Avro数据文件 |
--as-sequencefile |
将数据导入到SequenceFile |
--as-textfile |
将数据导入到普通文本文件(默认) |
--boundary-query <statement> |
边界查询,用于创建分片(InputSplit) |
--columns <col,col,col…> |
从表中导出指定的一组列的数据 |
--delete-target-dir |
如果指定目录存在,则先删除掉 |
--direct |
使用直接导入模式(优化导入速度) |
--direct-split-size <n> |
分割输入stream的字节大小(在直接导入模式下) |
--fetch-size <n> |
从数据库中批量读取记录数 |
--inline-lob-limit <n> |
设置内联的LOB对象的大小 |
-m,--num-mappers <n> |
使用n个map任务并行导入数据 |
-e,--query <statement> |
导入的查询语句 |
--split-by <column-name> |
指定按照哪个列去分割数据 |
--table <table-name> |
导入的源表表名 |
--target-dir <dir> |
导入HDFS的目标路径 |
--warehouse-dir <dir> |
HDFS存放表的根路径 |
--where <where clause> |
指定导出时所使用的查询条件 |
-z,--compress |
启用压缩 |
--compression-codec <c> |
指定Hadoop的codec方式(默认gzip) |
--null-string <null-string> |
如果指定列为字符串类型,使用指定字符串替换值为null的该类列的值 |
--null-non-string <null-string> |
如果指定列为非字符串类型,使用指定字符串替换值为null的该类列的值 |
下面,我们通过实例来说明,在实际中如何使用这些选项
【1】全量导入mysql表数据到HIVE
方式一:先复制表结构到hive中再导入数据
1.将关系型数据的表结构复制到hive中

将mysql中的emp_add表的结构复制到hive中 sqoop create-hive-table \ --connect jdbc:mysql://node01:3306/userdb \ --table emp_add \ --username root \ --password hadoop \ --hive-table hivedatabase.emp_add_sp 注: --table emp_add为mysql中的数据库userdb中的表。 --hive-table emp_add_sp为hive中hivedatabase库中新建的表名称
2.将MySQL数据库中整个表数据导入到Hive表
将MySQL数据库 userdb 中 emp_add 表的数据导入到Hive表中 sqoop import \ --connect jdbc:mysql://node01:3306/userdb \ --table emp_add \ --username root \ --password hadoop \ --hive-table emp_add \ --hive-import
方式二:直接复制表结构数据到hive中
将MySQL数据库 userdb 中 emp_conn 表的结构以及数据导入到Hive的hivedatabase库中 sqoop import \ --connect jdbc:mysql://node01:3306/userdb \ --username root \ --password hadoop \ --table emp_conn \ --hive-import \ --m 1 \ --hive-database hivedatabase
2】导入表数据子集
导入表数据子集(where过滤)
--where可以指定从关系数据库导入数据时的查询条件; 它执行在数据库服务器相应的SQL查询,并将结果存储在HDFS的目标目录 sqoop import \ --connect jdbc:mysql://node01:3306/userdb \ --table emp_add --m 1 \ --where "city ='sec-bad'" \ --username root \ --password hadoop \ --target-dir /wherequery
导入表数据子集(query查询)
注意事项: 使用query sql语句来进行查找不能加参数--table ; 并且必须要添加where条件; 并且where条件后面必须带一个$CONDITIONS 这个字符串; 并且这个sql语句必须用单引号,不能用双引号; sqoop命令中,--split-by id 通常配合-m 10参数使用;用于指定根据哪个字段进行划分并启动多少个maptask。 sqoop import \ --connect jdbc:mysql://node01:3306/userdb \ --username root \ --password hadoop \ --target-dir /wherequery2 \ --query 'select id,name,deg from emp WHERE id>1203 and $CONDITIONS' \ --split-by id \ --fields-terminated-by '\t' \ --m 2
Append模式增量导入
