
问题导读
最近学习Kylin,肯定需要一个已经安装好的环境,Kylin的依赖环境官方介绍如下:
依赖于 Hadoop 集群处理大量的数据集。您需要准备一个配置好 HDFS,YARN,MapReduce,,Hive, HBase,Zookeeper 和其他服务的 Hadoop 集群供 Kylin 运行。Kylin 可以在 Hadoop 集群的任意节点上启动。方便起见,您可以在 master 节点上运行 Kylin。但为了更好的稳定性,我们建议您将 Kylin 部署在一个干净的 Hadoop client 节点上,该节点上 Hive,HBase,HDFS 等命令行已安装好且 client 配置(如 core-site.xml,hive-site.xml,hbase-site.xml及其他)也已经合理的配置且其可以自动和其它节点同步。运行 Kylin 的 Linux 账户要有访问 Hadoop 集群的权限,包括创建/写入 HDFS 文件夹,Hive 表, HBase 表和提交 MapReduce 任务的权限。
软件要求
Hadoop: 2.7+, 3.1+ (since v2.5)
Hive: 0.13 - 1.2.1+
HBase: 1.1+, 2.0 (since v2.5)
Spark (可选) 2.3.0+
Kafka (可选) 1.0.0+ (since v2.5)
JDK: 1.8+ (since v2.5)
OS: Linux only, CentOS 6.5+ or Ubuntu 16.0.4+
安装要求知道了,但是hadoop这些东西不太熟悉,小白一个,看了网上一些资料边看边学边做,期间遇到了很多坑!很多人写的安装部署文档要么是步骤东一块西一块,要么是省略,扔个连接或则说让自己去百度。在经历了很多坑之后终于是把完全分布式的hadoop+mysql+hive+hbase+zookeeper+kylin部署成功了,但是对于日常自己学习测试来说,开多台虚拟机电脑实在撑不住,于是写了现在这个伪分布式的部署文档给像我一样初学kylin的小白同学们
环境配置:
目前有两个测试环境,以Centsos 7系统的安装为例子介绍详细过程,Centos7系统规划配置清单如下,另外一个测试环境为RedHat 6 64位系统,安装过程都差不多,Mysql安装有些不一样,不一样的地方都分别写了各自的安装方法,安装过程中遇到的坑很多
并且都已经解决,不再一一列举,按照下面步骤是完全可以在Centos 7/Redhat 6 64位系统安装成功的。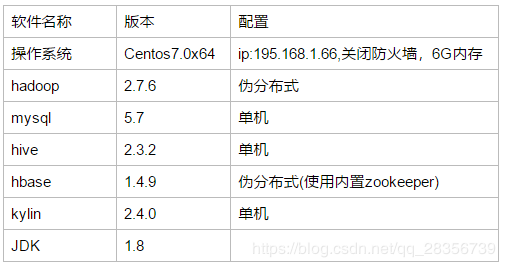
一、Centos7安装
打开vmware,创建新虚拟机安装Centos 774位系统: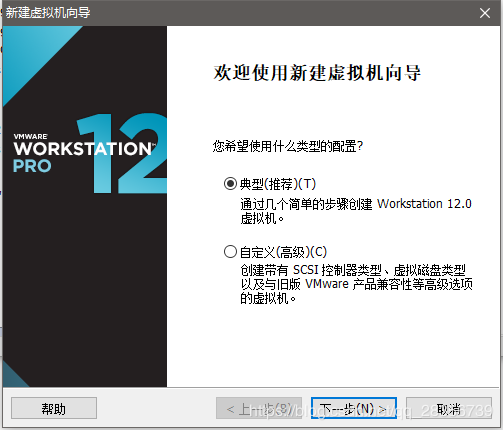


完成后界面如下:
选择启动虚拟机,选择第一个选项回车:
选择继续
等待依赖包检查完成,点击date&time设置时间
接下来点击software selection选择安装模式,这里选择最精简安装: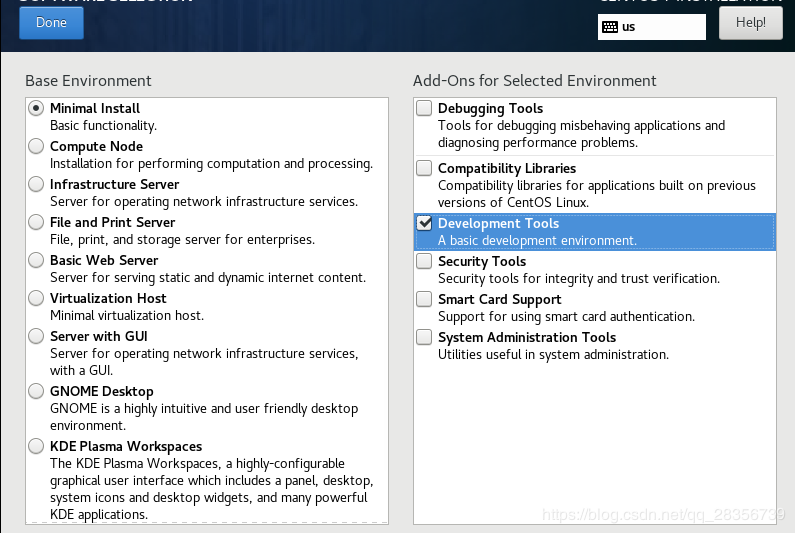
然后点击done出来之后,等待依赖包检查完成,然后设置磁盘分区
选择现在设置: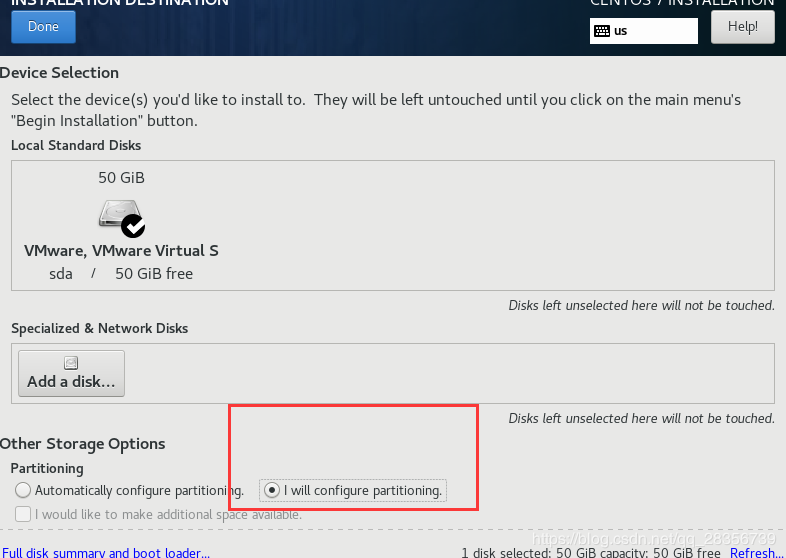
点击done后,进入下面所示界面,选择标准分区,然后设置点击+号设置分区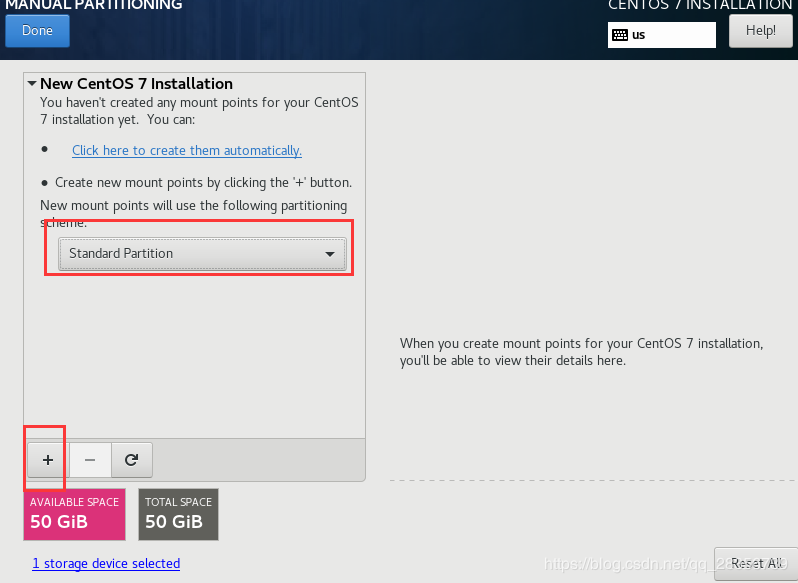
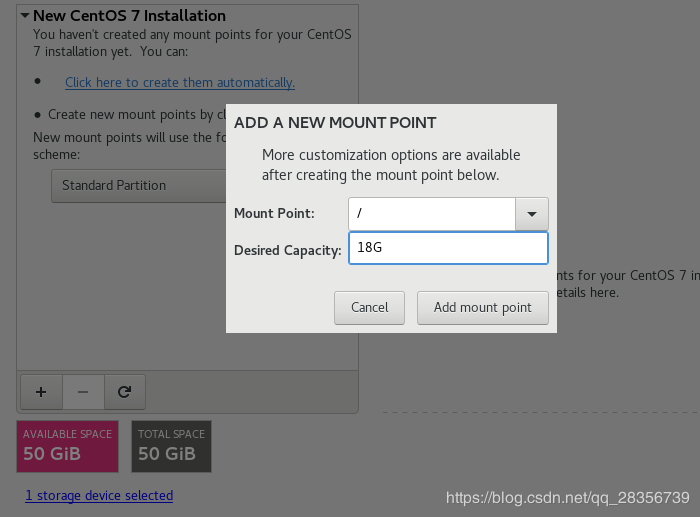
最后分好区如下: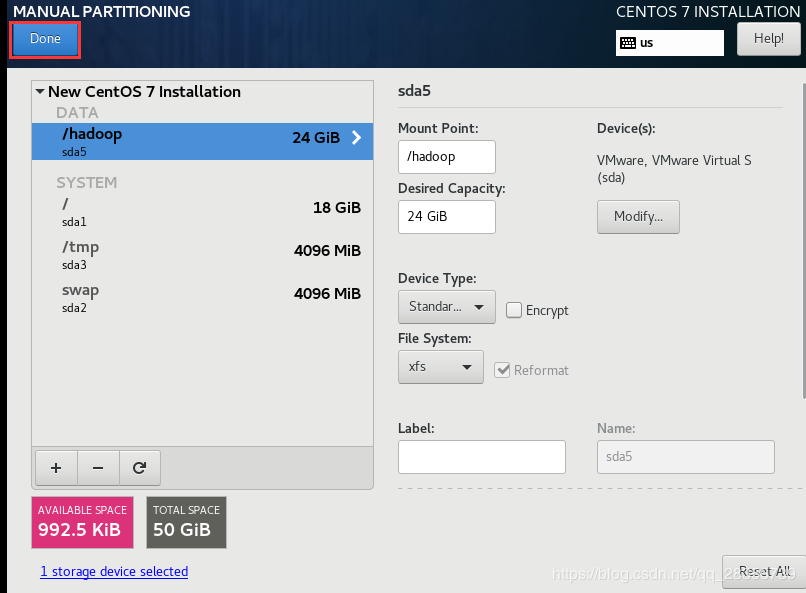
然后点击done后点击确认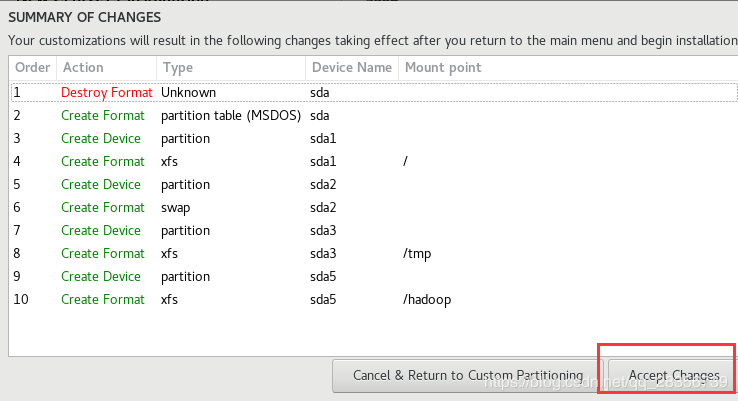
接下来选择网络设置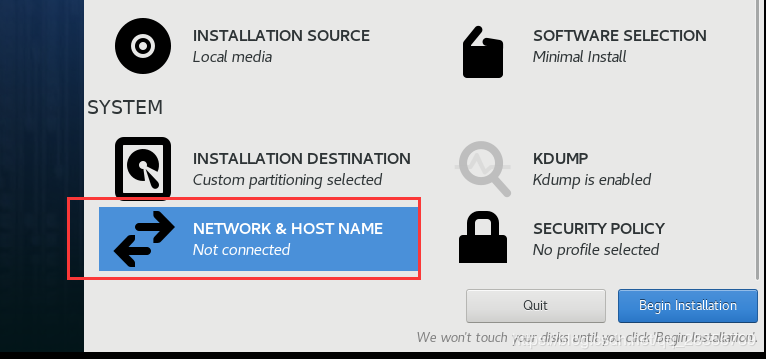
设置hostname,点击apply。然后选择configure设置网络ip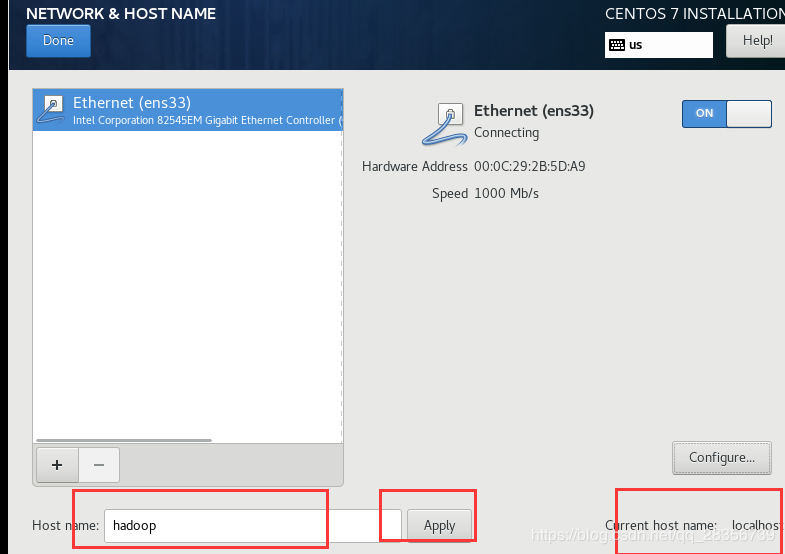
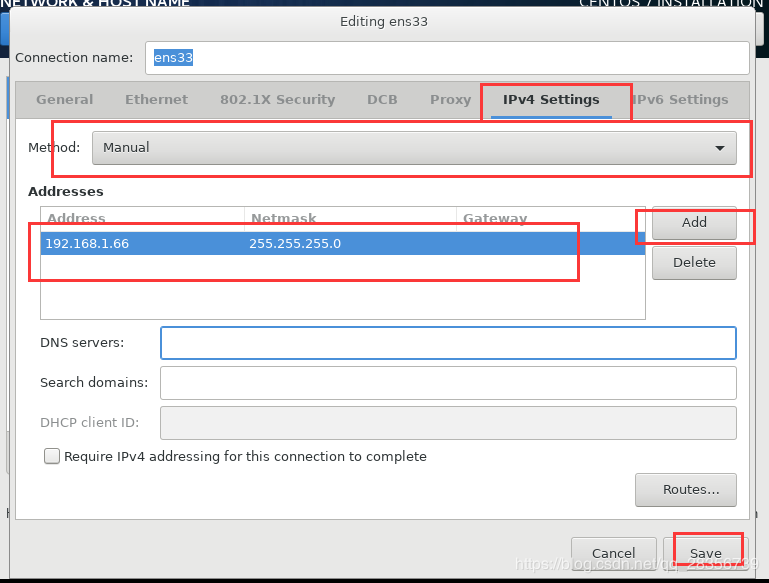
最后done点击安装就可以了:
可以在这个界面设置下root密码,等待安装完成就可以了。这是虚拟机的安装,接下来配置linux,安装软件。
1、linux网络配置:
(1)因为Centos 7安装的精简模式,先解决linux网络问题来让windows能够用xshell连上,编辑/etc/sysconfig/network-scripts/ifcfg-ens33内容如下:

TYPE=Ethernet PROXY_METHOD=none BROWSER_ONLY=no BOOTPROTO=none DEFROUTE=yes IPV4_FAILURE_FATAL=no IPV6INIT=yes IPV6_AUTOCONF=yes IPV6_DEFROUTE=yes IPV6_FAILURE_FATAL=no IPV6_ADDR_GEN_MODE=stable-privacy NAME=ens33 UUID=e8df3ff3-cf86-42cd-b48a-0d43fe85d8a6 DEVICE=ens33 ONBOOT="yes" IPADDR=192.168.1.66 PREFIX=24 IPV6_PRIVACY=no
(2)重启网络
[root@hadoop ~]# service network restart Restarting network (via systemctl): [ OK ] 重启后可以通过下面命令来检查网络 [root@hadoop ~]# ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 00:0c:29:0d:f1:ca brd ff:ff:ff:ff:ff:ff inet 192.168.1.66/24 brd 192.168.1.255 scope global noprefixroute ens33 valid_lft forever preferred_lft forever inet6 fe80::d458:8497:adb:7f01/64 scope link noprefixroute valid_lft forever preferred_lft forever
(3)接下来关闭防火墙
[root@hadoop ~]# systemctl disable firewalld
[root@hadoop ~]# systemctl stop firewalld```
(4)进程守护,关闭selinux
