

集群namenode与journalNode通讯超时导致namenode挂掉问题分析
背景:
因业务要求进行了一次业务数据的全量采集,采集过程中集群namenode与journalNode通讯超时导致namenode挂掉。如下图
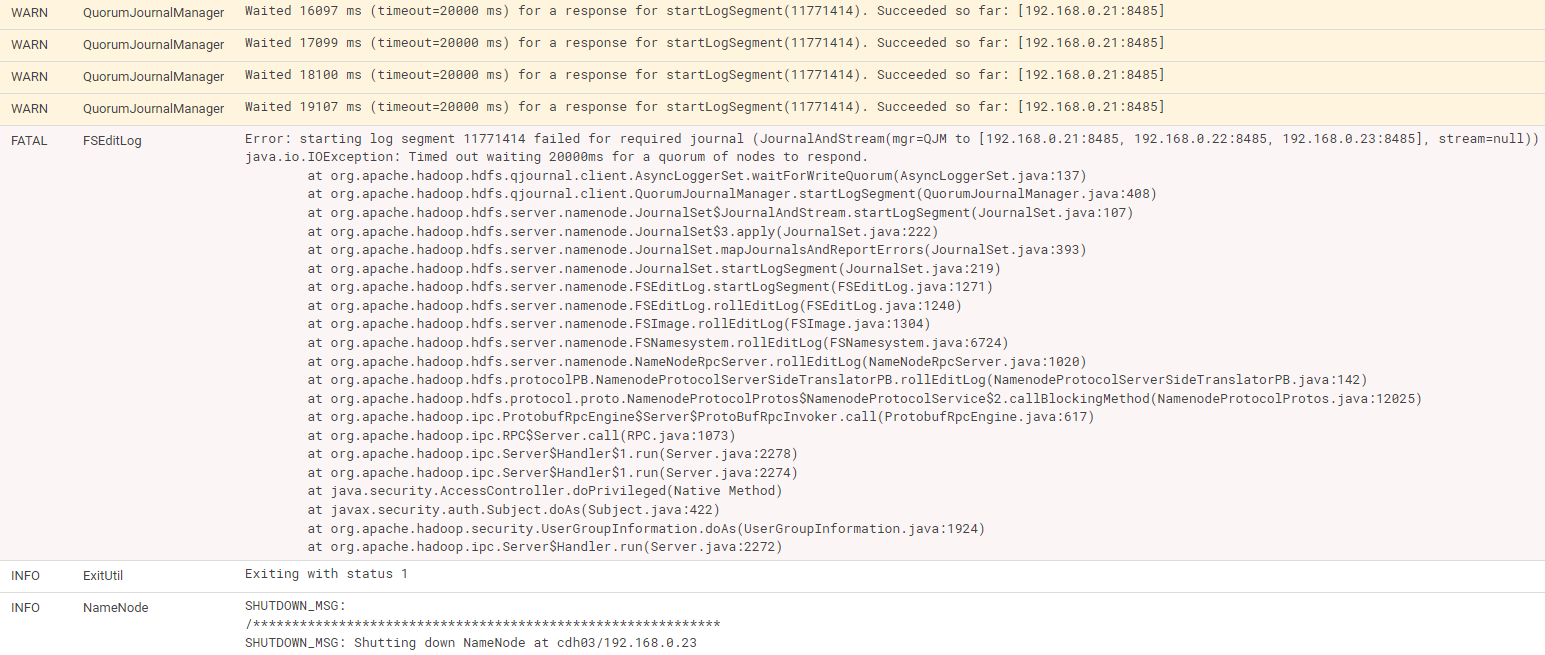
Error: starting log segment 11771414 failed for required journal (JournalAndStream(mgr=QJM to [192.168.0.21:8485, 192.168.0.22:8485, 192.168.0.23:8485], stream=null)) java.io.IOException: Timed out waiting 20000ms for a quorum of nodes to respond.
