

一、决策树的原理
决策树思想的来源非常朴素,程序设计中的条件分支结构就是if-then结构,最早的决策树就是利用这类结构分割数据的一种分类学习方法 。
二、决策树的现实案例
相亲

女儿:多大年纪了?
母亲:26。
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。
银行是否发放贷款
行长:是否有自己的房子?
职员:有。
行长:可以考虑放贷。
职员:如果没有自己的房子呢?
行长:是否有稳定工作?
职员:有。
行长:可以考虑放贷。
职员:那如果没有呢?
行长:既没有自己的房子,也没有稳定工作,那咱还放啥贷款?
职员:懂了。

预测足球队是否夺冠

三、信息论基础
信息熵:
假如我们竞猜32只足球队谁是冠军?我可以把球编上号,从1到32,然后提问:冠 军在1-16号吗?依次进行二分法询问,只需要五次,就可以知道结果。
32支球队,问询了5次,信息量定义为5比特,log32=5比特。比特就是表示信息的单位。
假如有64支球队的话,那么我们需要二分法问询6次,信息量就是6比特,log64=6比特。
问询了多少次,专业术语称之为信息熵,单位为比特。
公式为:

信息熵的作用:
决策树生成的过程中,信息熵大的作为根节点,信息熵小的作为叶子节点,按照信息熵的从大到小原则,生成决策树。
条件熵:
条件熵H(D|A)表示在已知随机变量A的条件下随机变量D的不确定性。
公式为:

通俗来讲就是,知道A情况下,D的信息量。
信息增益:
特征A对训练数据集D的信息增益g(D,A),定义为集合D的信息熵H(D)与特征A给定条件下D的信息条件熵H(D|A)之差。
公式为:

怎么理解信息增益呢?信息增益表示得知特征X的信息而使得类Y的信息的不确定性减少的程度。简单讲,就是知道的增多,使得不知道的(不确定的)就减少。
四、 决策树API
决策树:

sklearn.tree.DecisionTreeClassifier class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, max_depth=None,random_state=None) 决策树分类器 criterion:默认是’gini’系数,也可以选择信息增益的熵’entropy’ max_depth:树的深度大小 random_state:随机数种子 method: dec.fit(X,y): 根据数据集(X,y)建立决策树分类器 dec.apply(X): 返回每个样本被预测为的叶子的索引。 dec.cost_complexity_pruning_path(X,y): 在最小成本复杂性修剪期间计算修剪路径。 dec.decision_path(X): 返回树中的决策路径 dec.get_depth(): 返回树的深度 dec.get_n_leaves(): 返回决策树的叶子节点 dec.get_params(): 返回评估器的参数 dec.predict(X): 预测X的类或回归值 dec.predict_log_proba(X): 预测X的类的log值 dec.predict_proba(X): 预测X分类的概率值 dec.score(X,y): 测试数据X和标签值y之间的平均准确率 dec.set_params(min_samples_split=3): 设置评估器的参数 X 表示训练集,y表示特征值
决策树的生成与本地保存:
from sklearn.tree import DecisionTreeClassifier from sklearn.datasets import load_iris li = load_iris() dec = DecisionTreeClassifier() # 根据训练集(X,y)建立决策树分类器 dec.fit(li.data,li.target) # 预测X的类或回归值 dec.predict(li.data) # 测试数据X和标签值y之间的平均准确率 dec.score(li.data,li.target) # 保存树文件 tree.dot tree.export_graphviz(dec,out_file='tree.dot') tree.dot 保存结果: digraph Tree { node [shape=box] ; 0 [label="X[2] <= 2.45\ngini = 0.667\nsamples = 150\nvalue = [50, 50, 50]"] ; 1 [label="gini = 0.0\nsamples = 50\nvalue = [50, 0, 0]"] ; .....
五、实现案例
1、导入数据,划分测试集,训练集
from sklearn import tree from sklearn.datasets import load_wine from sklearn.model_selection import train_test_split import graphviz import pandas as pd data = load_wine() dataFrame = pd.concat([pd.DataFrame(X_train),pd.DataFrame(y_train)],axis=1) print(dataFrame) X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.3, random_state=30)

