
第1章 Spark 概述
1.1 什么是 Spark
Spark 的产生背景
Spark 是一种快速、通用、可扩展的大数据分析引擎,2009 年诞生于加州大学伯克利分校 AMPLab,2010 年开源,2013 年 6 月成为 Apache 孵化项目,2014 年 2 月成为 Apache 顶级项目。项目是用 Scala 进行编写。
目前,Spark生态系统已经发展成为一个包含多个子项目的集合,其中包含 SparkSQL、Spark Streaming、GraphX、MLib、SparkR 等子项目,Spark 是基于内存计算的大数据并行计算框架。除了扩展了广泛使用的 MapReduce 计算模型,而且高效地支持更多计算模式,包括交互式查询和流处理。Spark 适用于各种各样原先需要多种不同的分布式平台的场景,包括批处理、迭代算法、交互式查询、流处理。通过在一个统一的框架下支持这些不同的计算,Spark 使我们可以简单而低耗地把各种处理流程整合在一起。而这样的组合,在实际的数据分析过程中是很有意义的。不仅如此,Spark 的这种特性还大大减轻了原先需要对各种平台分别管理的负担。
大一统的软件栈,各个组件关系密切并且可以相互调用,这种设计有几个好处:
1、软件栈中所有的程序库和高级组件都可以从下层的改进中获益。
2、运行整个软件栈的代价变小了。不需要运行 5 到 10 套独立的软件系统了,一个机构只需要运行一套软件系统即可。系统的部署、维护、测试、支持等大大缩减。
3、能够构建出无缝整合不同处理模型的应用。
Spark 的内置项目如下:
Spark Core:实现了 Spark 的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core 中还包含了对弹性分布式数据集(resilient distributed dataset,简称RDD)的 API 定义。
Spark SQL:是 Spark 用来操作结构化数据的程序包。通过 Spark SQL,我们可以使用 SQL 或者 Apache Hive 版本的 SQL 方言(HQL)来查询数据。Spark SQL 支持多种数据源,比 如 Hive 表、Parquet 以及 JSON 等。
Spark Streaming:是 Spark 提供的对实时数据进行流式计算的组件。提供了用来操作数据流的 API,并且与 Spark Core 中的 RDD API 高度对应。
Spark MLlib:提供常见的机器学习(ML)功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据导入等额外的支持功能。
集群管理器:Spark 设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。为了实现这样的要求,同时获得最大灵活性,Spark 支持在各种集群管理器(cluster manager)上运行,包括 Hadoop YARN、Apache Mesos,以及 Spark 自带的一个简易调度器,叫作独立调度器。
Spark 得到了众多大数据公司的支持,这些公司包括 Hortonworks、IBM、Intel、Cloudera、MapR、Pivotal、百度、阿里、腾讯、京东、携程、优酷土豆。当前百度的 Spark 已应用于凤巢、大搜索、直达号、百度大数据等业务;阿里利用 GraphX 构建了大规模的图计算和图挖掘系统,实现了很多生产系统的推荐算法;腾讯 Spark 集群达到 8000 台的规模,是当前已知的世界上最大的 Spark 集群。