sqoop import \ --connect jdbc:mysql://node01:3306/userdb \ --table emp --m 1 \ --username root \ --password hadoop \ --target-dir /appendresult \ --incremental append \ --check-column id \ --last-value 1205 注: --check-column (col) 用来指定一些列,这些列在增量导入时用来检查这些数据是否作为增量数据进行导入,和关系型数据库中的自增字段及时间戳类似 这些被指定的列的类型不能使任意字符类型,如char、varchar等类型都是不可以的,同时-- check-column可以去指定多个列 --incremental (mode) append:追加,比如对大于last-value指定的值之后的记录进行追加导入; lastmodified:最后的修改时间,追加last-value指定的日期之后的记录 --last-value (value) 指定自从上次导入后列的最大值(大于该指定的值),也可以自己设定某一值
Lastmodified模式增量导入
append模式: sqoop import \ --connect jdbc:mysql://node01:3306/userdb \ --table customertest \ --username root \ --password hadoop \ --target-dir /lastmodifiedresult \ --check-column last_mod \ --incremental lastmodified \ --last-value "2019-05-28 18:42:06" \ --m 1 \ --append merge-key模式: sqoop import \ --connect jdbc:mysql://node01:3306/userdb \ --username root \ --password hadoop \ --table customertest \ --target-dir /lastmodifiedresult \ --check-column last_mod \ --incremental lastmodified \ --last-value "2019-05-28 18:42:06" \ --m 1 \ --merge-key id 注: lastmodified模式去处理增量时,会将大于等于last-value值的数据当做增量插入
数据导出工具export
| 选项 | 含义说明 |
|---|---|
--validate <class-name> |
启用数据副本验证功能,仅支持单表拷贝,可以指定验证使用的实现类 |
--validation-threshold <class-name> |
指定验证门限所使用的类 |
--direct |
使用直接导出模式(优化速度) |
--export-dir <dir> |
导出过程中HDFS源路径 |
-m,--num-mappers <n> |
使用n个map任务并行导出 |
--table <table-name> |
导出的目的表名称 |
--call <stored-proc-name> |
导出数据调用的指定存储过程名 |
--update-key <col-name> |
更新参考的列名称,多个列名使用逗号分隔 |
--update-mode <mode> |
指定更新策略,包括:updateonly(默认)、allowinsert |
--input-null-string <null-string> |
使用指定字符串,替换字符串类型值为null的列 |
--input-null-non-string <null-string> |
使用指定字符串,替换非字符串类型值为null的列 |
--staging-table <staging-table-name |
在数据导出到数据库之前,数据临时存放的表名称 |
--clear-staging-table> |
清除工作区中临时存放的数据 |
--batch |
使用批量模式导出 |
默认模式导出HDFS数据到mysql
sqoop export \ --connect jdbc:mysql://node01:3306/userdb \ --username root \ --password hadoop \ --table employee \ --export-dir /emp/emp_data --input-fields-terminated-by '\t' 注: --input-fields-terminated-by '\t' 指定文件中的分隔符 --columns 选择列并控制它们的排序。当导出数据文件和目标表字段列顺序完全一致的时候可以不写; 否则以逗号为间隔选择和排列各个列。没有被包含在–columns后面列名或字段要么具备默认值, 要么就允许插入空值,否则数据库会拒绝接受sqoop导出的数据,导致Sqoop作业失败 --export-dir 导出目录,在执行导出的时候,必须指定这个参数, 同时需要具备--table或--call参数两者之一,--table是指的导出数据库当中对应的表,--call是指的某个存储过程 --input-null-string --input-null-non-string 如果没有指定第一个参数,对于字符串类型的列来说,“NULL”这个字符串就回被翻译成空值, 如果没有使用第二个参数,无论是“NULL”字符串还是说空字符串也好,对于非字符串类型的字段来说,这两个类型的空串都会被翻译成空值; 比如: --input-null-string "\\N" --input-null-non-string "\\N"更新导出(updateonly模式)