2、模型实例化
clf = tree.DecisionTreeClassifier(criterion='gini' ,max_depth=None ,min_samples_leaf=1 ,min_samples_split=2 ,random_state=0 ,splitter='best' )
3、数据代入训练
4、测试集导入打分
score = clf.score(X_test,y_test)
5、graphviz画出决策树
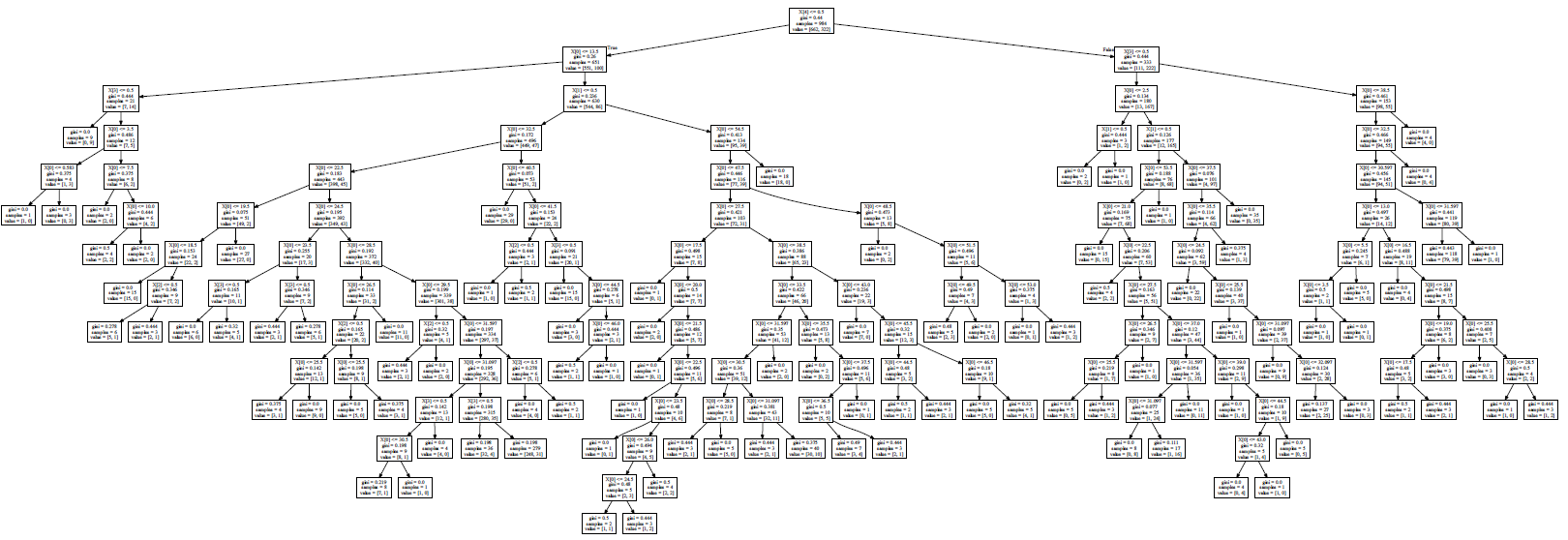
feature_name = ['酒精','苹果酸','灰','灰的碱性','镁','总酚','类黄酮','非黄烷类酚类','花青素','颜色强度','色调','od280/od315稀释葡萄酒','脯氨酸'] dot_data = tree.export_graphviz(clf ,out_file=None ,feature_names=feature_name ,class_names=["红酒","白酒","葡萄酒"] #别名 ,filled=True ,rounded=True ) graph = graphviz.Source(dot_data)

