
一. DataX3.0概览
DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
(这是一个单机多任务的ETL工具)

下载地址:http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
1、设计理念
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
2、当前使用现状
DataX在阿里巴巴集团内被广泛使用,承担了所有大数据的离线同步业务,并已持续稳定运行了6年之久。目前每天完成同步8w多道作业,每日传输数据量超过300TB。
此前已经开源DataX1.0版本,此次介绍为阿里云开源全新版本DataX3.0,有了更多更强大的功能和更好的使用体验。Github主页地址:https://github.com/alibaba/DataX
二、DataX3.0框架设计
DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。

-
Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
-
Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
-
Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
三. DataX3.0插件体系
DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入,目前支持数据如下图

四、DataX3.0核心架构
DataX 3.0 开源版本支持单机多线程模式完成同步作业运行,本小节按一个DataX作业生命周期的时序图,从整体架构设计非常简要说明DataX各个模块相互关系。

核心模块介绍:
-
DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
-
DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
-
切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
-
每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
-
DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
1、DataX调度流程:
举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到odps里面。 DataX的调度决策思路是:
-
DataXJob根据分库分表切分成了100个Task。
-
根据20个并发,DataX计算共需要分配4个TaskGroup。
-
4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task。
五、DataX 3.0六大核心优势
1、可靠的数据质量监控
-
完美解决数据传输个别类型失真问题 DataX旧版对于部分数据类型(比如时间戳)传输一直存在毫秒阶段等数据失真情况,新版本DataX3.0已经做到支持所有的强数据类型,每一种插件都有自己的数据类型转换策略,让数据可以完整无损的传输到目的端。
-
提供作业全链路的流量、数据量运行时监控 DataX3.0运行过程中可以将作业本身状态、数据流量、数据速度、执行进度等信息进行全面的展示,让用户可以实时了解作业状态。并可在作业执行过程中智能判断源端和目的端的速度对比情况,给予用户更多性能排查信息。
-
提供脏数据探测 在大量数据的传输过程中,必定会由于各种原因导致很多数据传输报错(比如类型转换错误),这种数据DataX认为就是脏数据。DataX目前可以实现脏数据精确过滤、识别、采集、展示,为用户提供多种的脏数据处理模式,让用户准确把控数据质量大关!
2、丰富的数据转换功能
DataX作为一个服务于大数据的ETL工具,除了提供数据快照搬迁功能之外,还提供了丰富数据转换的功能,让数据在传输过程中可以轻松完成数据脱敏,补全,过滤等数据转换功能,另外还提供了自动groovy函数,让用户自定义转换函数。详情请看DataX3的transformer详细介绍。
3、精准的速度控制
还在为同步过程对在线存储压力影响而担心吗?新版本DataX3.0提供了包括通道(并发)、记录流、字节流三种流控模式,可以随意控制你的作业速度,让你的作业在库可以承受的范围内达到最佳的同步速度。
"speed": {
"channel": 8, ----并发数限速(根据自己CPU合理控制并发数)
"byte": 524288, ----字节流限速(根据自己的磁盘和网络合理控制字节数)
"record": 10000 ----记录流限速(根据数据合理空行数)
}
4、强劲的同步性能
DataX3.0每一种读插件都有一种或多种切分策略,都能将作业合理切分成多个Task并行执行,单机多线程执行模型可以让DataX速度随并发成线性增长。在源端和目的端性能都足够的情况下,单个作业一定可以打满网卡。另外,DataX团队对所有的已经接入的插件都做了极致的性能优化,并且做了完整的性能测试。
5、健壮的容错机制
DataX作业是极易受外部因素的干扰,网络闪断、数据源不稳定等因素很容易让同步到一半的作业报错停止。因此稳定性是DataX的基本要求,在DataX 3.0的设计中,重点完善了框架和插件的稳定性。目前DataX3.0可以做到线程级别、进程级别(暂时未开放)、作业级别多层次局部/全局的重试,保证用户的作业稳定运行。 线程内部重试
DataX的核心插件都经过团队的全盘review,不同的网络交互方式都有不同的重试策略。
6、线程级别重试
目前DataX已经可以实现TaskFailover,针对于中间失败的Task,DataX框架可以做到整个Task级别的重新调度。
第二章、datax实战
0.环境
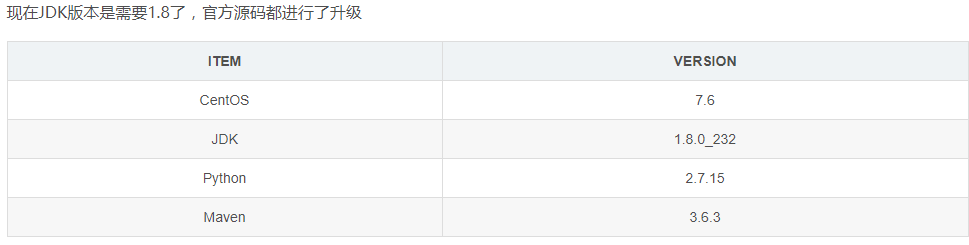
1.JDK安装配置【完美】
##### 卸载默认环境
yum -y remove java-1.8.0-openjdk*
yum -y remove tzdata-java*
# 下载安装依赖
yum install -y java-1.8.0-openjdk java-1.8.0-openjdk-devel
# 查到系统默认安装jdk的位置/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.222.b10-0.el7_6.x86_64/jre/bin/java
[root@ansible-server randolph]# ls -lrt /usr/bin/java
lrwxrwxrwx 1 root root 22 8月 23 13:42 /usr/bin/java -> /etc/alternatives/java
[root@ansible-server randolph]# ls -lrt /etc/alternatives/java
lrwxrwxrwx 1 root root 73 8月 23 13:42 /etc/alternatives/java -> /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.222.b10-0.el7_6.x86_64/jre/bin/java
# 加到环境变量
vim /etc/profile
# jdk
export JAVA_HOME=/usr/lib/jvm/java-1.8.0
export JRE_HOME=$JAVA_HOME/jre
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
source /etc/profile