1.2 Spark 特点
-
快
与 Hadoop 的 MapReduce 相比,Spark 基于内存的运算要快 100 倍以上,基于硬盘的运算也要快 10 倍以上。Spark 实现了高效的 DAG 执行引擎,可以通过基于内存来高效处理数据流。计算的中间结果是存在于内存中的。
-
易用
Spark 支持 Java、Python、R 和 Scala 的 API,还支持超过 80 种高级算法,使用户可以快速构建不同的应用。而且 Spark 支持交互式的 Python、R 和 Scala 的 shell,可以非常方便地在这些 shell 中使用 Spark 集群来验证解决问题的方法。
-
通用
Spark 提供了统一的解决方案。Spark 可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。Spark 统一的解决方案非常具有吸引力,毕竟任何公司都想用统一的平台去处理遇到的问题,减少开发和维护的人力成本和部署平台的物力成本。
-
兼容性
Spark 可以非常方便地与其他的开源产品进行融合。比如,Spark 可以使用 Hadoop 的 YARN 和 Apache Mesos 作为它的资源管理和调度器器,并且可以处理所有 Hadoop 支持的数据,包括 HDFS、HBase 和 Cassandra 等。这对于已经部署 Hadoop 集群的用户特别重要,因为不需要做任何数据迁移就可以使用 Spark 的强大处理能力。Spark 也可以不依赖于第三方的资源管理和调度器,它实现了 Standalone 作为其内置的资源管理和调度框架,这样进一步降低了 Spark 的使用门槛,使得所有人都可以非常容易地部署和使用 Spark。此外,Spark 还提供了在 EC2 上部署 Standalone 的 Spark 集群的工具。
1.3 Spark 的用户和用途
我们大致把 Spark 的用例分为两类:数据科学应用和数据处理应用。也就对应的有两种人群:数据科学家和工程师。
数据科学任务
主要是数据分析领域,数据科学家要负责分析数据并建模,具备 SQL、统计、预测建模(机器学习)等方面的经验,以及一定的使用 Python、Matlab 或 R 语言进行编程的能力。
数据处理应用
工程师定义为使用 Spark 开发生产环境中的数据处理应用的软件开发者,通过对接 Spark 的 API 实现对处理的处理和转换等任务。
第2章 Spark 集群安装
2.1 集群角色
从物理部署层面上来看,Spark 主要分为两种类型的节点,Master 节点和 Worker 节点,Master 节点主要运行集群管理器的中心化部分,所承载的作用是分配 Application 到 Worker 节点,维护 Worker 节点 的 Driver、Application 的状态。Worker 节点负责具体的业务运行。
从 Spark 程序运行的层面来看,Spark 主要分为驱动器节点和执行器节点。

2.2 机器准备
准备两台以上 Linux 服务器,安装好 JDK1.8。
2.3 下载 Spark 安装包

Step0、使用下载命令
wget 下载地址
Step1、上传 spark-2.1.1-bin-hadoop2.7.tgz 安装包到 Linux 对应的目录上,本人是上传至 /opt/software 目录下
Step2、解压安装包到指定位置
tar -zxf /opt/software/spark-2.1.1-bin-hadoop2.7.tgz -C /opt/module
如下图所示:

2.4 配置 Spark Standalone 模式
Spark 的部署模式有Local、Local-Cluster、Standalone、Yarn、Mesos,我们选择最具代表性的 Standalone 集群部署模式。
Step1、进入到 Spark 安装目录中的配置目录 conf
cd /opt/module/spark-2.1.1-bin-hadoop2.7/conf
如下图所示:

Step2、将 slaves.template 复制为 slaves
Step3、将 spark-env.sh.template 复制为 spark-env.sh

Step4、修改 slaves 文件,将 Worker 的 hostname 输入:

Step5、修改 spark-env.sh 文件,添加如下配置:
SPARK_MASTER_HOST=hadoop102
SPARK_MASTER_PORT=7077

Step6、将配置好的 Spark 文件拷贝到其他节点上 或者 使用配置分发的脚本
scp -r /opt/module/spark-2.1.1-bin-hadoop2.7/ atguigu@hadoop103:/opt/module/
scp -r /opt/module/spark-2.1.1-bin-hadoop2.7/ atguigu@hadoop104:/opt/module/
或者
xsync /opt/module/spark-2.1.1-bin-hadoop2.7/
Step7、Spark 集群配置完毕,目前是 1 个 Master,2 个 Work,hadoop102 上启动 Spark 集群
$ /opt/module/spark-2.1.1-bin-hadoop2.7/sbin/start-all.sh
如下图所示:

启动后执行 jps 命令,主节点上有 Master 进程,其他子节点上有 Worker 进行
登录 Spark 管理界面查看集群状态(主节点):http://hadoop102:8080/ 或者 http://192.168.25.102:8080/

到此为止,Spark 集群安装完毕。
问题1:如果遇到 “JAVA_HOME not set” 异常,如下图所示:

解决方案:可以在 sbin 目录下的 spark-config.sh 文件中加入如下配置,然后配置分发到其他机器:
export JAVA_HOME=/opt/module/jdk1.8.0_144
如下图所示:

问题2:如果遇到 Hadoop HDFS 的写入权限异常:
org.apache.hadoop.security.AccessControlException
解决方案: 在 hdfs-site.xml 中添加如下配置,关闭权限验证,然后配置分发到其他机器:
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
2.5 配置 Spark History Server
Step1、进入到 Spark 安装目录
cd /opt/module/spark-2.1.1-bin-hadoop2.7/conf
Step2、将 spark-default.conf.template 复制为 spark-default.conf
$ cp spark-defaults.conf.template spark-defaults.conf
Step3、修改 spark-default.conf 文件,开启 Log:
spark.master spark://hadoop102:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop102:9000/directory
如下图所示:

Step4、修改 spark-env.sh 文件,添加如下配置:
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000
-Dspark.history.retainedApplications=3
-Dspark.history.fs.logDirectory=hdfs://hadoop102:9000/directory"
如下图所示:

Step5、启动 HDFS 集群,在 HDFS 上创建好你所指定的 eventLog 日志目录。
$ /opt/module/hadoop-2.7.2/bin/hdfs dfs -mkdir -p /directory
参数描述:
spark.eventLog.dir Application 在运行过程中所有的信息均记录在该属性指定的路径下
spark.history.ui.port=4000 调整 WEBUI 访问的端口号为 4000
spark.history.retainedApplications=3 指定保存 Application 历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数
spark.history.fs.logDirectory=hdfs://hadoop102:9000/directory 配置了该属性后,在 start-history-server.sh 时就无需再显式的指定路径,Spark History Server 页面只展示该指定路径下的信息
Step6、将配置好的 Spark 文件拷贝到其他节点上或者配置分发。
Step7、重启 Spark 集群。
$ /opt/module/spark-2.1.1-bin-hadoop2.7/sbin/start-all.sh
Step8、启动后执行历史服务器。
$ /opt/module/spark-2.1.1-bin-hadoop2.7/sbin/start-history-server.sh
网页上查看

到此为止,Spark History Server 安装完毕。
2.6 配置 Spark HA
集群部署完了,但是有一个很大的问题,那就是 Master 节点存在单点故障,要解决此问题,就要借助 zookeeper,并且启动至少两个 Master 节点来实现高可靠,配置方式比较简单:
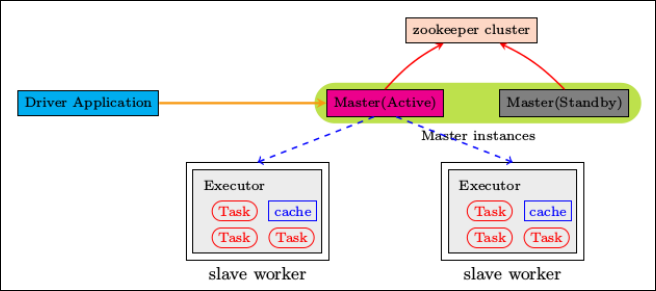
Step1、Spark 集群规划:hadoop102,hadoop103 是 Master;hadoop103,hadoop104 是 Worker。
Step2、安装配置 Zookeeper 集群,并启动 Zookeeper 集群。
Step3、停止 spark 所有服务,在 hadoop102 节点上修改配置文件 spark-env.sh,在该配置文件中删掉 SPARK_MASTER_IP(即 SPARK_MASTER_HOST) 并添加如下配置:
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=hadoop102:2181,hadoop103:2181,hadoop104:2181
-Dspark.deploy.zookeeper.dir=/spark"
如下图所示:

Step4、在 hadoop102 节点上修改 slaves 配置文件内容指定 worker 节点。
hadoop103
hadoop104
Step5、将配置文件同步到所有节点。
Step6、在 hadoop102 上执行 sbin/start-all.sh 脚本,启动集群并启动第一个 master 节点,然后在 hadoop103 上执行 sbin/start-master.sh 启动第二个 master 节点。
Step7、程序中 spark 集群的访问地址需要改成:
--master spark://hadoop102:7077,hadoop103:7077
我们干掉 hadoop102 上的 Master 进程,然后再次执行 WordCount 程序,看是否能够执行成功:

由上图可知,程序依旧可以运行。
同理:我们再干掉 hadoop103 上的 Master 进程,然后再次执行 WordCount 程序,看是否能够执行成功,经过测试,程序依旧可以执行成功,到此为止,Spark 的高可用完成!
Step8、我们想知道 Zookeeper 中保存了什么?
[atguigu@hadoop102 zookeeper-3.4.10]$ pwd
/opt/module/zookeeper-3.4.10
[atguigu@hadoop102 zookeeper-3.4.10]$ bin/zkCli.sh -server hadoop102:2181,hadoop103:2181,hadoop104:2181
Connecting to hadoop102:2181,hadoop103:2181,hadoop104:2181
......
......
[zk: hadoop102:2181,hadoop103:2181,hadoop104:2181(CONNECTED) 0] ls /spark
[leader_election, master_status]
[zk: hadoop102:2181,hadoop103:2181,hadoop104:2181(CONNECTED) 1] get /spark/master_status
192.168.25.102
cZxid = 0x4000000059
ctime = Mon Apr 22 10:10:11 CST 2019
mZxid = 0x4000000059
mtime = Mon Apr 22 10:10:11 CST 2019
pZxid = 0x4000000063
cversion = 3
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 14
numChildren = 3
[zk: hadoop102:2181,hadoop103:2181,hadoop104:2181(CONNECTED) 2]
2.7 配置 Spark Yarn 模式
Step1、修改 hadoop 配置下的 /opt/module/hadoop-2.7.2/etc/hadoop/yarn-site.xml 文件,然后分发到其他节点。
yarn-site.xml
<?xml version="1.0"?>
<configuration>
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 日志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!-- 任务历史服务器 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs/</value>
</property>
<!-- 指定yarn在启动的时候的内存大小 -->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>mapred.child.java.opts</name>
<value>-Xmx1024m</value>
</property>
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是 true,实际开发中设置成 true,学习阶段设置成 false -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是 true,实际开发中设置成 true,学习阶段设置成 false -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
Step2、修改 /opt/module/spark-2.1.1-bin-hadoop2.7/conf/spark-env.sh,添加以下内容,然后分发到其他节点。
spark-env.sh
# 让 spark 能够发现 hadoop 的配置文件
HADOOP_CONF_DIR=/opt/module/hadoop-2.7.2/etc/hadoop
YARN_CONF_DIR=/opt/module/hadoop-2.7.2/etc/hadoop
如下图所示:

Step3、提交应用进行测即可
$ /opt/module/spark-2.1.1-bin-hadoop2.7/bin/spark-submit \
--class com.atguigu.sparkdemo.WordCountDemo \
--master yarn \
--deploy-mode client \
--executor-memory 1G \
--total-executor-cores 2 \
/opt/software/sparkdemo-1.0-SNAPSHOT-jar-with-dependencies.jar \
hdfs://hadoop102:9000/RELEASE \
hdfs://hadoop102:9000/out
或者
$ /opt/module/spark-2.1.1-bin-hadoop2.7/bin/spark-submit \
--class com.atguigu.sparkdemo.WordCountDemo \
--master yarn-client \
--executor-memory 1G \
--total-executor-cores 2 \
/opt/software/sparkdemo-1.0-SNAPSHOT-jar-with-dependencies.jar \
hdfs://hadoop102:9000/RELEASE \
hdfs://hadoop102:9000/out
第3章 执行 Spark 程序
3.1 执行第一个 spark 程序
$ /opt/module/spark-2.1.1-bin-hadoop2.7/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop102:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
/opt/module/spark-2.1.1-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.1.1.jar \
100
参数说明:
--master spark://hadoop102:7077 指定 Master 的地址
--executor-memory 1G 指定每个 executor 可用内存为 1G
--total-executor-cores 2 指定每个 executor 使用的 cup 核数为 2 个
该算法是利用蒙特·卡罗算法求 PI,结果如下图:

网页上查看 History Server

3.2 Spark 应用提交
一旦打包好,就可以使用 bin/spark-submit 脚本启动应用了。 这个脚本负责设置 spark 使用的 classpath 和依赖,支持不同类型的集群管理器和发布模式:
$ /opt/module/spark-2.1.1-bin-hadoop2.7/bin/spark-submit \
--class <main-class> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... # other options
<application-jar> \
[application-arguments]
一些常用选项:
1) --class: 你的应用的启动类 (如 org.apache.spark.examples.SparkPi)。
2) --master: 集群的 master URL (如 spark://192.168.25.102:7077)。
3) --deploy-mode: 是否发布你的驱动到 Worker 节点(cluster) 或者作为一个本地客户端 client)(默认是 client)。
4) --conf: 任意的 Spark 配置属性, 格式 key=value,如果值包含空格,可以加引号 "key=value",缺省的 Spark 配置。
5) application-jar: 打包好的应用 jar,包含依赖,这个 URL 在集群中全局可见。 比如 hdfs://共享存储系统, 如果是 file://path, 那么所有的节点的 path 都包含同样的 jar。
6) application-arguments: 传给 main() 方法的参数。
--master 后面的 URL 可以是以下格式:

