
一维数据集上的神经网络
代码实现:

import numpy as np import matplotlib.pyplot as plt from sklearn import datasets import tensorflow.compat.v1 as tf tf.disable_v2_behavior() # 使用静态图模式运行以下代码 assert tf.__version__.startswith('2.') sess = tf.Session() # 2 初始化数据 data_size = 25 data_1d = np.random.normal(size=data_size) x_input_1d = tf.placeholder(dtype=tf.float32, shape=[data_size]) # 3 定义卷积层 def conv_layer_1d(input_1d, my_filter): # Make 1d input 4d input_2d = tf.expand_dims(input_1d, 0) input_3d = tf.expand_dims(input_2d, 0) input_4d = tf.expand_dims(input_3d, 3) # Perform convolution convolution_output = tf.nn.conv2d(input_4d, filter=my_filter, strides=[1, 1, 1, 1], padding='VALID') conv_output_1d = tf.squeeze(convolution_output) return conv_output_1d # Now drop extra dimensions my_filter = tf.Variable(tf.random_normal(shape=[1, 5, 1, 1])) my_convolution_output = conv_layer_1d(x_input_1d, my_filter) # 4 激励函数 def activation(input_1d): return tf.nn.relu(input_1d) my_activation_output = activation(my_convolution_output) # 池化 def max_pool(input_1d, width): # First we make the 1d input into 4d. input_2d = tf.expand_dims(input_1d, 0) input_3d = tf.expand_dims(input_2d, 0) input_4d = tf.expand_dims(input_3d, 3) # Perform the max pool operation pool_output = tf.nn.max_pool(input_4d, ksize=[1, 1, width, 1], strides=[1, 1, 1, 1], padding='VALID') pool_output_1d = tf.squeeze(pool_output) return pool_output_1d my_maxpool_output = max_pool(my_activation_output, width=5) # 全连接层 def fully_connected(input_layer, num_outputs): # Create weights weight_shape = tf.squeeze(tf.stack([tf.shape(input_layer), [num_outputs]])) weight = tf.random_normal(weight_shape, stddev=0.1) bias = tf.random_normal(shape=[num_outputs]) # make input into 2d input_layer_2d = tf.expand_dims(input_layer, 0) # perform fully connected operations full_output = tf.add(tf.matmul(input_layer_2d, weight), bias) # Drop extra dimmensions full_output_1d = tf.squeeze(full_output) return full_output_1d my_full_output = fully_connected(my_maxpool_output, 5) # 初始化变量,运行计算图大阴每层输出结果 init = tf.global_variables_initializer() sess.run(init) feed_dict = {x_input_1d: data_1d} # Convolution Output print("Input = array of length 25") print("Convolution w/filter length = 5, stride size = 1, results in an array of legth 21:") print(sess.run(my_convolution_output, feed_dict=feed_dict)) # Activation Output print('\nInput = the above array of length 21') print('Relu element wise returns the array of length 21:') print(sess.run(my_activation_output, feed_dict=feed_dict)) # Maxpool output print('\nInput = the above array of length 21') print('MaxPool, window length = 5, stride size = 1, results in the array of length 17') print(sess.run(my_maxpool_output, feed_dict=feed_dict)) # Fully Connected Output print('Input = the above array of length 17') print('Fully connected layer on all four rows with five outputs') print(sess.run(my_full_output, feed_dict=feed_dict)) # 关闭会话 sess.close()
输出结果如下:
