
算法原理
朴素贝叶斯是经典的机器学习算法之一,也是为数不多的基于概率论的分类算法。朴素贝叶斯原理简单,也很容易实现,多用于文本分类,比如垃圾邮件过滤。
该算法的优点在于简单易懂、学习效率高、在某些领域的分类问题中能够与决策树、神经网络相媲美。
但由于该算法以自变量之间的独立(条件特征独立)性和连续变量的正态性假设为前提,就会导致算法精度在某种程度上受影响。
marco 博客https://www.cnblogs.com/marc01in/p/4775440.html的简单例子能够很形象说明其核心思想:
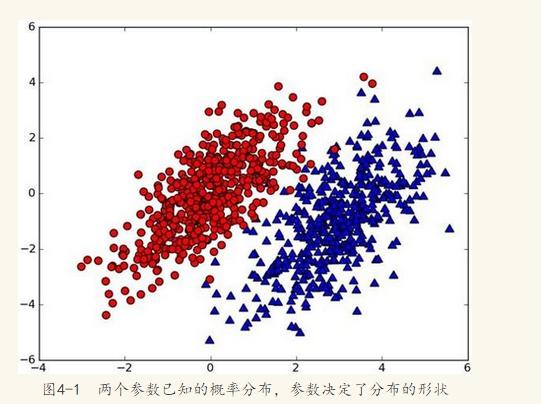
现在出现一个新的点new_point (x,y),其分类未知。我们可以用p1(x,y)表示数据点(x,y)属于红色一类的概率,同时也可以用p2(x,y)表示数据点(x,y)属于蓝色一类的概率。那要把new_point归在红、蓝哪一类呢?
我们提出这样的规则:
如果p1(x,y) > p2(x,y),则(x,y)为红色一类。
如果p1(x,y) <p2(x,y), 则(x,y)为蓝色一类。
换人类的语言来描述这一规则:选择概率高的一类作为新点的分类。这就是贝叶斯决策理论的核心思想,即选择具有最高概率的决策。
用条件概率的方式定义这一贝叶斯分类准则:
如果p(red|x,y) > p(blue|x,y), 则(x,y)属于红色一类。
如果p(red|x,y) < p(blue|x,y), 则(x,y)属于蓝色一类。
也就是说,在出现一个需要分类的新点时,我们只需要计算这个点的
max(p(c1 | x,y),p(c2 | x,y),p(c3 | x,y)...p(cn| x,y))。其对于的最大概率标签,就是这个新点的分类啦。
那么问题来了,对于分类i 如何求解p(ci| x,y)?
没错,就是贝叶斯公式:
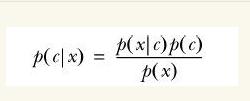
如果要确定某个样本归属于哪一类,则需要计算出归属不同类的概率,再从中挑选出最大的概率。
我们把上面的贝叶斯公式写出这样,也许你能更好的理解:
而这个公式告诉我们,需要计算最大的后验概率,只需要计算出分子的最大值即可,而不同水平的概率P(C)非常容易获得,故难点就在于P(X|C)的概率计算。而问题的解决,正是聪明之处,即贝叶斯假设变量X间是条件独立的,故而P(X|C)的概率就可以计算为:
一般流程
1. 收集数据:提供数据源(一般训练数据与测试数据比例为7:3);
2. 准备数据:将数据源解析成词条向量;
3. 分析数据:检查词条确保解析的正确性;
4. 训练算法:用训练数据生成的分类器;
5. 测试算法:用训练生成的分类器预测测试数据的结果,对比真实结果,计算错误率,衡量分类器的准确度。
6. 使用算法:通过错误率来评估分类器;
代码实现(python)
myBayes.py:代码实现文件,代码已做了详细注释,包含3个示例:
1. 过滤侮辱文档
2. 过滤垃圾邮件
3. 寻找在线RSS源排名靠前的单词




1 # -*- coding: utf-8 -*- 2 """ 3 Created on Mon Nov 5 14:02:18 2018 4 5 @author: weixw 6 """ 7 8 import numpy as np 9 10 def loadDataSet(): 11 postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], 12 ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'], 13 ['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'], 14 ['stop', 'posting', 'stupid', 'worthless', 'garbage'], 15 ['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'], 16 ['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']] 17 classVec = [0,1,0,1,0,1] #1 侮辱性, 0 not 18 return postingList,classVec 19 20 #输入:原始数据集 21 #功能:创建一个包含所有原始数据集词语集合,这个列表中词语不重复。 22 #输出:不重复词列表 23 def createVocabList(dataSet): 24 #创建一个空集合,这个集合中内容唯一,并且可动态扩展。 