
Alluxio介绍使用
一、Alluxio概述
Alluxio(前身Tachyon)是世界上第一个以内存为中心的虚拟的分布式存储系统。它统一了数据访问的方式,为上层计算框架和底层存储系统构建了桥梁。
Alluxio项目源自加州大学伯克利分校AMPLab,作为伯克利数据分析堆栈(BDAS)的数据访问层。Alluxio是增长最快的开源项目之一,吸引了来自300多家机构的1000多名贡献者,包括阿里巴巴,Alluxio,百度,CMU,谷歌,IBM,英特尔,NJU,红帽,腾讯,加州大学伯克利分校,以及雅虎。
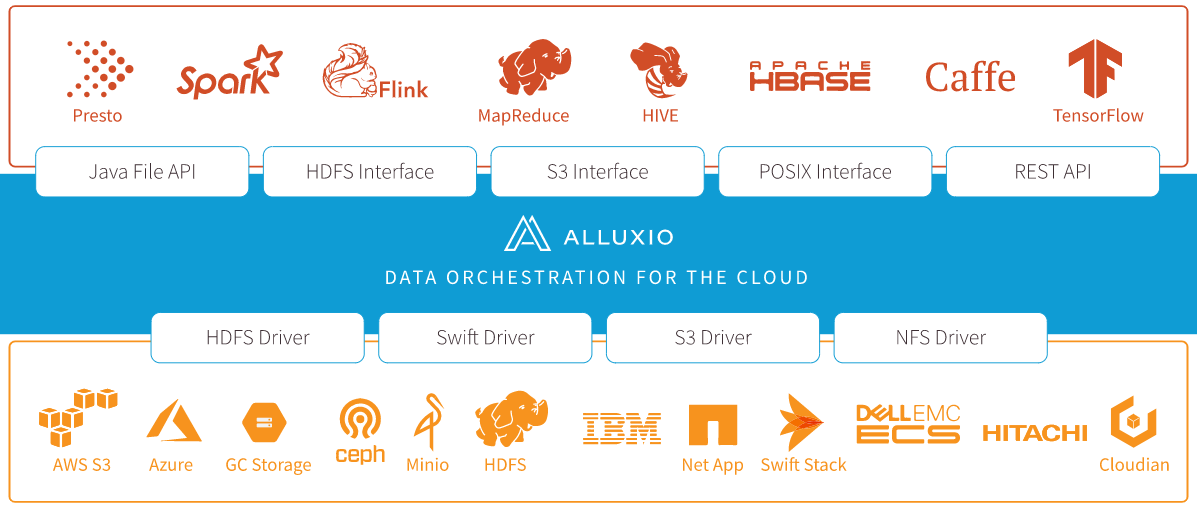
二、优势
通过简化应用程序访问其数据的方式(无论数据是什么格式或位置),Alluxio 能够帮助克服从数据中提取信息所面临的困难。Alluxio 的优势包括:
-
内存速度 I/O:Alluxio 能够用作分布式共享缓存服务,这样与 Alluxio 通信的计算应用程序可以透明地缓存频繁访问的数据(尤其是从远程位置),以提供内存级 I/O 吞吐率。此外,Alluxio的层次化存储机制能够充分利用内存、固态硬盘或者磁盘,降低具有弹性扩张特性的数据驱动型应用的成本开销。
-
简化云存储和对象存储接入:与传统文件系统相比,云存储系统和对象存储系统使用不同的语义,这些语义对性能的影响也不同于传统文件系统。在云存储和对象存储系统上进行常见的文件系统操作(如列出目录和重命名)通常会导致显著的性能开销。当访问云存储中的数据时,应用程序没有节点级数据本地性或跨应用程序缓存。将 Alluxio 与云存储或对象存储一起部署可以缓解这些问题,因为这样将从 Alluxio 中检索读取数据,而不是从底层云存储或对象存储中检索读取。
-
简化数据管理:Alluxio 提供对多数据源的单点访问。除了连接不同类型的数据源之外,Alluxio 还允许用户同时连接同一存储系统的不同版本,如多个版本的 HDFS,并且无需复杂的系统配置和管理。
-
应用程序部署简易:Alluxio 管理应用程序和文件或对象存储之间的通信,将应用程序的数据访问请求转换为底层存储接口的请求。Alluxio 与 Hadoop 生态系统兼容,现有的数据分析应用程序,如 Spark 和 MapReduce 程序,无需更改任何代码就能在 Alluxio 上运行
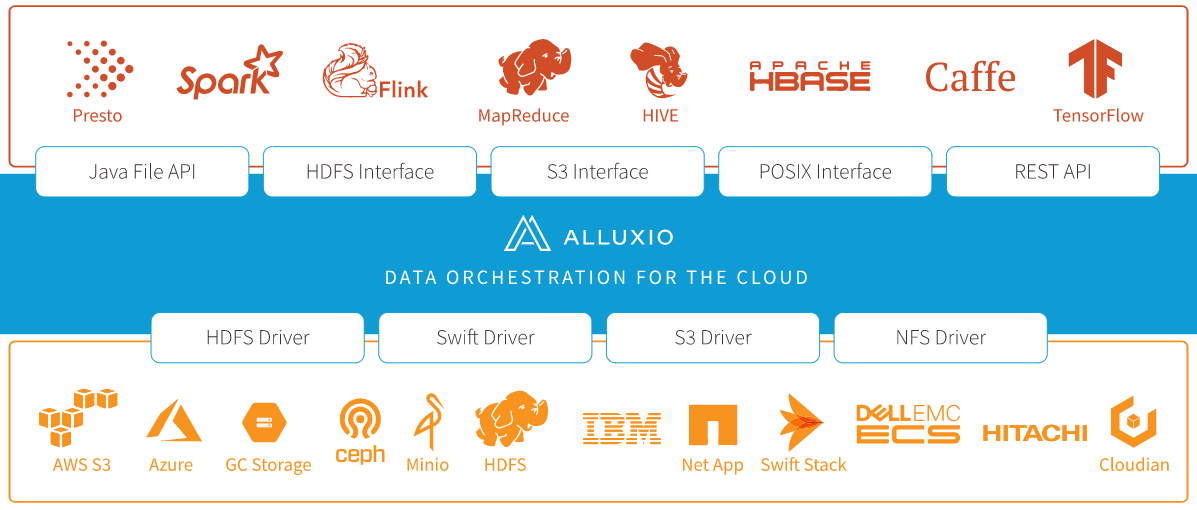
三、Alluxio架构
Alluxio是大数据和机器学习生态系统中的新数据访问层。Alluxio作为据访问层处于持久存储层(如Amazon S3,Microsoft Azure Object Store,Apache HDFS或OpenStack Swift)和计算框架层(如Apache Spark,Presto或Hadoop MapReduce)之间。
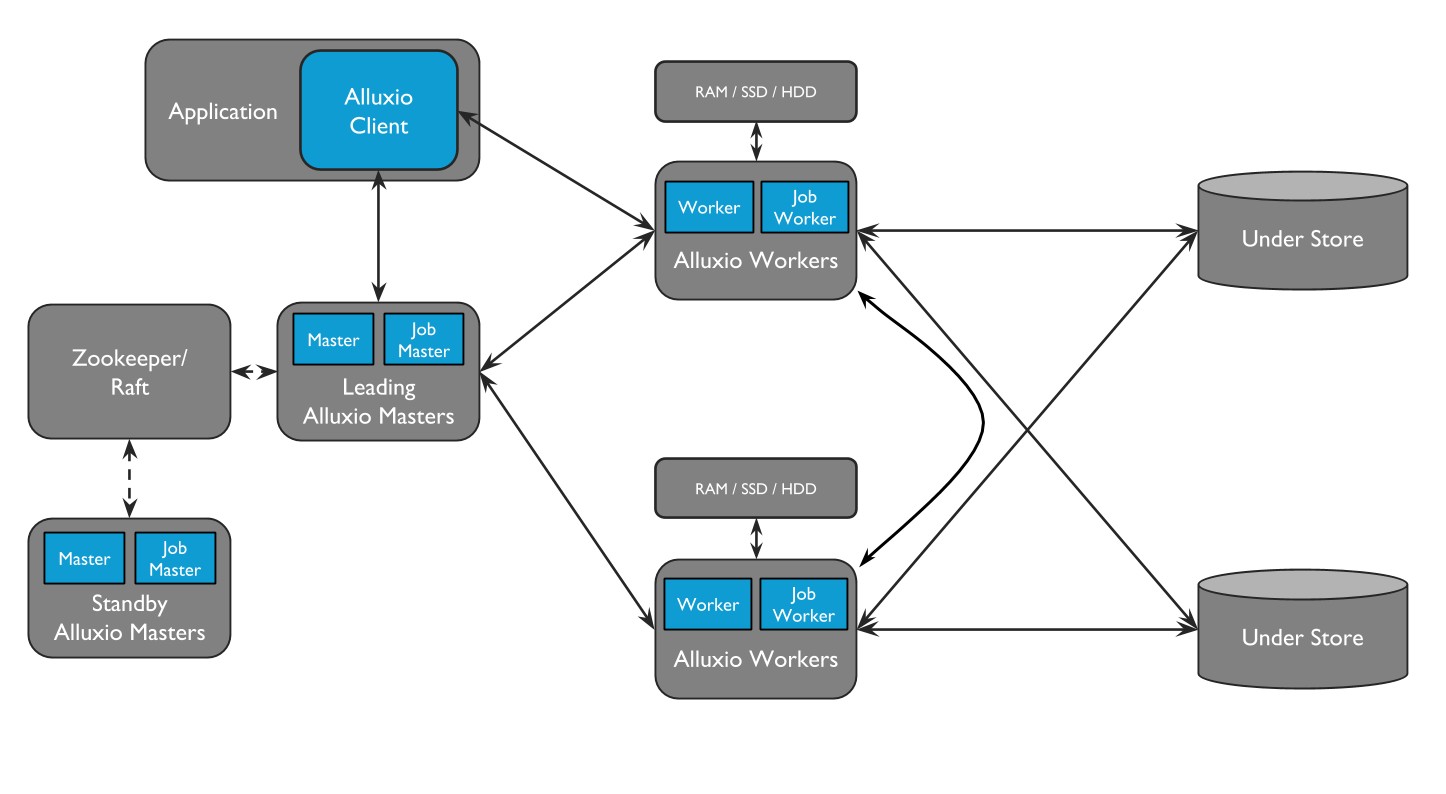
Alluxio主要包括3个角色:masters, workers, 和clients。典型的集群是由主备masters,主备job master,workers和job workers组成。
