
一 环境:

spark-2.2.0; hive-1.1.0; scala-2.11.8; hadoop-2.6.0-cdh-5.15.0; jdk-1.8;
mongodb-2.4.10;
二.数据情况:
MongoDB数据格式
{
"_id" : ObjectId("5ba0569cafc9ec432bd310a3"),
"id" : 7,
"name" : "7mongoDBi am using mongodb now",
"location" : "shanghai",
"sex" : "male",
"position" : "big data platform engineer"
}
Hive普通表 create table mgtohive_2( id string, name string, age string, deptno string )row format delimited fields terminated by '\t';
create table mgtohive_2(
id int,
name string,
location string,
sex string,
position string
)
row format delimited fields terminated by '\t';
Hive分区表
create table mg_hive_external(
id int,
name string,
location string,
position string
)
PARTITIONED BY(sex string)
row format delimited fields terminated by '\t';
三.Eclipse+Maven+Java
3.1 依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.2.0</version>
</dependency>
<dependency>
<groupId>org.mongodb</groupId>
<artifactId>mongo-java-driver</artifactId>
<version>3.6.3</version>
</dependency>
<dependency>
<groupId>org.mongodb.spark</groupId>
<artifactId>mongo-spark-connector_2.11</artifactId>
<version>2.2.2</version>
</dependency>
3.2 代码:
package com.mobanker.mongo2hive.Mongo2Hive; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.Function; import org.apache.spark.sql.Dataset; import org.apache.spark.sql.Row; import org.apache.spark.sql.RowFactory; import org.apache.spark.sql.SparkSession; import org.apache.spark.sql.hive.HiveContext; import org.apache.spark.sql.types.DataTypes; import org.apache.spark.sql.types.StructField; import org.apache.spark.sql.types.StructType; import org.bson.Document; import com.mongodb.spark.MongoSpark; import java.io.File; import java.util.ArrayList; import java.util.List; public class Mongo2Hive { public static void main(String[] args) { //spark 2.x String warehouseLocation = new File("spark-warehouse").getAbsolutePath(); SparkSession spark = SparkSession.builder() .master("local[2]") .appName("SparkReadMgToHive") .config("spark.sql.warehouse.dir", warehouseLocation) .config("spark.mongodb.input.uri", "mongodb://10.40.20.47:27017/test_db.test_table") .enableHiveSupport() .getOrCreate(); JavaSparkContext sc = new JavaSparkContext(spark.sparkContext()); // spark 1.x // JavaSparkContext sc = new JavaSparkContext(conf); // sc.addJar("/Users/mac/zhangchun/jar/mongo-spark-connector_2.11-2.2.2.jar"); // sc.addJar("/Users/mac/zhangchun/jar/mongo-java-driver-3.6.3.jar"); // SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("SparkReadMgToHive"); // conf.set("spark.mongodb.input.uri", "mongodb://127.0.0.1:27017/test.mgtest"); // conf.set("spark. serializer","org.apache.spark.serializer.KryoSerialzier"); // HiveContext sqlContext = new HiveContext(sc); // //create df from mongo // Dataset<Row> df = MongoSpark.read(sqlContext).load().toDF(); // df.select("id","name","name").show(); String querysql= "select id,name,location,sex,position from mgtohive_2 b"; String opType ="P"; SQLUtils sqlUtils = new SQLUtils(); List<String> column = sqlUtils.getColumns(querysql); //create rdd from mongo JavaRDD<Document> rdd = MongoSpark.load(sc); //将Document转成Object