
Network Stack : Disk Cache
OverviewThe disk cache stores resources fetched from the web so that they can be accessed quickly at a latter time if needed. The main characteristics of Chromium disk cache are:
A new version of the cache is under development, and some sections of this documents are going to be stale soon. In particular, the description of a cache entry, and the big picture diagram (sections 3.4 and 3.5) are only valid for files saved with version 2.x
Note that on Android we don't use this implementation; we use the simple cache instead.
External InterfaceAny implementation of Chromium's cache exposes two interfaces: disk_cache::Backend and disk_cache::Entry. (see src/net/disk_cache/disk_cache.h). The Backend provides methods to enumerate the resources stored on the cache (a.k.a Entries), open old entries or create new ones etc. Operations specific to a given resource are handled with the Entry interface. An entry is identified by its key, which is just the name of the resource (for example http://www.google.com/favicon.ico ). Once an entry is created, the data for that particular resource is stored in separate chunks or data streams: one for the HTTP headers and another one for the actual resource data, so the index for the required stream is an argument to the Entry::ReadData and Entry::WriteData methods. Disk StructureAll the files that store Chromium’s disk cache live in a single folder (you guessed it, it is called cache), and every file inside that folder is considered to be part of the cache (so it may be deleted by Chromium at some point!). Chromium uses at least five files: one index file and four data files. If any of those files is missing or corrupt, the whole set of files is recreated. The index file contains the main hash table used to locate entries on the cache, and the data files contain all sorts of interesting data, from bookkeeping information to the actual HTTP headers and data of a given request. These data files are also known as block-files, because their file format is optimized to store information on fixed-size “blocks”. For instance, a given block-file may store blocks of 256 bytes and it will be used to store data that can span from one to four such blocks, in other words, data with a total size of 1 KB or less. When the size of a piece of data is bigger than disk_cache::kMaxBlockSize (16 KB), it will no longer be stored inside one of our standard block-files. In this case, it will be stored in a “separate file”, which is a file that has no special headers and contains only the data we want to save. The name of a separate file follows the form f_xx, where xx is just the hexadecimal number that identifies the file. Cache AddressEvery piece of data stored by the disk cache has a given “cache address”. The cache address is simply a 32-bit number that describes exactly where the data is actually located. A cache entry will have an address; the HTTP headers will have another address, the actual request data will have a different address, the entry name (key) may have another address and auxiliary information for the entry (such as the rankings info for the eviction algorithm) will have another address. This allows us to reuse the same infrastructure to efficiently store different types of data while at the same time keeping frequently modified data together, so that we can leverage the underlying operating system to reduce access latency. The structure of a cache address is defined on disk_cache/addr.h, and basically tells if the required data is stored inside a block-file or as a separate file and the number of the file (block file or otherwise). If the data is part of a block-file, the cache address also has the number of the first block with the data, the number of blocks used and the type of block file. These are few examples of valid addresses: 0x00000000: not initialized 0x8000002A: external file f_00002A 0xA0010003: block-file number 1 (data_1), initial block number 3, 1 block of length. Index File StructureThe index file structure is specified on disk_cache/disk_format.h. Basically, it is just an disk_cache::IndexHeader structure followed by the actual hash table. The number of entries in the table is at least disk_cache::kIndexTablesize (65536), but the actual size is controlled by the table_len member of the header. The whole file is memory mapped to allow fast translation between the hash of the name of a resource (the key), and the cache address that stores the resource. The low order bits of the hash are used to index the table, and the content of the table is the address of the first stored resource with the same low order bits on the hash. One of the things that must be verified when dealing with the disk cache files (the index and every block-file) is that the magic number on the header matches the expected value, and that the version is correct. The version has a mayor and a minor part, and the expected behavior is that any change on the mayor number means that the format is now incompatible with older formats. Block File StructureThe block-file structure is specified on disk_cache/disk_format.h. Basically, it is just a file header (disk_cache::BlockFileHeader) followed by a variable number of fixed-size data blocks. Block files are named data_n, where n is the decimal file number. The header of the file (8 KB) is memory mapped to allow efficient creation and deletion of elements of the file. The bulk of the header is actually a bitmap that identifies used blocks on the file. The maximum number of blocks that can be stored on a single file is thus a little less than 64K. Whenever there are not enough free blocks on a file to store more data, the file is grown by 1024 blocks until the maximum number of blocks is reached. At that moment, a new block-file of the same type is created, and the two files are linked together using the next_file member of the header. The type of the block-file is simply the size of the blocks that the file stores, so all files that store blocks of the same size are linked together. Keep in mind that even if there are multiple block-files chained together, the cache address points directly to the file that stores a given record. The chain is only used when looking for space to allocate a new record. To simplify allocation of disk space, it is only possible to store records that use from one to four actual blocks. If the total size of the record is bigger than that, another type of block-file must be used. For example, to store a string of 2420 bytes, three blocks of 1024 bytes are needed, so that particular string will go to the block-file that has blocks of 1KB. Another simplification of the allocation algorithm is that a piece of data is not going to cross the four block alignment boundary. In other words, if the bitmap says that block 0 is used, and everything else is free (state A), and we want to allocate space for four blocks, the new record will use blocks 4 through 7 (state B), leaving three unused blocks in the middle. However, if after that we need to allocate just two blocks instead of four, the new record will use blocks 1 and 2 (state C). 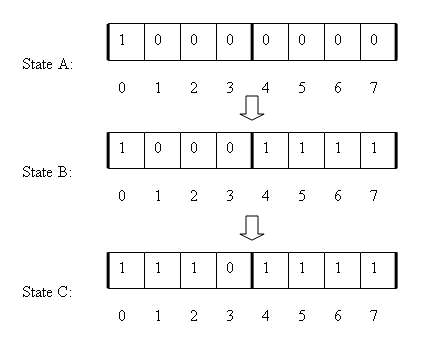 There are a couple of fields on the header to help the process of allocating space for a new record. The empty field stores counters of available space per block type and hints stores the last scanned location per block type. In this context, a block type is the number of blocks requested for the allocation. When a file is empty, it can store up to X records of four blocks each (X being close to 64K / 4). After a record of one block is allocated, it is able be able to store X-1 records of four blocks, and one record of three blocks. If after that, a record of two blocks is allocated, the new capacity is X-1 records of four blocks and one record of one block, because the space that was available to store the record of three blocks was used to store the new record (two blocks), leaving one empty block. It is important to realize that once a record has been allocated, its size cannot be increased. The only way to grow a record that was already saved is to read it, then delete it from the file and allocate a new record of the required size. From the reliability point of view, having the header memory mapped allows us to detect scenarios when the application crashes while we are in the middle of modifying the allocation bitmap. The updating field of the header provides a way to signal that we are updating something on the headers, so that if the field is set when the file is open, the header must be checked for consistency. Cache EntryAn entry is basically a complete entity stored by the cache. It is divided in two main parts: the disk_cache::EntryStore stores the part that fully identifies the entry and doesn’t change very often, and the disk_cache::RankingsNode stores the part that changes often and is used to implement the eviction algorithm.The RankingsNode is always the same size (36 bytes), and it is stored on a dedicated type of block files (with blocks of 36 bytes). On the other hand, the EntryStore can use from one to four blocks of 256 bytes each, depending on the actual size of the key (name of the resource). In case the key is too long to be stored directly as part of the EntryStore structure, the appropriate storage will be allocated and the address of the key will be saved on the long_key field, instead of the full key. The other things stored within EntryStore are addresses of the actual data streams associated with this entry, the key’s hash and a pointer to the next entry that has the same low-order hash bits (and thus shares the same position on the index table). Whenever an entry is in use, its RankingsNode is marked as in-use so that when a new entry is read from disk we can tell if it was properly closed or not. The Big Picture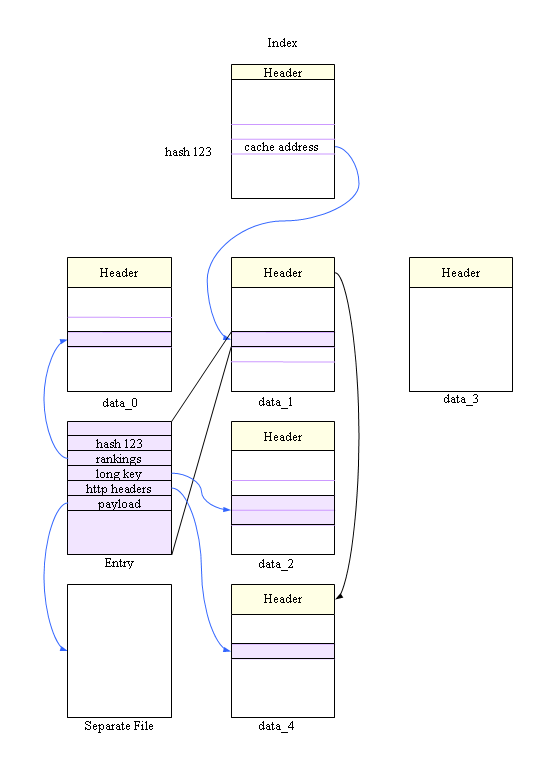 Implementation NotesChromium has two different implementations of the cache interfaces: while the main one is used to store info on a given disk, there is also a very simple implementation that doesn’t use a hard drive at all, and stores everything in memory. The in-memory implementation is used for the Incognito mode so that even if the application crashes it will be quite difficult to extract any information that was accessed while browsing in that mode.