[root@hadoop ~]# setenforce 0 [root@hadoop ~]# vi /etc/selinux/config [root@hadoop ~]# cat /etc/selinux/config # This file controls the state of SELinux on the system. # SELINUX= can take one of these three values: # enforcing - SELinux security policy is enforced. # permissive - SELinux prints warnings instead of enforcing. # disabled - No SELinux policy is loaded. SELINUX=disabled # SELINUXTYPE= can take one of three values: # targeted - Targeted processes are protected, # minimum - Modification of targeted policy. Only selected processes are protected. # mls - Multi Level Security protection. SELINUXTYPE=targeted
重启
[root@hadoop ~]# reboot
可以通过下面方式查看是否启用selinux
sestatus
getenforce
(5)编辑/etc/hosts加入下面内容
[root@hadoop ~]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.1.66 hadoop
2、安装java
(1)先看下当前linux环境是否有自带的open jdk:
[root@hadoop ~]# rpm -qa | grep java [root@hadoop ~]# rpm -qa | grep jdk [root@hadoop ~]# rpm -qa | grep gcj
没有,如果有的话要卸载,卸载案例如下:
卸载linux自带open jdk,将前面三条命令检查出来的内容一一卸载:
[root@master ~]# rpm -e --nodeps java-1.7.0-openjdk-1.7.0.99-2.6.5.1.0.1.el6.x86_64 [root@master ~]# rpm -e --nodeps tzdata-java-2016c-1.el6.noarch [root@master ~]# rpm -e java-1.6.0-openjdk-1.6.0.38-1.13.10.4.el6.x86_64 [root@master ~]# rpm -e java-1.7.0-openjdk-1.7.0.99-2.6.5.1.0.1.el6.x86_64
卸载完成后应该再检查一次
(2)接下来安装配置java
创建安装目录:
[root@hadoop ~]# mkdir -p /usr/java
上传并解压jdk到此目录
[root@hadoop ~]# cd /usr/java/ [root@hadoop java]# ls jdk-8u151-linux-x64 (1).tar.gz
解压缩
[root@hadoop java]# tar -zxvf jdk-8u151-linux-x64\ \(1\).tar.gz [root@hadoop java]# rm -rf jdk-8u151-linux-x64\ \(1\).tar.gz [root@hadoop java]# ls jdk1.8.0_151
编辑/etc/profile
写入下面jdk环境变量,保存退出
export JAVA_HOME=/usr/java/jdk1.8.0_151 export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export PATH=$PATH:$JAVA_HOME/bin
使环境变量生效
[root@master java]# source /etc/profile
检查安装是否没问题
[root@hadoop java]# java -version java version "1.8.0_151" Java(TM) SE Runtime Environment (build 1.8.0_151-b12) Java HotSpot(TM) 64-Bit Server VM (build 25.151-b12, mixed mode)
3、配置SSH免密码登录
(1)输入命令,ssh-keygen -t rsa,生成key,都不输入密码,一直回车,/root就会生成.ssh文件夹
[root@hadoop ~]# ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub. The key fingerprint is: SHA256:+Xxqh8qa2AguQPY4aNJci6YiUWS822NtcLRK/9Kopp8 root@hadoop1 The key's randomart image is: +---[RSA 2048]----+ | . | | + . | | o . . . | | oo + o . | |++o* B S | |=+*.* + o | |++o. o + o.. | |=. ..=ooo oo. | |o.o+E.+ooo.. | +----[SHA256]-----+ [root@hadoop ~]# cd .ssh/ [root@hadoop .ssh]# ls id_rsa id_rsa.pub known_hosts
合并公钥到authorized_keys文件,在hadoop服务器,进入/root/.ssh目录,通过SSH命令合并
[root@hadoop .ssh]# cat id_rsa.pub>> authorized_keys
通过下面命令测试
ssh localhost ssh hadoop ssh 192.168.1.66
4、安装Hadoop2.7
(1)下载连接:
http://archive.apache.org/dist/hadoop/core/hadoop-2.7.6/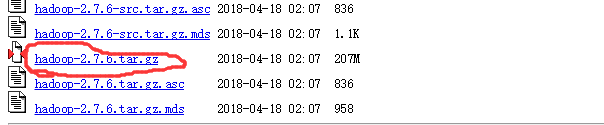
(2)解压:
[root@hadoop ~]# cd /hadoop/ [root@hadoop hadoop]# ls hadoop-2.7.6 (1).tar.gz [root@hadoop hadoop]# tar -zxvf hadoop-2.7.6\ \(1\).tar.gz ^C [root@hadoop hadoop]# ls hadoop-2.7.6 hadoop-2.7.6 (1).tar.gz [root@hadoop hadoop]# rm -rf *gz [root@hadoop hadoop]# mv hadoop-2.7.6/* .