Job Masters和Job Workers可以作为单独的功能,即Job Service。Job Service是一个轻量级的任务调度框架,负责为Job Worker分配各种不同类型的操作。
- 将UFS的数据加载到Alluxio
- 数据保留到UFS
- 复制Alluxio中的文件
- UFS/Alluxio之间移动或复制数据
Ⅰ).Masters
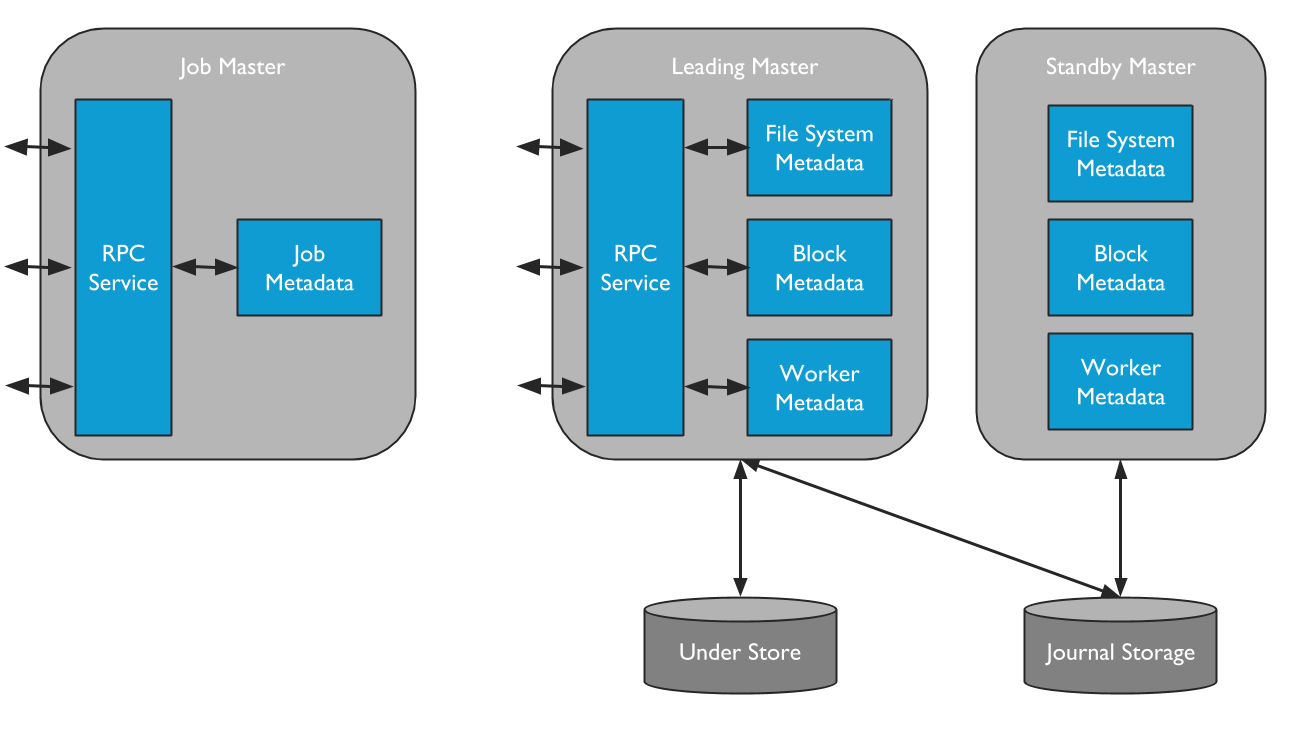
Alluxio包括2类主进程:
- Master: 为元数据的变更(用户请求和日志文件系统)提供服务
- Job Master: 做为轻便的调度器,对执行在Job Master上的文件操作提供调度
HA集群角色
a).Leading Master
Alluxio集群只能由一个Leading Master进程,Leading Master负责管理系统的全局元数据。包括file system metadata、block metadata 和 worker capacity metadata,Alluxio客户端通过与Leading Master交互来读取或修改元数据。所有的Workers定时向Leading Master发送心跳信息,Leading Master会记录所有的文件操作到日志中
b).Standby Master
Standby Master在运行在与Leading Master不同的服务器上,以便在HA模式下运行Alluxio时提供容错功能。Standby Master会及时同步读取Leading Master的日志。
c).Secondary Master
Alluxio不是HA模式时,可以在Leading Master服务器上启动Secondary Master来编写journals检查点。当Leading Master无法工作时,提供快速服务恢复;但Secondary Master永远不能能做为Standby Master。
d).Job Master
Job Master是一个独立的进程,负责在Alluxio中异步处理一些更重量级的文件系统的操作。
Ⅱ).Workers
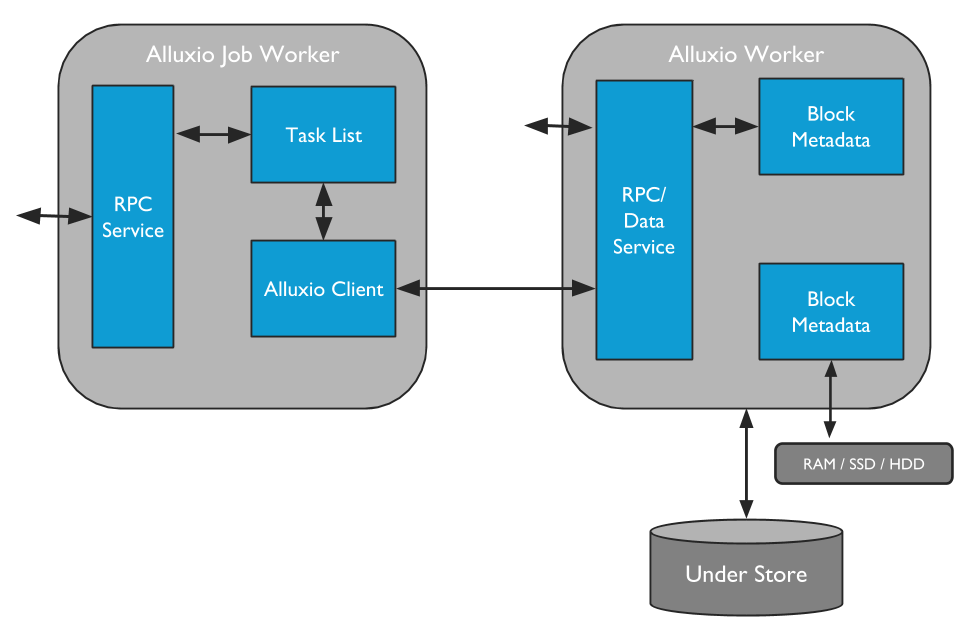
1.Alluxio Workers
Workers负责管理分配用户可配置的本地资源(例如内存,SSD,HDD)。Alluxio workers 通过 在其本地资源创建新的blocks存储或读取blocks来响应client的读写数据请求。Workers 只负责管理blocks,实际的映射关系( files to blocks )只存储在master。
2.Alluxio Job Workers
Job Workers做为Alluxio文件系统的客户端,负责执行Job Master分配他的任务。
Ⅲ).Client
Alluxio client为用户提供了与Alluxio servers交互的网关。Client和Leading Master交互操作元数据信息,再向workers交互读写请求。
注意Alluxio clients 不能直接访问底层存储系统,数据是通过Alluxio workers被转换传递的。
四、安装部署
1.前期准备
需要:
Mac OS X 或 Linux