-- update-key,更新标识,即根据某个字段进行更新, 例如id,可以指定多个更新标识的字段,多个字段之间用逗号分隔 -- updatemod,指定updateonly(默认模式),仅仅更新已存在的数据记录,不会插入新纪录 更新导出: sqoop export \ --connect jdbc:mysql://node01:3306/userdb \ --username root \ --password hadoop \ --table updateonly \ --export-dir /updateonly_2/ \ --update-key id \ --update-mode updateonly更新导出(allowinsert模式)
-- update-key,更新标识,即根据某个字段进行更新, 例如id,可以指定多个更新标识的字段,多个字段之间用逗号分隔 -- updatemod,指定updateonly(默认模式),仅仅更新已存在的数据记录,不会插入新纪录 更新导出: sqoop export \ --connect jdbc:mysql://node01:3306/userdb \ --username root --password hadoop \ --table allowinsert \ --export-dir /allowinsert_2/ \ --update-key id \ --update-mode allowinsert
2.3 业务数据生成
2.3.1 连接 MySQL
通过 MySQL 操作可视化工具 SQLyog 连接 MySQL
2.3.2 建表语句
1)通过 SQLyog 创建数据库 gmall
2)设置数据库编码
3)导入数据库结构脚本(gmall2020-03-16.sql)
2.3.3 生成业务数据
1)在 node01 的 /opt/modules/目录下创建 db_log 文件夹
2)把 gmall-mock-db-2020-03-16-SNAPSHOT.jar 和 application.properties 上传到 node01
的/opt/module/db_log 路径上
3)根据需求修改 application.properties 相关配置
logging.level.root=info spring.datasource.driver-class-name=com.mysql.jdbc.Driver spring.datasource.url=jdbc:mysql://node01:3306/gmall?charac terEncoding=utf-8&useSSL=false&serverTimezone=GMT%2B8 spring.datasource.username=root spring.datasource.password=hadoop logging.pattern.console=%m%n mybatis-plus.global-config.db-config.field-strategy=not_null #业务日期 mock.date=2020-03-10 #是否重置 mock.clear=1 #是否生成新用户 mock.user.count=50 #男性比例 mock.user.male-rate=20 #收藏取消比例 mock.favor.cancel-rate=10 #收藏数量 mock.favor.count=100 #购物车数量 mock.cart.count=10 #每个商品最多购物个数 mock.cart.sku-maxcount-per-cart=3 #用户下单比例 mock.order.user-rate=80 #用户从购物中购买商品比例 mock.order.sku-rate=70 #是否参加活动 mock.order.join-activity=1 #是否使用购物券 mock.order.use-coupon=1 #购物券领取人数 mock.coupon.user-count=10 #支付比例 mock.payment.rate=70 #支付方式 支付宝:微信 :银联 mock.payment.payment-type=30:60:10 #评价比例 好:中:差:自动 mock.comment.appraise-rate=30:10:10:50 #退款原因比例:质量问题 商品描述与实际描述不一致 缺货 号码不合适 拍错 不想买了 其他 mock.refund.reason-rate=30:10:20:5:15:5:5
4)并在该目录下执行,如下命令,生成 2020-03-10 日期数据:
java -jar gmall-mock-db-2020-03-16-SNAPSHOT.jar
5)在配置文件 application.properties 中修改
mock.date=2020-03-11 mock.clear=0
6)再次执行命令,生成 2020-03-11 日期数据:
java -jar gmall-mock-db-2020-03-16-SNAPSHOT.jar
2.4 同步策略
数据同步策略的类型包括:全量表、增量表、新增及变化表
- 全量表:存储完整的数据
- 增量表:存储新增加的数据
- 新增及变化表:存储新增加的数据和变化的数据
- 特殊表:只需要存储一次