JavaRDD<Object> Ordd = rdd.map(new Function<Document, Object>() { public Object call(Document document){ List list = new ArrayList(); for (int i = 0; i < column.size(); i++) { list.add(String.valueOf(document.get(column.get(i)))); } return list; // return list.toString().replace("[","").replace("]",""); } }); System.out.println(Ordd.first()); //通过编程方式将RDD转成DF List ls= new ArrayList(); for (int i = 0; i < column.size(); i++) { ls.add(column.get(i)); } String schemaString = ls.toString().replace("[","").replace("]","").replace(" ",""); System.out.println(schemaString); List<StructField> fields = new ArrayList<StructField>(); for (String fieldName : schemaString.split(",")) { StructField field = DataTypes.createStructField(fieldName, DataTypes.StringType, true); fields.add(field); } StructType schema = DataTypes.createStructType(fields); JavaRDD<Row> rowRDD = Ordd.map((Function<Object, Row>) record -> { List fileds = (List) record; // String[] attributes = record.toString().split(","); return RowFactory.create(fileds.toArray()); }); Dataset<Row> df = spark.createDataFrame(rowRDD,schema); //将DF写入到Hive中 //选择Hive数据库 spark.sql("use datalake"); //注册临时表 df.registerTempTable("mgtable"); if ("O".equals(opType.trim())) { System.out.println("数据插入到Hive ordinary table"); Long t1 = System.currentTimeMillis(); spark.sql("insert into mgtohive_2 " + querysql + " " + "where b.id not in (select id from mgtohive_2)"); System.out.println("insert into mgtohive_2 " + querysql + " "); Long t2 = System.currentTimeMillis(); System.out.println("共耗时:" + (t2 - t1) / 60000 + "分钟"); }else if ("P".equals(opType.trim())) { System.out.println("数据插入到Hive dynamic partition table"); Long t3 = System.currentTimeMillis(); //必须设置以下参数 否则报错 spark.sql("set hive.exec.dynamic.partition.mode=nonstrict"); //sex为分区字段 select语句最后一个字段必须是sex spark.sql("insert into mg_hive_external partition(sex) select id,name,location,position,sex from mgtable b where b.id not in (select id from mg_hive_external)"); Long t4 = System.currentTimeMillis(); System.out.println("共耗时:"+(t4 -t3)/60000+ "分钟"); } spark.stop(); } }
工具类:
package com.mobanker.mongo2hive.Mongo2Hive; import java.util.ArrayList; import java.util.List; public class SQLUtils { public List<String> getColumns(String querysql){ List<String> column = new ArrayList<String>(); String tmp = querysql.substring(querysql.indexOf("select") + 6, querysql.indexOf("from")).trim(); if (tmp.indexOf("*") == -1){ String cols[] = tmp.split(","); for (String c:cols){ column.add(c); } } return column; } public String getTBname(String querysql){ String tmp = querysql.substring(querysql.indexOf("from")+4).trim(); int sx = tmp.indexOf(" "); if(sx == -1){ return tmp; }else { return tmp.substring(0,sx); } } }
四 错误解决办法:
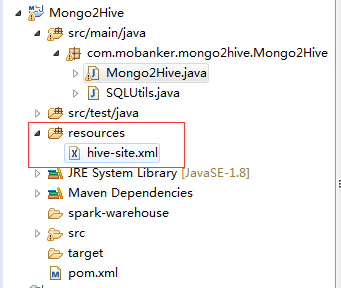
下载cdh集群Hive的hive-site.xml文件,在项目中新建resources文件夹,讲hive-site.xml配置文件放入其中:
五 执行情况:
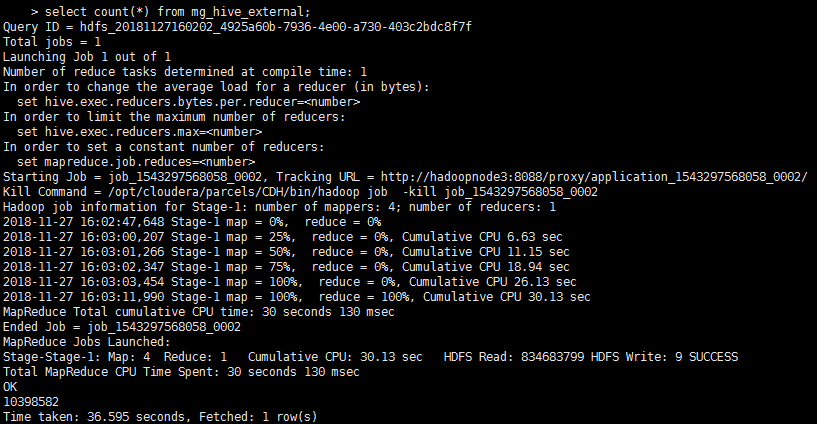
耗时14mins,写入hive表10398582条数据:
本文来自博客园,作者:大码王,转载请注明原文链接:https://www.cnblogs.com/huanghanyu/
分类:
离线数据仓库

 posted on
posted on










【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具