C:\Anaconda3\python.exe "C:\Program Files\JetBrains\PyCharm 2019.1.1\helpers\pydev\pydevconsole.py" --mode=client --port=65184 import sys; print('Python %s on %s' % (sys.version, sys.platform)) sys.path.extend(['C:\\app\\PycharmProjects', 'C:/app/PycharmProjects']) Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] Type 'copyright', 'credits' or 'license' for more information IPython 7.12.0 -- An enhanced Interactive Python. Type '?' for help. PyDev console: using IPython 7.12.0 Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] on win32 runfile('C:/app/PycharmProjects/ArtificialIntelligence/classification.py', wdir='C:/app/PycharmProjects/ArtificialIntelligence') WARNING:tensorflow:From C:\Anaconda3\lib\site-packages\tensorflow\python\compat\v2_compat.py:96: disable_resource_variables (from tensorflow.python.ops.variable_scope) is deprecated and will be removed in a future version. Instructions for updating: non-resource variables are not supported in the long term 2020-06-16 17:49:59.355213: I tensorflow/core/platform/cpu_feature_guard.cc:143] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 2020-06-16 17:49:59.371808: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x225498bdc50 initialized for platform Host (this does not guarantee that XLA will be used). Devices: 2020-06-16 17:49:59.373816: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version Input = array of length 25 Convolution w/filter length = 5, stride size = 1, results in an array of legth 21: [ 0.57410306 1.2466588 -5.2342267 1.5412238 1.1326292 0.9449366 4.176463 -0.66215414 0.5528939 -0.09213515 -0.5939804 1.1933011 2.2207081 3.337352 -1.3791142 -2.5168674 2.025437 -5.8652186 -3.144189 -0.01129406 -0.23239633] Input = the above array of length 21 Relu element wise returns the array of length 21: [0.57410306 1.2466588 0. 1.5412238 1.1326292 0.9449366 4.176463 0. 0.5528939 0. 0. 1.1933011 2.2207081 3.337352 0. 0. 2.025437 0. 0. 0. 0. ] Input = the above array of length 21 MaxPool, window length = 5, stride size = 1, results in the array of length 17 [1.5412238 1.5412238 4.176463 4.176463 4.176463 4.176463 4.176463 1.1933011 2.2207081 3.337352 3.337352 3.337352 3.337352 3.337352 2.025437 2.025437 2.025437 ] Input = the above array of length 17 Fully connected layer on all four rows with five outputs [ 1.1319295 -0.16019821 1.164511 -2.4321733 -3.9491425 ]
卷积层
首先,卷积层输入序列是25个元素的一维数组。卷积层的功能是相邻5个元素与过滤器(长度为5的向量)内积。因为移动步长为1,所以25个元素的序列中一共有21个相邻为5的序列,最终输出也是5。
激励函数
将卷积成的输出,21个元素的向量通过relu函数逐元素转化。输出仍是21个元素的向量。
池化层,最大值池化
取相邻5个元素的最大值。输入21个元素的序列,输出17个元素的序列。
全连接层
上述17个元素通过全连接层,有5个输出。
注意上述过程的输出都做了维度的裁剪。但在每一步的过程中都是扩充成4维张量操作的。
二维数据上的神经网络
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets import tensorflow.compat.v1 as tf tf.disable_v2_behavior() # 使用静态图模式运行以下代码 assert tf.__version__.startswith('2.') sess = tf.Session() # 2 创建数据和占位符 data_size = [10, 10] data_2d = np.random.normal(size=data_size) x_input_2d = tf.placeholder(dtype=tf.float32, shape=data_size) # 3 卷积层:2x2过滤器 def conv_layer_2d(input_2d, my_filter): # First, change 2d input to 4d input_3d = tf.expand_dims(input_2d, 0) input_4d = tf.expand_dims(input_3d, 3) # Perform convolution convolution_output = tf.nn.conv2d(input_4d, filter=my_filter, strides=[1,2,2,1], padding='VALID') # Drop extra dimensions conv_output_2d = tf.squeeze(convolution_output) return conv_output_2d