
前言
我给大家介绍了 Flink Data Source 以及简短的介绍了一下自定义 Data Source,这篇文章更详细的介绍下,并写一个 demo 出来让大家理解。
Flink Kafka source
准备工作
我们先来看下 Flink 从 Kafka topic 中获取数据的 demo,首先你需要安装好了 FLink 和 Kafka 。
运行启动 Flink、Zookepeer、Kafka,
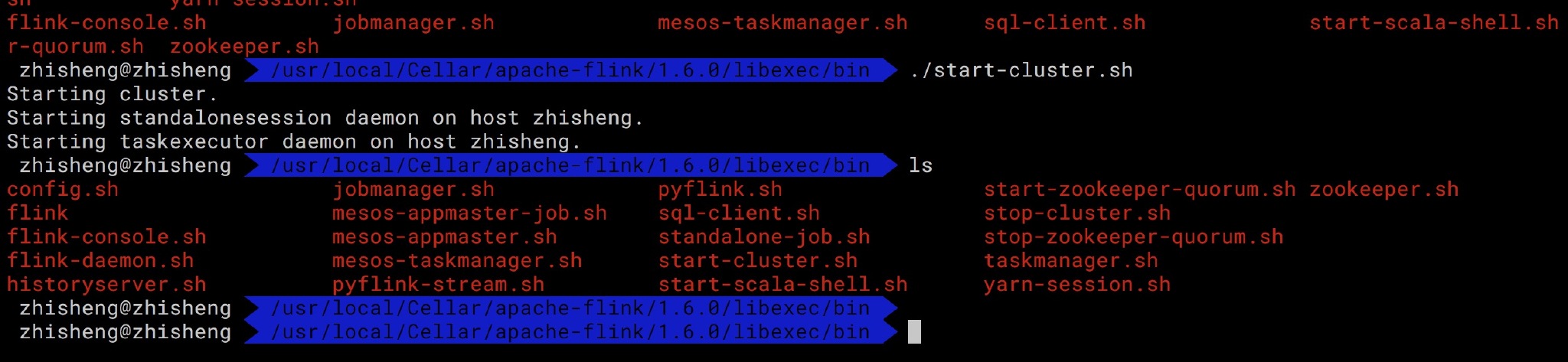

好了,都启动了!
maven 依赖

<!--flink java--> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_${scala.binary.version}</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> <!--日志--> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.7</version> <scope>runtime</scope> </dependency> <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>1.2.17</version> <scope>runtime</scope> </dependency> <!--flink kafka connector--> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka-0.11_${scala.binary.version}</artifactId> <version>${flink.version}</version> </dependency> <!--alibaba fastjson--> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.51</version> </dependency>
实体类,Metric.java测试发送数据到 kafka topic
import java.util.Map; public class Metric { public String name; public long timestamp; public Map<String, Object> fields; public Map<String, String> tags; public Metric() { } public Metric(String name, long timestamp, Map<String, Object> fields, Map<String, String> tags) { this.name = name; this.timestamp = timestamp; this.fields = fields; this.tags = tags; } @Override public String toString() { return "Metric{" + "name='" + name + '\'' + ", timestamp='" + timestamp + '\'' + ", fields=" + fields + ", tags=" + tags + '}'; } public String getName() { return name; } public void setName(String name) { this.name = name; } public long getTimestamp() { return timestamp; } public void setTimestamp(long timestamp) { this.timestamp = timestamp; } public Map<String, Object> getFields() { return fields; } public void setFields(Map<String, Object> fields) { this.fields = fields; } public Map<String, String> getTags() { return tags; } public void setTags(Map<String, String> tags) { this.tags = tags; } }
往 kafka 中写数据工具类:KafkaUtils.java
import com.alibaba.fastjson.JSON; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerRecord; import java.util.HashMap; import java.util.Map; import java.util.Properties; public class KafkaUtils { public static final String broker_list = "localhost:9092"; public static final String topic = "metric"; // kafka topic,Flink 程序中需要和这个统一 public static void writeToKafka() throws InterruptedException { Properties props = new Properties(); props.put("bootstrap.servers", broker_list); props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); //key 序列化 props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); //value 序列化 KafkaProducer producer = new KafkaProducer<String, String>(props); Metric metric = new Metric(); metric.setTimestamp(System.currentTimeMillis()); metric.setName("mem"); Map<String, String> tags = new HashMap<>(); Map<String, Object> fields = new HashMap<>(); tags.put("cluster", "zhisheng"); tags.put("host_ip", "101.147.022.106"); fields.put("used_percent", 90d); fields.put("max", 27244873d); fields.put("used", 17244873d); fields.put("init", 27244873d); metric.setTags(tags); metric.setFields(fields); ProducerRecord record = new ProducerRecord<String, String>(topic, null, null, JSON.toJSONString(metric)); producer.send(record); System.out.println("发送数据: " + JSON.toJSONString(metric)); producer.flush(); } public static void main(String[] args) throws InterruptedException { while (true) { Thread.sleep(300); writeToKafka(); } } }
运行:
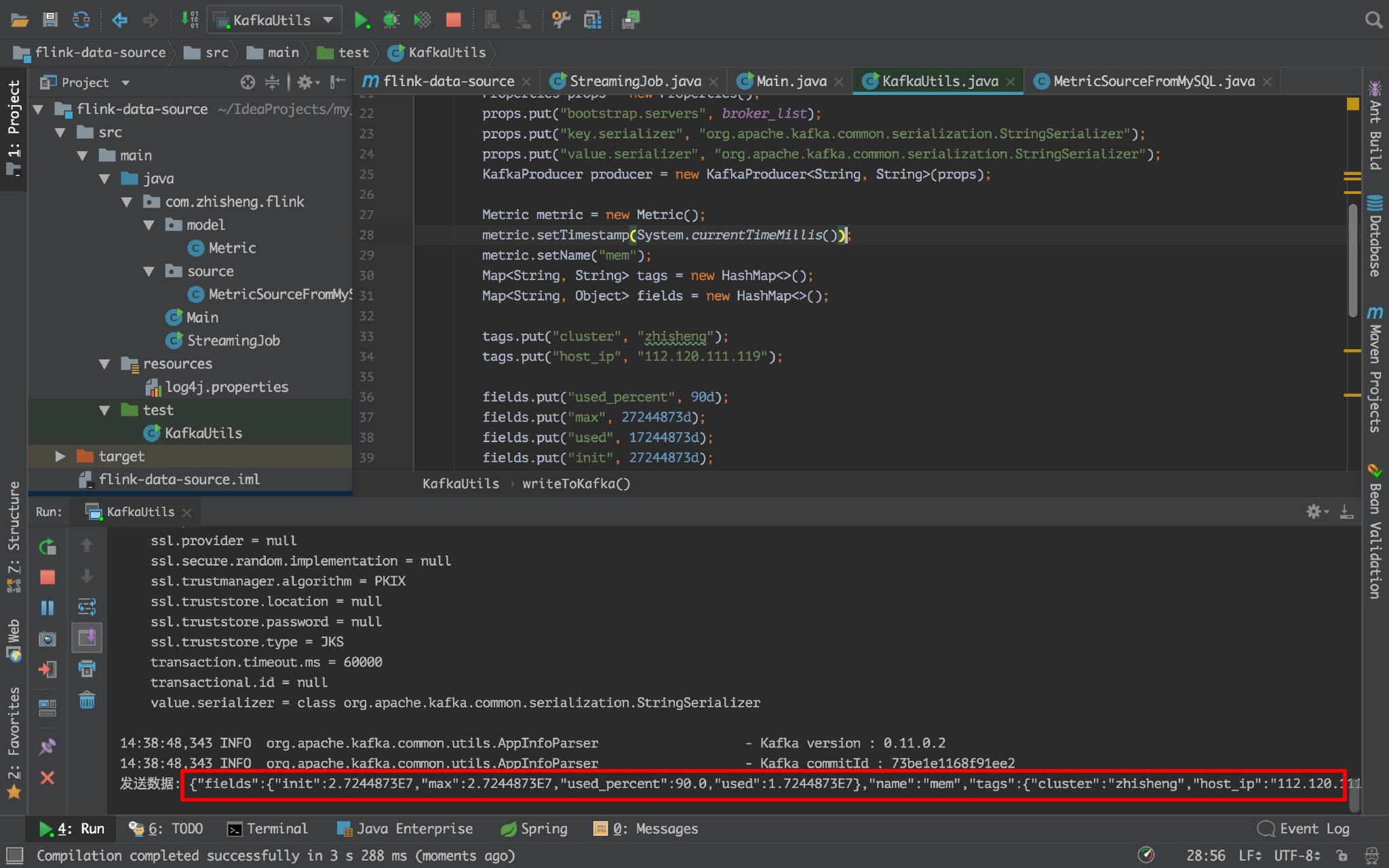
如果出现如上图标记的,即代表能够不断的往 kafka 发送数据的。
Flink 程序
Main.java
import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011; import java.util.Properties; public class Main { public static void main(String[] args) throws Exception { final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("zookeeper.connect", "localhost:2181"); props.put("group.id", "metric-group"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); //key 