There are a few different types of caches (see net/base/cache_type.h), mainly defined by their intended use: there is a media specific cache, the general purpose disk cache, and another one that serves as the back end storage for AppCache, in addition to the in-memory type already mentioned. All types of caches behave in a similar way, with the exception that the eviction algorithm used by the general purpose cache is not the same LRU used by the others. The regular cache implementation is located on disk_cache/backend_impl.cc and disk_cache/entry_impl.cc. Most of the files on that folder are actually related to the main implementation, except for a few that implement the in-memory cache: disk_cache/mem_backend_impl.cc and disk_cache/entry_impl.cc.The lower interface of the disk cache (the one that deals with the OS) is handled mostly by two files: disk_cache/file.h and disk_cache/mapped_file.h, with separate implementations per operating system. The most notable requirement is support for partially memory-mapped files, but asynchronous interfaces and a decent file system level cache go a long way towards performance (we don’t want to replicate the work of the OS). To deal with all the details about block-file access, the disk cache keeps a single object that deals with all of them: a disk_cache::BlockFiles object. This object enables allocation and deletion of disk space, and provides disk_cache::File object pointers to other people so that they can access the information that they need. A StorageBlock is a simple template that represents information stored on a block-file, and it provides methods to load and store the required data from disk (based on the record’s cache address). We have two instantiations of the template, one for dealing with the EntryStore structure and another one for dealing with the RankingsNode structure. With this template, it is common to find code like entry->rankings()->Store().EvictionSupport for the eviction algorithm of the cache is implemented on disk_cache/rankings (and mem_rankings for the in-memory one), and the eviction itself is implemented on disk_cache/eviction. Right now we have a simple Least Recently Used algorithm that just starts deleting old entries once a certain limit is exceeded, and a second algorithm that takes reuse and age into account before evicting an entry. We also have the concept of transaction when one of the the lists is modified so that if the application crashes in the middle of inserting or removing an entry, next time we will roll the change back or forward so that the list is always consistent. In order to support reuse as a factor for evictions, we keep multiple lists of entries depending on their type: not reused, with low reuse and highly reused. We also have a list of recently evicted entries so that if we see them again we can adjust their eviction next time we need the space. There is a time-target for each list and we try to avoid eviction of entries without having the chance to see them again. If the cache uses only LRU, all lists except the not-reused are empty. BufferingWhen we start writing data for a new entry we allocate a buffer of 16 KB where we keep the first part of the data. If the total length is less than the buffer size, we only write the information to disk when the entry is closed; however, if we receive more than 16 KB, then we start growing that buffer until we reach a limit for this stream (1 MB), or for the total size of all the buffers that we have. This scheme gives us immediate response when receiving small entries (we just copy the data), and works well with the fact that the total record size is required in order to create a new cache address for it. It also minimizes the number of writes to disk so it improves performance and reduces disk fragmentation. Deleting EntriesTo delete entries from the cache, one of the Doom*() methods can be used. All that they do is to mark a given entry to be deleted once all users have closed the entry. Of course, this means that it is possible to open a given entry multiple times (and read and write to it simultaneously). When an entry is doomed (marked for deletion), it is removed from the index table so that any attempt to open it again will fail (and creating the entry will succeed), even when an already created Entry object can still be used to read and write the old entry. When two objects are open at the same time, both users will see what the other is doing with the entry (there is only one “real” entry, and they see a consistent state of it). That’s even true if the entry is doomed after it was open twice. However, once the entry is created after it was doomed, we end up with basically two separate entries, one for the old, doomed entry, and another one for the newly created one. EnumerationsA good example of enumerating the entries stored by the cache is located at src/net/url_request/url_request_view_cache_job.cc . It should be noted that this interface is not making any statements about the order in which the entries are enumerated, so it is not a good idea to make assumptions about it. Also, it could take a long time to go through all the info stored on disk. Sparse DataAn entry can