25 vocabSet = set([]) #create empty set 26 #获取每一行数据list 27 for document in dataSet: 28 #将每一行数据取出,合并到vocabSet集合中,vocabSet会自动过滤重复词 29 vocabSet = vocabSet | set(document) #union of the two sets 30 #将集合转化为列表list 31 return list(vocabSet) 32 33 #输入:列表集合(唯一),输入集合(一行文档内容) 34 ''' 35 功能:检查输入集合单词是否在列表集合中,在则在列表集合对应位置设置为1,否则为0 36 将每个词在文档中出现与否作为一个特征,称为词集模型(set-of-words model) 37 ''' 38 #输出:向量列表(判断输入文档中每个单词是否在词汇样本中) 39 def setOfWords2Vec(vocabList, inputSet): 40 #初始化为0,长度为vocabList长度的集合 41 returnVec = [0]*len(vocabList) 42 #检查inputSet中每个单词是否在vocabList集合中,在则在vocabList对应位置置1,否则不作处理 43 for word in inputSet: 44 if word in vocabList: 45 returnVec[vocabList.index(word)] = 1 46 else: print ("the word: %s is not in my Vocabulary!" % word) 47 return returnVec 48 49 #输入:trainMatrix(文档数组(处理为0,1向量)),trainCategory(列标签数组) 50 ''' 51 功能:生成分类器(获取最佳训练参数权值) 52 训练样本以及测试样本大小要相同,通过标签指定行词语类别来计算训练样本对应位置权重参数值。 53 这里有个假定前提,每一行词语是相互独立的,也就有 54 p(w/c1) = p(w0,w1,w2...wn/c1) = p(w0/c1)*p(w1/c1)*p(w2/c1)***p(wn/c1) 55 ''' 56 #输出:p0Vect(文档中非侮辱性词语概率),p1Vect(侮辱性词语概率),pAbusive(标签类中侮辱性标签概率) 57 def trainNB0(trainMatrix,trainCategory): 58 #数据集行大小 59 numTrainDocs = len(trainMatrix) 60 #数据集列大小 61 numWords = len(trainMatrix[0]) 62 #标签类中侮辱性标签概率(0:非侮辱,1:侮辱) 63 #引入float强制转换是使结果为小数 64 pAbusive = sum(trainCategory)/float(numTrainDocs) 65 #初始化为数据集列大小的单位矩阵 66 #p0Num:非侮辱性矩阵,p1Num:侮辱性矩阵 67 p0Num = np.ones(numWords); p1Num = np.ones(numWords) #change to ones() 68 #使np.log > 1,防止np.log分母为0而无法计算 69 70 #防止分母为0。因为计算每个子项概率采用的对数log(防止下溢出),是以2为底的,如果pADDenom = 2.0,则避免了分母为0的可能。 71 p0Denom = 2.0; p1Denom = 2.0 #change to 2.0 72 #遍历数据集每一行 73 for i in range(numTrainDocs): 74 #如果标签类中该行定义为侮辱性标签 75 if trainCategory[i] == 1: 76 #将数据集中指定侮辱性行对应数据迭代求和,结果还是矩阵 77 #统计数据集中指定侮辱性行存在的词语(为1),并求和,结果是数字 78 p1Num += trainMatrix[i] 79 p1Denom += sum(trainMatrix[i]) 80 #如果标签类中该行定义为非侮辱性标签 81 else: 82 #将数据集中指定非侮辱性行对应数据迭代求和,结果还是矩阵 83 p0Num += trainMatrix[i] 84 #统计数据集中指定非侮辱性行存在的词语(为1),并求和,结果是数字 85 p0Denom += sum(trainMatrix[i]) 86 #这里有个假定前提,每一行词语是相互独立的,也就有 87 #p(w/c1) = p(w0,w1,w2...wn/c1) = p(w0/c1)*p(w1/c1)*p(w2/c1)***p(wn/c1) 88 #计算数据集中侮辱性词语概率p(w/c1) 89 #取对数是防止下溢出,由于概率因子都非常小,当计算乘积p(W0/Ci)*p(W1/Ci)*p(W2/Ci)...*p(Wn/Ci)时,得到结果会更小, 90 #四舍五入会为0,所以采用log(a*b) = log(a) + log(b) 91 p1Vect = np.log(p1Num/p1Denom) #change to log() 92 #计算数据集中非侮辱性词语概率p(w/c0) 93 p0Vect = np.log(p0Num/p0Denom) #change to log() 94 95 return p0Vect,p1Vect,pAbusive 96 ''' 97 输入:vec2Classify(测试文档(0.1向量)),p0Vec(非侮辱性概率训练参数), 98 p1Vec(侮辱性概率训练参数),pClass1(标签类中侮辱性标签概率) 99 功能:比较侮辱性和非侮辱性后验概率,判断测试文档所属类别 