6、参数的重要性讨论
clf.feature_importances_
[*zip(feature_name,clf.feature_importances_)]
[('酒精', 0.0),
('苹果酸', 0.0),
('灰', 0.023800041266200594),
('灰的碱性', 0.0),
('镁', 0.0),
('总酚', 0.0),
('类黄酮', 0.14796731056604398),
('非黄烷类酚类', 0.0),
('花青素', 0.023717402234026283),
('颜色强度', 0.3324466124446747),
('色调', 0.021345662010623646),
('od280/od315稀释葡萄酒', 0.0),
('脯氨酸', 0.45072297147843077)]
7、参数的稳定性和随机性
问题:为什么大家对同一份数据进行执行,结果分数会不一样呢?同一个人执行同一份数据,每次的分数结果也会不一样?
答:是因为训练数据集在模型里每次都是随机划分的,所以执行的结果会不稳定,那么要怎么才会稳定呢?参数random_state就是用来干这个事情的,只要给random_state设置了值,那么每次执行的结果就都会是一样的了。具体设置多少呢?是不一定的,从0到n可以自己尝试,哪个值得到的score高就用哪个。
clf = tree.DecisionTreeClassifier(criterion="entropy",random_state=30)
clf = clf.fit(X_train, y_train)
score = clf.score(X_test, y_test) #返回预测的准确度
8、剪枝参数调优
为什么要剪枝?
剪枝参数的默认值会让树无限增长,这些树在某些数据集中可能非常巨大,非常消耗内存。其次,决策树的无限增长会造成过拟合线性,导致模型在训练集中表现很好,但是在测试集中表现一般。之所以在训练集中表现很好,是包括了训练集中的噪音在里面,造成了过拟合现象。所以,我们要对决策树进行剪枝参数调优。
常用的参数主要有:
-
min_samples_leaf: 叶子的最小样本量,如果少于设定的值,则停止分枝;太小引起过拟合,太大阻止模型学习数据;建议从5开始;
-
min_samples_split: 分枝节点的样本量,如果少于设定的值,那么就停止分枝。
-
max_depth:树的深度,超过深度的树枝会被剪掉,建议从3开始,看效果决定是否要增加深度;如果3的准确率只有50%,那增加深度,如果3的准确率80%,90%,那考虑限定深度,不用再增加深度了,节省计算空间。
clf = tree.DecisionTreeClassifier(min_samples_leaf=10 , min_samples_split=20 , max_depth=3) clf.fit(X_train, y_train) dot_data = tree.export_graphviz(clf ,feature_names=feature_name ,class_names=["红酒","白酒","葡萄酒"] #别名 ,filled=True ,rounded=True) graphviz.Source(dot_data)

9、确定最优剪枝参数
import matplotlib.pyplot as plt score_list = [] for i in range(1,11): clf = tree.DecisionTreeClassifier(max_depth=i ,criterion="entropy" ,random_state=30 ,splitter="random") clf.fit(Xtrain, Ytrain) score = clf.score(Xtest, Ytest) score_list.append(score) plt.plot(range(1,11),score_list,color="red",label="max_depth",linewidth=2) plt.legend() plt.show()

