
机器学习算法及代码实现–K邻近算法
1、K邻近算法
将标注好类别的训练样本映射到X(选取的特征数)维的坐标系之中,同样将测试样本映射到X维的坐标系之中,选取距离该测试样本欧氏距离(两点间距离公式)最近的k个训练样本,其中哪个训练样本类别占比最大,我们就认为它是该测试样本所属的类别。

2、算法步骤:
1)为了判断未知实例的类别,以所有已知类别的实例作为参照
2)选择参数K
3)计算未知实例与所有已知实例的距离
4)选择最近K个已知实例
5)根据少数服从多数的投票法则(majority-voting),让未知实例归类为K个最邻近样本中最多数的类别3、距离
Euclidean Distance 定义
其他距离衡量:余弦值(cos), 相关度 (correlation), 曼哈顿距离 (Manhattan distance)
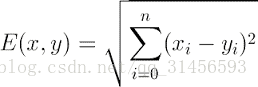
其他距离衡量:余弦值(cos), 相关度 (correlation), 曼哈顿距离 (Manhattan distance)
4、例子
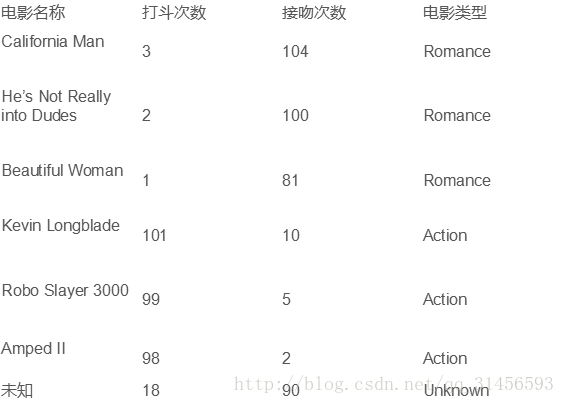
将其映射到2维空间
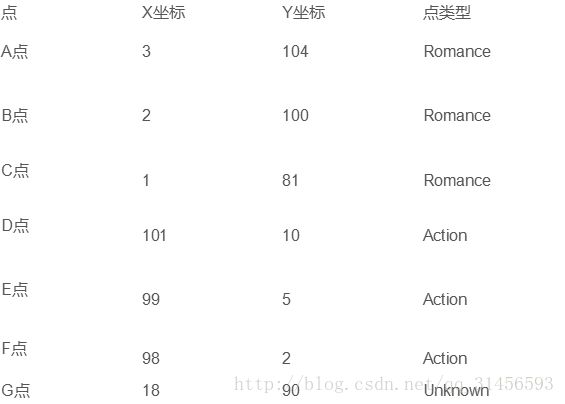
求距G点最近的k点中哪一类点最多,就可以预测G点类型。
5、算法优缺点:
优点
1)简单
2)易于理解
3)容易实现
4)通过对K的选择可具备丢噪音数据的健壮性
缺点
1)需要大量空间储存所有已知实例 2)算法复杂度高(需要比较所有已知实例与要分类的实例) 3) 当其样本分布不平衡时,比如其中一类样本过大(实例数量过多)占主导的时候,新的未知实例容易被归类为这个主导样本,因为这类样本实例的数量过大,但这个新的未知实例实际并木接近目标样本
6、 改进版本
考虑距离,根据距离加上权重
比如: 1/d (d: 距离)代码

# -*- coding: utf-8 -*- from sklearn import neighbors from sklearn import datasets # 调用knn分类器 knn = neighbors.KNeighborsClassifier() # 导入数据集 iris = datasets.load_iris() print iris # 训练 knn.fit(iris.data, iris.target) # 预测 predictedLabel = knn.predict([[0.1, 0.2, 0.3, 0.4]]) print 'predictedLabel:' print predictedLabel
本文来自博客园,作者:大码王,转载请注明原文链接:https://www.cnblogs.com/huanghanyu/

 posted on
posted on










【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具