查看 Spark-submit 全部参数:

3.3 Spark shell
spark-shell 是 Spark 自带的交互式 Shell 程序,方便用户进行交互式编程,用户可以在该命令行下用 scala 编写 spark 程序。
3.3.1 启动 Spark shell
启动 spark shell 时没有指定 master 地址
$ /opt/module/spark-2.1.1-bin-hadoop2.7/bin/spark-shell
启动 spark shell 时指定 master 地址
$ /opt/module/spark-2.1.1-bin-hadoop2.7/bin/spark-shell \
--master spark://hadoop102:7077 \
--executor-memory 2G \
--total-executor-cores 2
注意1:如果启动 spark shell 时没有指定 master 地址,但是也可以正常启动 spark shell 和执行 spark shell 中的程序,其实是启动了 spark 的 cluster 模式,如果 spark 是单节点,并且没有指定 slave 文件,这个时候如果打开 spark-shell 默认是 local 模式。
Local 模式是 master 和 worker 在同同一进程内。
Cluster 模式是 master 和 worker 在不同进程内。注意2:Spark Shell 中已经默认将 SparkContext 类初始化为对象 sc。用户代码如果需要用到,则直接应用 sc 即可。

3.3.2 在 Spark shell 中编写 WordCount 程序
Step1、首先启动 HDFS,在 HDFS 上创建一个 /RELEASE 目录
$ /opt/module/hadoop-2.7.2/bin/hdfs dfs -mkdir -p /RELEASE
Step2、将 Spark 目录下的 RELEASE 文件上传一个文件到:hdfs://hadoop102:9000/RELEASE 上
$ /opt/module/hadoop-2.7.2/bin/hdfs dfs -put /opt/module/spark-2.1.1-bin-hadoop2.7/RELEASE /RELEASE
如下图所示:
Step3、在 Spark shell 中用 scala 语言编写 spark 程序
scala> sc.textFile("hdfs://hadoop102:9000/RELEASE/RELEASE").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile("hdfs://hadoop102:9000/out")
如下图所示:

Step4、使用 hdfs 命令查看结果
$ /opt/module/hadoop-2.7.2/bin/hdfs dfs -cat hdfs://hadoop102:9000/out/p*
如下图所示:

说明:
sc 是 SparkContext 对象,该对象是提交 spark 程序的入口。
textFile(hdfs://hadoop102:9000/RELEASE/RELEASE) 是 hdfs 中读取数据
flatMap(_.split(" ")) 先 map 在压平
map((_,1)) 将单词和1构成元组
reduceByKey(_+_) 按照 key 进行 reduce,并将 value 累加
saveAsTextFile("hdfs://hadoop102:9000/out") 将结果写入到 hdfs 中
如下图所示:

3.4 在 IDEA 中编写 WordCount 程序
spark shell 仅在测试和验证我们的程序时使用的较多,在生产环境中,通常会在 IDE 中编制程序,然后打成 jar 包,然后提交到集群,最常用的是创建一个 Maven 项目,利用 Maven 来管理 jar 包的依赖。
Step1、创建一个项目
Step2、选择 Maven 项目,然后点击 next
Step3、填写 maven 的 GAV,然后点击 next
Step4、填写项目名称,然后点击 finish
Step5、创建好 maven 项目后,点击 Enable Auto-Import
Step6、配置 Maven 的 pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.atguigu</groupId>
<artifactId>sparkdemo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<scala.version>2.11.8</scala.version>
<spark.version>2.1.1</spark.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
<configuration>
<archive>
<manifest>
<mainClass>com.atguigu.sparkdemo.WordCountDemo</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
</plugins>
</build>
</project>
Step7、将 src/main/scala 设置成源代码目录。
Step8、添加 IDEA Scala(执行此操作后,pom 文件中不用添加 scala 依赖,因为已经以 lib 库的方式加入)