可以看到,max_depth在=3的时候,score已经达到了最高,再增加深度,则会增加过拟合的风险。
六、 决策树的优缺点
优点
- 简单的理解和解释,树木可视化。
- 需要很少的数据准备,其他技术通常需要数据归一化。
缺点
- 决策树学习者可以创建不能很好地推广数据的过于复杂的树,被称为过拟合。
- 决策树可能不稳定,因为数据的小变化可能会导致完全不同的树
被生成。
改进
- 减枝cart算法
- 随机森林
七、环境准备
在Windows中直接利用pip是无法进行安装的,网上有很多的方法,具体每个人可能报错的原因不一样,这里我说明一下我是怎么解决的:
下载并安装Graphviz
设置环境变量
为Python加载Graphviz
资源下载
Graphviz的官网下载:https://graphviz.gitlab.io/_pages/Download/Download_windows.html,下载后按照提示进行安装就可以了;
在anaconda中新建了一个graphviz文件夹,安装在此文件夹中方便查找;
设置环境变量:
如果没配置环境变量会出现如下报错:
'dot' 不是内部或外部命令,也不是可运行的程序 或批处理文件。
在:我的电脑-系统属性-高级系统设置-高级-环境变量-系统变量-找到Path 进行环境配置
将上面安装的graphviz中的bin路径添加到path中(添加不是重建)
我这里是:D:\Anaconda\graphviz\bin
测试安装:
1.win+R
2.输入命令:dot -version
3.观察到如下信息,则该设置生效;
加载graphviz
此时再利用pip进行安装即可:
pip install graphviz
八、完整代码
1、鸳鸯花实现:
代码实现:
# coding: utf-8 # In[1]: from sklearn import datasets import math import numpy as np # In[69]: def getInformationEntropy(arr, leng): # print("length = ",leng) return -(arr[0] / leng * math.log(arr[0] / leng if arr[0] > 0 else 1) + arr[1] / leng * math.log( arr[1] / leng if arr[1] > 0 else 1) + arr[2] / leng * math.log(arr[2] / leng if arr[2] > 0 else 1)) # informationEntropy = getInformationEntropy(num,length) # print(informationEntropy) # In[105]: # 离散化特征一的值 def discretization(index): feature1 = np.array([iris.data[:, index], iris.target]).T feature1 = feature1[feature1[:, 0].argsort()] counter1 = np.array([0, 0, 0]) counter2 = np.array([0, 0, 0]) resEntropy = 100000 for i in range(len(feature1[:, 0])): counter1[int(feature1[i, 1])] = counter1[int(feature1[i, 1])] + 1 counter2 = np.copy(counter1) for j in range(i + 1, len(feature1[:, 0])): counter2[int(feature1[j, 1])] = counter2[int(feature1[j, 1])] + 1 # print(i,j,counter1,counter2) # 贪心算法求最优的切割点 if i != j and j != len(feature1[:, 0]) - 1: # print(counter1,i+1,counter2-counter1,j-i,np.array(num)-counter2,length-j-1) sum = (i + 1) * getInformationEntropy(counter1, i + 1) + (j - i) * getInformationEntropy( counter2 - counter1, j - i) + (length - j - 1) * getInformationEntropy(np.array(num) - counter2, length - j - 1) if sum < resEntropy: resEntropy = sum res = np.array([i, j]) res_value = [feature1[res[0], 0], feature1[res[1], 0]] print(res, resEntropy, res_value) return res_value # In[122]: # 求合适的分割值 def getRazors(): a = [] for i in range(len(iris.feature_names)): print(i) a.append(discretization(i)) return np.array(a) # In[326]: # 随机抽取80%的训练集和20%的测试集 def divideData(): completeData = np.c_[iris.data, iris.target.T] np.random.shuffle(completeData) trainData = completeData[range(int(length * 0.8)), :] testData = completeData[range(int(length * 0.8), length), :] return [trainData, testData] # In[213]: def getEntropy(counter): res = 0 denominator = np.sum(counter) if denominator == 0: return 0 for value in counter: if value == 0: continue res += value / denominator * math.log(value / denominator if value > 0 and denominator > 0 else 1) return -res # In[262]: def findMaxIndex(dataSet): maxIndex = 0 maxValue = -1 for index, value in enumerate(dataSet): if value > maxValue: maxIndex = index maxValue = value return maxIndex # In[308]: def recursion(featureSet, dataSet, counterSet): # print("函数开始,剩余特征:",featureSet," 剩余结果长度:",len(dataSet)) if (counterSet[0] == 0 and counterSet[1] == 0 and counterSet[2] != 0): return iris.target_names[2] if (counterSet[0] != 0 and counterSet[1] == 0 and counterSet[2] == 0): return iris.target_names[0] if (counterSet[0] == 0 and counterSet[1] != 0 and counterSet[2] == 