
4.链表(上)
对比数组,链表不需要一块连续的内存空间,它通过“指针”将一组零散的内存块串联起来使用。
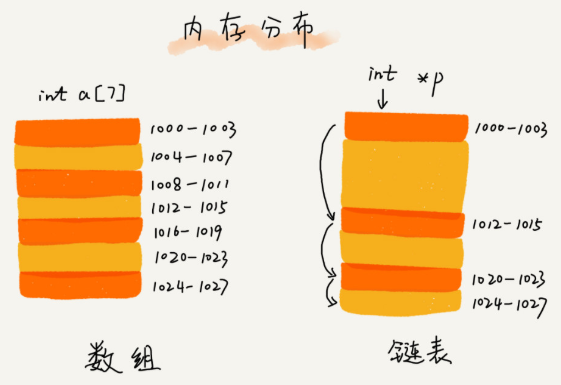
链表有单链表、双链表、循环链表
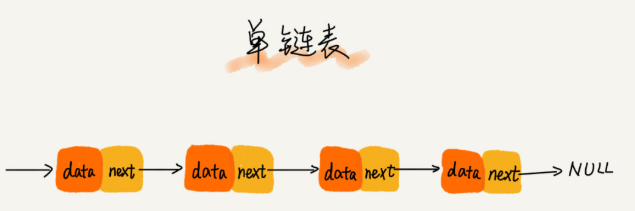
单链表
将零散的内存块(被称为结点)串联在一起,每个链表的节点除了存储数据外还要存储下一个结点的指针,记录下一个结点的指针成为后继指针。
头结点和尾结点比较特殊,头结点记录链表的基地址,用它,便可以遍历整个链表,尾结点存储的指针指向一个空地址NULL
链表和数组一样支持数据的查找、插入和删除
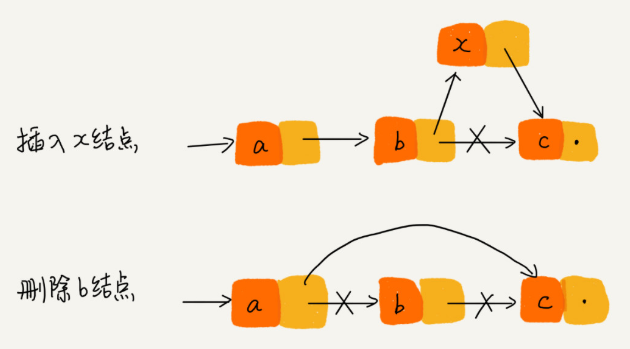
看图便可知,链表的单纯的(插入和删除)的时间复杂度为O(1)
但鱼与熊掌不可兼得,链表的查询就不能像数组一样通过首地址和下标经过寻址公式便可以得到,所以链表的查询只能一个个遍历,时间复杂度为O(n)
循环链表
尾结点指向头结点的单链表
当处理的数据具有环形结构时,就适合使用循环链表,如约瑟夫问题。
1 #include<bits/stdc++.h>//c++万能头文件,写了这个其他头文件不用写 2 using namespace std;//使用名字空间,你不用管 3 4 typedef struct node//节点存放一个数据和指向下一个节点的指针 5 { 6 int data;//数据域 7 struct node *pnext;//指针域,而且必须指向下一个同类型的节点的指针变量 struct node这个类型 8 } Node; 9 10 Node *create(int n)//创建n个节点的循环链表,函数名前加*表示返回Node类型的指针 11 { 12 //先创建第1个节点 13 Node *p,*q,*head;//p,q,head为指向struct node类型的指针变量,可以为其赋值 14 int i; 15 p = (Node *)malloc(sizeof(Node));//malloc函数为p动态分配内存空间 16 head = p;//头部也就是第一个节点 17 p->data = 1; 18 19 for(i = 2;i<=n;i++)//再创建剩余节点 20 { 21 q = (Node *)malloc(sizeof(Node));//添加新节点所以重新分配内存空间,动态分配 22 q->data = i; 23 p->pnext = q;//p在q前面所以p指向q 24 p = q;//这个时候p就得是q了,因为要往后创建 ,也就是说q就变成下一个节点的前驱 25 } 26 p->pnext = head;//最后一个节点指向头部,形成循环链表 27 return head; 28 } 29 30 void Josephus(Node *head,int k,int