# 检测
java -version
javac
2.Maven安装配置——用于编译git clone下来的源码
cd /opt/
wget https://mirrors.tuna.tsinghua.edu.cn/apache/maven/maven-3/3.6.3/binaries/apache-maven-3.6.3-bin.tar.gz
tar -zxvf apache-maven-3.6.3-bin.tar.gz
mv apache-maven-3.6.3/ maven # 改名方便操作
vim /etc/profile # 修改配置文件,并在末尾添加
# maven
M2_HOME=/opt/maven # 这里的路径注意下
export PATH=${M2_HOME}/bin:${PATH}
# 重载文件立即生效
source /etc/profile
检查maven安装是否成功
mvn -v
检查maven已经安装
[root@ansible-server opt]# mvn -v
Apache Maven 3.6.3 (cecedd343002696d0abb50b32b541b8a6ba2883f)
Maven home: /opt/maven
Java version: 1.8.0_222, vendor: Oracle Corporation, runtime: /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.222.b10-0.el7_6.x86_64/jre
Default locale: zh_CN, platform encoding: UTF-8
OS name: "linux", version: "3.10.0-957.27.2.el7.x86_64", arch: "amd64", family: "unix"
3.检查系统版本、python版本
实际上有python2/3都OK,后面datax的bin文件夹下的三个py文件datax.py也有python2/3版本,在执行命令的时候只需要对应即可。
[root@client-1 ~]# cat /etc/redhat-release
CentOS Linux release 7.6.1810 (Core)
[root@ansible-server DataX]# java -version
openjdk version "1.8.0_232"
OpenJDK Runtime Environment (build 1.8.0_232-b09)
OpenJDK 64-Bit Server VM (build 25.232-b09, mixed mode)
[root@ansible-server ~]# python -V
Python 2.7.15
[root@ansible-server ~]# python3 -V
Python 3.6.8
1.DataX安装部署
git clone https://github.com/alibaba/DataX.git
cd DataX
mvn -U clean package assembly:assembly -Dmaven.test.skip=true # maven打包
等待编译好久… 竟然编译了39分钟!!!
留个纪念:
[INFO] datax/lib/slf4j-api-1.7.10.jar already added, skipping
[INFO] datax/lib/logback-classic-1.0.13.jar already added, skipping
[INFO] datax/lib/logback-core-1.0.13.jar already added, skipping
[INFO] datax/lib/commons-math3-3.1.1.jar already added, skipping
[INFO] datax/lib/hamcrest-core-1.3.jar already added, skipping
[WARNING] Assembly file: /opt/DataX/target/datax is not a regular file (it may be a directory). It cannot be attached to the project build for installation or deployment.
[INFO] ------------------------------------------------------------------------
[INFO] Reactor Summary for datax-all 0.0.1-SNAPSHOT:
[INFO]
[INFO] datax-all .......................................... SUCCESS [03:23 min]
[INFO] datax-common ....................................... SUCCESS [ 22.458 s]
[INFO] datax-transformer .................................. SUCCESS [ 25.734 s]
[INFO] datax-core ......................................... SUCCESS [01:02 min]
[INFO] plugin-rdbms-util .................................. SUCCESS [ 20.741 s]
[INFO] mysqlreader ........................................ SUCCESS [ 1.096 s]
[INFO] drdsreader ......................................... SUCCESS [ 2.539 s]
[INFO] sqlserverreader .................................... SUCCESS [ 1.885 s]
[INFO] postgresqlreader ................................... SUCCESS [ 5.029 s]
[INFO] oraclereader ....................................... SUCCESS [ 1.047 s]
[INFO] odpsreader ......................................... SUCCESS [ 43.033 s]
[INFO] otsreader .......................................... SUCCESS [ 31.965 s]
[INFO] otsstreamreader .................................... SUCCESS [ 16.498 s]
[INFO] plugin-unstructured-storage-util ................... SUCCESS [03:08 min]
[INFO] txtfilereader ...................................... SUCCESS [ 5.172 s]
[INFO] hdfsreader ......................................... SUCCESS [06:13 min]
[INFO] streamreader ....................................... SUCCESS [ 1.028 s]
