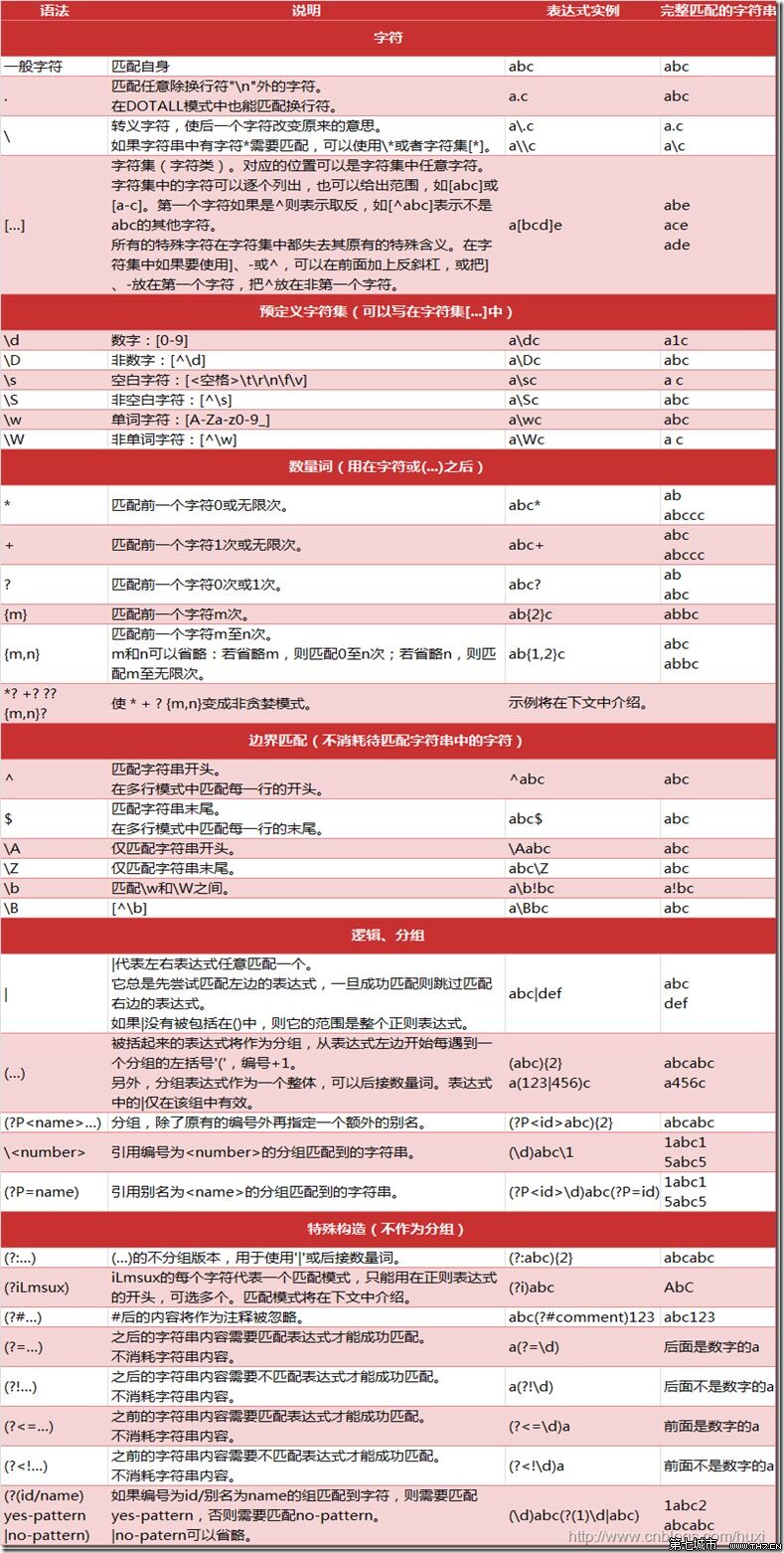
re(正则表达式)模块
一、最常用的匹配语法
re.match 从头开始匹配
re.search 匹配包含
re.findall 把所有匹配到的字符放到以列表中的元素返回
re.split 以匹配到的字符当做列表分隔符
re.sub 匹配字符并替换'.' 默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行
匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE)'$' 匹配字符结尾,或e.search("foo$","bfoo\nsdfsf",flags=re.MULTILINE).group()也可以'*' 匹配*号前的字符0次或多次,re.findall("ab*","cabb3abcbbac") 结果为['abb', 'ab', 'a']'+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb']'?' 匹配前一个字符1次或0次'{m}' 匹配前一个字符m次'{n,m}' 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb']'|' 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC''(...)' 分组匹配,re.search("(abc){2}a(123|456)c", "abcabca456c").group() 结果 abcabca456c'\Z' 匹配字符结尾,同$'\d' 匹配数字0-9'\D' 匹配非数字'\w' 匹配[A-Za-z0-9]'\W' 匹配非[A-Za-z0-9]'s' 匹配空白字符、\t、\n、\r , re.search("\s+","ab\tc1\n3").group() 结果 '\t''(?P<name>...)' 分组匹配 re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})","371481199306143242").groupdict("city") 结果{'province': '3714', 'city': '81', 'birthday': '1993'}import re
a = 'abc+10 + 20'
b = 'abc+10+20'
regex1 = re.compile('\d+\s*[+]\s*\d+') #对正则表达式进行编译,\d+表示匹配一个或多个数字,\s*表示匹配0个或多个空格,[]里面为字符集
print(regex1.search(a).group()) #匹配字符串 结果:10 + 20,对匹配该算术表达式来说,如果这里换成\s+则匹配不到,如果\d+换成\d*则会匹配到你不想匹配到的结果
print(regex1.search(b).group()) #结果:10+20
上述的python表示方式也可以这么表示
print(re.search('\d+\s*[+]\s*\d+',a).group())等同于先进行编译,再匹配
3、?一般搭配*、+、{}使用
当正则表达式中包含能接受重复的限定符时,通常的行为是(在使整个表达式能得到匹配的前提下)匹配尽可能多的字符。以这个表达式为例:a.*b,它将会匹配最长的以a开始,以b结束的字符串。如果用它来搜索aabab的话,它会匹配整个字符串aabab。这被称为贪婪匹配。