安装 SSH (Mac OS X)
如果你使用 Mac OS X,你必须能够 ssh 到 localhost。远程登录开启方法:打开系统偏好设置,然后打开共享,确保远程登录已开启。
2.下载 Alluxio
从这里下载 Alluxio。
$ tar -xzf alluxio-2.7.3-bin.tar.gz $ cd alluxio-2.7.3
这会创建一个包含所有的 Alluxio 源文件和 Java 二进制文件的文件夹alluxio-2.7.3。在本教程中,这个文件夹的路径将被引用为${ALLUXIO_HOME}。
3.配置 Alluxio
在${ALLUXIO_HOME}/conf目录下,根据模板文件创建conf/alluxio-site.properties配置文件。
$ cp conf/alluxio-site.properties.template conf/alluxio-site.properties 在conf/alluxio-site.properties文件中修改 alluxio.master.hostname,默认是本地文件系统。
关于挂载特定版本hdfs请参考https://docs.alluxio.io/os/user/stable/cn/ufs/HDFS.html,下文也有挂载hdfs介绍。
alluxio.master.hostname=localhost
4.验证 Alluxio 运行环境
在启动 Alluxio 前,要保证当前系统环境下 Alluxio 可以正常运行。可以通过运行如下命令来验证 Alluxio 的本地运行环境:
$ ./bin/alluxio validateEnv local该命令将汇报在本地环境运行 Alluxio 可能出现的问题。
你可以在这里查看更多关于validateEnv命令的信息。
5.启动 Alluxio
在启动 Alluxio 进程前,需要进行格式化。如下命令会格式化 Alluxio 的日志和 worker 存储目录。
$ ./bin/alluxio format默认配置下,本地运行 Alluxio 会启动一个 master 和一个 worker。我们可以用如下命令在 localhost 启动 Alluxio:
$ ./bin/alluxio-start.sh local SudoMount
![]()
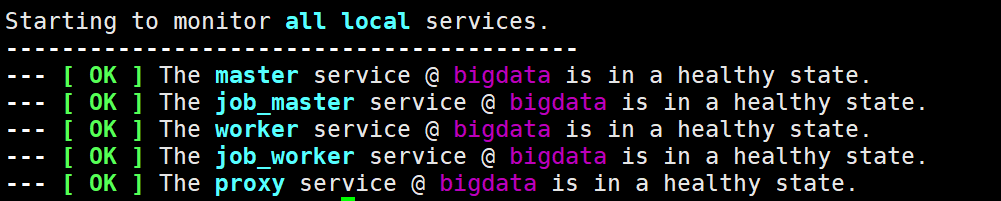
可以访问 http://localhost:19999 查看 Alluxio master 的运行状态
访问 http://localhost:30000 查看 Alluxio worker 的运行状态

6.使用 Alluxio Shell
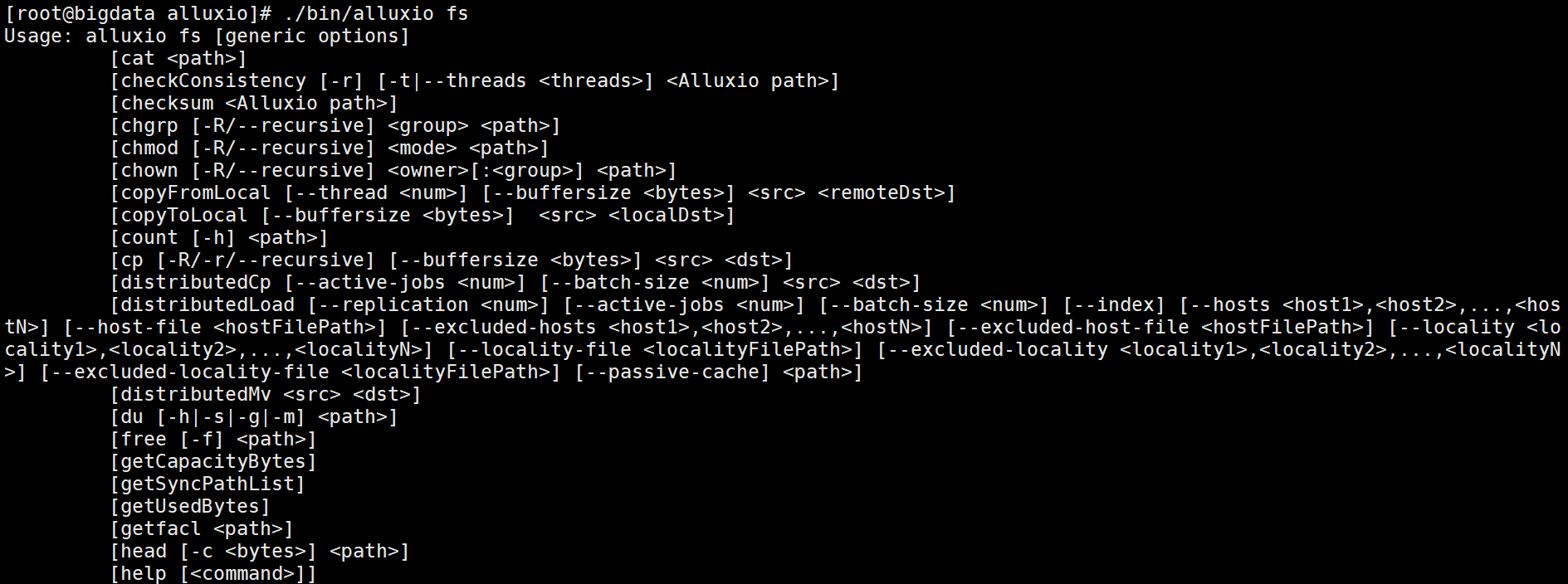
Alluxio shell 包含多种与 Alluxio 交互的命令行操作。如果要查看文件系统操作命令列表,运行:
$ ./bin/alluxio fs
![]()
通过ls命令列出 Alluxio 里的文件。比如列出根目录下所有文件:
$ ./bin/alluxio fs ls /
目前 Alluxio 里没有文件。copyFromLocal命令可以拷贝本地文件到 Alluxio 中。