2.4.1 全量同步策略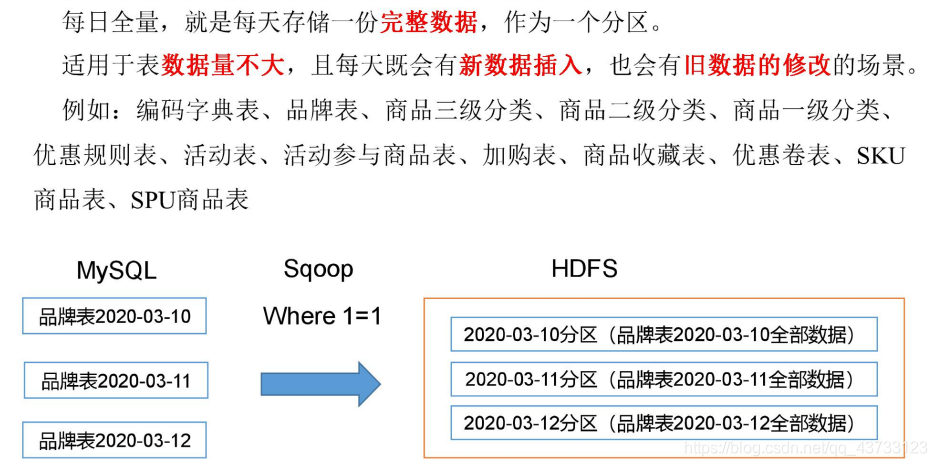
2.4.2 增量同步策略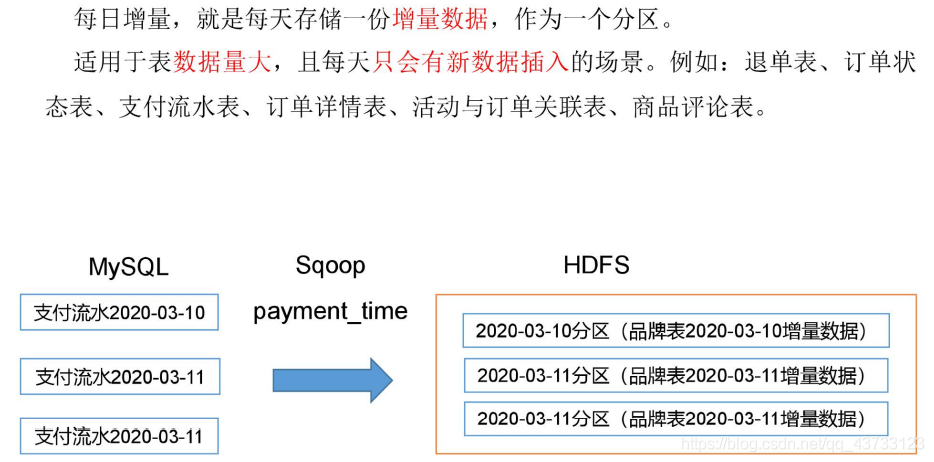
2.4.3 新增及变化策略
每日新增及变化,就是存储创建时间和操作时间都是今天的数据
适用场景为,表的数据量大,既会有新增,又会有变化
例如:用户表、订单表、优惠卷领用表
2.4.4 特殊策略
某些特殊的维度表,可不必遵循上述同步策略
- 1)客观世界维度
没变化的客观世界的维度(比如性别,地区,民族,政治成分,鞋子尺码)可以只存一
份固定值。
- 2)日期维度
日期维度可以一次性导入一年或若干年的数据
- 3)地区维度
省份表、地区表
2.5 业务数据导入 HDFS
2.5.1 分析表同步策略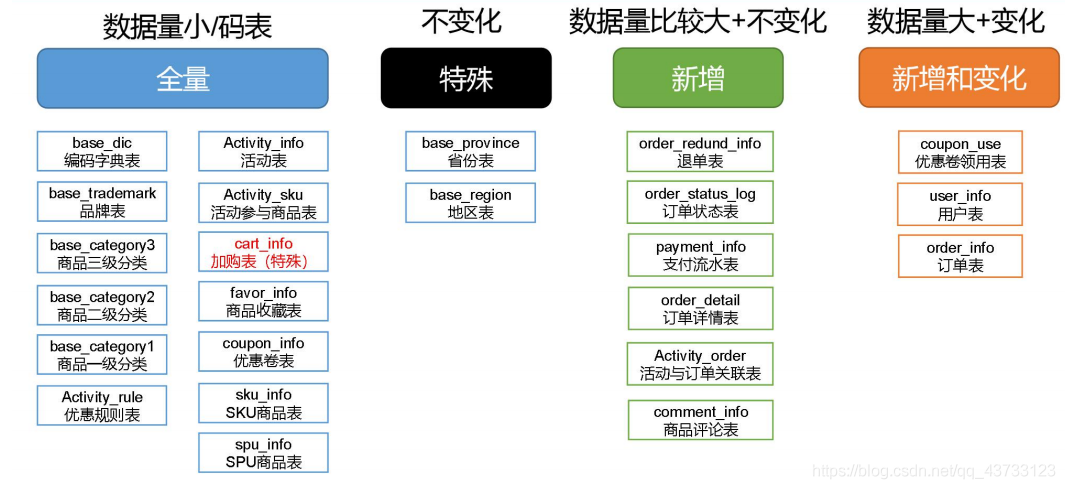
2.5.2 脚本编写
1)创建脚本
vim mysql_to_hdfs.sh
2)添加如下内容:
vim mysql_to_hdfs.sh
#! /bin/bash sqoop=/opt/modules/sqoop/bin/sqoop do_date=`date -d '-1 day' +%F` if [[ -n "$2" ]]; then do_date=$2 fi import_data(){ $sqoop import \ --connect jdbc:mysql://node01:3306/gmall \ --username root \ --password hadoop \ --target-dir /origin_data/gmall/db/$1/$do_date \ --delete-target-dir \ --query "$2 and \$CONDITIONS" \ --num-mappers 1 \ --fields-terminated-by '\t' \ --compress \ --compression-codec lzop \ --null-string '\\N' \ --null-non-string '\\N' hadoop jar /opt/modules/hadoop/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /origin_data/gmall/db/$1/$do_date } import_order_info(){ import_data order_info "select id, final_total_amount, order_status, user_id, out_trade_no, create_time, operate_time, province_id, benefit_reduce_amount, original_total_amount, feight_fee from order_info where (date_format(create_time,'%Y-%m-%d')='$do_date' or date_format(operate_time,'%Y-%m-%d')='$do_date')" } import_coupon_use(){ import_data coupon_use "select id, coupon_id, user_id, order_id, coupon_status, get_time, using_time, used_time from coupon_use where (date_format(get_time,'%Y-%m-%d')='$do_date' or date_format(using_time,'%Y-%m-%d')='$do_date' or date_format(used_time,'%Y-%m-%d')='$do_date')" } import_order_status_log(){ import_data order_status_log "select id, order_id, order_status, operate_time from order_status_log where date_format(operate_time,'%Y-%m-%d')='$do_date'" } import_activity_order(){ import_data activity_order "select id, activity_id, order_id, create_time from activity_order where date_format(create_time,'%Y-%m-%d')='$do_date'" } import_user_info(){ import_data "user_info" "select id, name, birthday, gender, email, user_level, create_time, operate_time from user_info where (DATE_FORMAT(create_time,'%Y-%m-%d')='$do_date' or DATE_FORMAT(operate_time,'%Y-%m-%d')='$do_date')" } import_order_detail(){ import_data order_detail "select od.id, order_id, user_id, sku_id, sku_name, order_price, sku_num, od.create_time from order_detail