(3)在/hadoop目录下创建数据存放的文件夹,tmp、hdfs、hdfs/data、hdfs/name
[root@hadoop hadoop]# pwd /hadoop [root@hadoop hadoop]# mkdir tmp [root@hadoop hadoop]# mkdir hdfs [root@hadoop hadoop]# mkdir hdfs/data [root@hadoop hadoop]# mkdir hdfs/name
(4)配置/hadoop/etc/hadoop目录下的core-site.xml
[root@hadoop hadoop]# vi etc/hadoop/core-site.xml <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://192.168.1.66:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/hadoop/tmp</value> </property> <property> <name>io.file.buffer.size</name> <value>131702</value> </property> </configuration>
(5)配置/hadoop/etc/hadoop/hdfs-site.xm
[root@hadoop hadoop]# vi etc/hadoop/hdfs-site.xml <configuration> <property> <name>dfs.namenode.name.dir</name> <value>file:/hadoop/hdfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/hadoop/hdfs/data</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>192.168.1.66:9001</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> </configuration>
(6)复制etc/hadoop/mapred-site.xml.template为etc/hadoop/mapred-site.xml,再编辑:
[root@hadoop hadoop]# cd etc/hadoop/ [root@hadoop hadoop]# cp mapred-site.xml.template mapred-site.xml [root@hadoop hadoop]# vi mapred-site.xml <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>192.168.1.66:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>192.168.1.66:19888</value> </property> </configuration>
(7)配置 etc/hadoop/yarn-site.xml
[root@hadoop1 hadoop]# vi yarn-site.xml <configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop</value> </property> </configuration>
(8)配置/hadoop/etc/hadoop/目录下hadoop-env.sh、yarn-env.sh的JAVA_HOME,不设置的话,启动不了
[root@hadoop hadoop]# pwd /hadoop/etc/hadoop [root@hadoop hadoop]# vi hadoop-env.sh 将 export JAVA_HOME 改为:export JAVA_HOME=/usr/java/jdk1.8.0_151 加入 export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/etc/hadoop"} export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native [root@hadoop hadoop]# vi yarn-env.sh 将 export JAVA_HOME 改为:export JAVA_HOME=/usr/java/jdk1.8.0_151
配置slaves文件
[root@hadoop hadoop]# cat slaves localhost
(9)配置hadoop环境变量
[root@hadoop ~]# vi /etc/profile 写入下面内容 export HADOOP_HOME=/hadoop/ export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR" export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin [root@hadoop ~]# source /etc/profile
(10)启动hadoop
[root@hadoop hadoop]# pwd /hadoop [root@hadoop hadoop]# bin/hdfs namenode -format .。。。。。。。。。。。。。。。。。。。。。 19/03/04 17:18:00 INFO namenode.FSImage: Allocated new BlockPoolId: BP-774693564-192.168.1.66-1551691079972 19/03/04 17:18:00 INFO common.Storage: Storage directory /hadoop/hdfs/name has been successfully formatted. 19/03/04 17:18:00 INFO namenode.FSImageFormatProtobuf: Saving image file /hadoop/hdfs/name/current/fsimage.ckpt_0000000000000000000 using no compression 19/03/04 17:18:00 INFO namenode.FSImageFormatProtobuf: Image file /hadoop/hdfs/name/current/fsimage.ckpt_0000000000000000000 of size 321 bytes saved in 0 seconds. 19/03/04 17:18:00 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 19/03/04 17:18:00 INFO util.ExitUtil: Exiting with status 0 19/03/04 17:18:00 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at hadoop/192.168.1.66 ************************************************************/
全部启动sbin/start-all.sh,也可以分开sbin/start-dfs.sh、sbin/start-yarn.sh
[root@hadoop hadoop]# sbin/start-dfs.sh [root@hadoop hadoop]# sbin/start-yarn.sh
停止的话,输入命令,sbin/stop-all.sh
输入命令jps,可以看到相关信息:
[root@hadoop hadoop]# jps 10581 ResourceManager 10102 NameNode 10376 SecondaryNameNode 10201 DataNode 10683 NodeManager 11007 Jps
(11)启动jobhistory
mr-jobhistory-daemon.sh start historyserver [root@hadoop hadoop]# jps 33376 NameNode 33857 ResourceManager 33506 DataNode 33682 SecondaryNameNode 33960 NodeManager 34319 JobHistoryServer 34367 Jps
(12)验证
1)浏览器打开http://192.168.1.66:8088/
2)浏览器打开http://192.168.1.66:50070/
5、安装Mysql
需要根据自己的系统版本去下载,下载连接:
https://dev.mysql.com/downloads/mysql/5.7.html#downloads
我这里下载的是适用我当前本人测试环境Centos 7 64位 的系统,而另一个测试环境10.1.197.241是Redhat 6,两个测试环境如果安装时要下载对应系统的rpm包,不然不兼容的rpm包安装时会报下面的错误(比如在Redhat6安装适用centos7的mysql):
[root@s197240 hadoop]# rpm -ivh mysql-community-libs-5.7.18-1.el7.x86_64.rpm warning: mysql-community-libs-5.7.18-1.el7.x86_64.rpm: Header V3 DSA/SHA1 Signature, key ID 5072e1f5: NOKEY error: Failed dependencies: libc.so.6(GLIBC_2.14)(64bit) is needed by mysql-community-libs-5.7.18-1.el7.x86_64
1)检查卸载mariadb-lib
Centos自带mariadb数据库,删除,安装mysql
[root@hadoop hadoop]# rpm -qa|grep mariadb mariadb-libs-5.5.60-1.el7_5.x86_64 [root@hadoop hadoop]# rpm -e mariadb-libs-5.5.60-1.el7_5.x86_64 --nodeps [root@hadoop hadoop]# rpm -qa|grep mariadb
如果时Redhat6安装时自带mysql库,卸载自带的包:
通过此命令查找已经安装的mysql包:
[root@s197240 hadoop]# rpm -qa |grep mysql mysql-community-common-5.7.18-1.el7.x86_64
通过此命令卸载:
[root@s197240 hadoop]# rpm -e --allmatches --nodeps mysql-community-common-5.7.18-1.el7.x86_64
2)上传解压安装包
下载连接:
https://dev.mysql.com/downloads/file/?id=469456
[root@hadoop mysql]# pwd /usr/local/mysql [root@hadoop mysql]# ls mysql-5.7.18-1.el7.x86_64.rpm-bundle.tar [root@hadoop mysql]# tar -xvf mysql-5.7.18-1.el7.x86_64.rpm-bundle.tar mysql-community-server-5.7.18-1.el7.x86_64.rpm mysql-community-embedded-devel-5.7.18-1.el7.x86_64.rpm mysql-community-devel-5.7.18-1.el7.x86_64.rpm mysql-community-client-5.7.18-1.el7.x86_64.rpm mysql-community-common-5.7.18-1.el7.x86_64.rpm mysql-community-embedded-5.7.18-1.el7.x86_64.rpm mysql-community-embedded-compat-5.7.18-1.el7.x86_64.rpm mysql-community-libs-5.7.18-1.el7.x86_64.rpm mysql-community-server-minimal-5.7.18-1.el7.x86_64.rpm mysql-community-test-5.7.18-1.el7.x86_64.rpm mysql-community-minimal-debuginfo-5.7.18-1.el7.x86_64.rpm mysql-community-libs-compat-5.7.18-1.el7.x86_64.rpm
(3)安装mysql server
其中,安装mysql-server, 需要以下几个必要的安装包:
mysql-community-client-5.7.17-1.el7.x86_64.rpm(依赖于libs) mysql-community-common-5.7.17-1.el7.x86_64.rpm (依赖于common) mysql-community-libs-5.7.17-1.el7.x86_64.rpm mysql-community-server-5.7.17-1.el7.x86_64.rpm(依赖于common, client)