0): return iris.target_names[1] if len(featureSet) == 0: return iris.target_names[findMaxIndex(counterSet)] if len(dataSet) == 0: return [] res = 1000 final = 0 # print("剩余特征数目", len(featureSet)) for feature in featureSet: i = razors[feature][0] j = razors[feature][1] # print("i = ",i," j = ",j) set1 = [] set2 = [] set3 = [] counter1 = [0, 0, 0] counter2 = [0, 0, 0] counter3 = [0, 0, 0] for data in dataSet: index = int(data[-1]) # print("data ",data," index ",index) if data[feature] < i: set1.append(data) counter1[index] = counter1[index] + 1 elif data[feature] >= i and data[feature] <= j: set2.append(data) counter2[index] = counter2[index] + 1 else: set3.append(data) counter3[index] = counter3[index] + 1 a = (len(set1) * getEntropy(counter1) + len(set2) * getEntropy(counter2) + len(set3) * getEntropy( counter3)) / len(dataSet) # print("特征编号:",feature,"选取该特征得到的信息熵:",a) if a < res: res = a final = feature # 返回被选中的特征的下标 # sequence.append(final) # print("最终在本节点上选取的特征编号是:",final) featureSet.remove(final) child = [0, 0, 0, 0] child[0] = final child[1] = recursion(featureSet, set1, counter1) child[2] = recursion(featureSet, set2, counter2) child[3] = recursion(featureSet, set3, counter3) return child # In[322]: def judge(data, tree): root = "unknow" while (len(tree) > 0): if isinstance(tree, str) and tree in iris.target_names: return tree root = tree[0] if (isinstance(root, str)): return root if isinstance(root, int): if data[root] < razors[root][0] and tree[1] != []: tree = tree[1] elif tree[2] != [] and (tree[1] == [] or (data[root] >= razors[root][0] and data[root] <= razors[root][1])): tree = tree[2] else: tree = tree[3] return root # In[327]: if __name__ == '__main__': iris = datasets.load_iris() num = [0, 0, 0] for row in iris.data: num[int(row[-1])] = num[int(row[-1])] + 1 length = len(iris.target) [trainData, testData] = divideData() razors = getRazors() tree = recursion(list(range(len(iris.feature_names))), trainData, [np.sum(trainData[:, -1] == 0), np.sum(trainData[:, -1] == 1), np.sum(trainData[:, -1] == 2)]) print("本次选取的训练集构建出的树: ", tree) index = 0 right = 0 for data in testData: result = judge(testData[index], tree) truth = iris.target_names[int(testData[index][-1])] print("result is ", result, " truth is ", truth) index = index + 1 if result == truth: right = right + 1 print("正确率 : ", right / index)
执行结果:
C:\Anaconda3\python.exe "C:\Program Files\JetBrains\PyCharm 2019.1.1\helpers\pydev\pydevconsole.py" --mode=client --port=57893 import sys; print('Python %s on %s' % (sys.version, sys.platform)) sys.path.extend(['C:\\app\\PycharmProjects', 'C:/app/PycharmProjects']) Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] Type 'copyright', 'credits' or 'license' for more information IPython 7.12.0 -- An enhanced Interactive Python. Type '?' for help. PyDev console: using IPython 7.12.0 Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] on win32 runfile('C:/app/PycharmProjects/ArtificialIntelligence/test.py', wdir='C:/app/PycharmProjects/ArtificialIntelligence') 0 [ 54 148] 38.11466484080816 [5.5, 7.7] 1 [ 75 148] 60.48021792365705 [3.0, 4.2] 2 [ 49 148] 4.6815490923045076 [1.9, 6.7] 3 [ 49 148] 4.6815490923045076 [0.6, 2.5] 本次选取的训练集构建出的树: [3, 'setosa', [0, [], [1, [], [2, 'setosa', 'versicolor', 'setosa'], 'setosa'], 'virginica'], 'setosa'] result is versicolor truth is virginica result is setosa truth is setosa result is versicolor truth is versicolor result is versicolor