反序列化 props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("auto.offset.reset", "latest"); //value 反序列化 DataStreamSource<String> dataStreamSource = env.addSource(new FlinkKafkaConsumer011<>( "metric", //kafka topic new SimpleStringSchema(), // String 序列化 props)).setParallelism(1); dataStreamSource.print(); //把从 kafka 读取到的数据打印在控制台 env.execute("Flink add data source"); } }
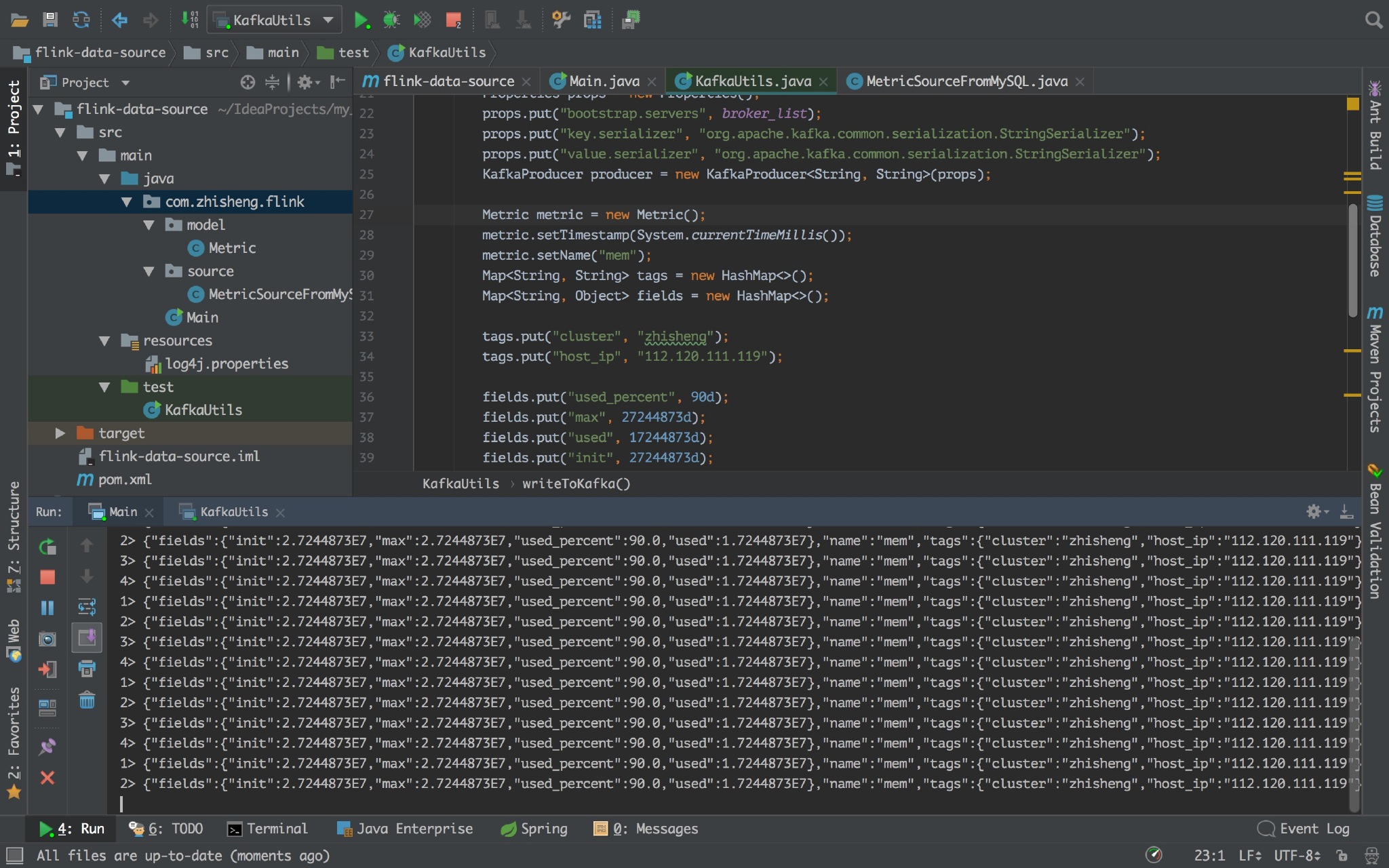 运行起来:
运行起来:
看到没程序,Flink 程序控制台能够源源不断的打印数据呢。
自定义 Source
上面就是 Flink 自带的 Kafka source,那么接下来就模仿着写一个从 MySQL 中读取数据的 Source。
首先 pom.xml 中添加 MySQL 依赖:
<dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.34</version> </dependency>
数据库建表如下:
DROP TABLE IF EXISTS `student`; CREATE TABLE `student` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `name` varchar(25) COLLATE utf8_bin DEFAULT NULL, `password` varchar(25) COLLATE utf8_bin DEFAULT NULL, `age` int(10) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
插入数据:
INSERT INTO `student` VALUES ('1', 'zhisheng01', '123456', '18'), ('2', 'zhisheng02', '123', '17'), ('3', 'zhisheng03', '1234', '18'), ('4', 'zhisheng04', '12345', '16'); COMMIT;
新建实体类:Student.java