od join order_info oi on od.order_id=oi.id where DATE_FORMAT(od.create_time,'%Y-%m-%d')='$do_date'" } import_payment_info(){ import_data "payment_info" "select id, out_trade_no, order_id, user_id, alipay_trade_no, total_amount, subject, payment_type, payment_time from payment_info where DATE_FORMAT(payment_time,'%Y-%m-%d')='$do_date'" } import_comment_info(){ import_data comment_info "select id, user_id, sku_id, spu_id, order_id, appraise, comment_txt, create_time from comment_info where date_format(create_time,'%Y-%m-%d')='$do_date'" } import_order_refund_info(){ import_data order_refund_info "select id, user_id, order_id, sku_id, refund_type, refund_num, refund_amount, refund_reason_type, create_time from order_refund_info where date_format(create_time,'%Y-%m-%d')='$do_date'" } import_sku_info(){ import_data sku_info "select id, spu_id, price, sku_name, sku_desc, weight, tm_id, category3_id, create_time from sku_info where 1=1" } import_base_category1(){ import_data "base_category1" "select id, name from base_category1 where 1=1" } import_base_category2(){ import_data "base_category2" "select id, name, category1_id from base_category2 where 1=1" } import_base_category3(){ import_data "base_category3" "select id, name, category2_id from base_category3 where 1=1" } import_base_province(){ import_data base_province "select id, name, region_id, area_code, iso_code from base_province where 1=1" } import_base_region(){ import_data base_region "select id, region_name from base_region where 1=1" } import_base_trademark(){ import_data base_trademark "select tm_id, tm_name from base_trademark where 1=1" } import_spu_info(){ import_data spu_info "select id, spu_name, category3_id, tm_id from spu_info where 1=1" } import_favor_info(){ import_data favor_info "select id, user_id, sku_id, spu_id, is_cancel, create_time, cancel_time from favor_info where 1=1" } import_cart_info(){ import_data cart_info "select id, user_id, sku_id, cart_price, sku_num, sku_name, create_time, operate_time, is_ordered, order_time from cart_info where 1=1" } import_coupon_info(){ import_data coupon_info "select id, coupon_name, coupon_type, condition_amount, condition_num, activity_id, benefit_amount, benefit_discount, create_time, range_type, spu_id, tm_id, category3_id, limit_num, operate_time, expire_time from coupon_info where 1=1" } import_activity_info(){ import_data activity_info "select