安装上面四个包需要libaio和net-tools的依赖,这里配置好yum源,使用yum安装,通过以下命令安装:
yum -y install libaio yum -y install net-tools
安装mysql-server:按照common–>libs–>client–>server的顺序。若不按照此顺序,也会有一定“依赖”关系的提醒。
[root@hadoop mysql]# rpm -ivh mysql-community-common-5.7.18-1.el7.x86_64.rpm warning: mysql-community-common-5.7.18-1.el7.x86_64.rpm: Header V3 DSA/SHA1 Signature, key ID 5072e1f5: NOKEY Preparing... ################################# [100%] Updating / installing... 1:mysql-community-common-5.7.18-1.e################################# [100%] [root@hadoop mysql]# rpm -ivh mysql-community-libs-5.7.18-1.el7.x86_64.rpm warning: mysql-community-libs-5.7.18-1.el7.x86_64.rpm: Header V3 DSA/SHA1 Signature, key ID 5072e1f5: NOKEY Preparing... ################################# [100%] Updating / installing... 1:mysql-community-libs-5.7.18-1.el7################################# [100%] [root@hadoop mysql]# rpm -ivh mysql-community-client-5.7.18-1.el7.x86_64.rpm warning: mysql-community-client-5.7.18-1.el7.x86_64.rpm: Header V3 DSA/SHA1 Signature, key ID 5072e1f5: NOKEY Preparing... ################################# [100%] Updating / installing... 1:mysql-community-client-5.7.18-1.e################################# [100%] [root@hadoop mysql]# rpm -ivh mysql-community-server-5.7.18-1.el7.x86_64.rpm warning: mysql-community-server-5.7.18-1.el7.x86_64.rpm: Header V3 DSA/SHA1 Signature, key ID 5072e1f5: NOKEY Preparing... ################################# [100%] Updating / installing... 1:mysql-community-server-5.7.18-1.e################################# [100%]
(4)初始化mysql
[root@hadoop mysql]# mysqld --initialize
mysql默认安装在/var/lib下。
(5)更改mysql数据库所属于用户及其所属于组
[root@hadoop mysql]# chown mysql:mysql /var/lib/mysql -R
(6)启动mysql数据库
[root@hadoop mysql]# cd /var/lib/mysql [root@hadoop mysql]# systemctl start mysqld.service [root@hadoop ~]# cd /var/log/ [root@hadoop log]# grep 'password' mysqld.log 2019-02-26T04:33:06.989818Z 1 [Note] A temporary password is generated for root@localhost: mxeV&htW-3VC
更改root用户密码,新版的mysql在第一次登录后更改密码前是不能执行任何命令的
[root@hadoop log]# mysql -u root -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 4 Server version: 5.7.18 Copyright (c) 2000, 2017, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
更改密码
mysql> set password=password('oracle'); Query OK, 0 rows affected, 1 warning (0.00 sec) mysql> flush privileges; Query OK, 0 rows affected (0.00 sec) mysql> grant all privileges on *.* to root@'%' identified by 'oracle' with grant option; Query OK, 0 rows affected, 1 warning (0.00 sec) mysql> flush privileges; Query OK, 0 rows affected (0.00 sec)
如果是Redhat6系统,启动mysql数据库过程如下:
[root@s197240 mysql]# /etc/rc.d/init.d/mysqld start Starting mysqld: [ OK ] [root@s197240 mysql]# ls /etc/rc.d/init.d/mysqld -l -rwxr-xr-x 1 root root 7157 Dec 21 19:29 /etc/rc.d/init.d/mysqld [root@s197240 mysql]# chkconfig mysqld on [root@s197240 mysql]# chmod 755 /etc/rc.d/init.d/mysqld [root@s197240 mysql]# service mysqld start Starting mysqld: [ OK ] [root@s197240 mysql]# service mysqld status mysqld (pid 28861) is running...
mysql启动后,剩余后面的操作完全按照上面systemctl start mysqld.service步骤下面的过程来就可以了
6、Hive安装
下载连接:
http://archive.apache.org/dist/hive/hive-2.3.2/
(1)上载和解压缩
[root@hadoop ~]# mkdir /hadoop/hive [root@hadoop ~]# cd /hadoop/hive/ [root@hadoop hive]# ls apache-hive-2.3.3-bin.tar.gz [root@hadoop hive]# tar -zxvf apache-hive-2.3.3-bin.tar.gz
(2)配置环境变量
[root@hadoop hive]# vim /etc/profile export JAVA_HOME=/usr/java/jdk1.8.0_151 export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export PATH=$PATH:$JAVA_HOME/bin export HADOOP_HOME=/hadoop/ export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR" export HIVE_HOME=/hadoop/hive/ export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin
#修改完文件后,执行如下命令,让配置生效:
[root@hadoop hive]# source /etc/profile
(3)Hive配置Hadoop HDFS
hive-site.xml配置
进入目录$HIVE_HOME/conf,将hive-default.xml.template文件复制一份并改名为hive-site.xml
[root@hadoop hive]# cd $HIVE_HOME/conf [root@hadoop conf]# cp hive-default.xml.template hive-site.xml
使用hadoop新建hdfs目录,因为在hive-site.xml中有如下配置:
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
<property>
执行hadoop命令新建/user/hive/warehouse目录:
[root@hadoop1 ~]# $HADOOP_HOME/bin/hadoop dfs -mkdir -p /user/hive/warehouse DEPRECATED: Use of this script to execute hdfs command is deprecated. Instead use the hdfs command for it.
#给新建的目录赋予读写权限
[root@hadoop1 ~]# cd $HIVE_HOME [root@hadoop1 hive]# cd conf/ [root@hadoop1 conf]# sh $HADOOP_HOME/bin/hdfs dfs -chmod 777 /user/hive/warehouse
#查看修改后的权限
[root@hadoop1 conf]# sh $HADOOP_HOME/bin/hdfs dfs -ls /user/hive Found 1 items drwxrwxrwx - root supergroup 0 2019-02-26 14:15 /user/hive/warehouse #运用hadoop命令新建/tmp/hive目录 [root@hadoop1 conf]# $HADOOP_HOME/bin/hdfs dfs -mkdir -p /tmp/hive #给目录/tmp/hive赋予读写权限 [root@hadoop1 conf]# $HADOOP_HOME/bin/hdfs dfs -chmod 777 /tmp/hive #检查创建好的目录 [root@hadoop1 conf]# $HADOOP_HOME/bin/hdfs dfs -ls /tmp Found 1 items drwxrwxrwx - root supergroup 0 2019-02-26 14:17 /tmp/hive
将hive_site.xml文件中的{system:java.io.tmpdir}替换为hive的临时目录,例如我替换为$HIVE_HOME/tmp,该目录如果不存在则要自己手工创建,并且赋予读写权限。
[root@hadoop1 conf]# cd $HIVE_HOME [root@hadoop1 hive]# mkdir tmp
配置文件hive-site.xml:
将文件中的所有 system:java.io.tmpdir替换成/hadoop/hive/tmp将文件中所有的 {system:java.io.tmpdir}替换成/hadoop/hive/tmp将文件中所有的system:java.io.tmpdir替换成/hadoop/hive/tmp将文件中所有的{system:user.name}替换为root
(4)配置mysql
把mysql的驱动包上传到Hive的lib目录下:
[root@hadoop lib]# pwd /usr/local/hive/lib [root@hadoop1 lib]# ls |grep mysql mysql-connector-java-5.1.47.jar
(5)修改hive-site.xml数据库相关配置
搜索javax.jdo.option.connectionURL,将该name对应的value修改为MySQL的地址:
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/metastore?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=false</value>
<description>
JDBC connect string for a JDBC metastore.
To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.
