

自从科学,技术和人工智能的最初立场出发,跟随布莱斯·帕斯卡(Blaise Pascal)和冯·莱布尼兹(Von Leibniz)的科学家们在思考这种机器具有与人类一样多的智力。儒勒
·凡尔纳(Jules Verne),弗兰克·鲍姆(Frank Baum,绿野仙踪),玛丽·雪莉(Frankkenstein),乔治·卢卡斯(George Lucas,星球大战)等著名作家梦ed以求的是类似于人类行为的人造生物,甚至在不同的环境中淹没了人性化的技能。

Pascal的机器执行减法和求和– 1642年
机器学习是AI的重要途径之一,在研究或行业中AI是非常热门的话题。公司,大学投入大量资源来提高知识水平。该领域的最新进展为不同任务提供了非常可观的结果,与人类的表现相当(交通标志的 98.98%-高于人类)。
在这里,我想分享一个简单的机器学习时间表,并签署一些尚未完成的里程碑。另外,您应该在文本中任何参数的开头添加“据我所知”。
希伯(Hebb)于1949年根据神经心理学学习方法提出了迈向流行性ML的第一步。这就是所谓的赫本学习理论。通过简单的解释,它可以找到递归神经网络(RNN)节点之间的相关性。它可以记住网络上的任何共同点,并在以后充当内存。正式地,论点指出:
让我们假设,反射性活动(或“痕迹”)的持续或重复趋向于诱导持久的细胞变化,从而增加其稳定性。……当 细胞 A 的 轴突 足够接近以激发细胞 B 并反复或持续吸收时在射击它的过程中,一个或两个细胞都发生了某些生长过程或代谢变化,从而随着射击B的其中一个细胞, A 的效率 得以提高。[1]

亚瑟·塞缪尔(Arthur Samuel)
1952年,IBM的Arthur Samuel开发了一个播放Checkers的程序。该程序能够观察位置并学习隐式模型,从而为后一种情况提供更好的动作。塞缪尔(Samuel)使用该程序玩了很多游戏,并观察到该程序在一段时间内可以玩得更好。
塞缪尔(Samuel)在该程序中混淆了一般的要求,使机器无法超越书面代码,无法学习人类的模式。他创造了“机器学习”,他将其定义为:
无需明确编程即可赋予计算机功能的研究领域。