有时,我们更需要懒惰匹配,也就是匹配尽可能少的字符。前面给出的限定符都可以被转化为懒惰匹配模式,只要在它后面加上一个问号?。这样.*?就意味着匹配任意数量的重复,但是在能使整个匹配成功的前提下使用最少的重复。现在看看懒惰版的例子吧:
a.*?b匹配最短的,以a开始,以b结束的字符串。如果把它应用于aabab的话,它会匹配aab(第一到第三个字符)和ab(第四到第五个字符)。
python结果:
a = 'aabab'
regex1 = re.compile(r'a.*?b')
regex2 = re.compile(r'a.*b')
print(regex1.findall(a)) ->['aab', 'ab'] ->这里用search的话只能找到aab
print(regex2.findall(a)) ->['aabab']
"*?" 重复任意次,但尽可能少重复
如 "acbacb" 正则 "a.*?b" 只会取到第一个"acb" 原本可以全部取到但加了限定符后,只会匹配尽可能少的字符 ,而"acbacb"最少字符的结果就是"acb"
"+?" 重复1次或更多次,但尽可能少重复
与上面一样,只是至少要重复1次
"??" 重复0次或1次,但尽可能少重复
如 "aaacb" 正则 "a.??b" 只会取到最后的三个字符"acb"
"{n,m}?" 重复n到m次,但尽可能少重复
如 "aaaaaaaa" 正则 "a{0,m}" 因为最少是0次所以取到结果为空
"{n,}?" 重复n次以上,但尽可能少重复
如 "aaaaaaa" 正则 "a{1,}" 最少是1次所以取到结果为 "a"
4、groups与()搭配使用
a = 'abc+10+20'
regex1 = re.compile(r'(\d+)([+])(\d+)')
print(regex1.search(a).groups()) ->('10', '+', '20') 能把分组的数据一一取出来
5、^与&
如:匹配以数字开头以数字结尾
a = '1abc+10+20'
regex1 = re.compile(r'^\d.*\d$')
print(regex1.search(a).group()) ->1abc+10+20,如果不是以数字开头和数字结尾则匹配不到
6、groupdict与()搭配使用
print(re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})","371481199306143242").groupdict() ) -> {'province': '3714', 'city': '81', 'birthday': '1993'}
7、split使用
- a = '1abc+10+20'
- regex1 = re.compile(r'\+')
- print(regex1.split(a)) ->['1abc', '10', '20']
上述2、3步骤相当于
print(re.split(r'\+',a))
8、sub使用
*号替换+号
- a = '1abc+10+20'
- regex1 = re.compile(r'\+')
- print(regex1.sub('*',a)) ->1abc*10*20,后面可以加count来确保匹配多少次
上述2、3步骤相当于
#print(re.sub(r'\+','*',a)) ->1abc*10*20
9、反斜杠的困扰
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\\"表示。同样,匹配一个数字的"\\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
10^与[]搭配
[^abc]匹配除了abc之外的任意字符
最后在添加一个图表