For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
</description>
</property>
搜索javax.jdo.option.ConnectionDriverName,将该name对应的value修改为MySQL驱动类路径:
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
搜索javax.jdo.option.ConnectionUserName,将对应的value修改为MySQL数据库登录名:
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>Username to use against metastore database</description>
</property>
搜索javax.jdo.option.ConnectionPassword,将对应的value修改为MySQL数据库的登录密码:
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>oracle</value>
<description>password to use against metastore database</description>
</property>
搜索hive.metastore.schema.verification,将对应的value修改为false:
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
在$HIVE_HOME/conf目录下新建hive-env.sh
[root@hadoop1 conf]# cd $HIVE_HOME/conf [root@hadoop1 conf]# cp hive-env.sh.template hive-env.sh #打开hive-env.sh并添加如下内容 [root@hadoop1 conf]# vim hive-env.sh export HADOOP_HOME=/hadoop/ export HIVE_CONF_DIR=/hadoop/hive/conf export HIVE_AUX_JARS_PATH=/hadoop/hive/lib
(6)MySQL数据库进行初始化
[root@apollo conf]# cd $HIVE_HOME/bin #对数据库进行初始化: [root@hadoop1 bin]# schematool -initSchema -dbType mysql SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/hadoop/hive/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/imp l/StaticLoggerBinder.class]SLF4J: Found binding in [jar:file:/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/ org/slf4j/impl/StaticLoggerBinder.class]SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] Metastore connection URL: jdbc:mysql://localhost:3306/metastore?createDatabaseIfNotEx ist=true&characterEncoding=UTF-8&useSSL=falseMetastore Connection Driver : com.mysql.jdbc.Driver Metastore connection User: root Starting metastore schema initialization to 2.3.0 Initialization script hive-schema-2.3.0.mysql.sql Initialization script completed schemaTool completed
出现上面就是初始化成功,去mysql看下:
mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | metastore | | mysql | | performance_schema | | sys | +--------------------+ 5 rows in set (0.00 sec) mysql> use metastore Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed mysql> show tables; +---------------------------+ | Tables_in_metastore | +---------------------------+ | AUX_TABLE | | BUCKETING_COLS | | CDS | | COLUMNS_V2 | | COMPACTION_QUEUE | | COMPLETED_COMPACTIONS | | COMPLETED_TXN_COMPONENTS | | DATABASE_PARAMS | | DBS | | DB_PRIVS | | DELEGATION_TOKENS | | FUNCS | | FUNC_RU | | GLOBAL_PRIVS | | HIVE_LOCKS | | IDXS | | INDEX_PARAMS | | KEY_CONSTRAINTS | | MASTER_KEYS | | NEXT_COMPACTION_QUEUE_ID | | NEXT_LOCK_ID | | NEXT_TXN_ID | | NOTIFICATION_LOG | | NOTIFICATION_SEQUENCE | | NUCLEUS_TABLES | | PARTITIONS | | PARTITION_EVENTS | | PARTITION_KEYS | | PARTITION_KEY_VALS | | PARTITION_PARAMS | | PART_COL_PRIVS | | PART_COL_STATS | | PART_PRIVS | | ROLES | | ROLE_MAP | | SDS | | SD_PARAMS | | SEQUENCE_TABLE | | SERDES | | SERDE_PARAMS | | SKEWED_COL_NAMES | | SKEWED_COL_VALUE_LOC_MAP | | SKEWED_STRING_LIST | | SKEWED_STRING_LIST_VALUES | | SKEWED_VALUES | | SORT_COLS | | TABLE_PARAMS | | TAB_COL_STATS | | TBLS | | TBL_COL_PRIVS | | TBL_PRIVS | | TXNS | | TXN_COMPONENTS | | TYPES | | TYPE_FIELDS | | VERSION | | WRITE_SET | +---------------------------+ 57 rows in set (0.01 sec)
(7)启动hive:
启动metastore服务
nohup hive --service metastore >> ~/metastore.log 2>&1 &
启动hiveserver2,jdbc连接均需要
nohup hive --service hiveserver2 >> ~/hiveserver2.log 2>&1 &
检测hive和hive2端口
[root@hadoop bin]# netstat -lnp|grep 9083 tcp 0 0 0.0.0.0:9083 0.0.0.0:* LISTEN 11918/java [root@hadoop bin]# netstat -lnp|grep 10000 tcp 0 0 0.0.0.0:10000 0.0.0.0:* LISTEN 12011/java
测试hive
[root@hadoop1 bin]# ./hive which: no hbase in (/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/usr/java/jdk1.8.0_151 /bin:/usr/java/jdk1.8.0_151/bin:/hadoop//bin:/hadoop//sbin:/root/bin:/usr/java/jdk1.8.0_151/bin:/usr/java/jdk1.8.0_151/bin:/hadoop//bin:/hadoop//sbin:/hadoop/hive/bin)SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/hadoop/hive/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/imp l/StaticLoggerBinder.class]SLF4J: Found binding in [jar:file:/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/ org/slf4j/impl/StaticLoggerBinder.class]SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] Logging initialized using configuration in jar:file:/hadoop/hive/lib/hive-common-2.3.3.jar!/ hive-log4j2.properties Async: trueHive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases. hive> show functions; OK ! != $sum0 % 。。。。。 hive> desc function sum; OK sum(x) - Returns the sum of a set of numbers Time taken: 0.183 seconds, Fetched: 1 row(s) hive> create database sbux; OK Time taken: 0.236 seconds hive> use sbux; OK Time taken: 0.033 seconds hive> create table student(id int, name string) row format delimited fields terminated by '\t'; OK Time taken: 0.909 seconds hive> desc student; OK id int name string Time taken: 0.121 seconds, Fetched: 2 row(s) 在$HIVE_HOME下新建一个文件 #进入#HIVE_HOME目录 [root@apollo hive]# cd $HIVE_HOME #新建文件student.dat [root@apollo hive]# touch student.dat #在文件中添加如下内容 [root@apollo hive]# vim student.dat 001 david 002 fab 003 kaishen 004 josen 005 arvin 006 wada 007 weda 008 banana 009 arnold 010 simon 011 scott .导入数据 hive> load data local inpath '/hadoop/hive/student.dat' into table sbux.student; Loading data to table sbux.student OK Time taken: 8.641 seconds hive> use sbux; OK Time taken: 0.052 seconds hive> select * from student; OK 1 david 2 fab 3 kaishen 4 josen 5 arvin 6 wada 7 weda 8 banana 9 arnold 10 simon 11 scott NULL NULL Time taken: 2.217 seconds, Fetched: 12 row(s)
(8)在界面上查看刚刚写入的hdfs数据
在hadoop的namenode上查看:
<ignore_js_op style="overflow-wrap: break-word; color: rgb(68, 68, 68); font-family: "Microsoft Yahei", tahoma, arial, "Hiragino Sans GB", 宋体, sans-serif;">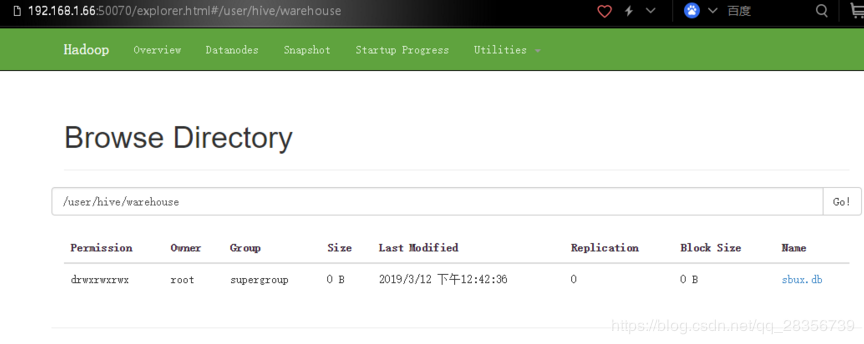
在mysql的hive数据里查看
[root@hadoop1 bin]# mysql -u root -p Enter password: mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | metastore | | mysql | | performance_schema | | sys | +--------------------+ 5 rows in set (0.00 sec) mysql> use metastore; Database changed mysql> select * from TBLS; +--------+-------------+-------+------------------+-------+-----------+-------+----------+---------------+--------------------+--------------------+--------------------+ | TBL_ID | CREATE_TIME | DB_ID | LAST_ACCESS_TIME | OWNER | RETENTION | SD_ID | TBL_NAME | TBL_TYPE | VIEW_EXPANDED_TEXT | VIEW_ORIGINAL_TEXT | IS_REWRITE_ENABLED | +--------+-------------+-------+------------------+-------+-----------+-------+----------+---------------+--------------------+--------------------+--------------------+ | 1 | 1551178545 | 6 | 0 | root | 0 | 1 | student | MANAGED_TABLE | NULL | NULL | | +--------+-------------+-------+------------------+-------+-----------+-------+----------+---------------+--------------------+--------------------+--------------------+ 1 row in set (0.00 sec)
7、Zookeeper安装
上传解压:
[root@hadoop ~]# cd /hadoop/ [root@hadoop hadoop]# pwd /hadoop [root@hadoop hadoop]# mkdir zookeeper [root@hadoop hadoop]# cd zookeeper/ [root@hadoop zookeeper]# tar -zxvf zookeeper-3.4.6.tar.gz 。。 [root@hadoop zookeeper]# ls zookeeper-3.4.6 zookeeper-3.4.6.tar.gz [root@hadoop zookeeper]# rm -rf *gz [root@hadoop zookeeper]# mv zookeeper-3.4.6/* . [root@hadoop zookeeper]# ls bin CHANGES.txt contrib docs ivy.xml LICENSE.txt README_packaging.txt recipes zookeeper-3.4.6 zookeeper-3.4.6.jar.asc zookeeper-3.4.6.jar.sha1 build.xml conf dist-maven ivysettings.xml lib NOTICE.txt README.txt src zookeeper-3.4.6.jar zookeeper-3.4.6.jar.md5