100 朴素贝叶斯公式:p(Ci/W) = p(W/Ci)p(Ci)/p(W) 101 输出:1:侮辱性文档 0:非侮辱性文档 102 ''' 103 def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1): 104 #计算文档属于侮辱性标签概率p(c1/w) 105 #np.log是以2为底,求和实际是相乘 106 p1 = sum(vec2Classify * p1Vec) + np.log(pClass1) #element-wise mult 107 #计算文档属于非侮辱性标签概率p(c0/w) 108 p0 = sum(vec2Classify * p0Vec) + np.log(1.0 - pClass1) 109 if p1 > p0: 110 #u"侮辱文档" 111 return 1 112 else: 113 #u"非侮辱文档" 114 return 0 115 116 #输入:列表集合(唯一),输入集合(文档或词汇表) 117 ''' 118 功能:检查输入集合单词是否在列表集合中,在则在列表集合对应位置加1 119 如果一个词在文档中出现不止一次,这可能意味着包含该词是否出现在文档中所不能表达的某种信息, 120 称为词袋模型(bags-of-words model)。在词袋中,每个单子可以出现多次,而在词集中,每个词只能出现一次。 121 ''' 122 #输出:向量列表(统计输入文档中每个单词在词汇样本中个数) 123 def bagOfWords2VecMN(vocabList, inputSet): 124 returnVec = [0]*len(vocabList) 125 for word in inputSet: 126 if word in vocabList: 127 returnVec[vocabList.index(word)] += 1 128 return returnVec 129 130 #测试(过滤网站恶意留言) 131 def testingNB(): 132 #获取数据集(数组),标签列表 133 listOPosts,listClasses = loadDataSet() 134 #将数据集数组转化为内容唯一的数据集list 135 #创建一个包含所有原始数据集词语集合,这个列表中词语不重复。 136 myVocabList = createVocabList(listOPosts) 137 trainMat=[] 138 #遍历数据集中每一行数组,将词语转化为向量0,1(1:该行数据中词语在myVocabList存在) 139 #词语文档 => 向量文档 140 for postinDoc in listOPosts: 141 trainMat.append(bagOfWords2VecMN(myVocabList, postinDoc)) 142 #计算分类器训练参数 143 p0V,p1V,pAb = trainNB0(np.array(trainMat),np.array(listClasses)) 144 #测试1 145 testEntry = ['love', 'my', 'dalmation'] 146 #词语文档 => 向量文档 147 thisDoc = np.array(bagOfWords2VecMN(myVocabList, testEntry)) 148 #结果分类 149 print (testEntry,'classified as: ', u"0 (非侮辱文档)" if(classifyNB(thisDoc,p0V,p1V,pAb) == 0) else u"1(侮辱文档)") 150 #测试2 151 testEntry = ['stupid', 'garbage'] 152 #词语文档 => 向量文档 153 thisDoc = np.array(bagOfWords2VecMN(myVocabList, testEntry)) 154 #结果分类 155 print (testEntry,'classified as: ', u"0 (非侮辱文档)" if(classifyNB(thisDoc,p0V,p1V,pAb) == 0) else u"1(侮辱文档)") 156 157 158 #输入:文本字符串 159 ''' 160 功能:文本处理,过滤掉一些不需要的字符(?,&,=...)以及URL中en和py这样的单词, 161 并全部转换为小写 162 ''' 163 #输出:处理后的字符串集合 164 def textParse(bigString): #input is big string, #output is word list 165 import re 166 #分隔符是除单词、数字外的任意字符都是分隔符 167 #string.split()只是以" "分隔 168 #正则匹配 169 listOfTokens = re.split(r'\W*', bigString) 170 #过滤掉少于2个字符的字符串,并全部转换为小写 171 return [tok.lower() for tok in listOfTokens if len(tok) > 2] 172 