$ ./bin/alluxio fs copyFromLocal LICENSE /LICENSE
Copied LICENSE to /LICENSE 再次列出 Alluxio 里的文件,可以看到刚刚拷贝的LICENSE文件:
$ ./bin/alluxio fs ls /
![]()

输出显示 LICENSE 文件在 Alluxio 中,也包含一些其他的有用信息,比如文件的大小、创建的日期、文件的所有者和组以及 Alluxio 中这个文件的缓存占比。
cat命令可以打印文件的内容。
$ ./bin/alluxio fs cat /LICENSE
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
... 默认设置中,Alluxio 使用本地文件系统作为底层文件系统 (UFS)。默认的 UFS 路径是./underFSStorage。我们可以查看 UFS 中的内容:
$ ls ./underFSStorage/然而,这个目录不存在!这是由于 Alluxio 默认只写入数据到 Alluxio 存储空间,而不会写入 UFS。
但是,我们可以告诉 Alluxio 将文件从 Alluxio 空间持久化到 UFS。shell 命令persist可以做到。
$ ./bin/alluxio fs persist /LICENSE
persisted file /LICENSE with size 26847如果我们现在再次检查 UFS,文件就会出现。
$ ls ./underFSStorage
![]()

如果我们在 master webUI 中浏览 Alluxio 文件系统,我们可以看见 LICENSE 文件以及其它有用的信息。其中,Persistence State 栏显示文件为 PERSISTED

free命令
将文件从释放中释放,前提是这个文件已经持久化到UFS了,不然是没办法释放的
./bin/alluxio fs free /LICENSE

七、Alluxio 中的挂载功能
Alluxio 通过统一命名空间的特性统一了对存储系统的访问。你可以阅读统一命名空间的博客和统一命名空间文档获取更详细的解释。
这个特性允许用户挂载不同的存储系统到 Alluxio 命名空间中并且通过 Alluxio 命名空间无缝地跨存储系统访问文件。
首先,我们在 Alluxio 中创建一个目录作为挂载点。
$ ./bin/alluxio fs mkdir /mnt
Successfully created directory /mnt
挂载hdfs 到 Alluxio
./bin/alluxio fs mount --shared alluxio://localhost:19998/mnt/hdfs hdfs://bigdata:9000/
![]()

我们可以通过 Alluxio 命名空间列出 hdfs中的文件

新挂载的文件和目录也可以在 Alluxio web UI 中看到
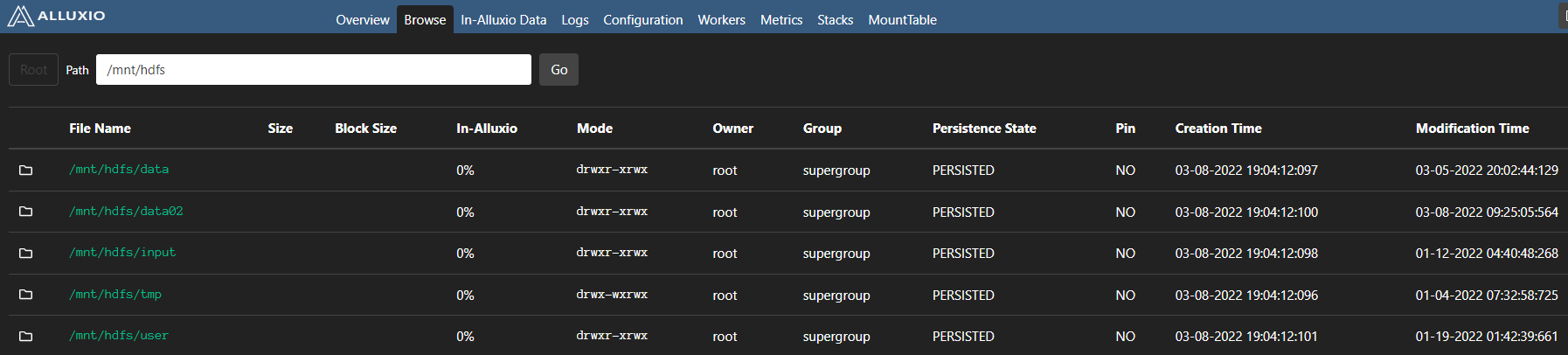
修改删除hdfs文件
原文件

执行删除命令