id, activity_name, activity_type, start_time, end_time, create_time from activity_info where 1=1" } import_activity_rule(){ import_data activity_rule "select id, activity_id, condition_amount, condition_num, benefit_amount, benefit_discount, benefit_level from activity_rule where 1=1" } import_base_dic(){ import_data base_dic "select dic_code, dic_name, parent_code, create_time, operate_time from base_dic where 1=1" } case $1 in "order_info") import_order_info ;; "base_category1") import_base_category1 ;; "base_category2") import_base_category2 ;; "base_category3") import_base_category3 ;; "order_detail") import_order_detail ;; "sku_info") import_sku_info ;; "user_info") import_user_info ;; "payment_info") import_payment_info ;; "base_province") import_base_province ;; "base_region") import_base_region ;; "base_trademark") import_base_trademark ;; "activity_info") import_activity_info ;; "activity_order") import_activity_order ;; "cart_info") import_cart_info ;; "comment_info") import_comment_info ;; "coupon_info") import_coupon_info ;; "coupon_use") import_coupon_use ;; "favor_info") import_favor_info ;; "order_refund_info") import_order_refund_info ;; "order_status_log") import_order_status_log ;; "spu_info") import_spu_info ;; "activity_rule") import_activity_rule ;; "base_dic") import_base_dic ;; "first") import_base_category1 import_base_category2 import_base_category3 import_order_info import_order_detail import_sku_info import_user_info import_payment_info import_base_province import_base_region import_base_trademark import_activity_info import_activity_order import_cart_info import_comment_info import_coupon_use import_coupon_info import_favor_info import_order_refund_info import_order_status_log import_spu_info import_activity_rule import_base_dic ;; "all") import_base_category1 import_base_category2 import_base_category3 import_order_info import_order_detail import_sku_info import_user_info import_payment_info import_base_trademark import_activity_info import_activity_order import_cart_info import_comment_info import_coupon_use import_coupon_info import_favor_info import_order_refund_info import_order_status_log import_spu_info import_activity_rule import_base_dic ;; esac
说明 1:
[ -n 变量值 ] 判断变量的值,是否为空 -- 变量的值,非空,返回 true -- 变量的值,为空,返回 false
说明 2:
查看 date 命令的使用,date --help
2)修改脚本权限
chmod 770 mysql2hdfs.sh
3)初次导入
mysql2hdfs.sh first 2020-03-10
4)每日导入
mysql2hdfs.sh all 2020-03-11
注意:此过程可能会执行10-20分钟左右,请耐心等待!