问题分析:
这种问题通常是Full GC导致的问题, namenode这个时间点进行了一次时间比较长的 full gc,导致写 journalnode 超时(默认是20s), namenode进程退出。
结合集群namenode jvm参数
-XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70 -XX:+CMSParallelRemarkEnabled
为什么Namenode JVM一般选用CMS,可以参考:NameNode Garbage Collection Configuration: Best Practices and Rationale
可能是以下原因:
1. Perm(jdk1.8后是元数据空间)空间不足; 2. CMS GC时出现promotion failed和concurrent mode failure(concurrent mode failure发生的原因一般是CMS正在进行,但是由于老年代空间不足,需要尽快回收老年代里面的不再被使用的对象,这时停止所有的线程,同时终止CMS,直接进行Serial Old GC); 3. 主动触发Full GC(执行jmap -histo:live [pid])来避免碎片问题。
再结合如下监控及heap情况:
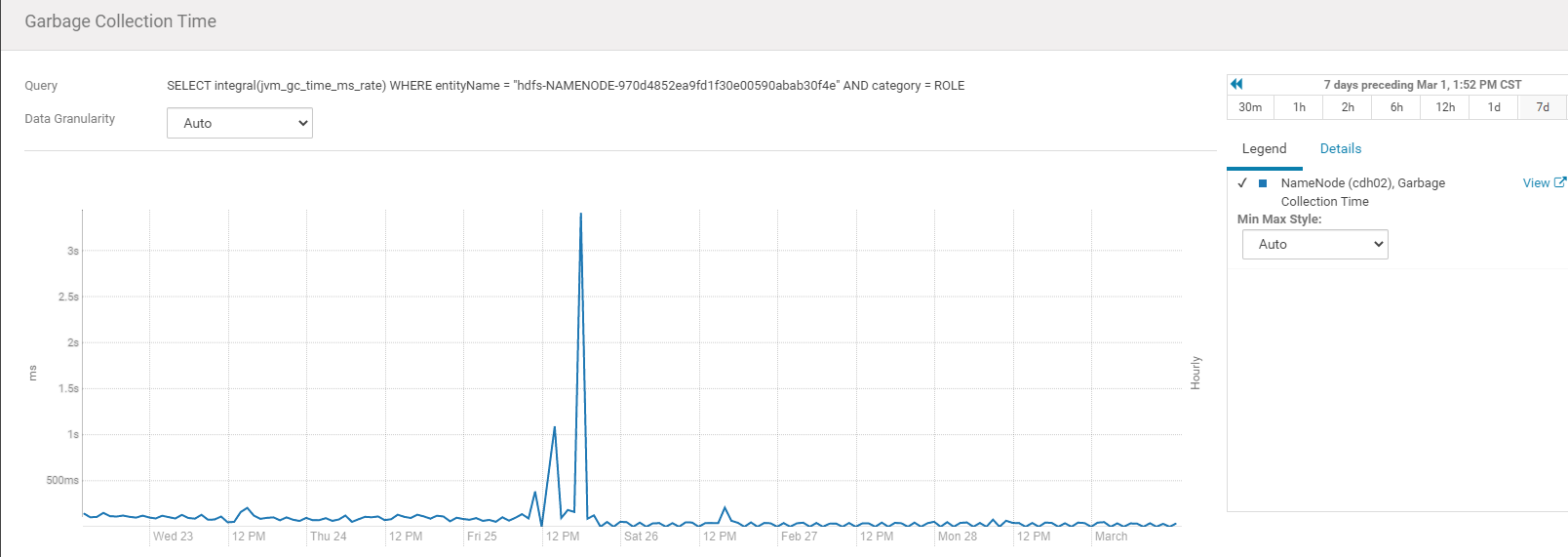
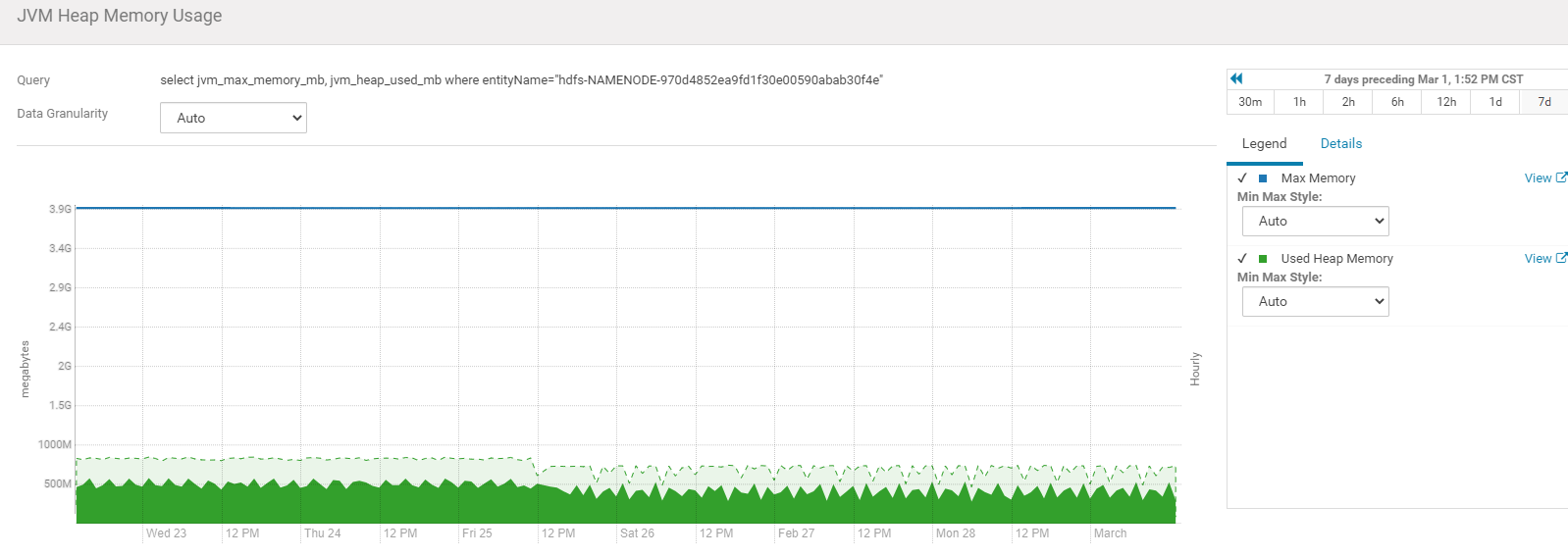

我们可以看到,E伊甸园区使用比例 和M元数据区使用比例都很高,O老年代使用比例很低,且元数据区默认只有20M,所以判断是元数据空间不足导致的 full gc。
另外新生代和老生代比例为1:4,容易造成大对象在做gc时,大对象直接进入老生代,造成老生代内存快速增长,full gc更加频繁。
调优方向:
1.提升堆内存大小,降低Old区使用比例,修改新生代和老生代比例为1:3,规避压缩式GC的STW风险
2.调节journalnode 的写入超时时间 dfs.qjournal.write-txns.timeout.ms = 90s
3.设置Java8的永生代初始值MetaspaceSize为较大的值128m,避免MetaSpace用满需要增长而引发的Full GC,-XX:MetaspaceSize=128m
-XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70 -XX:+UseCMSInitiatingOccupancyOnly -XX:+CMSParallelRemarkEnabled -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=9004 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -XX:NewRatio=3 -XX:MetaspaceSize=128m -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps

补充:
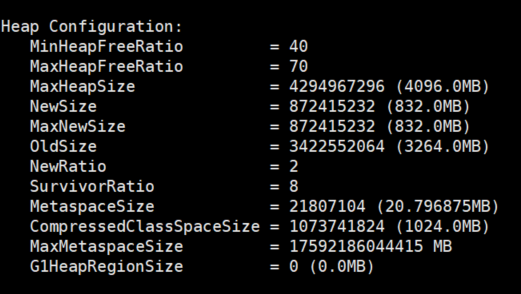
jdk8的JVM 内存划分

GC 主要工作在 Heap 区和 MetaSpace 区(上图蓝色部分)