public class Student { public int id; public String name; public String password; public int age; public Student() { } public Student(int id, String name, String password, int age) { this.id = id; this.name = name; this.password = password; this.age = age; } @Override public String toString() { return "Student{" + "id=" + id + ", name='" + name + '\'' + ", password='" + password + '\'' + ", age=" + age + '}'; } public int getId() { return id; } public void setId(int id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } public String getPassword() { return password; } public void setPassword(String password) { this.password = password; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } }
新建 Source 类 SourceFromMySQL.java,该类继承 RichSourceFunction ,实现里面的 open、close、run、cancel 方法:
import com.zhisheng.flink.model.Student; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.functions.source.RichSourceFunction; import java.sql.Connection; import java.sql.DriverManager; import java.sql.PreparedStatement; import java.sql.ResultSet; public class SourceFromMySQL extends RichSourceFunction<Student> { PreparedStatement ps; private Connection connection; /** * open() 方法中建立连接,这样不用每次 invoke 的时候都要建立连接和释放连接。 * * @param parameters * @throws Exception */ @Override public void open(Configuration parameters) throws Exception { super.open(parameters); connection = getConnection(); String sql = "select * from Student;"; ps = this.connection.prepareStatement(sql); } /** * 程序执行完毕就可以进行,关闭连接和释放资源的动作了 * * @throws Exception */ @Override public void close() throws Exception { super.close(); if (connection != null) { //关闭连接和释放资源 connection.close(); } if (ps != null) { ps.close(); } } /** * DataStream 调用一次 run() 方法用来获取数据 * * @param ctx * @throws Exception */ @Override public void run(SourceContext<Student> ctx) throws Exception { ResultSet resultSet = ps.executeQuery(); while (resultSet.next()) { Student student = new Student( resultSet.getInt("id"), resultSet.getString("name").trim(), resultSet.getString("password").trim(), resultSet.getInt("age")); ctx.collect(student); } } @Override public void cancel() { } private static Connection getConnection() { Connection con = null; try { Class.forName("com.mysql.jdbc.Driver"); con = DriverManager.getConnection("jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8", "root", "root123456"); } catch (Exception e) { System.out.println("-----------mysql get connection has exception , msg = "+ e.getMessage()); } return con; } }
Flink 程序:
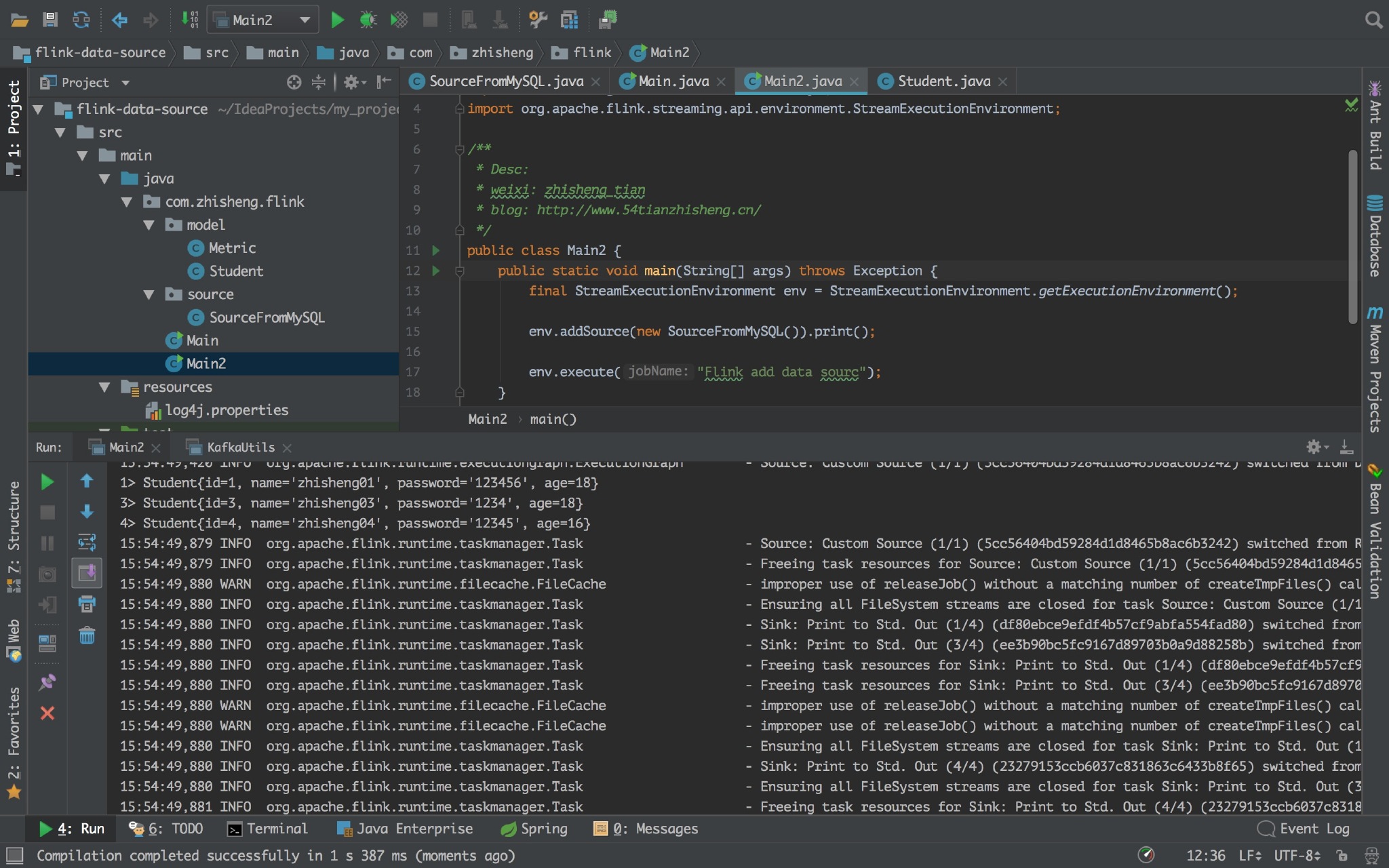
