
5.链表(下)
写好链表的代码
1.理解指针(引用)的含义
将变量赋值个指针,实际上就是将这个变量的地址赋值给指针
p->next = q : p结点的next指针存储了q结点的内存地址
p->next = q->next->next : p结点的next指针存储了q结点的下下一个结点的内存地址
2.警惕指针丢失和内存泄漏
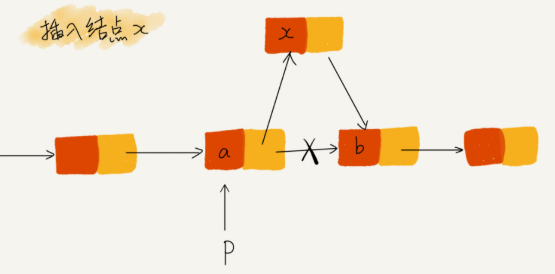
p->next = x; // 将 p 的 next 指针指向 x 结点;
x->next = p->next; // 将 x 的结点的 next 指针指向 b 结点;
如果这样写,就会造成x->next的指向x自己,造成指针泄漏,整个链表就断了。
将上面两句代码顺反一下就解决了问题。
对于像C语言这样内存管理是由程序员负责的,插入和删除链表结点,一定要手动释放内存空间,否则就会发生内存泄露。
3.利用哨兵简化实现难度
在p节点后插入一个节点:
new_node—>next = p—>next;
p—>next = new_node;
但若向空链表中插入一个节点:
if(head == null){
head = new_node;
}
要删除节点p的后继节点:
p—>next = p—>next—>next;
但若是删除链表的最后一个节点(链表中只剩下这个节点),则代码如下:
if(head—>next == null){
head = null;
}
针对链表的插入、删除操作,需要对插入第一个节点和删除最后一个结点的情况进行特殊处理。 这样代码实现起来机会繁琐而不简介,容易在边界考虑上犯错。
因此引入哨兵结点,不管链表是否为空,head指针一直指向哨兵结点。
有哨兵结点的:带头链表
没哨兵结点的:不带头链表

举个例子:
1 // 在数组 a 中,查找 key,返回 key 所在的位置 2 // 其中,n 表示数组 a 的长度 3 int find(char* a, int n, char key) { 4 // 边界条件处理,如果 a 为空,或者 n<=0,说明数组中没有数据,就不用 while 循环比较了 5 if(a == null || n <= 0) { 6 return -1; 7 } 8 9 int i = 0; 10 // 这里有两个比较操作:i<n 和 a[i]==key. 11 while (i < n) { 12 if (a[i] == key) { 13 return i; 14 } 15 ++i; 16 } 17 18 return -1; 19 } 20
1 // 在数组 a 中,查找 key,返回 key 所在的位置 2 // 其中,n 表示数组 a 的长度 3 // 我举 2 个例子,你可以拿例子走一下代码 4 // a = {4, 2, 3, 5, 9, 6} n=6 key = 7 5 // a = {4, 2, 3, 5, 9, 6} n=6 key = 6 6 int find(char* a, int n, char key) { 7 if(a == null || n <= 0) { 8 return -1; 9 } 10 11 // 这里因为要将 a[n-1] 的值替换成 key,所以要特殊处理这个值 12 if (a[n-1] == key) { 13 return n-1; 14 } 15 16 // 把 a[n-1] 的值临时保存在变量 tmp 中,以便之后恢复。tmp=6。 17 // 之所以这样做的目的是:希望 find() 代码不要改变 a 数组中的内容 18 char tmp = a[n-1]; 19 // 把 key 的值放到 a[n-1] 中,此时 a = {4, 2, 3, 5, 9, 7} 20 a[n-1] = key; 21 22 int i = 0; 23 // while 循环比起代码一,少了 i<n 这个比较操作 24 while (a[i] != key) { 25 ++i; 26 } 27 28 // 恢复 a[n-1] 原来的值, 此时 a= {4, 2, 3, 5, 9, 6} 29 a[n-1] = tmp; 30 31 if (i == n-1) { 32 // 如果 i == n-1 说明,在 0...n-2 之间都没有 key,所以返回 -1 33 return -1; 34 } else { 35 // 否则,返回 i,就是等于 key 值的元素的下标 36 return i; 37 } 38 }
对比两段低吗,当a很长很长的时候,代码二会明显快。因为while循环是执行最多的一部分,而代码二通过哨兵a[n-1] = key,省略了一个比较语句i<n 。
以上只是举例,但实际写代码,代码二的可读性太差了,一般不会追求如此极致的性能。
4.举例画图,辅助思考
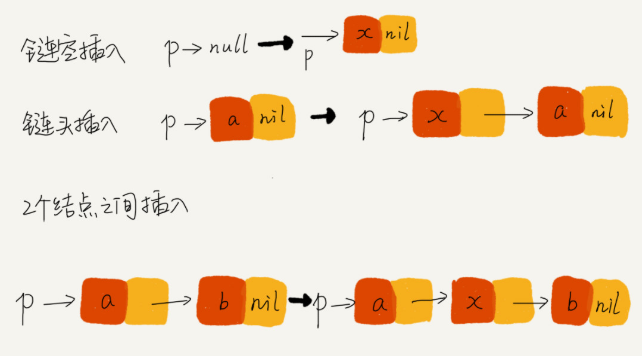
5.重点留意边界条件处理
一般检查的边界条件:
- 链表为空,代码能否正常工作?
- 链表只包含一个结点,代码能否正常工作?
- 链表只包含两个结点,代码能否正常工作?
- 代码逻辑在处理头结点和尾结点的时候,代码能否正常工作?
此外针对不同的场景,可能还有特定的边界条件
6.多写多练
- 精选的5个常见的链表操作
- 单链表的反转
- 链表中环的检测
- 两个有序的链表的合并
- 删除链表倒数第n个节点
- 求链表的中间结点