173 #测试(过滤垃圾邮件) 174 #说明:50封邮件中随机选取10封作为测试样本,剩下40封作为训练样本 175 def spamTest(): 176 docList=[]; classList = []; fullText =[] 177 #email文件下26封正常邮件,26封垃圾邮件 178 for i in range(1,26): 179 #准备数据,文本预处理 180 wordList = textParse(open('email/spam/%d.txt' % i).read()) 181 #保存为list(list递增 二维) 182 docList.append(wordList) 183 #保存为array(扩展 一维) 184 fullText.extend(wordList) 185 #标记邮件类别,垃圾邮件 186 classList.append(1) 187 #准备数据,文本预处理 188 wordList = textParse(open('email/ham/%d.txt' % i).read()) 189 #保存为list(list递增 二维) 190 docList.append(wordList) 191 #保存为array(扩展 一维) 192 fullText.extend(wordList) 193 #标记邮件类别,正常邮件 194 classList.append(0) 195 #将数据集数组转化为内容唯一的数据集list 196 #创建一个包含所有原始数据集词语集合,这个列表中词语不重复。 197 vocabList = createVocabList(docList)#create vocabulary 198 #python3.x range返回的是range对象,不返回数组对象 199 trainingSet = list(range(50)); testSet=[] #create test set 200 #随机选取10封邮件作为测试数据 201 for i in range(10): 202 #在50封邮件中随机抽选 203 randIndex = int(np.random.uniform(0,len(trainingSet))) 204 #保存list中 205 testSet.append(trainingSet[randIndex]) 206 #选取并保存后,去除该邮件对应的索引 207 del(trainingSet[randIndex]) 208 trainMat=[]; trainClasses = [] 209 #剩余40封邮件作为训练样本,训练分类器参数 210 for docIndex in trainingSet:#train the classifier (get probs) trainNB0 211 #将处理后的文本转化为词向量(词袋模型),并保存 212 trainMat.append(bagOfWords2VecMN(vocabList, docList[docIndex])) 213 #保存对应标签 214 trainClasses.append(classList[docIndex]) 215 #训练,获取最终训练参数 216 p0V,p1V,pSpam = trainNB0(np.array(trainMat),np.array(trainClasses)) 217 218 errRate = 0.0;iterNumber = 20 219 #迭代20次 220 for i in range(iterNumber): 221 errorCount = 0 222 #遍历测试数据集 223 for docIndex in testSet: #classify the remaining items 224 #将处理后的测试数据转化为词向量(词袋模型),并保存 225 wordVector = bagOfWords2VecMN(vocabList, docList[docIndex]) 226 #将训练后的参数导入分类器,输入测试的词向量,与测试数据对应标签比较,统计错误率 227 result = classifyNB(np.array(wordVector),p0V,p1V,pSpam) 228 if result != classList[docIndex]: 229 errorCount += 1 230 # print ("docIndex:%d,classification error:%s"%(docIndex, docList[docIndex])) 231 print ("docIndex:%d,classification error, predict result: %d mark class result %d:"%(docIndex, result, classList[docIndex])) 232 #每次错误率 233 print ('the error rate is: ',float(errorCount)/len(testSet)) 234 errRate += float(errorCount)/len(testSet) 235 #平均错误率 236 print ("the mean error rate is:", float(errRate)/iterNumber) 237 238 #return vocabList,fullText 239 240 241 #输入:vocabList(去重词汇表),fullText(未去重所有单词) 242 ''' 243 功能:计算高频词汇。