[INFO] ossreader .......................................... SUCCESS [ 12.157 s]
[INFO] ftpreader .......................................... SUCCESS [ 6.172 s]
[INFO] mongodbreader ...................................... SUCCESS [ 9.056 s]
[INFO] rdbmsreader ........................................ SUCCESS [ 1.186 s]
[INFO] hbase11xreader ..................................... SUCCESS [04:06 min]
[INFO] hbase094xreader .................................... SUCCESS [02:57 min]
[INFO] tsdbreader ......................................... SUCCESS [ 7.664 s]
[INFO] opentsdbreader ..................................... SUCCESS [02:45 min]
[INFO] cassandrareader .................................... SUCCESS [ 35.874 s]
[INFO] mysqlwriter ........................................ SUCCESS [ 0.861 s]
[INFO] drdswriter ......................................... SUCCESS [ 1.111 s]
[INFO] odpswriter ......................................... SUCCESS [ 1.895 s]
[INFO] txtfilewriter ...................................... SUCCESS [ 3.672 s]
[INFO] ftpwriter .......................................... SUCCESS [ 3.045 s]
[INFO] hdfswriter ......................................... SUCCESS [ 6.932 s]
[INFO] streamwriter ....................................... SUCCESS [ 0.863 s]
[INFO] otswriter .......................................... SUCCESS [ 1.609 s]
[INFO] oraclewriter ....................................... SUCCESS [ 1.247 s]
[INFO] sqlserverwriter .................................... SUCCESS [ 0.855 s]
[INFO] postgresqlwriter ................................... SUCCESS [ 1.073 s]
[INFO] osswriter .......................................... SUCCESS [ 3.064 s]
[INFO] mongodbwriter ...................................... SUCCESS [ 3.227 s]
[INFO] adswriter .......................................... SUCCESS [ 20.076 s]
[INFO] ocswriter .......................................... SUCCESS [ 37.687 s]
[INFO] rdbmswriter ........................................ SUCCESS [ 1.196 s]
[INFO] hbase11xwriter ..................................... SUCCESS [ 6.453 s]
[INFO] hbase094xwriter .................................... SUCCESS [ 4.315 s]
[INFO] hbase11xsqlwriter .................................. SUCCESS [03:24 min]
[INFO] hbase11xsqlreader .................................. SUCCESS [02:09 min]
[INFO] elasticsearchwriter ................................ SUCCESS [ 21.244 s]
[INFO] tsdbwriter ......................................... SUCCESS [ 1.477 s]
[INFO] adbpgwriter ........................................ SUCCESS [ 24.980 s]
[INFO] gdbwriter .......................................... SUCCESS [01:30 min]
[INFO] cassandrawriter .................................... SUCCESS [ 5.859 s]
[INFO] hbase20xsqlreader .................................. SUCCESS [02:00 min]
[INFO] hbase20xsqlwriter .................................. SUCCESS [ 1.659 s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 39:28 min
[INFO] Finished at: 2019-12-12T14:39:51+08:00
[INFO] ------------------------------------------------------------------------
[root@ansible-server DataX]#
4.DataX使用/踩坑
1.配置一个简单例子
做什么好呢,正好手上有三个虚机absible-server client-1 client-2; 我们将absible-server mysql数据库test.user同步到client-1数据库test.user吧;
配置的任务是json格式的,我们假设任务的配置文件叫做mysql2mysql.json 需要用datax.py执行,看一眼datax.py就知道项目是python2的; mysql2mysql.json位置在上一层目录job文件夹下存放;
1.如何跑任务呢:
python /opt/DataX/target/datax/datax/bin/datax.py /opt/DataX/target/datax/datax/job/mysql2mysql.json
成功的话会是这样的:

但是我相信你需要仔细看一下任务的json文件该如何去配置
2.配置文件格式说明:
可以看到job分为reader和writer两部分,正体现了datax的架构特征: 阿里云开源离线同步工具DataX3.0介绍

部分参数说明:
jdbcUrl jdbc:mysql://127.0.0.1:3306/test?characterEncoding=utf8 里面需要配置源IP/目标IP:数据库端口/数据库名?characterEncoding=utf8 控制编码格式,防止写入中文出现错误 username 这个用户,需要在数据库中创建,并赋予其增删改查等权限 创建的可以用来读取主库/修改从库的用户,我直接使用的root用户,并且后面试错后给root用户【允许所有远程机器访问】的权限 参考MySQL用户授权(GRANT) /opt/DataX/target/datax/datax/job/mysql2mysql.json :
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"id",
"name"
],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://127.0.0.1:3306/test?characterEncoding=utf8"],
"table": ["user"]
}
],
"password": "asdf",
"username": "root"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [
"id",
"name"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://192.168.255.134:3306/test?characterEncoding=utf8",
"table": ["user"]
}
],
"password": "asdf",
"username": "root"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
上面的文件配置完,就可以用datax.py跑这个json文件了,当然,我第一次跑,遇到了几处错误
3.跑任务出错与测试
1.Host ‘ansible-server’ is not allowed to connect to this MySQL server 原因:mysql服务器出于安全考虑,默认只允许本地登录数据库服务器 因此主服务器133不能用root访问从服务器数据库:
[root@ansible-server job]# mysql -h192.168.255.134 -uroot -p
Enter password:
ERROR 1130 (HY000): Host '192.168.255.133' is not allowed to connect to this MySQL server
从服务器将mysql的root用户的host从"localhost"改成"%",允许所有远程端访问: 主服务器的root用户也作同样修改,进入mysql库,看下root的host,然后改成%,确认下:
mysql> use mysql;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> select host, user from user;
+-----------+---------------+
| host | user |
+-----------+---------------+
| localhost | mysql.session |
| localhost | mysql.sys |
| localhost | root |
+-----------+---------------+
3 rows in set (0.28 sec)
mysql> update user set host = '%' where user = 'root';
Query OK, 1 row affected (0.59 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> flush privileges;
Query OK, 0 rows affected (0.14 sec)
mysql> select host, user from user;
+-----------+---------------+
| host | user |
+-----------+---------------+
| % | root |
| localhost | mysql.session |
| localhost | mysql.sys |
+-----------+---------------+
3 rows in set (0.00 sec)
2.跑同步任务成功【但中文插入错误】
检查下有没有将主库的test.user表同步到从库134的test.user表: 出现了错误,将中文数据显示错误,jdbcurl末尾加上?characterEncoding=utf8 主库test.user表插入一条数据:

[root@ansible-server job]# python /opt/DataX/target/datax/datax/bin/datax.py /opt/DataX/target/datax/datax/job/mysql2mysql.json
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
2019-12-12 17:04:18.115 [main] INFO VMInfo - VMInfo# operatingSystem class => sun.management.OperatingSystemImpl
2019-12-12 17:04:18.122 [main] INFO Engine - the machine info =>
osInfo: Oracle Corporation 1.8 25.232-b09
jvmInfo: Linux amd64 3.10.0-957.27.2.el7.x86_64
cpu num: 4
totalPhysicalMemory: -0.00G
freePhysicalMemory: -0.00G
maxFileDescriptorCount: -1
currentOpenFileDescriptorCount: -1
GC Names [PS MarkSweep, PS Scavenge]
MEMORY_NAME | allocation_size | init_size
PS Eden Space | 256.00MB | 256.00MB
Code Cache | 240.00MB | 2.44MB
Compressed Class Space | 1,024.00MB | 0.00MB
PS Survivor Space | 42.50MB | 42.50MB
PS Old Gen | 683.00MB | 683.00MB
Metaspace | -0.00MB | 0.00MB
2019-12-12 17:04:18.143 [main] INFO Engine -
{
"content":[
{
"reader":{
"name":"mysqlreader",
"parameter":{
"column":[
"id",
"name"
],
"connection":[
{
"jdbcUrl":[
"jdbc:mysql://127.0.0.1:3306/test"
],
"table":[
"user"
]
}
],
"password":"****",