truth is virginica result is versicolor truth is versicolor result is setosa truth is setosa result is versicolor truth is versicolor result is setosa truth is setosa result is versicolor truth is virginica result is versicolor truth is virginica result is setosa truth is setosa result is setosa truth is setosa result is versicolor truth is virginica result is setosa truth is setosa result is setosa truth is setosa result is versicolor truth is versicolor result is setosa truth is setosa result is setosa truth is setosa result is versicolor truth is versicolor result is versicolor truth is virginica result is versicolor truth is virginica result is versicolor truth is versicolor result is setosa truth is setosa result is versicolor truth is virginica result is versicolor truth is virginica result is versicolor truth is virginica result is versicolor truth is versicolor result is versicolor truth is virginica result is setosa truth is setosa result is setosa truth is setosa 正确率 : 0.6333333333333333
2、声音和头发类型实现:
代码实现:
from math import log import operator def calcShannonEnt(dataSet): # 计算数据的熵(entropy) numEntries=len(dataSet) # 数据条数 labelCounts={} for featVec in dataSet: currentLabel=featVec[-1] # 每行数据的最后一个字(类别) if currentLabel not in labelCounts.keys(): labelCounts[currentLabel]=0 labelCounts[currentLabel]+=1 # 统计有多少个类以及每个类的数量 shannonEnt=0 for key in labelCounts: prob=float(labelCounts[key])/numEntries # 计算单个类的熵值 shannonEnt-=prob*log(prob,2) # 累加每个类的熵值 return shannonEnt def createDataSet1(): # 创造示例数据 dataSet = [['长', '粗', '男'], ['短', '粗', '男'], ['短', '粗', '男'], ['长', '细', '女'], ['短', '细', '女'], ['短', '粗', '女'], ['长', '粗', '女'], ['长', '粗', '女']] labels = ['头发','声音'] #两个特征 return dataSet,labels def splitDataSet(dataSet,axis,value): # 按某个特征分类后的数据 retDataSet=[] for featVec in dataSet: if featVec[axis]==value: reducedFeatVec =featVec[:axis] reducedFeatVec.extend(featVec[axis+1:]) retDataSet.append(reducedFeatVec) return retDataSet def chooseBestFeatureToSplit(dataSet): # 选择最优的分类特征 numFeatures = len(dataSet[0])-1 baseEntropy = calcShannonEnt(dataSet) # 原始的熵 bestInfoGain = 0 bestFeature = -1 for i in range(numFeatures): featList = [example[i] for example in dataSet] uniqueVals = set(featList) newEntropy = 0 for value in uniqueVals: subDataSet = splitDataSet(dataSet,i,value) prob =len(subDataSet)/float(len(dataSet)) newEntropy +=prob*calcShannonEnt(subDataSet) # 按特征分类后的熵 infoGain = baseEntropy - newEntropy # 原始熵与按特征分类后的熵的差值 if (infoGain>bestInfoGain): # 若按某特征划分后,熵值减少的最大,则次特征为最优分类特征 bestInfoGain=infoGain bestFeature = i return bestFeature def majorityCnt(classList): #按分类后类别数量排序,比如:最后分类为2男1女,则判定为男; classCount={} for vote in classList: if vote not in classCount.keys(): classCount[vote]=0 classCount[vote]+=1 sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True) return sortedClassCount[0][0] def createTree(dataSet,labels): classList=[example[-1] for example in dataSet] # 类别:男或女 if classList.count(classList[0])==len(classList): return classList[0] if len(dataSet[0])==1: return majorityCnt(classList) bestFeat=chooseBestFeatureToSplit(dataSet) #选择最优特征 bestFeatLabel=labels[bestFeat] myTree={bestFeatLabel:{}} #分类结果以字典形式保存 del(labels[bestFeat]) featValues=[example[bestFeat] for example in dataSet] uniqueVals=set(featValues) for value in uniqueVals: subLabels=labels[:] myTree[bestFeatLabel][value]=createTree(splitDataSet\ (dataSet,bestFeat,value),subLabels) return myTree if __name__=='__main__': dataSet, labels=createDataSet1() # 创造示列数据 print(createTree(dataSet, labels)) # 输出决策树模型结果