遍历词汇表中每个词并统计它在文本中出现的次数,然后根据出现次数从高到低对词典进行排序, 244 最后返回排序最高的30个单词。 245 ''' 246 #输出:按降序排列的前30个单词以及单词对应出现次数 247 def calcMostFreq(vocabList,fullText): 248 import operator 249 freqDict = {} 250 #遍历词汇表中每个单词,统计每个单词出现的次数,然后以键值对保存 251 for token in vocabList: 252 freqDict[token]=fullText.count(token) 253 #以单词出现次数倒叙排列 254 sortedFreq = sorted(freqDict.items(), key=operator.itemgetter(1), reverse=True) 255 #返回前30个键值对对象 256 return sortedFreq[:30] 257 258 #输入:feed1(RSS1源),feed0(RSS0源) 259 ''' 260 功能: 261 1 根据朴素贝叶斯公式生成分类器; 262 2 判断随机抽选测试数据属于源RSS0或者RSS1; 263 3 计算分类错误率; 264 ''' 265 #输出:vocabList(词汇表),p0V(源RSS0概率),p1V(源RSS1概率) 266 def localWords(feed1,feed0): 267 # import feedparser 268 docList=[]; classList = []; fullText =[] 269 #获取源RSS0,RSS1最小行大小 270 minLen = min(len(feed1['entries']),len(feed0['entries'])) 271 for i in range(minLen): 272 #文本处理 273 wordList = textParse(feed1['entries'][i]['summary']) 274 #保存list(二维) 275 docList.append(wordList) 276 #保存array(一维) 277 fullText.extend(wordList) 278 #添加标签 279 classList.append(1) #NY is class 1 280 #文本处理 281 wordList = textParse(feed0['entries'][i]['summary']) 282 #保存list(二维) 283 docList.append(wordList) 284 #保存array(一维) 285 fullText.extend(wordList) 286 #添加标签 287 classList.append(0) 288 #生成词汇表 289 vocabList = createVocabList(docList)#create vocabulary 290 #获取词汇表中单词在文本中出现次数,并截取排名前30键值对 291 top30Words = calcMostFreq(vocabList,fullText) #remove top 30 words 292 #去除词汇表中排名前30单词 293 for pairW in top30Words: 294 if pairW[0] in vocabList: vocabList.remove(pairW[0]) 295 #RSS0+RSS1 296 trainingSet = list(range(2*minLen)); testSet=[] #create test set 297 #随机选取20作为测试数据,保存,然后在训练集中去除 298 for i in range(20): 299 randIndex = int(np.random.uniform(0,len(trainingSet))) 300 testSet.append(trainingSet[randIndex]) 301 del(trainingSet[randIndex]) 302 trainMat=[]; trainClasses = [] 303 #除去20个测试数据,剩下作为训练数据 304 for docIndex in trainingSet:#train the classifier (get probs) trainNB0 305 trainMat.append(bagOfWords2VecMN(vocabList, docList[docIndex])) 306 trainClasses.append(classList[docIndex]) 307 #生成分类器,获取训练参数结果 308 p0V,p1V,pSpam = trainNB0(np.array(trainMat),np.array(trainClasses)) 