配置配置文件
创建快照日志存放目录: mkdir -p /hadoop/zookeeper/dataDir
【注意】:如果不配置dataLogDir,那么事务日志也会写在dataDir目录中。这样会严重影响zk的性能。因为在zk吞吐量很高的时候,产生的事务日志和快照日志太多。
[root@hadoop zookeeper]# cd conf/ [root@hadoop conf]# mv zoo_sample.cfg zoo.cfg [root@hadoop conf]# cat /hadoop/zookeeper/conf/zoo.cfg |grep -v ^#|grep -v ^$ tickTime=2000 initLimit=10 syncLimit=5 dataDir=/hadoop/zookeeper/dataDir dataLogDir=/hadoop/zookeeper/dataLogDir clientPort=2181 server.1=192.168.1.66:2887:3887
在我们配置的dataDir指定的目录下面,创建一个myid文件,里面内容为一个数字,用来标识当前主机,conf/zoo.cfg文件中配置的server.X中X为什么数字,则myid文件中就输入这个数字:
[root@hadoop conf]# echo "1" > /hadoop/zookeeper/dataDir/myid
启动zookeeper:
[root@hadoop zookeeper]# cd bin/ [root@hadoop bin]# ./zkServer.sh start JMX enabled by default Using config: /hadoop/zookeeper/bin/../conf/zoo.cfg Starting zookeeper ... STARTED [root@hadoop bin]# ./zkServer.sh status JMX enabled by default Using config: /hadoop/zookeeper/bin/../conf/zoo.cfg Mode: standalone [root@hadoop bin]# ./zkCli.sh -server localhost:2181 Connecting to localhost:2181 2019-03-12 11:47:29,355 [myid:] - INFO [main:Environment@100] - Client environment:zookeeper.version=3.4.6-1569965, built on 02/20/2014 09:09 GMT 2019-03-12 11:47:29,360 [myid:] - INFO [main:Environment@100] - Client environment:host.name=hadoop 2019-03-12 11:47:29,361 [myid:] - INFO [main:Environment@100] - Client environment:java.version=1.8.0_151 2019-03-12 11:47:29,364 [myid:] - INFO [main:Environment@100] - Client environment:java.vendor=Oracle Corporation 2019-03-12 11:47:29,364 [myid:] - INFO [main:Environment@100] - Client environment:java.home=/usr/java/jdk1.8.0_151/jre 2019-03-12 11:47:29,364 [myid:] - INFO [main:Environment@100] - Client environment:java.class.path=/hadoop/zookeeper/bin/../build/classes:/hadoop/zookeeper/bin/../build/lib/*.jar:/hadoop/z ookeeper/bin/../lib/slf4j-log4j12-1.6.1.jar:/hadoop/zookeeper/bin/../lib/slf4j-api-1.6.1.jar:/hadoop/zookeeper/bin/../lib/netty-3.7.0.Final.jar:/hadoop/zookeeper/bin/../lib/log4j-1.2.16.jar:/hadoop/zookeeper/bin/../lib/jline-0.9.94.jar:/hadoop/zookeeper/bin/../zookeeper-3.4.6.jar:/hadoop/zookeeper/bin/../src/java/lib/*.jar:/hadoop/zookeeper/bin/../conf:.:/usr/java/jdk1.8.0_151/lib/dt.jar:/usr/java/jdk1.8.0_151/lib/tools.jar2019-03-12 11:47:29,364 [myid:] - INFO [main:Environment@100] - Client environment:java.library.path=/usr/java/packages/lib/amd64:/usr/lib64:/lib64:/lib:/usr/lib 2019-03-12 11:47:29,364 [myid:] - INFO [main:Environment@100] - Client environment:java.io.tmpdir=/tmp 2019-03-12 11:47:29,364 [myid:] - INFO [main:Environment@100] - Client environment:java.compiler=<NA> 2019-03-12 11:47:29,364 [myid:] - INFO [main:Environment@100] - Client environment:os.name=Linux 2019-03-12 11:47:29,364 [myid:] - INFO [main:Environment@100] - Client environment:os.arch=amd64 2019-03-12 11:47:29,364 [myid:] - INFO [main:Environment@100] - Client environment:os.version=3.10.0-957.el7.x86_64 2019-03-12 11:47:29,365 [myid:] - INFO [main:Environment@100] - Client environment:user.name=root 2019-03-12 11:47:29,365 [myid:] - INFO [main:Environment@100] - Client environment:user.home=/root 2019-03-12 11:47:29,365 [myid:] - INFO [main:Environment@100] - Client environment:user.dir=/hadoop/zookeeper/bin 2019-03-12 11:47:29,366 [myid:] - INFO [main:ZooKeeper@438] - Initiating client connection, connectString=localhost:2181 sessionTimeout=30000 watcher=org.apache.zookeeper.ZooKeeperMain$MyW atcher@799f7e29Welcome to ZooKeeper! 2019-03-12 11:47:29,402 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@975] - Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authe nticate using SASL (unknown error)JLine support is enabled 2019-03-12 11:47:29,494 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@852] - Socket connection established to localhost/127.0.0.1:2181, initiating session 2019-03-12 11:47:29,519 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@1235] - Session establishment complete on server localhost/127.0.0.1:2181, sessionid = 0x1696f feb12f0000, negotiated timeout = 30000 WATCHER:: WatchedEvent state:SyncConnected type:None path:null [zk: localhost:2181(CONNECTED) 0] [root@hadoop bin]# jps 12467 QuorumPeerMain 11060 JobHistoryServer 10581 ResourceManager 12085 RunJar 10102 NameNode 12534 Jps 10376 SecondaryNameNode 10201 DataNode 11994 RunJar 10683 NodeManager
发现zookeeper正常起来了
8、Kafka安装
上传解压:
[root@hadoop bin]# cd /hadoop/ [root@hadoop hadoop]# mkdir kafka [root@hadoop hadoop]# cd kafka/ [root@hadoop kafka]# ls kafka_2.11-1.1.1.tgz [root@hadoop kafka]# tar zxf kafka_2.11-1.1.1.tgz [root@hadoop kafka]# mv kafka_2.11-1.1.1/* . [root@hadoop kafka]# ls bin config kafka_2.11-1.1.1 kafka_2.11-1.1.1.tgz libs LICENSE NOTICE site-docs [root@hadoop kafka]# rm -rf *tgz [root@hadoop kafka]# ls bin config kafka_2.11-1.1.1 libs LICENSE NOTICE site-docs
修改配置文件:
[root@hadoop kafka]# cd config/ [root@hadoop config]# ls connect-console-sink.properties connect-file-sink.properties connect-standalone.properties producer.properties zookeeper.properties connect-console-source.properties connect-file-source.properties consumer.properties server.properties connect-distributed.properties connect-log4j.properties log4j.properties tools-log4j.properties [root@hadoop config]# vim server.properties
配置如下:
[root@hadoop config]# cat server.properties |grep -v ^#|grep -v ^$ broker.id=0 listeners=PLAINTEXT://192.168.1.66:9092 num.network.threads=3 num.io.threads=8 socket.send.buffer.bytes=102400 socket.receive.buffer.bytes=102400 socket.request.max.bytes=104857600 log.dirs=/hadoop/kafka/logs num.partitions=1 num.recovery.threads.per.data.dir=1 offsets.topic.replication.factor=1 transaction.state.log.replication.factor=1 transaction.state.log.min.isr=1 log.retention.hours=168 log.segment.bytes=1073741824 log.retention.check.interval.ms=300000 zookeeper.connect=192.168.1.66:2181 zookeeper.connection.timeout.ms=6000 group.initial.rebalance.delay.ms=0 delete.topic.enble=true -----如果不指定这个参数,执行删除操作只是标记删除
启动kafka
[root@hadoop kafka]# nohup bin/kafka-server-start.sh config/server.properties&
查看nohup文件有没有错误信息,没错就没问题。
验证kafka,为了日后操作方便,先来编辑几个常用脚本:
--消费者消费指定topic数据 [root@hadoop kafka]# cat console.sh #!/bin/bash read -p "input topic:" name bin/kafka-console-consumer.sh --zookeeper 192.168.1.66:2181 --topic $name --from-beginning --列出当前所有topic [root@hadoop kafka]# cat list.sh #!/bin/bash bin/kafka-topics.sh -describe -zookeeper 192.168.1.66:2181 --生产者指定topic生产数据 [root@hadoop kafka]# cat productcmd.sh #!/bin/bash read -p "input topic:" name bin/kafka-console-producer.sh --broker-list 192.168.1.66:9092 --topic $name --启动kafka [root@hadoop kafka]# cat startkafka.sh #!/bin/bash nohup bin/kafka-server-start.sh config/server.properties& 关闭kafka [root@hadoop kafka]# cat stopkafka.sh #!/bin/bash bin/kafka-server-stop.sh sleep 6 jps --创建topic [root@hadoop kafka]# cat create.sh read -p "input topic:" name bin/kafka-topics.sh --create --zookeeper 192.168.1.66:2181 --replication-factor 1 --partitions 1 --topic $name
接下来验证kafka可用性:
会话1创建topic
[root@hadoop kafka]# ./create.sh input topic:test Created topic "test".