my_filter = tf.Variable(tf.random_normal(shape=[2,2,1,1])) my_convolution_output = conv_layer_2d(x_input_2d, my_filter) # 4 激励函数 def activation(input_2d): return tf.nn.relu(input_2d) my_activation_output = activation(my_convolution_output) # 5 池化层 def max_pool(input_2d, width, height): # Make 2d input into 4d input_3d = tf.expand_dims(input_2d, 0) input_4d = tf.expand_dims(input_3d, 3) # Perform max pool pool_output = tf.nn.max_pool(input_4d, ksize=[1, height, width, 1], strides=[1,1,1,1], padding='VALID') # Drop extra dimensions pool_output_2d = tf.squeeze(pool_output) return pool_output_2d my_maxpool_output = max_pool(my_activation_output, width=2, height=2) # 6 全连接层 def fully_connected(input_layer, num_outputs): # Flatten into 1d flat_input = tf.reshape(input_layer, [-1]) # Create weights weight_shape = tf.squeeze(tf.stack([tf.shape(flat_input), [num_outputs]])) weight = tf.random_normal(weight_shape, stddev=0.1) bias = tf.random_normal(shape=[num_outputs]) # Change into 2d input_2d = tf.expand_dims(flat_input, 0) # Perform fully connected operations full_output = tf.add(tf.matmul(input_2d, weight), bias) # Drop extra dimensions full_output_2d = tf.squeeze(full_output) return full_output_2d my_full_output = fully_connected(my_maxpool_output, 5) # 7 初始化变量 init = tf.initialize_all_variables() sess.run(init) feed_dict = {x_input_2d: data_2d} # 8 打印每层输出结果 # Convolution Output print('Input = [10 x 10] array') print('2x2 Convolution, stride size = [2x2], results in the [5x5] array:') print(sess.run(my_convolution_output, feed_dict=feed_dict)) # Activation Output print('\nInput = the above [5x5] array') print('Relu element wise returns the [5x5] array:') print(sess.run(my_activation_output, feed_dict=feed_dict)) # Max Pool Output print('\nInput = the above [5x5] array') print('[2x2] MaxPool, stride size = [1x1] results in the [4x4] array:') print(sess.run(my_maxpool_output, feed_dict = feed_dict)) # Fully connected output print('\nInput = the above [4x4] array') print('Fully connected layer on all four rows with five outputs:') print(sess.run(my_full_output, feed_dict=feed_dict))
输出结果如下:
C:\Anaconda3\python.exe "C:\Program Files\JetBrains\PyCharm 2019.1.1\helpers\pydev\pydevconsole.py" --mode=client --port=49317 import sys; print('Python %s on %s' % (sys.version, sys.platform)) sys.path.extend(['C:\\app\\PycharmProjects', 'C:/app/PycharmProjects']) Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] Type 'copyright', 'credits' or 'license' for more information IPython 7.12.0 -- An enhanced Interactive Python. Type '?' for help. PyDev console: using IPython 7.12.0 Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] on win32 runfile('C:/app/PycharmProjects/ArtificialIntelligence/classification.py', wdir='C:/app/PycharmProjects/ArtificialIntelligence') WARNING:tensorflow:From C:\Anaconda3\lib\site-packages\tensorflow\python\compat\v2_compat.py:96: disable_resource_variables (from tensorflow.python.ops.variable_scope) is deprecated and will be removed in a future version. Instructions for updating: non-resource variables are not supported in the long term 2020-06-16 17:54:43.270370: I