./bin/alluxio fs rm /mnt/hdfs/data/google.com/google.com190912.bz2

参考hdfs文件结果

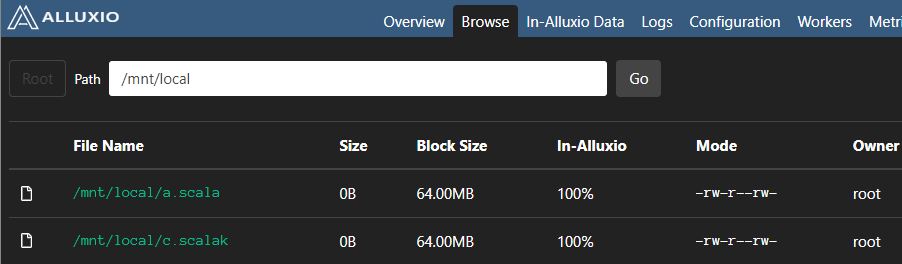
挂载local
./bin/alluxio fs mount --shared alluxio://localhost:19998/mnt/local /root/data/1
![]()

linux本地文件情况

alluxio挂载后
如果在底层文件系统操作挂载的目录,alluxion无法感知,通过alluxion操作挂载的目录对应的文件等,底层文件系统也会相应改变。
例子说明:
linux上cp wc.txt到 1/目录下
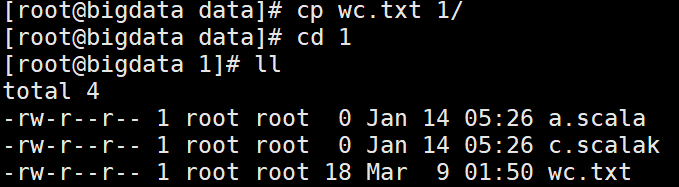
alluxion是没有wc.txt的
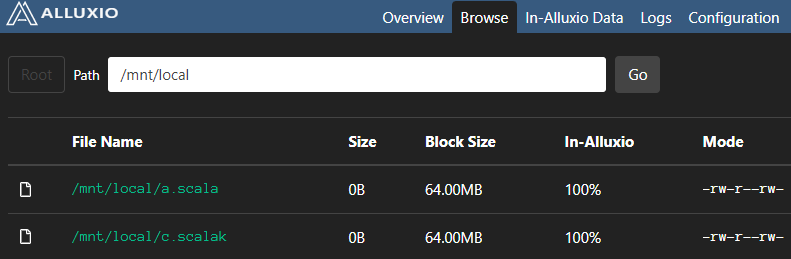
通过alluxion创建/mnt/local/new.scala文件

可以看到本地和alluxion都创建了new.scala文件
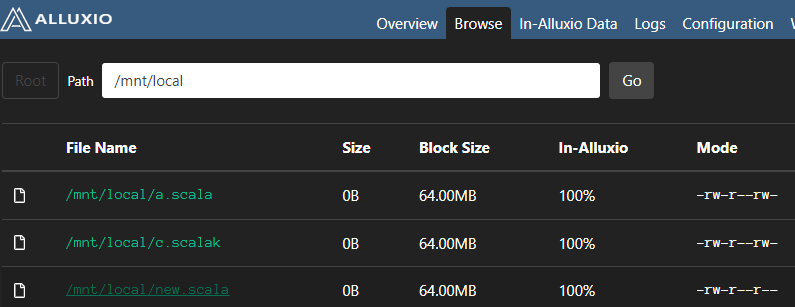
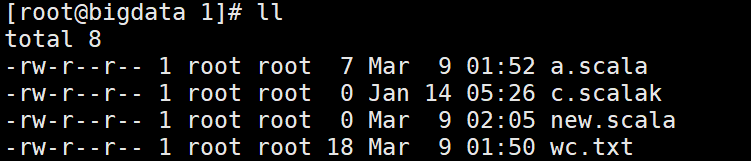
总结:如果使用了alluxion管理各种文件系统,那么对挂载的文件系统读写操作都通过alluxion操作是比较合理的。
八、在Alluxio上运行Hadoop MapReduce
1.Alluxio客户端
为了使MapReduce应用可以与Alluxio进行通信,需要将Alluxio Client的Jar包包含在MapReduce的classpaths中
Alluxio客户端Jar包可以在/<PATH_TO_ALLUXIO>/client/alluxio-2.7.3-client.jar中发现。
2.配置Hadoop
将以下两个属性添加到Hadoop的安装目录下的core-site.xml文件中:
<property>
<name>fs.alluxio.impl</name>
<value>alluxio.hadoop.FileSystem</value>
<description>The Alluxio FileSystem (Hadoop 1.x and 2.x)</description>
</property>
<property>
<name>fs.AbstractFileSystem.alluxio.impl</name>
<value>alluxio.hadoop.AlluxioFileSystem</value>
<description>The Alluxio AbstractFileSystem (Hadoop 2.x)</description>
</property>该配置让MapReduce作用在输入和输出文件中通过Alluxio scheme alluxio:// 来识别URIs。
其次, 在conf目录中hadoop-env.sh文件中修改$HADOOP_CLASSPATH:
$ export HADOOP_CLASSPATH=/<PATH_TO_ALLUXIO>/client/alluxio-2.7.3-client.jar:${HADOOP_CLASSPATH}该配置确保Alluxio客户端jar包是利用的,对于通过Alluxio的URIs来创建和提交作业进行交互的MapReduce作业客户端。
3.分发Alluxio客户端Jar包
为了让MapRedude应用在Alluxio上读写文件,Alluxio客户端Jar包必须被分发到不同节点的应用相应的classpaths中。
如何从Cloudera上加入第三方库这篇文档介绍了分发Jar包的多种方式。文档中建议通过使用命令行的-libjars选项,使用分布式缓存来分发Alluxio客户端Jar包。另一种分发客户端Jar包的方式就是手动将其分发到Hadoop节点上。下面就是这两种主流方法的介绍:
1.使用-libjars命令行选项
你可以在使用hadoop jar ...的时候加入-libjars命令行选项,指定/<PATH_TO_ALLUXIO>/client/alluxio-2.7.3-client.jar为-libjars的参数。这条命令会把该Jar包放到Hadoop的DistributedCache中,使所有节点都可以访问到。例如,下面的命令就是将Alluxio客户端Jar包添加到-libjars选项中。
$ ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount \
-libjars /<PATH_TO_ALLUXIO>/client/alluxio-2.7.3-client.jar <INPUT FILES> <OUTPUT DIRECTORY>有时候,你还需要设置环境变量HADOOP_CLASSPATH,让Alluxio客户端在运行hadoop jar命令时创建的客户端JVM可以使用jar包:
$ export HADOOP_CLASSPATH=/<PATH_TO_ALLUXIO>/client/alluxio-2.7.3-client.jar:${HADOOP_CLASSPATH}2.手动将Client Jar包分发到所有节点
为了在每个节点安装Alluxio,将客户端jar包/<PATH_TO_ALLUXIO>/client/alluxio-2.7.3-client.jar置于每个MapReduce节点的$HADOOP_HOME/lib(由于版本不同也可能是$HADOOP_HOME/share/hadoop/common/lib),然后重新启动Hadoop。 另一种选择,在你的Hadoop部署中,把这个jar包添加到mapreduce.application.classpath系统属性,确保jar包在classpath上。 为了在每个节点上安装Alluxio,将客户端Jar包mapreduce.application.classpath,该方法要注意的是所有Jar包必须再次安装,因为每个Jar包都更新到了最新版本。另一方面,当该Jar包已经在每个节点上的时候,就没有必要使用-libjars命令行选项了。
4.在本地模式的Alluxio上运行Hadoop wordcount
重启hadoop集群
你可以在Alluxio中加入两个简单的文件来运行wordcount。在你的Alluxio目录中运行:
$ ./bin/alluxio fs copyFromLocal LICENSE /wordcount/input.txt该命令将LICENSE文件复制到Alluxio的文件命名空间中,并指定其路径为/wordcount/input.txt。
现在我们运行一个用于wordcount的MapReduce作业。
$ ./bin/hadoop jar /root/app/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar wordcount \
-libjars /root/app/alluxio/client/alluxio-2.7.3-client.jar \
alluxio://localhost:19998/wordcount/input.txt \
alluxio://localhost:19998/wordcount/output作业完成后,wordcount的结果将存在Alluxio的/wordcount/output目录下。可以通过运行如下命令来查看结果文件:
$ ./bin/alluxio fs ls /wordcount/output
$ ./bin/alluxio fs cat /wordcount/output/part-r-00000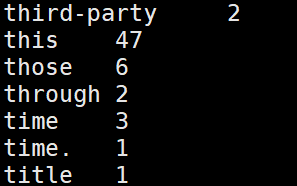
九、Apache Spark 使用 Alluxio
1.基础设置
1)将 Alluxio客户端 jar 包分发在运行 Spark driver 或 executor 的节点上。具体地说,将客户端 jar 包放在每个节点上的同一本地路径(例如/<PATH_TO_ALLUXIO>/client/alluxio-2.7.3-client.jar)。
2)将 Alluxio 客户端 jar 包添加到 Spark driver 和 executor 的 classpath 中,以便 Spark 应用程序能够使用客户端 jar 包在 Alluxio 中读取和写入文件。具体来说,在运行 Spark 的每个节点上,将以下几行添加到spark/conf/spark-defaults.conf中。
spark.driver.extraClassPath /<PATH_TO_ALLUXIO>/client/alluxio-2.7.3-client.jar
spark.executor.extraClassPath /<PATH_TO_ALLUXIO>/client/alluxio-2.7.3-client.jar
3)使用--jars传递 jar
--jars /root/app/alluxio/client/alluxio-2.7.3-client.jar2.e.g:使用 Alluxio 作为输入和输出
代码
import alluxio.AlluxioURI
import alluxio.client.file.FileSystem
import alluxio.conf.{AlluxioConfiguration, AlluxioProperties, InstancedConfiguration, PropertyKey}
import alluxio.grpc.DeletePOptions