查看创建的topic
[root@hadoop kafka]# ./list.sh Topic:test PartitionCount:1 ReplicationFactor:1 Configs: Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0
会话1指定test生产数据:
[root@hadoop kafka]# ./productcmd.sh input topic:test >test >
会话2指定test消费数据:
[root@hadoop kafka]# ./console.sh input topic:test Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper] .test
测试可以正常生产和消费。
将kafka和zookeeper相关环境变量加到/etc/profile,并source使其生效。
export ZOOKEEPER_HOME=/hadoop/zookeeper
export KAFKA_HOME=/hadoop/kafka
9、Hbase安装
下载连接:
http://archive.apache.org/dist/hbase/
(1)创建安装目录并上传解压:
[root@hadoop hbase]# tar -zxvf hbase-1.4.9-bin.tar.gz [root@hadoop hbase]# ls hbase-1.4.9 hbase-1.4.9-bin.tar.gz [root@hadoop hbase]# rm -rf *gz mv [root@hadoop hbase]# mv hbase-1.4.9/* . [root@hadoop hbase]# pwd /hadoop/hbase [root@hadoop hbase]# ls bin conf hbase-1.4.9 LEGAL LICENSE.txt README.txt CHANGES.txt docs hbase-webapps lib NOTICE.txt
(2)环境变量配置,我的环境变量如下:
export JAVA_HOME=/usr/java/jdk1.8.0_151 export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export PATH=$PATH:$JAVA_HOME/bin export HADOOP_HOME=/hadoop/ export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR" export HIVE_HOME=/hadoop/hive export HIVE_CONF_DIR=${HIVE_HOME}/conf export HCAT_HOME=$HIVE_HOME/hcatalog export HIVE_DEPENDENCY=/hadoop/hive/conf:/hadoop/hive/lib/*:/hadoop/hive/hcatalog/share/hcatalog/hive-hcatalog-pig-adapter-2.3.3.jar:/hadoop/hive/hcatalog/share/hcatalog/hive-hcatalog-core-2.3.3.jar:/hadoop/hive/hcatalog/share/hcatalog/hive-hcatalog-server-extensions-2.3.3.jar:/hadoop/hive/hcatalog/share/hcatalog/hive-hcatalog-streaming-2.3.3.jar:/hadoop/hive/lib/hive-exec-2.3.3.jar export HBASE_HOME=/hadoop/hbase/ export ZOOKEEPER_HOME=/hadoop/zookeeper export KAFKA_HOME=/hadoop/kafka export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$HCAT_HOME/bin:$HBASE_HOME/bin:$ZOOKEEPER_HOME:$KAFKA_HOME export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:${HIVE_HOME}/lib:$HBASE_HOME/lib
详细配置
修改conf/hbase-env.sh中的HBASE_MANAGES_ZK为false:
[root@hadoop kafka]# cd /hadoop/hbase/ [root@hadoop hbase]# ls bin conf hbase-1.4.9 LEGAL LICENSE.txt README.txt CHANGES.txt docs hbase-webapps lib NOTICE.txt
修改hbase-env.sh文件加入下面内容
[root@hadoop hbase]# vim conf/hbase-env.sh export JAVA_HOME=/usr/java/jdk1.8.0_151 export HADOOP_HOME=/hadoop/ export HBASE_HOME=/hadoop/hbase/ export HBASE_MANAGES_ZK=false
修改配置文件hbase-site.xml
在该配置文件中可以给hbase配置一个临时目录,这里指定为mkdir /root/hbase/tmp,先执行命令创建文件夹。
mkdir /root/hbase mkdir /root/hbase/tmp mkdir /root/hbase/pids
在<configuration>节点内增加以下配置:
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://192.168.1.66:9000/hbase</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/hadoop/zookeeper/dataDir</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>192.168.1.66</value>
<description>the pos of zk</description>
</property>
<!-- 此处必须为true,不然hbase仍用自带的zk,若启动了外部的zookeeper,会导致冲突,hbase启动不起来 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- hbase主节点的位置 -->
<property>
<name>hbase.master</name>
<value>192.168.1.66:60000</value>
</property>
</configuration>
[root@hadoop hbase]# cat conf/regionservers
192.168.1.66
[root@hadoop hbase]# cp /hadoop/zookeeper/conf/zoo.cfg /hadoop/hbase/conf/
启动hbase
[root@hadoop bin]# ./start-hbase.sh running master, logging to /hadoop/hbase//logs/hbase-root-master-hadoop.out Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0 Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0 : running regionserver, logging to /hadoop/hbase//logs/hbase-root-regionserver-hadoop.out : Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0 : Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0 --查看hbase相关进程HMaster、HRegionServer 已经起来了 [root@hadoop bin]# jps 12449 QuorumPeerMain 13094 Kafka 10376 SecondaryNameNode 12046 RunJar 11952 RunJar 11060 JobHistoryServer 10581 ResourceManager 10102 NameNode 10201 DataNode 10683 NodeManager 15263 HMaster 15391 HRegionServer 15679 Jps
10、安装KYLIN
下载连接
http://kylin.apache.org/cn/download/
(1)上传解压
[root@hadoop kylin]# pwd /hadoop/kylin [root@hadoop kylin]# ls apache-kylin-2.4.0-bin-hbase1x.tar.gz [root@hadoop kylin]# tar -zxvf apache-kylin-2.4.0-bin-hbase1x.tar.gz [root@hadoop kylin]# rm -rf apache-kylin-2.4.0-bin-hbase1x.tar.gz [root@hadoop kylin]# [root@hadoop kylin]# mv apache-kylin-2.4.0-bin-hbase1x/* . [root@hadoop kylin]# ls apache-kylin-2.4.0-bin-hbase1x bin commit_SHA1 conf lib sample_cube spark tomcat tool
(2)配置环境变量
/etc/profile内容如下
export JAVA_HOME=/usr/java/jdk1.8.0_151 export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export PATH=$PATH:$JAVA_HOME/bin export HADOOP_HOME=/hadoop/ export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR" export HIVE_HOME=/hadoop/hive export HIVE_CONF_DIR=${HIVE_HOME}/conf export HCAT_HOME=$HIVE_HOME/hcatalog export HIVE_DEPENDENCY=/hadoop/hive/conf:/hadoop/hive/lib/*:/hadoop/hive/hcatalog/share/hcatalog/hive-hcatalog-pig-adapter-2.3.3.jar:/hadoop/hive/hcatalog/share/hcatalog/hive-hcatalog-core-2.3.3.jar:/hadoop/hive/hcatalog/share/hcatalog/hive-hcatalog-server-extensions-2.3.3.jar:/hadoop/hive/hcatalog/share/hcatalog/hive-hcatalog-streaming-2.3.3.jar:/hadoop/hive/lib/hive-exec-2.3.3.jar export HBASE_HOME=/hadoop/hbase/ export ZOOKEEPER_HOME=/hadoop/zookeeper export KAFKA_HOME=/hadoop/kafka export KYLIN_HOME=/hadoop/kylin/ export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$HCAT_HOME/bin:$HBASE_HOME/bin:$ZOOKEEPER_HOME:$KAFKA_HOME:$KYLIN_HOME/bin export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:${HIVE_HOME}/lib:$HBASE_HOME/lib:$KYLIN_HOME/lib [root@hadoop kylin]# source /etc/profile
(3)修改kylin.properties内容
[root@hadoop kylin]# vim conf/kylin.properties kylin.rest.timezone=GMT+8 kylin.rest.servers=192.168.1.66:7070 kylin.job.jar=/hadoop/kylin/lib/kylin-job-2.4.0.jar kylin.coprocessor.local.jar=/hadoop/kylin/lib/kylin-coprocessor-2.4.0.jar kyin.server.mode=all kylin.rest.servers=192.168.1.66:7070
(4)编辑kylin_hive_conf.xml
[root@hadoop kylin]# vim conf/kylin_hive_conf.xml <property> <name>hive.exec.compress.output</name> <value>false</value> <description>Enable compress</description> </property>
(5)编辑server.xml