2.5.3 项目经验
Hive 中的 Null 在底层是以“\N”来存储,而 MySQL 中的 Null 在底层就是 Null,为了
保证数据两端的一致性。在导出数据时采用–input-null-string 和–input-null-non-string 两个参
数。导入数据时采用–null-string 和–null-non-string
三、数据环境准备
3.1 安装 Hive2.3
(PS:博主曾经安装过Hive,不过版本是Hive-1.1.0的,但是这次使用的是Hive2.3,配置稍有不同,所以就重新在这里写一遍配置!)
1)上传 apache-hive-2.3.0-bin.tar.gz 到/opt/software 目录下,并解压到/opt/modules
tar -zxf apache-hive-2.3.6-bin.tar.gz -C /opt/modules
2)修改 apache-hive-2.3.6-bin 名称为 hive
mv apache-hive-2.3.6-bin hive
3)将 Mysql 的 mysql-connector-java-5.1.27-bin.jar 拷贝到 /opt/modules/hive/lib
cp /opt/software/mysql-libs/mysql-connector-java-5.1.27/mysql-connector-java-5.1.27-bin.jar /opt/modules/hive/lib/
4)在/opt/modules/hive/conf 路径上,修改hive-env.sh,添加如下配置
5)在/opt/modules/hive/conf 路径上,创建 hive-site.xml 文件
vim hive-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://node01:3306/hive?createDatabaseIfNotExist=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>hadoop</value> </property> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <property> <name>hive.cli.print.header</name> <value>true</value> </property> <property> <name>hive.cli.print.current.db</name> <value>true</value> </property> <property> <name>hive.metastore.schema.verification</name> <value>false</value> </property> <property> <name>datanucleus.schema.autoCreateAll</name> <value>true</value> </property> <property> <name>hive.server2.thrift.bind.host</name> <value>node01</value> </property> <property> <name>hive.metastore.uris</name> <value>thrift://node01:9083</value> </property> </configuration>
6)启动!
nohup ./bin/hive --service metastore & nohup ./bin/hiveserver2 & ./bin/beeline !connect jdbc:hive2://node01:10000
3.2 Hive 集成引擎 Tez
Tez 是一个 Hive 的运行引擎,性能优于 MR。为什么优于 MR 呢?看下图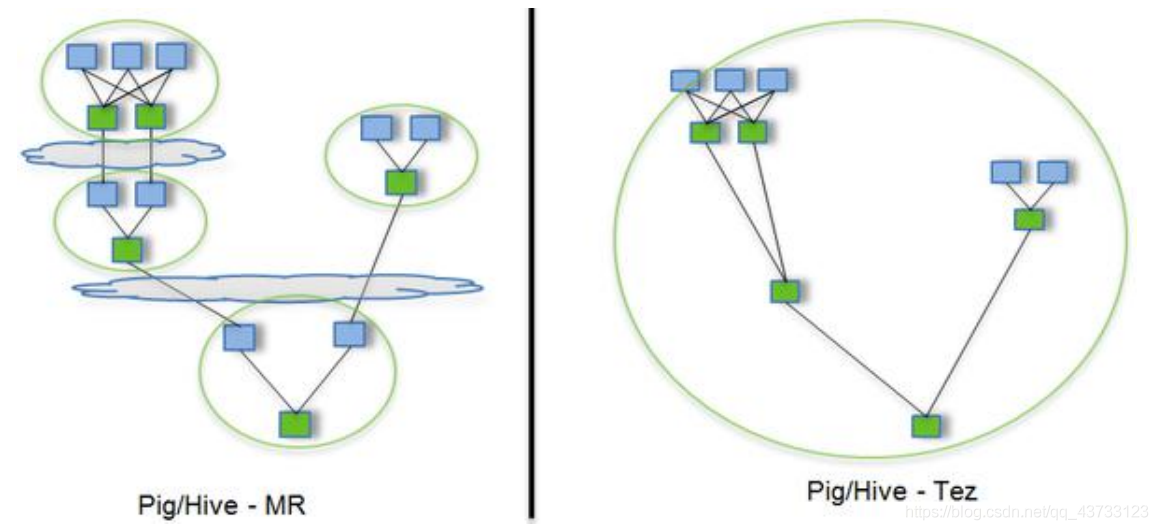
用 Hive 直接编写 MR 程序,假设有四个有依赖关系的 MR 作业,上图中,绿色是 ReduceTask,云状表示写屏蔽,需要将中间结果持久化写到 HDFS
Tez 可以将多个有依赖的作业转换为一个作业,这样只需写一次 HDFS,且中间节点较少,从而大大提升作业的计算性能
3.2.1 安装包准备
1)下载 tez 的依赖包:http://tez.apache.org
2)将 apache-tez-0.9.1-bin.tar.gz 上传到 HDFS 的 /tez 目录下