import org.apache.spark.{SparkConf, SparkContext}
import javax.security.auth.Subject
object AlluxioApp02{
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
// .setAppName(this.getClass.getName).setMaster("local[2]")
val sc = new SparkContext(conf)
val inpath = args(0)
val outpath = args(1)
val alluxioProperties = new AlluxioProperties()
//
alluxioProperties.set(PropertyKey.MASTER_BIND_HOST,"bigdata")
alluxioProperties.set(PropertyKey.MASTER_HOSTNAME,"bigdata")
val alluxioConfiguration = new InstancedConfiguration(alluxioProperties)
val fs = FileSystem.Factory.get(new Subject,alluxioConfiguration)
val path = new AlluxioURI(outpath);
if(fs.exists(path)){
//参考https://docs.alluxio.io/os/javadoc/stable/index.html
val options: DeletePOptions = DeletePOptions.newBuilder().setRecursive(true).build()
fs.delete(path,options)
}
sc.textFile(inpath)
.saveAsTextFile(outpath)
sc.stop()
}
}
spark提交任务
spark-submit \ --name alluxioApp \ --class com.jojo.AlluxioApp \ --master yarn \ --deploy-mode client \ --executor-memory 1G \ --num-executors 1 \ --jars /root/app/alluxio/client/alluxio-2.7.3-client.jar \ /root/job/alluxio/alluxio-1.0.jar \ alluxio://bigdata:19998/mnt/hdfs/data/baidu.com/baidu.com0911.log \ alluxio://bigdata:19998/mnt/hdfs/data/baidu.com/baidu.com0911.log.out
结果
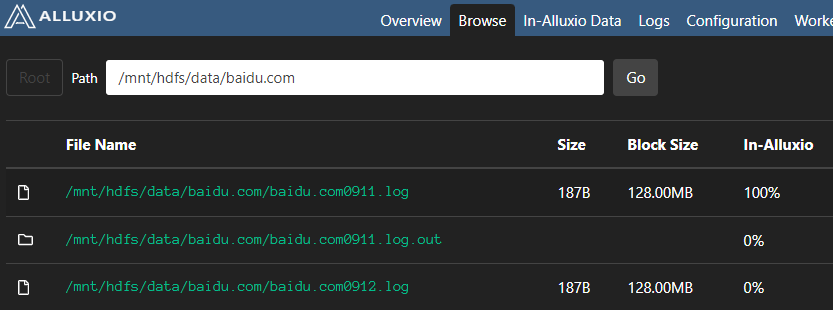

 浙公网安备 33010602011771号
浙公网安备 33010602011771号