m)//从编号为k(1<=k<=n)的人开始报数,数到m的那个人出列; 31 { 32 int i; 33 Node *p = head,*tmp1; 34 while(p->data != k)//p指向的节点data为k,先找到开始的数的那个位置 35 p = p->pnext; 36 37 while(p->pnext != p)//模拟报数的过过程直到剩下自己一个人的时候,这时只有一个他指向自己 38 { 39 for(i=1;i<m;i++)//数到第m个 40 { 41 tmp1 = p;//tmp1在这里用于记录出局人的前一个人 42 p = p->pnext; 43 } 44 printf("%d ",p->data);//输出出局的人的编号 45 //链表的精髓在下面这个部分,比数组好多了 46 tmp1->pnext= p->pnext;//只需改变指针指向的数据元素,就可以去掉出局的那个人,从他下一个位置的人开始数 47 free(p);//释放p指向的内存空间,彻底地把出局人的位置都清空他就不存在了 48 p = tmp1->pnext;//下一轮开始的位置 49 50 } 51 printf("\nThe lucky people is %d\n",p->data);//最后的赢家 52 free(p);//释放p指向的内存空间 53 } 54 55 int main() 56 { 57 int n,m,s; 58 scanf("%d %d %d",&n,&m,&s); 59 Node *head = create(n);//调用函数创建含n个节点的循环链表 60 Josephus(head,s,m);//调用模拟Josephus的函数 61 return 0; 62 }
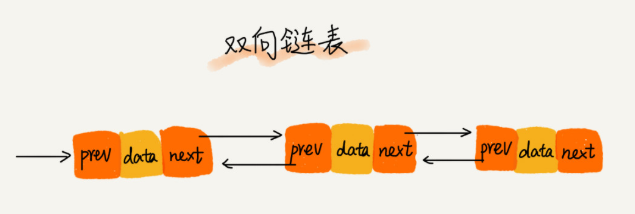
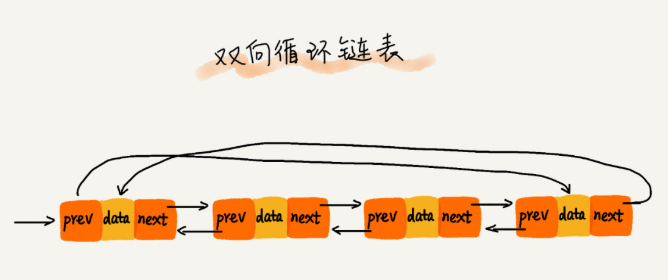
双向链表
pre前驱结点(存储着上一个结点的地址)和next后继结点
删除操作
删除结点中“值等于某个给定值”的结点
单链表和双链表单纯删除时间复杂度都为O(1),但查找值需要遍历操作,因此整个操作时间复杂度为O(n)
删除给定指针指向的结点
找到要删除的结点q后,删除需要它的prev结点,双链表因为有了prev指针,时间复杂度为O(1),单链表仍要遍历寻找,为O(n)
指点结点插入,同理,单链表为O(n),双链表O(1)
在有序链表中按值查询,双链表也更有效率,可以几率上次查找的位置p,根据查找的值与p对比,决定查找方向。
双链表的效率--->Java中LinkedHashMap -->用空间换时间
双向循环链表
链表VS数组
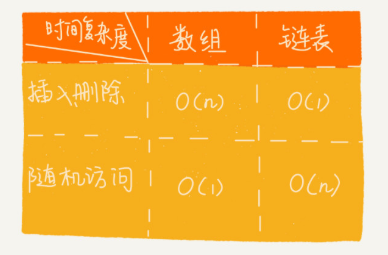
链表更适合插入、删除操作频繁的场景,查询的时间复杂度较高,具体开发中,需要综合对比链表和数组选择其中一个