hdfs dfs -mkdir /tez hdfs dfs -put /opt/software/apache-tez-0.9.1-bin.tar.gz /tez
3)解压缩 apache-tez-0.9.1-bin.tar.gz,并重命名为 tez
cd /opt/modules/hive/conf
2)在 Hive 的/opt/modules/hive/conf 下面创建一个 tez-site.xml 文件
vim tez-site.xml
添加如下内容
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>tez.lib.uris</name> <value>${fs.defaultFS}/tez/apache-tez-0.9.1-bin.tar.gz</value> </property> <property> <name>tez.use.cluster.hadoop-libs</name> <value>true</value> </property> <property> <name>tez.history.logging.service.class</name> <value>org.apache.tez.dag.history.logging.ats.ATSHistoryLoggin gService</value> </property> </configuration>
3)在 hive-site.xml 文件中添加如下配置,更改 hive 计算引擎
<property> <name>hive.execution.engine</name> <value>tez</value> </property>
3.2.3 测试
1)启动 Hive
2)创建表
create table student(id int,name string);
3)向表中插入数据
insert into student values(1,"zhangsan");
4)如果没有报错就表示成功了
select * from student;
3.2.4 注意事项
1)运行 Tez 时检查到用过多内存而被 NodeManager 杀死进程问题:
Caused by: org.apache.tez.dag.api.SessionNotRunning: TezSession has already shutdown. Application application_1546781144082_0005 failed 2 times due to AM Container for appattempt_1546781144082_0005_000002 exited with exitCode: -103 For more detailed output, check application tracking page:http://hadoop103:8088/cluster/app/application_15467811440 82_0005Then, click on links to logs of each attempt. Diagnostics: Container [pid=11116,containerID=container_1546781144082_0005_02_000001] is running beyond virtual memory limits. Current usage: 216.3 MB of 1 GB physical memory used; 2.6 GB of 2.1 GB virtual memory used. Killing container.
这种问题是从机上运行的 Container 试图使用过多的内存,而被 NodeManager kill 掉了
2)解决方法:
(1)关掉虚拟内存检查,修改 yarn-site.xml,添加如下配置
<property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property>
(2)修改后分发配置文件,并重新启动 hadoop 集群
本文来自博客园,作者:大码王,转载请注明原文链接:https://www.cnblogs.com/huanghanyu/

 posted on
posted on










【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具