309 errorCount = 0 310 #计算测试分类错误率 311 for docIndex in testSet: #classify the remaining items 312 wordVector = bagOfWords2VecMN(vocabList, docList[docIndex]) 313 if classifyNB(np.array(wordVector),p0V,p1V,pSpam) != classList[docIndex]: 314 errorCount += 1 315 print ('the error rate is: ',float(errorCount)/len(testSet)) 316 return vocabList,p0V,p1V 317 318 #输入:ny(源RSS0),sf(源RSS1) 319 #功能:根据贝叶斯公式,通过训练分类器获得的分类概率,找到排名靠前的单词。 320 #输出:RSS0和RSS1出现频率排名靠前的单词 321 def getTopWords(ny,sf): 322 # import operator 323 #获取训练样本词汇表,以及RSS0,RSS1的概率 324 vocabList,p0V,p1V=localWords(ny,sf) 325 topNY=[]; topSF=[] 326 #设置概率阈值,保存满足条件的键值对 327 for i in range(len(p0V)): 328 if p0V[i] > -6.0 : topSF.append((vocabList[i],p0V[i])) 329 if p1V[i] > -6.0 : topNY.append((vocabList[i],p1V[i])) 330 #RSS0最终结果排序 331 sortedSF = sorted(topSF, key=lambda pair: pair[1], reverse=True) 332 print (u"RSS0最终结果排序") 333 #打印RSS0频率最高词汇 334 for item in sortedSF: 335 print (item[0]) 336 #RSS1最终结果排序 337 sortedNY = sorted(topNY, key=lambda pair: pair[1], reverse=True) 338 print (u"RSS1最终结果排序") 339 #打印RSS1频率最高词汇 340 for item in sortedNY: 341 print (item[0])
测试文件:testMyBayes.py
1 # -*- coding: utf-8 -*- 2 """ 3 Created on Mon Nov 5 14:08:32 2018 4 5 @author: weixw 6 """ 7 8 import myBayes as mb; 9 import feedparser as fp 10 11 #过滤网站恶意留言 12 mb.testingNB(); 13 14 #过滤垃圾邮件 15 mb.spamTest() 16 17 18 ny = fp.parse('http://www.people.com.cn/rss/politics.xml') 19 length = len(ny['entries']) 20 21 sf = fp.parse('http://www.people.com.cn/rss/world.xml') 22 length = len(ny['entries']) 23 24 #vocabList,pSF,pNY = bs.localWords(ny,sf) 25 26 #找到排名靠前的单词 27 mb.getTopWords(ny,sf);
测试运行结果
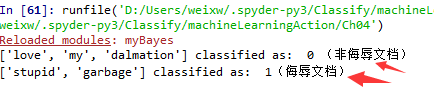
1. 过滤侮辱文档
由给定的标签类可以看出,预测分类结果是正确的。
2. 过滤垃圾邮件(40封作为训练样本,10封作为测试样本),迭代次数:20
结果一:对垃圾邮件的过滤准确度平均只有80%,而且还会把正确邮件错认为垃圾邮件。
结果二:对垃圾邮件的过滤准确度100%。
出现两种不同结果的原因是:训练样本太少,导致准确度不稳定,并且产生了将正确邮件错认为垃圾邮件。
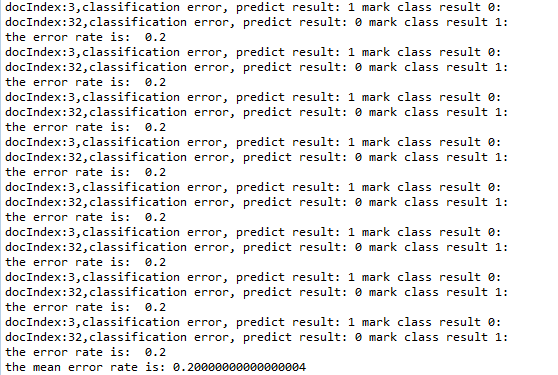
结果二
3. 寻找在线RSS源排名靠前的单词
通过RSS源http://www.people.com.cn/rss/politics.xml,http://www.people.com.cn/rss/world.xml
来校验。
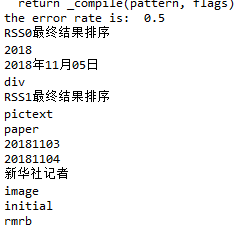
不要让懒惰占据你的大脑,不要让妥协拖垮了你的人生。青春就是一张票,能不能赶上时代的快车,你的步伐就掌握在你的脚下。
本文来自博客园,作者:大码王,转载请注明原文链接:https://www.cnblogs.com/huanghanyu/

 posted on
posted on










【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具