罗森布拉特
1957年,罗森布拉特的 感知器是神经科学背景下再次提出的第二种模型,它与当今的ML模型更加相似。当时,这是一个非常令人兴奋的发现,并且实际上比Hebbian的想法更适用。罗森布拉特(Rosenblatt)通过以下几行介绍了Perceptron:
感知器旨在说明一般智能系统的一些基本属性,而不会过于沉迷于特定生物通常具有的特殊且通常未知的条件。[2]
3年后,Widrow [4] 雕刻了Delta学习规则,然后将其用作Perceptron训练的实际步骤。也称为最小二乘 问题。这两个想法的结合创造了一个很好的线性分类器。然而,Persky的兴奋与Minsky [3]在1969年有关。他提出了著名的XOR问题,以及在这种线性不可分割的数据分布中感知器无法实现的问题。这是明斯基对NN社区的解决。此后,直到1980年代,神经网络研究才处于休眠状态。
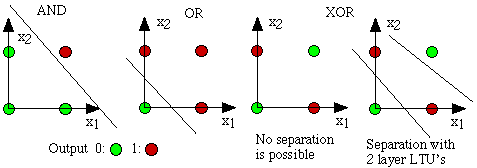
异或问题也不是线性可分离的数据方向
直到1981年Werbos [6]用NN特定的反向传播(BP)算法 提出了多层感知器(MLP)的直觉之后,才进行了很多工作,尽管 1970年Linnainmaa [5]曾提出过BP的想法 。以“自动区分的反向模式”的名称命名。BP仍然是当今NN体系结构的关键要素。有了这些新想法,NN的研究再次加速。1985年至1986年,神经网络研究人员先后通过实际的BP训练提出了MLP 的思想(Rumelhart,Hinton,Williams [7] – Hetch,Nielsen [8])
![摘自赫奇和尼尔森[7]](https://erogol.com/wp-content/uploads/2014/05/Hetch_Nielsen_NN.png)
摘自赫奇和尼尔森[8]
在另一个方面,JR Quinlan [9]在1986 年提出了一种众所周知的ML算法,我们称之为决策树,更具体地讲是ID3算法。这是另一个主流机器学习的亮点。而且,ID3还作为一种软件发布,它具有简单的规则和清晰的推论,可以发现更多现实生活中的用例,这与仍然是黑盒子的NN模型相反。
在ID3之后,社区已经探索了许多不同的替代方案或改进方法(例如ID4,回归树,CART…),但它仍然是ML中的活跃主题之一。
![来自昆兰[]](https://erogol.com/wp-content/uploads/2014/05/Quinlan_ID3.png)
来自昆兰[9]
机器学习最重要的突破之一是支持向量机(网络)(SVM),该向量机由Vapnik和Cortes [10] 于1995年提出,具有很强的理论地位和实证结果。那时是NN或SVM倡导者将ML社区分成两个人群的时候。但是,在将内核支持版本的SVM 移至2000年代左右后,NN端这两个社区之间的竞争并不容易(我无法找到有关该主题的第一篇论文),SVM充分利用了NN模型之前所完成的许多任务。此外,SVM能够利用凸优化,广义裕度理论和针对NN模型的核的所有深厚知识。因此,它可能会发现来自不同学科的巨大推动力,从而在理论和实践上取得了迅速的进步。
![来自瓦普尼克和科尔特斯[10]](https://erogol.com/wp-content/uploads/2014/05/SVM_Vapnik.png)
来自瓦普尼克和科尔特斯[10]
1991年Hochreiter的论文[40]和 Hochreiter等人的工作使NN遭受了另一次破坏。等[11] 在2001年,显示了当我们应用BP学习时,NN单元饱和后的梯度损失。简单地说,由于饱和单元,在一定数量的时期之后训练NN单元是多余的,因此NN非常倾向于在短时期内过度拟合。
不久之前,Freund和Schapire 在1997年提出了另一种固体ML模型,该模型规定了称为Adaboost的弱分类器的增强合奏 。这项工作在当时还授予了戈德尔奖。Adaboost通过更加重视硬实例来训练易于训练的弱分类器集。该模型仍然是许多不同任务(例如人脸识别和检测)的基础。这也是PAC(大概近似正确)学习理论的实现。通常,将所谓的弱分类器选择为简单的决策树桩(单个决策树节点)。他们介绍了Adaboost为;
我们研究的模型可以解释为将经过充分研究的在线预测模型广泛扩展到抽象的决策理论环境……[11]
Breiman [12]在2001年探索的另一个集成模型将多个决策树集合在一起,其中每个决策树由实例的随机子集管理,并且每个节点都从特征的随机子集中选择。由于其性质,它被称为随机森林(RF)。RF还具有抗过度拟合的理论和经验证明。甚至AdaBoost都显示出数据过拟合和离群值实例的弱点,RF 对于这些警告而言是更健壮的模型(有关RF的更多详细信息,请参阅我的旧文章。)RF在许多不同的任务(例如Kaggle比赛)中也显示出成功。
随机森林是树预测器的组合,因此每棵树都取决于独立采样的随机向量的值,并且对森林中的所有树具有相同的分布。随着森林中树木数量的增加,森林的一般化误差收敛到极限[12]。
随着我们今天越来越近,一种称为深度学习的NN新时代已经商业化。该短语仅表示具有许多较宽连续层的NN模型。NN的第三次兴起始于2005年 ,这是近来的专家Hinton,LeCun,Bengio,Andrew Ng和其他有价值的资深研究人员从过去到现在的许多发现共同开始的 。我列举了一些重要的标题(我想,我将专门为深度学习撰写完整的帖子);
- GPU编程
- 卷积神经网络[18] [20] [40]
- 反卷积网络[21]
- 优化算法
- 随机梯度下降[19] [22]
- BFGS和L-BFGS [23]
- 共轭梯度下降[24]
- 反向传播[40] [19]
- 整流器单元
- 稀疏性[15] [16]
- 辍学网[26]
- 麦克斯图网[25]
- 无监督的NN模型[14]
- 深度信仰网络[13]
- 堆叠式自动编码器[16] [39]
- 去噪NN模型[17]
结合所有这些想法和未列出的想法,NN模型能够在非常不同的任务(例如对象识别,语音识别,NLP等)上超越现有技术。但是,应该指出的是,这绝对不意味着,这是其他ML流的结尾。即使深度学习成功案例迅速发展,也有许多批评家直接针对培训成本和调整这些模型的外生参数。此外,由于其简单性,SVM仍在更普遍地使用。(表示但可能引起巨大争议 )
)
在结束之前,我需要介绍另一个相对年轻的ML趋势。随着WWW和社交媒体的发展,一个新的名词 BigData 出现了,并极大地影响了ML研究。由于BigData带来的大量问题,许多强大的ML算法对于合理的系统毫无用处(当然,对于大型的Tech公司而言,这是没有用的)。因此,研究人员提出了一套新的简单模型,称为Bandit算法[27-38](正式称为 Online Learning) ,使学习变得更容易且更适合大规模问题。
我想总结一下这本ML史的婴儿表。如果您发现错误(应该),不足或未被引用,请立即以各种方式警告我。
本文来自博客园,作者:大码王,转载请注明原文链接:https://www.cnblogs.com/huanghanyu/

 posted on
posted on










【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具