执行结果:
C:\Anaconda3\python.exe "C:\Program Files\JetBrains\PyCharm 2019.1.1\helpers\pydev\pydevconsole.py" --mode=client --port=65305 import sys; print('Python %s on %s' % (sys.version, sys.platform)) sys.path.extend(['C:\\app\\PycharmProjects', 'C:/app/PycharmProjects']) Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] Type 'copyright', 'credits' or 'license' for more information IPython 7.12.0 -- An enhanced Interactive Python. Type '?' for help. PyDev console: using IPython 7.12.0 Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] on win32 runfile('C:/app/PycharmProjects/ArtificialIntelligence/K_means.py', wdir='C:/app/PycharmProjects/ArtificialIntelligence') {'声音': {'细': '女', '粗': {'头发': {'短': '男', '长': '女'}}}}
3、泰坦尼克号实现
代码实现:
#coding=utf-8 import pandas as pd from sklearn.model_selection import train_test_split from sklearn.feature_extraction import DictVectorizer #特征转换器 from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import classification_report from sklearn import tree #1.数据获取 titanic = pd.read_csv('C:/data/titanic.txt') #print titanic.head() #print titanic.info() X = titanic[['pclass','age','sex']] #提取要分类的特征。一般可以通过最大熵原理进行特征选择 y = titanic['survived'] print (X.shape) #(1313, 3) #print X.head() #print X['age'] #2.数据预处理:训练集测试集分割,数据标准化 X['age'].fillna(X['age'].mean(),inplace=True) #age只有633个,需补充,使用平均数或者中位数都是对模型偏离造成最小的策略 X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.25,random_state=33) # 将数据进行分割 vec = DictVectorizer(sparse=False) X_train = vec.fit_transform(X_train.to_dict(orient='record')) #对训练数据的特征进行提取 X_test = vec.transform(X_test.to_dict(orient='record')) #对测试数据的特征进行提取 #转换特征后,凡是类别型型的特征都单独独成剥离出来,独成一列特征,数值型的则不变 print (vec.feature_names_) #['age', 'pclass=1st', 'pclass=2nd', 'pclass=3rd', 'sex=female', 'sex=male'] #3.使用决策树对测试数据进行类别预测 dtc = DecisionTreeClassifier() dtc.fit(X_train,y_train) y_predict = dtc.predict(X_test) #4.获取结果报告 print ('Accracy:',dtc.score(X_test,y_test)) print (classification_report(y_predict,y_test,target_names=['died','servived'])) #5.将生成的决策树保存 with open("jueceshu.dot", 'w') as f: f = tree.export_graphviz(dtc, out_file = f)
执行结果:
C:\Anaconda3\python.exe "C:\Program Files\JetBrains\PyCharm 2019.1.1\helpers\pydev\pydevconsole.py" --mode=client --port=55077 import sys; print('Python %s on %s' % (sys.version, sys.platform)) sys.path.extend(['C:\\app\\PycharmProjects', 'C:/app/PycharmProjects']) Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] Type 'copyright', 'credits' or 'license' for more information IPython 7.12.0 -- An enhanced Interactive Python. Type '?' for help. PyDev console: using IPython 7.12.0 Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] on win32 runfile('C:/app/PycharmProjects/ArtificialIntelligence/classification.py', wdir='C:/app/PycharmProjects/ArtificialIntelligence') (1313, 3) C:\Anaconda3\lib\site-packages\pandas\core\generic.py:6245: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy self._update_inplace(new_data) ['age', 'pclass=1st', 'pclass=2nd', 'pclass=3rd', 'sex=female', 'sex=male'] Accracy: 0.7811550151975684 precision recall f1-score support died 0.91 0.78 0.84 236 servived 0.58 0.80 0.67 93 accuracy 0.78 329 macro avg 0.74 0.79 0.75 329 weighted avg 0.81 0.78 0.79 329
本文来自博客园,作者:大码王,转载请注明原文链接:https://www.cnblogs.com/huanghanyu/

 posted on
posted on










【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具