import com.zhisheng.flink.source.SourceFromMySQL; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class Main2 { public static void main(String[] args) throws Exception { final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.addSource(new SourceFromMySQL()).print(); env.execute("Flink add data sourc"); } }
运行 Flink 程序,控制台日志中可以看见打印的 student 信息。
RichSourceFunction
从上面自定义的 Source 可以看到我们继承的就是这个 RichSourceFunction 类,那么来了解一下:
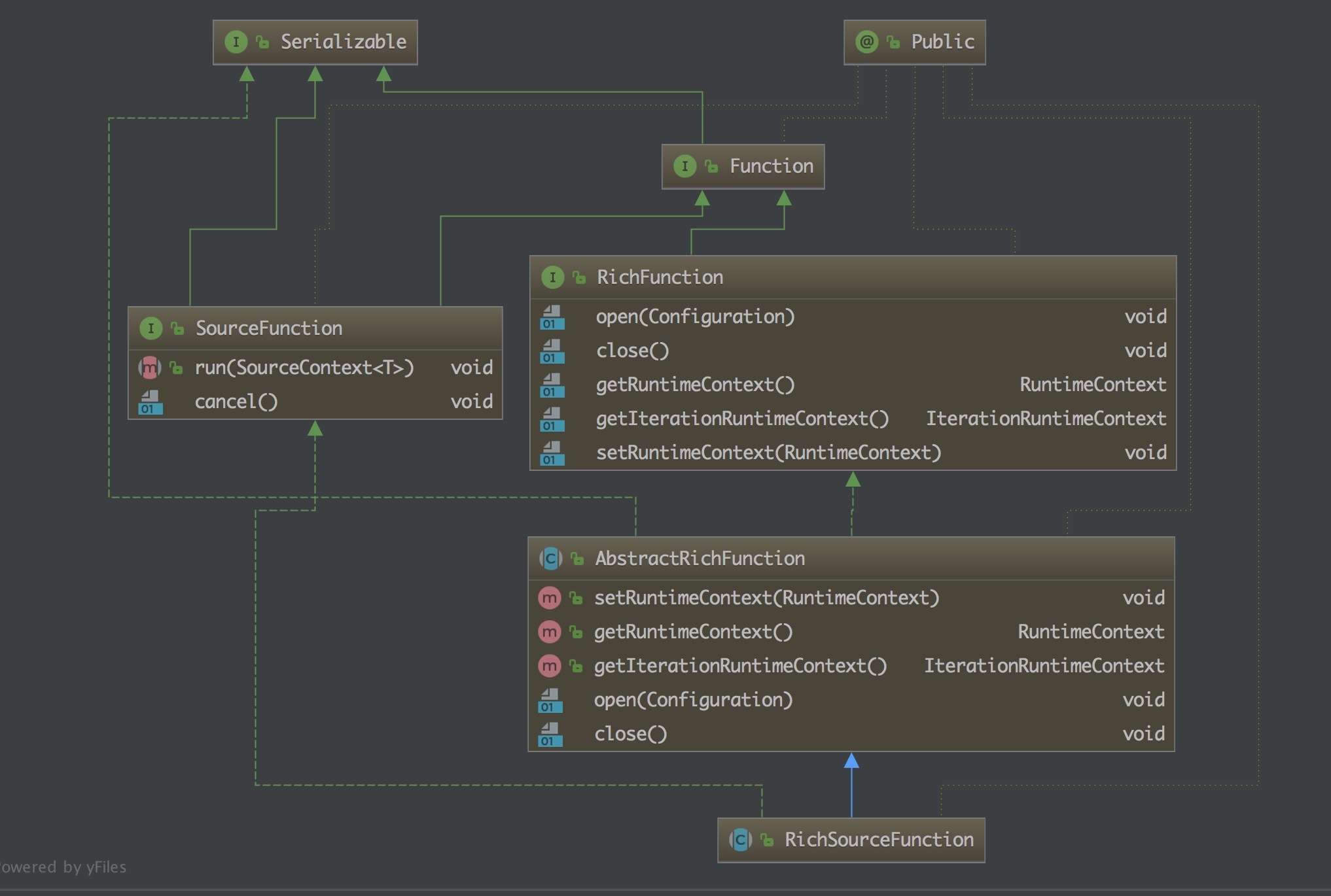
一个抽象类,继承自 AbstractRichFunction。为实现一个 Rich SourceFunction 提供基础能力。该类的子类有三个,两个是抽象类,在此基础上提供了更具体的实现,另一个是 ContinuousFileMonitoringFunction。
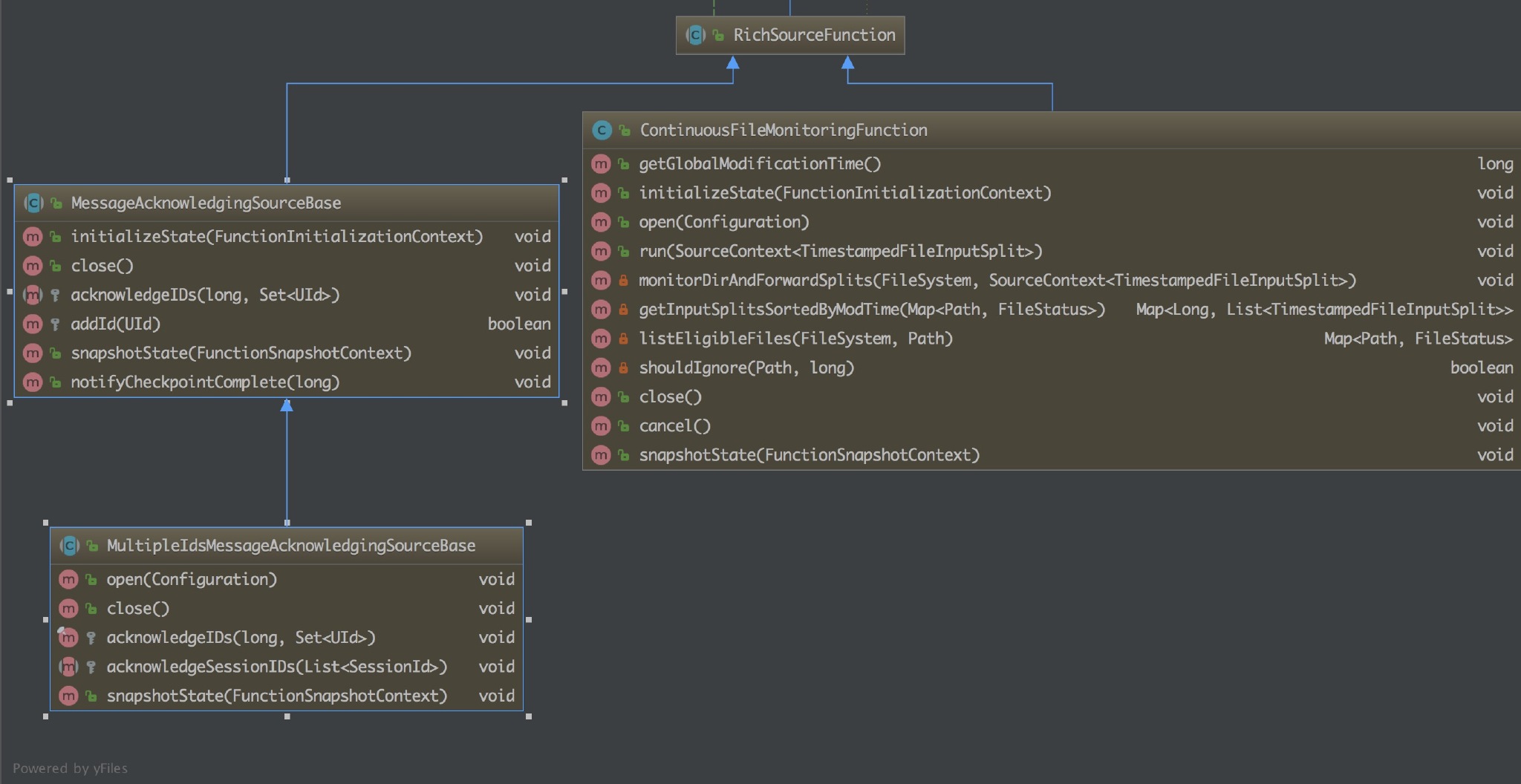
- MessageAcknowledgingSourceBase :它针对的是数据源是消息队列的场景并且提供了基于 ID 的应答机制。
- MultipleIdsMessageAcknowledgingSourceBase : 在 MessageAcknowledgingSourceBase 的基础上针对 ID 应答机制进行了更为细分的处理,支持两种 ID 应答模型:session id 和 unique message id。
- ContinuousFileMonitoringFunction:这是单个(非并行)监视任务,它接受 FileInputFormat,并且根据 FileProcessingMode 和 FilePathFilter,它负责监视用户提供的路径;决定应该进一步读取和处理哪些文件;创建与这些文件对应的 FileInputSplit 拆分,将它们分配给下游任务以进行进一步处理。
最后
本文主要讲了下 Flink 使用 Kafka Source 的使用,并提供了一个 demo 教大家如何自定义 Source,从 MySQL 中读取数据,当然你也可以从其他地方读取,实现自己的数据源 source。可能平时工作会比这个更复杂,需要大家灵活应对!
本文来自博客园,作者:大码王,转载请注明原文链接:https://www.cnblogs.com/huanghanyu/

 posted on
posted on










【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具