tensorflow/core/platform/cpu_feature_guard.cc:143] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 2020-06-16 17:54:43.291541: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x1a303a82660 initialized for platform Host (this does not guarantee that XLA will be used). Devices: 2020-06-16 17:54:43.293406: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version WARNING:tensorflow:From C:\Anaconda3\lib\site-packages\tensorflow\python\util\tf_should_use.py:235: initialize_all_variables (from tensorflow.python.ops.variables) is deprecated and will be removed after 2017-03-02. Instructions for updating: Use `tf.global_variables_initializer` instead. Input = [10 x 10] array 2x2 Convolution, stride size = [2x2], results in the [5x5] array: [[ 0.9541372 -0.5357596 -1.9833868 0.9627971 0.34088665] [-1.480279 1.0545661 0.27794296 1.0536083 0.9530723 ] [ 1.6841828 1.1668804 -0.1371274 -3.2182534 1.9898502 ] [-1.077354 3.28457 3.120058 -1.7702417 -0.75471795] [-0.08349466 1.4444114 1.7416577 0.10787213 -3.7250257 ]] Input = the above [5x5] array Relu element wise returns the [5x5] array: [[0.9541372 0. 0. 0.9627971 0.34088665] [0. 1.0545661 0.27794296 1.0536083 0.9530723 ] [1.6841828 1.1668804 0. 0. 1.9898502 ] [0. 3.28457 3.120058 0. 0. ] [0. 1.4444114 1.7416577 0.10787213 0. ]] Input = the above [5x5] array [2x2] MaxPool, stride size = [1x1] results in the [4x4] array: [[1.0545661 1.0545661 1.0536083 1.0536083 ] [1.6841828 1.1668804 1.0536083 1.9898502 ] [3.28457 3.28457 3.120058 1.9898502 ] [3.28457 3.28457 3.120058 0.10787213]] Input = the above [4x4] array Fully connected layer on all four rows with five outputs: [ 2.3414695 0.36326647 1.9187844 1.7268257 -0.7776375 ]
TensorFlow 实现多层神经网络
import csv import os import matplotlib.pyplot as plt import numpy as np import requests import tensorflow.compat.v1 as tf tf.disable_v2_behavior() # 使用静态图模式运行以下代码 assert tf.__version__.startswith('2.') sess = tf.Session() # 2 导入数据 # name of data file birth_weight_file = 'birth_weight.csv' birthdata_url = 'https://github.com/nfmcclure/tensorflow_cookbook/raw/master' \ '/01_Introduction/07_Working_with_Data_Sources/birthweight_data/birthweight.dat' # Download data and create data file if file does not exist in current directory if not os.path.exists(birth_weight_file): birth_file = requests.get(birthdata_url) birth_data = birth_file.text.split('\r\n') birth_header = birth_data[0].split('\t') birth_data = [[float(x) for x in y.split('\t') if len(x) >= 1] for y in birth_data[1:] if len(y) >= 1] with open(birth_weight_file, "w") as f: writer = csv.writer(f) writer.writerows([birth_header]) writer.writerows(birth_data) # read birth weight data into memory birth_data = [] with open(birth_weight_file, newline='') as csvfile: csv_reader = csv.reader(csvfile) birth_header = next(csv_reader) for row in csv_reader: if len(row) > 0: birth_data.append(row) birth_data = [[float(x) for x in row] for row in birth_data] # Extract y-target (birth weight) y_vals = np.array([x[8] for x in birth_data]) # Filter for features of interest cols_of_interest = ['AGE', 'LWT', 'RACE', 'SMOKE', 'PTL', 'HT', 'UI'] x_vals = np.array([[x[ix] for ix, feature in