be used to store sparse data instead of a single, continuous stream. In this case, only two streams can be stored by the entry, a regular one (the first one), and a sparse one (the second one). Internally, the cache will distribute sparse chunks among a set of dedicated entries (child entries) that are linked together from the main entry (the parent entry). Each child entry will store a particular range of the sparse data, and inside that range we could have "holes" that have not been written yet. This design allows the user to store files of any length (even bigger than the total size of the cache), while the cache is in fact simultaneously evicting parts of that file, according to the regular eviction policy. Most of this logic is implemented on disk_cache/sparse_control (and disk_cache/mem_entry_impl for the in-memory case). Dedicated ThreadWe have a dedicated thread to perform most of the work, while the public API is called on the regular network thread (the browser's IO thread). The reason for this dedicated thread is to be able to remove any potentially blocking call from the IO thread, because that thread serves the IPC messages with all the renderer and plugin processes: even if the browser's UI remains responsive when the IO thread is blocked, there is no way to talk to any renderer so tabs look unresponsive. On the other hand, if the computer's IO subsystem is under heavy load, any disk access can block for a long time. Note that it may be possible to extend the use of asynchronous IO and just keep using the same thread. However, we are not really using asynchronous IO for Posix (due to compatibility issues), and even in Windows, not every operation can be performed asynchronously; for instance, opening and closing a file are always synchronous operations, so they are subject to significant delays under the proper set of circumstances. Another thing to keep in mind is that we tend to perform a large number of IO operations, knowing that most of the time they just end up being completed by the system's cache. It would have been possible to use asynchronous operations all the time, but the code would have been much harder to understand because that means a lot of very fragmented state machines. And of course that doesn't solve the problem with Open/Close. As a result, we have a mechanism to post tasks from the main thread (IO thread), to a background thread (Cache thread), and back, and we forward most of the API to the actual implementation that runs on the background thread. See disk_cache/in_flight_io and disk_cache/in_flight_backend_io. There are a few methods that are not forwarded to the dedicated thread, mostly because they don't interact with the files, and only provide state information. There is no locking to access the cache, so these methods are generally racing with actual modifications, but that non-racy guarantee is not made by the API. For example, getting the size of a data stream (entry::GetDataSize()) is racing with any pending WriteData operation, so it may return the value before of after the write completes. Note that we have multiple instances of disk-caches, and they all have the same background thread. Data IntegrityThere is a balance to achieve between performance and crash resilience. At one extreme, every unexpected failure will lead to unrecoverable corrupt information and at the other extreme every action has to be flushed to disk before moving on to be able to guarantee the correct ordering of operations. We didn’t want to add the complexity of a journaling system given that the data stored by the cache is not critical by definition, and doing that implies some performance degradation. The current system relies heavily on the presence of an OS-wide file system cache that provides adequate performance characteristics at the price of losing some deterministic guarantees about when the data actually reaches the disk (we just know that at some point, some part of the OS will actually decide that it is time to write the information to disk, but not if page X will get to disk before page Y). Some critical parts of the system are directly memory mapped so that, besides providing optimum performance, even if the application crashes the latest state will be flushed to disk by the system. Of course, if the computer crashes we’ll end up on a pretty bad state because we don’t know if some part of the information reached disk or not (each memory page can be in a different state). The most common problem if the system crashes is that the lists used by the eviction algorithm will be corrupt because some pages will have reached disk while others will effectively be on a “previous” state, still linking to entries that were removed etc. In this case, the corruption will not be detected at start up (although individual dirty entries will be detected and handled correctly), but at some point we’ll find out and proceed to discard the whole cache. It could be possible to start “saving” individual good entries from the cache, but the benefit is probably not worth the increased complexity.
|

posted on 2018-09-19 14:37 huangguanyuan 阅读(359) 评论(0) 编辑 收藏 举报


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~