
一、什么是canal
canal是纯Java开发。基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了MySQL
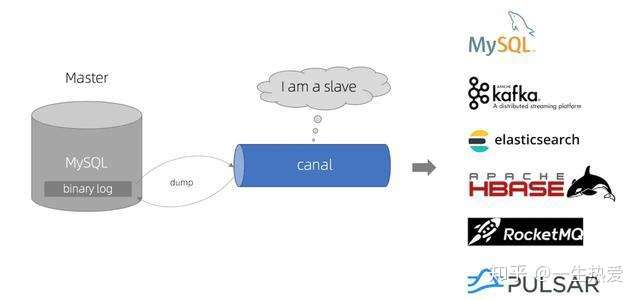
如上图:canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
二、canal 搭建
1、搭建mysql环境
-
对于自建 MySQL , 需要先开启 Binlog 写入功能,配置 binlog-format 为 ROW 模式,my.cnf 中配置如下
[mysqld]
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复
-
授权 canal 链接 MySQL 账号具有作为 MySQL slave 的权限, 如果已有账户可直接 grant
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
FLUSH PRIVILEGES;
这个第一步还是蛮简单的,就是要自己搭建一个mysql,修改一下mysql的配置,这个配置一般是再/etc/my.cnf中,还是得要点小基础的哈,至少mysql得会搭
2、搭建canal环境
-
下载 canal, 访问 release 页面 , 选择需要的包下载, 如以 1.0.17 版本为例
wget https://github.com/alibaba/canal/releases/download/canal-1.0.17/canal.deployer-1.0.17.tar.gz
-
解压缩
mkdir /tmp/canal
tar zxvf canal.deployer-$version.tar.gz -C /tmp/canal
解压完成后,进入 /tmp/canal 目录,可以看到如下结构

-
配置修改
vi conf/example/instance.properties
#################################################
## mysql serverId , v1.0.26+ will autoGen
canal.instance.mysql.slaveId=8
# enable gtid use true/false
canal.instance.gtidon=false
# position info 需要改成自己的数据库信息
canal.instance.master.address=10.0.98.186:3306
canal.instance.master.journal.name=
canal.instance.master.position=
canal.instance.master.timestamp=
canal.instance.master.gtid=
# rds oss binlog
canal.instance.rds.accesskey=
canal.instance.rds.secretkey=
canal.instance.rds.instanceId=
# table meta tsdb info
canal.instance.tsdb.enable=true
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb
#canal.instance.tsdb.dbUsername=canal
#canal.instance.tsdb.dbPassword=canal
#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#canal.instance.standby.gtid=
# username/password 需要改成自己的数据库信息
canal.instance.dbUsername=root
canal.instance.dbPassword=root
canal.instance.connectionCharset=UTF-8
canal.instance.defaultDatabaseName=expert-online-school
# table regex
canal.instance.filter.regex=.*\\..*
# table black regex
canal.instance.filter.black.regex=
#################################################
注意: canal.instance.connectionCharset 代表数据库的编码方式对应到 java 中的编码类型,比如 UTF-8,GBK , ISO-8859-1 如果系统是1个 cpu,需要将 canal.instance.parser.parallel 设置为 false
-
启动
sh bin/startup.sh
到目前为止 canal的服务端我们已经搭建好了 但是到目前 我们只是把数据库的binlog 拉到canal中,我们还得把数据用otter去消费
三、写个简单的Demo 去监听mysql 数据的变动
1、Jar包
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.3</version>
</dependency>
四、测试代码
package com.hq.eos.sync.client;
import java.net.InetSocketAddress;
import java.util.List;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry.Column;
import com.alibaba.otter.canal.protocol.CanalEntry.Entry;
import com.alibaba.otter.canal.protocol.CanalEntry.EntryType;
import com.alibaba.otter.canal.protocol.CanalEntry.EventType;
import com.alibaba.otter.canal.protocol.CanalEntry.RowChange;
import com.alibaba.otter.canal.protocol.CanalEntry.RowData;
import com.alibaba.otter.canal.protocol.Message;
public class CanalTest {
public static void main(String[] args) throws Exception {
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("10.0.98.186", 11111), "expert", "root", "root");
connector.connect();
connector.subscribe(".*\\..*");
connector.rollback();
while (true) {
Message message = connector.getWithoutAck(100); // 获取指定数量的数据
long batchId = message.getId();
if (batchId == -1 || message.getEntries().isEmpty()) {
Thread.sleep(1000);
continue;
}
// System.out.println(message.getEntries());
printEntries(message.getEntries());
connector.ack(batchId);// 提交确认,消费成功,通知server删除数据
// connector.rollback(batchId);// 处理失败, 回滚数据,后续重新获取数据
}
}
private static void printEntries(List<Entry> entries) throws Exception {
for (Entry entry : entries) {
if (entry.getEntryType() != EntryType.ROWDATA) {
continue;
}
RowChange rowChange = RowChange.parseFrom(entry.getStoreValue());
EventType eventType = rowChange.getEventType();