enumerate(birth_header) if feature in cols_of_interest] for x in birth_data]) # 3 设置种子 seed = 4 tf.set_random_seed(seed) np.random.seed(seed) batch_size = 100 # 4 划分训练集和测试集 train_indices = np.random.choice(len(x_vals), round(len(x_vals) * 0.8), replace=False) test_indices = np.array(list(set(range(len(x_vals))) - set(train_indices))) x_vals_train = x_vals[train_indices] x_vals_test = x_vals[test_indices] y_vals_train = y_vals[train_indices] y_vals_test = y_vals[test_indices] def normalize_cols(m): col_max = m.max(axis=0) col_min = m.min(axis=0) return (m - col_min) / (col_max - col_min) x_vals_train = np.nan_to_num(normalize_cols(x_vals_train)) x_vals_test = np.nan_to_num(normalize_cols(x_vals_test)) # 5 定义一个设置变量和bias的函数 def init_weight(shape, st_dev): weight = tf.Variable(tf.random_normal(shape, stddev=st_dev)) return weight def init_bias(shape, st_dev): bias = tf.Variable(tf.random_normal(shape, stddev=st_dev)) return bias # 6 初始化占位符 x_data = tf.placeholder(shape=[None, 7], dtype=tf.float32) y_target = tf.placeholder(shape=[None, 1], dtype=tf.float32) # 7 创建全连接层函数,方便重复使用 def fully_connected(input_layer, weights, biases): layer = tf.add(tf.matmul(input_layer, weights), biases) return tf.nn.relu(layer) # 8 创建算法模型 # Create second layer (25 hidden nodes) weight_1 = init_weight(shape=[7, 25], st_dev=10.0) bias_1 = init_weight(shape=[25], st_dev=10.0) layer_1 = fully_connected(x_data, weight_1, bias_1) # Create second layer (10 hidden nodes) weight_2 = init_weight(shape=[25, 10], st_dev=10.0) bias_2 = init_weight(shape=[10], st_dev=10.0) layer_2 = fully_connected(layer_1, weight_2, bias_2) # Create third layer (3 hidden nodes) weight_3 = init_weight(shape=[10, 3], st_dev=10.0) bias_3 = init_weight(shape=[3], st_dev=10.0) layer_3 = fully_connected(layer_2, weight_3, bias_3) # Create output layer (1 output value) weight_4 = init_weight(shape=[3, 1], st_dev=10.0) bias_4 = init_bias(shape=[1], st_dev=10.0) final_output = fully_connected(layer_3, weight_4, bias_4) # 9 L1损失函数 loss = tf.reduce_mean(tf.abs(y_target - final_output)) my_opt = tf.train.AdamOptimizer(0.05) train_step = my_opt.minimize(loss) init = tf.global_variables_initializer() sess.run(init) # 10 迭代200 # Initialize the loss vectors loss_vec = [] test_loss = [] for i in range(200): # Choose random indices for batch selection rand_index = np.random.choice(len(x_vals_train), size=batch_size) # Get random batch rand_x = x_vals_train[rand_index] rand_y = np.transpose([y_vals_train[rand_index]]) # Run the training step sess.run(train_step, feed_dict={x_data: rand_x, y_target: rand_y}) # Get and store the train loss temp_loss = sess.run(loss, feed_dict={x_data: rand_x, y_target: rand_y}) loss_vec.append(temp_loss) # get and store the test loss test_temp_loss = sess.run(loss, feed_dict={x_data: x_vals_test, y_target: np.transpose([y_vals_test])}) test_loss.append(test_temp_loss) if (i + 1) % 25 == 0: print('Generation: ' + str(i + 1) + '.Loss = ' + str(temp_loss)) # 12 绘图 plt.plot(loss_vec, 'k-', label='Train Loss') plt.plot(test_loss, 'r--', label='Test Loss') plt.title('Loss per Generation') plt.xlabel('Generation') plt.ylabel('Loss') plt.legend(loc='upper