[root@hadoop kylin]# vim tomcat/conf/server.xml 注释掉下面这点代码: <!-- Connector port="7443" protocol="org.apache.coyote.http11.Http11Protocol" maxThreads="150" SSLEnabled="true" scheme="https" secure="true" keystoreFile="conf/.keystore" keystorePass="changeit" clientAuth="false" sslProtocol="TLS" /> -->
(6)编辑kylin.sh
#additionally add tomcat libs to HBASE_CLASSPATH_PREFIX export HBASE_CLASSPATH_PREFIX=${tomcat_root}/bin/bootstrap.jar:${tomcat_root}/bin/tomcat-juli.jar:${tomcat_root}/lib/*:$hive_dependency:${HBASE_CLASSPATH_PREFIX}
(7)启动kylin
[root@hadoop kylin]# cd bin/ [root@hadoop bin]# pwd /hadoop/kylin/bin [root@hadoop bin]# ./check-env.sh Retrieving hadoop conf dir... KYLIN_HOME is set to /hadoop/kylin [root@hadoop bin]# ./kylin.sh start Retrieving hadoop conf dir... KYLIN_HOME is set to /hadoop/kylin Retrieving hive dependency... 。。。。。。。。。。。 A new Kylin instance is started by root. To stop it, run 'kylin.sh stop' Check the log at /hadoop/kylin/logs/kylin.log Web UI is at http://<hostname>:7070/kylin [root@hadoop bin]# jps 13216 HMaster 10376 SecondaryNameNode 12011 RunJar 11918 RunJar 13070 HQuorumPeer 11060 JobHistoryServer 10581 ResourceManager 31381 RunJar 10102 NameNode 13462 HRegionServer 10201 DataNode 10683 NodeManager 31677 Jps
至此,安装已经完成,大家可以通过http://:7070/kylin去访问kylin了,至于cube及steam cube的官方案例,因为文章长度原因,笔者写到了这篇文章供参考:
hadoop+kylin安装及官方cube/steam cube案例文档
8)初步验证及使用:
测试创建项目从hive库取表:
打开网页:http://192.168.1.66:7070/kylin/login
初始密码:ADMIN/KYLIN
由顶部菜单栏进入 Model 页面,然后点击 Manage Projects。
点击 + Project 按钮添加一个新的项目。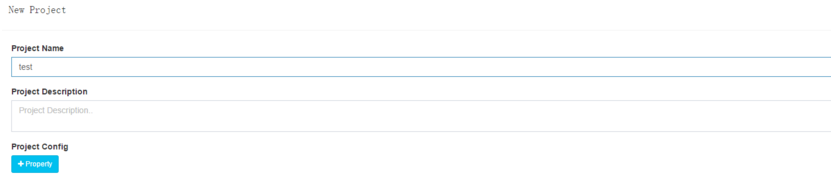

在顶部菜单栏点击 Model,然后点击左边的 Data Source 标签,它会列出所有加载进 Kylin 的表,点击 Load Table 按钮。
输入表名并点击 Sync 按钮提交请求。
接下来就可以看到导入的表结构了:
(2)、运行官方案例:
root@hadoop bin]# pwd /hadoop/kylin/bin [root@hadoop bin]# ./sample.sh Retrieving hadoop conf dir... 。。。。。。。。。 Sample cube is created successfully in project 'learn_kylin'. Restart Kylin Server or click Web UI => System Tab => Reload Metadata to take effect
看到上面最后两条信息就说明案例使用的hive表都创建好了,接下来重启kylin或则 reload metadata
再次刷新页面: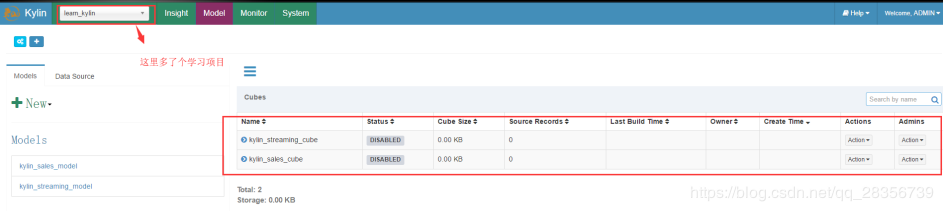
选择第二个kylin_sales_cube
选择bulid,随意选择一个12年以后的日期
然后切换到monitor界面: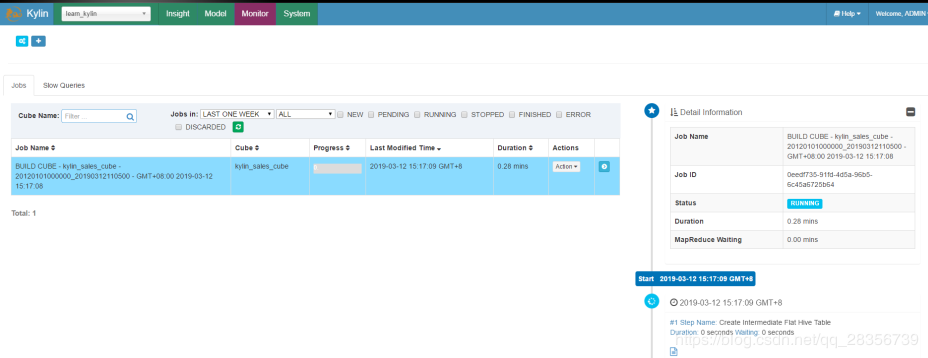
等待cube创建完成。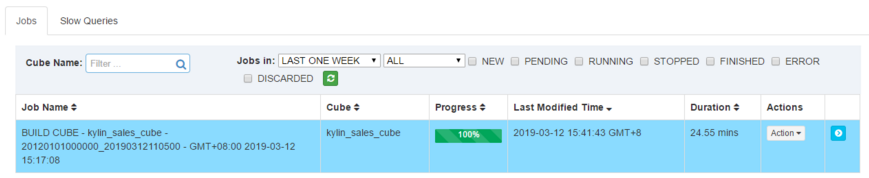
做sql查询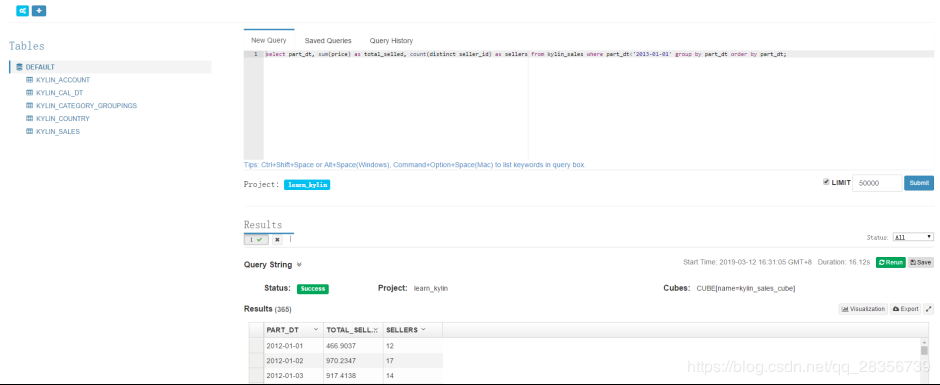
编辑整个环境重启脚本方便日常启停:
环境停止脚本
[root@hadoop hadoop]# cat stop.sh #!/bin/bash echo -e "\n========Start stop kylin========\n" $KYLIN_HOME/bin/kylin.sh stop sleep 5 echo -e "\n========Start stop hbase========\n" $HBASE_HOME/bin/stop-hbase.sh sleep 5 echo -e "\n========Start stop kafka========\n" $KAFKA_HOME/bin/kafka-server-stop.sh $KAFKA_HOME/config/server.properties sleep 3 echo -e "\n========Start stop zookeeper========\n" $ZOOKEEPER_HOME/bin/zkServer.sh stop sleep 3 echo -e "\n========Start stop jobhistory========\n" mr-jobhistory-daemon.sh stop historyserver sleep 3 echo -e "\n========Start stop yarn========\n" stop-yarn.sh sleep 5 echo -e "\n========Start stop dfs========\n" stop-dfs.sh sleep 5 echo -e "\n========Start stop prot========\n" `lsof -i:9083|awk 'NR>=2{print "kill -9 "$2}'|sh` `lsof -i:10000|awk 'NR>=2{print "kill -9 "$2}'|sh` sleep 2 echo -e "\n========Check process========\n" jps
环境启动脚本
[root@hadoop hadoop]# cat start.sh #!/bin/bash echo -e "\n========Start run dfs========\n" start-dfs.sh sleep 5 echo -e "\n========Start run yarn========\n" start-yarn.sh sleep 3 echo -e "\n========Start run jobhistory========\n" mr-jobhistory-daemon.sh start historyserver sleep 2 echo -e "\n========Start run metastore========\n" nohup hive --service metastore >> ~/metastore.log 2>&1 & sleep 10 echo -e "\n========Start run hiveserver2========\n" nohup hive --service hiveserver2 >> ~/hiveserver2.log 2>&1 & sleep 10 echo -e "\n========Check Port========\n" netstat -lnp|grep 9083 sleep 5 netstat -lnp|grep 10000 sleep 2 echo -e "\n========Start run zookeeper========\n" $ZOOKEEPER_HOME/bin/zkServer.sh start sleep 5 echo -e "\n========Start run kafka========\n" $KAFKA_HOME/bin/kafka-server-start.sh $KAFKA_HOME/config/server.properties sleep 5 echo -e "\n========Start run hbase========\n" $HBASE_HOME/bin/start-hbase.sh sleep 5 echo -e "\n========Check process========\n" jps sleep 1 echo -e "\n========Start run kylin========\n" $KYLIN_HOME/bin/kylin.sh start
11.安装scala
cd /home/tom $ tar -xzvf scala-2.10.6.tgz
在/etc/profile文件的末尾添加环境变量:
export SCALA_HOME=/home/tom//scala-2.10.6 export PATH=$SCALA_HOME/bin:$PATH
保存并更新/etc/profile:
source /etc/profile
查看是否成功:
scala -version
12.安装Spark
cd /home/tom $ tar -xzvf spark-1.6.0-bin-hadoop2.6.tgz $ mv spark-1.6.0-bin-hadoop2.6 spark-1.6.0 $ sudo vim /etc/profile[/mw_shl_code]
在/etc/profile文件的末尾添加环境变量:
export SPARK_HOME=/home/tom/spark-1.6.0 export PATH=$SPARK_HOME/bin:$PATH
保存并更新/etc/profile:
source /etc/profile
在conf目录下复制并重命名spark-env.sh.template为spark-env.sh:
cp spark-env.sh.template spark-env.sh $ vi spark-env.sh
在spark-env.sh中添加:
export JAVA_HOME=/home/tom/jdk1.8.0_73/ export SCALA_HOME=/home/tom//scala-2.10.6 export SPARK_MASTER_IP=localhost export SPARK_WORKER_MEMORY=4G
启动
$SPARK_HOME/sbin/start-all.sh
停止
$SPARK_HOME/sbin/stop-all.sh
测试Spark是否安装成功:
$SPARK_HOME/bin/run-example SparkPi
检查WebUI,浏览器打开端口:http://localhost:8080
查看集群环境
http://master:8080/ 访问正常
进入spark-shell
$spark-shell 执行正常如下图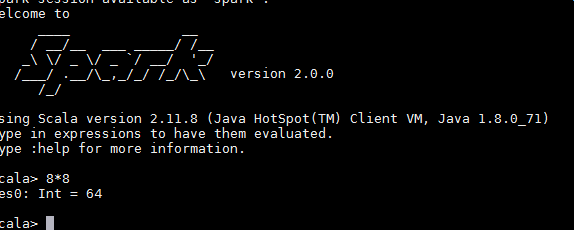
查看jobs等信息
http://master:4040/jobs/ 访问正常。
13、Flink安装
一:安装
Flink官网下载地址:https://flink.apache.org/downloads.html
选择1.6.3版本

下载:
wget http://mirrors.hust.edu.cn/apache/flink/flink-1.7.1/flink-1.7.1-bin-hadoop26-scala_2.11.tgz
解压:
tar -zxvf flink-1.6.3-bin-hadoop26-scala_2.11.tgz mv flink-1.6.3 flink
查看本机host
进入flink目录,修改conf/flink-conf.yaml文件
vim conf/flink-conf.yaml
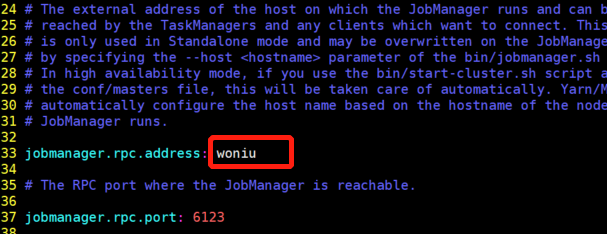
修改conf/masters文件,修改后内容如下:
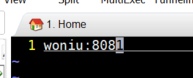
启动单机版flink:
bin/start-cluster.sh
启动界面如下:
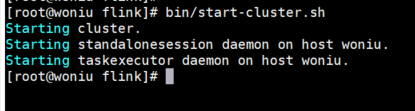
查看启动是否成功:
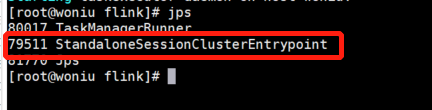
查看dashboard界面:http://192.168.186.129:808

二:官方案例演示
1.启动一个终端输入如下指令:
nc -lk 8000
2.启动第二个终端,执行flink自带的wordcount案例
bin/flink run examples/streaming/SocketWindowWordCount.jar --port 8000

3.在第一个终端发送数据:
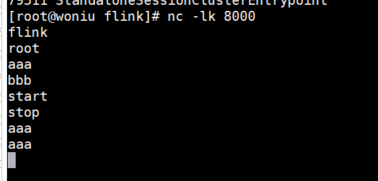
4.测试结果保存在log/flink-root-taskexecutor-0-woniu.out文件中
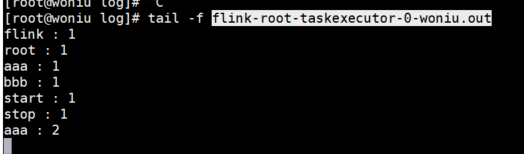
5. Dashboard也可以看到任务信息

本文来自博客园,作者:大码王,转载请注明原文链接:https://www.cnblogs.com/huanghanyu/

 posted on
posted on










【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具