选择要添加的模块

Step9、新建一个 Scala class,类型为 Object

Step10、编写 spark 程序
示例代码如下:
package com.atguigu.sparkdemo
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactory
object WordCountDemo {
val logger = LoggerFactory.getLogger(WordCountDemo.getClass)
def main(args: Array[String]): Unit = {
// 创建 SparkConf() 并设置 App 名称
val sparkConf = new SparkConf().setAppName("WC")
// 创建 SparkContext,该对象是提交 Spark App 的入口
val sc = new SparkContext(sparkConf)
// 使用 sc 创建 RDD 并执行相应的 transformation 和 action
sc.textFile(args(0)).flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _, 1).sortBy(_._2, false).saveAsTextFile(args(1))
// 停止 sc,结束该任务
logger.info("complete!")
sc.stop()
}
}
Step11、使用 Maven 打包:首先修改 pom.xml 中的 main class

Step12、点击 idea 右侧的 Maven Project 选项,点击 “闪电”图表,表示跳过测试,然后点击 Lifecycle,再分别双击 clean 和 package

Step13、选择编译成功的 jar 包,并将该 jar 上传到 Spark 集群中的某个节点上

Step14、首先启动 hdfs 和 Spark 集群
启动 hdfs
/opt/module/hadoop-2.7.3/sbin/start-dfs.sh
启动 spark
/opt/module/spark-2.1.1-bin-hadoop2.7/sbin/start-all.sh
Step15、使用 spark-submit 命令提交 Spark 应用(注意参数的顺序)
$ /opt/module/spark-2.1.1-bin-hadoop2.7/bin/spark-submit \
--class com.atguigu.sparkdemo.WordCountDemo \
--master spark://hadoop102:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
/opt/software/sparkdemo-1.0-SNAPSHOT-jar-with-dependencies.jar \
hdfs://hadoop102:9000/RELEASE \
hdfs://hadoop102:9000/out1
Step16、查看程序执行结果
$ /opt/module/hadoop-2.7.2/bin/hdfs dfs -cat hdfs://hadoop102:9000/out1/p*
如下图所示:

--master 后面跟的参数小结:

传入参数说明:
hdfs://hadoop102:9000/RELEASE 输入文件路径
hdfs://hadoop102:9000/out1 输出文件路径
如果在 spark 程序中写死了这两处路径,则这两个参数就不需要了。
3.5 在 IDEA 中本地调试 WordCount 程序
本地 Spark 程序调试需要使用 local 提交模式,即将本机当做运行环境,Master 和 Worker 都为本机。运行时直接加断点调试即可。如下:

如果本机操作系统是 windows,如果在程序中使用了 hadoop 相关的东西,比如写入文件到 HDFS,则会遇到如下异常:

出现这个问题的原因,并不是程序的错误。在 windows 下调试 spark 的时候,用到了 hadoop 相关的服务。
解决办法1:本项目生效,是将一个 hadoop 相关的服务 zip 包(hadoop-common-bin-2.7.3-x64.zip)解压到任意目录。
点击 Run -> Run Configurations
然后在 IDEA 中配置 Run Configuration,添加 HADOOP_HOME 变量即可:

解决办法2:所有项目生效,windows 系统中配置 hadoop 的环境变量,如下图所示:

3.6 在 IDEA 中远程调试 WordCount 程序
通过 IDEA 进行远程调试,主要是将 IDEA 作为 Driver 来提交应用程序,配置过程如下:
修改 sparkConf,添加最终需要运行的 Jar 包、Driver 程序的地址,并设置 Master 的提交地址:

3.7 Spark 核心概念
每个 Spark 应用都由一个驱动器程序(driver program)来发起集群上的各种并行操作。驱动器程序包含应用的 main 函数,并且定义了集群上的分布式数据集,还对这些分布式数据集应用了相关操作。
驱动器程序通过一个 SparkContext 对象来访问 Spark。这个对象代表对计算集群的一个连接。shell 启动时已经自动创建了一个 SparkContext 对象,是一个叫作 sc 的变量。
驱动器程序一般要管理多个执行器(executor)节点。

本文来自博客园,作者:大码王,转载请注明原文链接:https://www.cnblogs.com/huanghanyu/

 posted on
posted on










【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具