什么是Matespace,它使用的是什么内存,Metadata GC Threshold的含义是什么
Mateapce:元空间,是JDK1.8中用来代替Perm的。它使用的是本地堆内存(native heap),所以Matespace并不受JVM可使用内存大小限制。可以使用” -XX:MaxMetaspaceSize “参数指定Matespace最大可使用的空间,-XX:MaxMetaspaceSize默认是没有限制的。
Matespace主要由Class Metaspace和Non-Class MetaSpace组成。
- Class Matespace:主要包括byte code、class等信息。如果开启了压缩指针
-XX:+UseCompressedClassPointers(默认开启),这一块的数据会被放到”Compressed Class Space” 中,可以通过-XX:CompressedClassSpaceSize参数来控制大小(默认1G,最大3G)。 - Non-Class Metaspace:专门来存class相关的其他的内容,比如method,constantPool等
Metadata GC Threshold 顾名思义,就是 Metaspace 的空间大小超过了这个阈值,尝试FullGC收集可以卸载的类加载器来复用空间,如果空间仍然不足,则尝试对Metaspace进行扩容。如此循环,直到达到 MaxMetaspaceSize 指定的上限。
如果频繁发生原因是 Metadata GC Threshold 的FullGC ,那么需要做如下排查:
- MaxMetaspaceSize 设定的是否过小
- 使用的类加载,是否存在内存泄漏的情况
类加载器负责分配Metaspace的空间,当一个类加载器被卸载后,且发生GC时,这个类加载器加载的类所占用的Metaspace空间,将会被释放。释放的Metaspace空间并不会归还给系统内存,而是会被 JVM 保留下来。
参考文章:
https://tech.meituan.com/2017/12/29/jvm-optimize.html
https://ericsahit.github.io/2016/12/25/Namenode%E5%86%85%E5%AD%98%E5%88%86%E6%9E%90/
https://tech.meituan.com/2020/11/12/java-9-cms-gc.html
https://russxia.com/2020/03/06/%E7%94%B1MateSpace%E7%A9%BA%E9%97%B4%E4%B8%8D%E8%B6%B3%E5%BC%95%E5%8F%91%E7%9A%84FullGC/
https://toutiao.io/posts/155svp/preview
https://cache.one/read/3461413
http://blog.itpub.net/30089851/viewspace-2122226/
https://community.cloudera.com/t5/Support-Questions/Name-Node-instability-flush-failed-for-required-journal/td-p/128161