right') plt.show() # Model Accuracy actuals = np.array([x[0] for x in birth_data]) test_actuals = actuals[test_indices] train_actuals = actuals[train_indices] test_preds = [x[0] for x in sess.run(final_output, feed_dict={x_data: x_vals_test})] train_preds = [x[0] for x in sess.run(final_output, feed_dict={x_data: x_vals_train})] test_preds = np.array([0.0 if x < 2500.0 else 1.0 for x in test_preds]) train_preds = np.array([0.0 if x < 2500.0 else 1.0 for x in train_preds]) # Print out accuracies test_acc = np.mean([x == y for x, y in zip(test_preds, test_actuals)]) train_acc = np.mean([x == y for x, y in zip(train_preds, train_actuals)]) print('On predicting the category of low birthweight from regression output (<2500g):') print('Test Accuracy: {}'.format(test_acc)) print('Train Accuracy: {}'.format(train_acc))
执行结果:
C:\Anaconda3\python.exe "C:\Program Files\JetBrains\PyCharm 2019.1.1\helpers\pydev\pydevconsole.py" --mode=client --port=49628 import sys; print('Python %s on %s' % (sys.version, sys.platform)) sys.path.extend(['C:\\app\\PycharmProjects', 'C:/app/PycharmProjects']) Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] Type 'copyright', 'credits' or 'license' for more information IPython 7.12.0 -- An enhanced Interactive Python. Type '?' for help. PyDev console: using IPython 7.12.0 Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] on win32 runfile('C:/app/PycharmProjects/ArtificialIntelligence/classification.py', wdir='C:/app/PycharmProjects/ArtificialIntelligence') WARNING:tensorflow:From C:\Anaconda3\lib\site-packages\tensorflow\python\compat\v2_compat.py:96: disable_resource_variables (from tensorflow.python.ops.variable_scope) is deprecated and will be removed in a future version. Instructions for updating: non-resource variables are not supported in the long term 2020-06-16 17:57:44.532006: I tensorflow/core/platform/cpu_feature_guard.cc:143] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 2020-06-16 17:57:44.552087: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x12781280550 initialized for platform Host (this does not guarantee that XLA will be used). Devices: 2020-06-16 17:57:44.554884: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version Generation: 25.Loss = 2876.5713 Generation: 50.Loss = 2733.6035 Generation: 75.Loss = 2716.0818 Generation: 100.Loss = 2562.6213 Generation: 125.Loss = 2748.026 Generation: 150.Loss = 2664.8457 Generation: 175.Loss = 2535.071 Generation: 200.Loss = 2723.3906 On predicting the category of low birthweight from regression output (<2500g): Test Accuracy: 0.5789473684210527 Train Accuracy: 0.6556291390728477
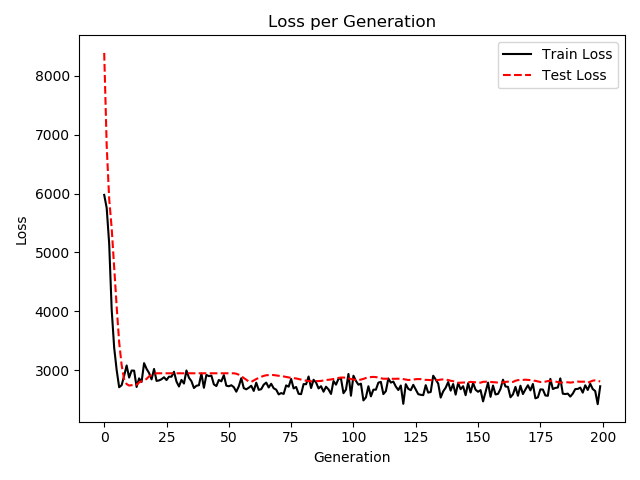
实现了一个含有三层隐藏层的全连接神经网络。
线性预测模型的优化
代码实现:
import csv import os import matplotlib.pyplot as plt import numpy as np import requests import tensorflow.compat.v1 as tf tf.disable_v2_behavior() # 使用静态图模式运行以下代码 assert tf.__version__.startswith('2.') sess = tf.Session() # 加载数据集,进行数据抽取和归一化 # name of data file birth_weight_file = 'birth_weight.csv' birthdata_url = 'https://github.com/nfmcclure/tensorflow_cookbook/raw/master' \ '/01_Introduction/07_Working_with_Data_Sources/birthweight_data/birthweight.dat' # Download data and create data file if file does not exist in current directory if not os.path.exists(birth_weight_file): birth_file = requests.get(birthdata_url) birth_data = birth_file.text.split('\r\n') birth_header = birth_data[0].split('\t') birth_data = [[float(x) for x in y.split('\t') if len(x) >= 1] for y in birth_data[1:] if len(y) >= 1] with open(birth_weight_file, "w") as f: writer = csv.writer(f) writer.writerows([birth_header]) writer.writerows(birth_data) # read birth weight data into memory birth_data = [] with open(birth_weight_file, newline='') as csvfile: csv_reader = csv.reader(csvfile) birth_header = next(csv_reader) for row in csv_reader: if len(row) > 0: birth_data.append(row) birth_data = [[float(x) for x in row] for row in birth_data] # Extract y-target (birth weight) y_vals = np.array([x[0] for x in birth_data]) # Filter for features of interest cols_of_interest = ['AGE', 'LWT', 'RACE', 'SMOKE', 'PTL', 'HT', 'UI'] x_vals = np.array([[x[ix] for ix, feature in enumerate(birth_header) if feature in cols_of_interest] for x in birth_data]) # 4 划分训练集和测试集 train_indices = np.random.choice(len(x_vals), round(len(x_vals) * 0.8), replace=False) test_indices = np.array(list(set(range(len(x_vals))) - set(train_indices))) x_vals_train = x_vals[train_indices] x_vals_test = x_vals[test_indices] y_vals_train = y_vals[train_indices] y_vals_test = y_vals[test_indices] def normalize_cols(m): col_max = m.max(axis=0) col_min = m.min(axis=0) return (m - col_min) / (col_max - col_min) x_vals_train = np.nan_to_num(normalize_cols(x_vals_train)) x_vals_test = np.nan_to_num(normalize_cols(x_vals_test)) # 3 声明批量大小和占位符 batch_size = 90 x_data = tf.placeholder(shape=[None, 7], dtype=tf.float32) y_target = tf.placeholder(shape=[None, 1], dtype=tf.float32) # 4 声明函数来初始化变量和层 def init_variable(shape): return tf.Variable(tf.random_normal(shape=shape)) # Create a logistic layer definition def logistic(input_layer, multiplication_weight, bias_weight, activation=True): linear_layer = tf.add(tf.matmul(input_layer, multiplication_weight), bias_weight) if activation: return tf.nn.sigmoid(linear_layer) else: return linear_layer # 5 声明神经网络的两个隐藏层和输出层 # First logistic layer (7 inputs to 14 hidden nodes) A1 = init_variable(shape=[7, 14]) b1 = init_variable(shape=[14]) logistic_layer1 = logistic(x_data, A1, b1) # Second logistic layer (14 inputs to 5 hidden nodes) A2 = init_variable(shape=[14, 5]) b2 = init_variable(shape=[5]) logistic_layer2 = logistic(logistic_layer1, A2, b2) # Final output layer (5 hidden nodes to 1 output) A3 = init_variable(shape=[5, 1]) b3 = init_variable(shape=[1]) final_output = logistic(logistic_layer2, A3, b3, activation=False) # 6 声明损失函数和优化方法 # Create loss function loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits( labels=y_target, logits=final_output)) # Declare optimizer my_opt = tf.train.AdamOptimizer(learning_rate=0.002) train_step = my_opt.minimize(loss) # Initialize variables init = tf.global_variables_initializer() sess.run(init) # 7 评估精度 prediction = tf.round(tf.nn.sigmoid(final_output)) predictions_correct = tf.cast(tf.equal(prediction, y_target), tf.float32) accuracy = tf.reduce_mean(predictions_correct) # 8 迭代训练模型 # Initialize loss and accuracy vectors loss_vec = [] train_acc = [] test_acc = [] for i in range(1500): # Select random indicies for batch selection rand_index = np.random.choice(len(x_vals_train), size=batch_size) # Select batch rand_x = x_vals_train[rand_index] rand_y = np.transpose([y_vals_train[rand_index]]) # Run training step sess.run(train_step, feed_dict={x_data: rand_x, y_target: rand_y}) # Get training loss temp_loss = sess.run(loss, feed_dict={x_data: rand_x, y_target: rand_y}) loss_vec.append(temp_loss) # Get training accuracy temp_acc_train = sess.run(accuracy, feed_dict={x_data: x_vals_train, y_target: np.transpose([y_vals_train])}) train_acc.append(temp_acc_train) # Get test accuracy temp_acc_test = sess.run(accuracy, feed_dict={x_data: x_vals_test, y_target: np.transpose([y_vals_test])}) test_acc.append(temp_acc_test) if (i + 1) % 150 == 0: print('Loss = ' + str(temp_loss)) # 9 绘图 # Plot loss over time plt.plot(loss_vec, 'k-') plt.title('Cross Entropy Loss per Generation') plt.xlabel('Generation') plt.ylabel('Cross Entropy Loss') plt.show() # Plot train and test accuracy plt.plot(train_acc, 'k-', label='Train Set Accuracy') plt.plot(test_acc, 'r--', label='Test Set Accuracy') plt.title('Train and Test Accuracy') plt.xlabel('Generation') plt.ylabel('Accuracy') plt.legend(loc='lower right') plt.show()
执行结果:
C:\Anaconda3\python.exe "C:\Program Files\JetBrains\PyCharm 2019.1.1\helpers\pydev\pydevconsole.py" --mode=client --port=50184 import sys; print('Python %s on %s' % (sys.version, sys.platform)) sys.path.extend(['C:\\app\\PycharmProjects', 'C:/app/PycharmProjects']) Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] Type 'copyright', 'credits' or 'license' for more information IPython 7.12.0 -- An enhanced Interactive Python. Type '?' for help. PyDev console: using IPython 7.12.0 Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] on win32 runfile('C:/app/PycharmProjects/ArtificialIntelligence/classification.py', wdir='C:/app/PycharmProjects/ArtificialIntelligence') WARNING:tensorflow:From C:\Anaconda3\lib\site-packages\tensorflow\python\compat\v2_compat.py:96: disable_resource_variables (from tensorflow.python.ops.variable_scope) is deprecated and will be removed in a future version. Instructions for updating: non-resource variables are not supported in the long term 2020-06-16 18:03:42.213313: I tensorflow/core/platform/cpu_feature_guard.cc:143] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 2020-06-16 18:03:42.230418: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x24a2a2387e0 initialized for platform Host (this does not guarantee that XLA will be used). Devices: 2020-06-16 18:03:42.232488: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version Loss = 0.5170202 Loss = 0.53559077 Loss = 0.51184845 Loss = 0.5487095 Loss = 0.48175952 Loss = 0.5629245 Loss = 0.469246 Loss = 0.586653 Loss = 0.5067203 Loss = 0.51572895
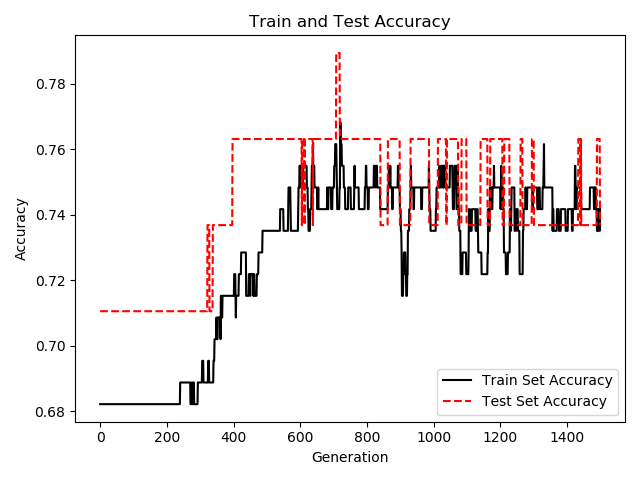
这一个仍然是全连接,只是只有两层隐藏层,节点数也减少了。
本文来自博客园,作者:大码王,转载请注明原文链接:https://www.cnblogs.com/huanghanyu/

 posted on
posted on










【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具