
今天介绍用 Flink 读取Kafka生成的数据,并进行汇总的案例
第一步:环境准备,kafka,flink,zookeeper。我这边是用的CDH环境,kafka跟zookeeper 都安装完毕,并测试可以正常使用
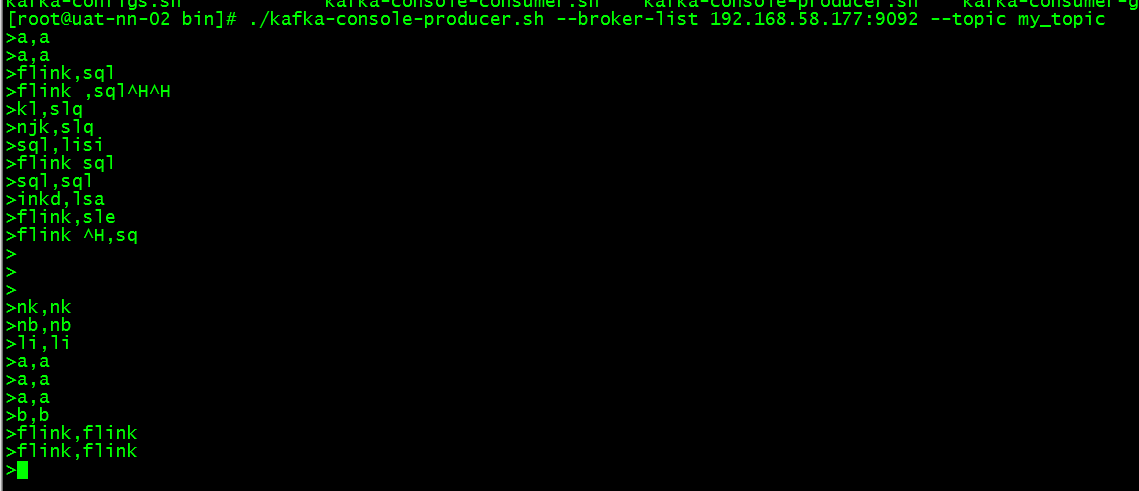
第二步:用kafka创建一个生产者进行消息生产
./kafka-console-producer.sh --broker-list 192.168.58.177:9092 --topic my_topic
3. 第三步:在idea里面创建一个flink项目。代码如下:

StreamExecutionEnvironment Env = StreamExecutionEnvironment.getExecutionEnvironment(); Properties properties = new Properties(); properties.setProperty("bootstrap.servers", "192.168.58.177:9092"); properties.setProperty("zookeeper.connect", "192.168.58.171:2181,192.168.58.177:2181"); properties.setProperty("group.id", "test"); FlinkKafkaConsumer<String> myConsumer = new FlinkKafkaConsumer<String>("my_topic",new SimpleStringSchema(),properties); myConsumer.setStartFromLatest(); myConsumer.setStartFromGroupOffsets(); Env.setParallelism(2).setStreamTimeCharacteristic(TimeCharacteristic.EventTime); DataStream<Tuple2<String,Integer>> stream = Env.addSource(myConsumer) .flatMap((String lines, Collector<Tuple2<String,Integer>> out) -> Stream.of(lines.split(",")) .forEach(a -> out.collect(Tuple2.of(a,1)))) .returns(Types.TUPLE(Types.STRING,Types.INT)) .keyBy(0) //.window(TumblingEventTimeWindows.of(Time.seconds(5))) .sum(1) ; //stream.writeAsText("C:\\Users\\yaowentao\\Desktop\\a"); stream.print(); Env.execute("my first stream flink");
第四步:返回kafka进行消息输入,并观察控制台是否有数据输出


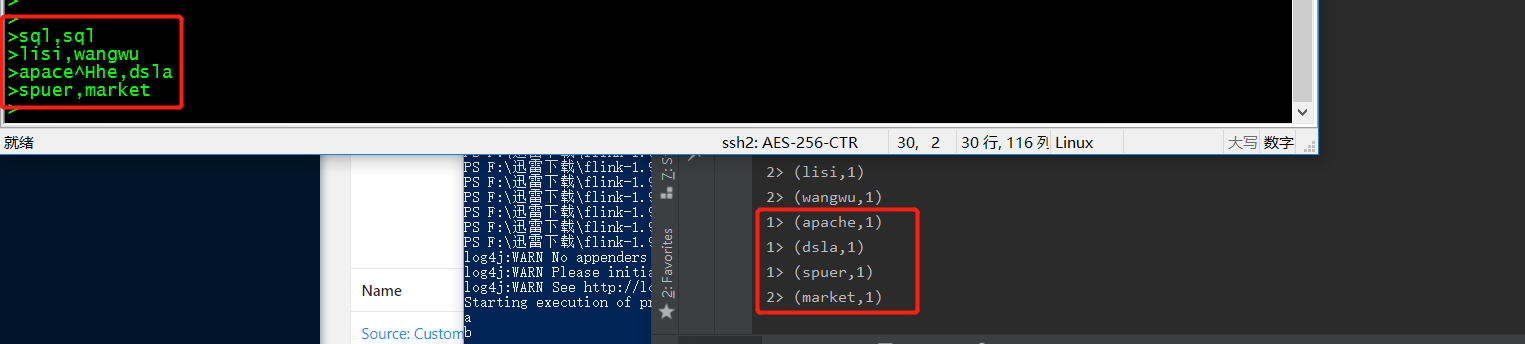
这样就能初步实现 flink读取kafka的消息
本文来自博客园,作者:大码王,转载请注明原文链接:https://www.cnblogs.com/huanghanyu/

 posted on
posted on










【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具