归纳程序综合计算机实现自我编程,真的可以实现吗?
国庆前夕,看见一个微信公共号推送有关于AI Programmer这篇文章,说计算机可以自己实现自主编程。又恰好自己也是做有关这个方面,就利用国庆放假时间做了简单的调研,并看了DeepCoder和AI Programmer。记录一下,可以方便自己今后查阅:
首先,先放上自己参考的几篇博客:
深度 | 机器的自我进化:走向自主编程的人工智能
人工智能在学习自主编程
谷歌新目标——让计算机实现自我编程,自主机器时代不再遥远
如何评价arXiv上的最新论文:“可自动编程”的人工智能程序员(AI Programmer)?
1.背景
人工智能目前已经得到了长足的发展,诸如CNN,RNN,LSTM等等深度学习算法,迁移学习,进化算法等等的提出,都让人工智能在很多领域都取得了成功的运用。细想下来,AI的未来是非常有趣的:家庭服务机器人、亚马逊的智能家庭中枢(Echo)等设备将走进每家每户,还有无人机快递和更加精准的医疗,这些都让大家对未来的AI充满希望。
但是,机器学习的专家目前还是倾向于聚焦那些特定任务的AI应用,比如人脸识别。自动驾驶、语音识别、阿尔法狗下围棋,甚至搜索等等。但是,如果这些算法如果可以在不需要人们参与帮助、解释或者干预的情况下,理解它们自身的代码结构呢?就像它们可以理解人类的语言或者图像那样,它们可以自己合成代码。
如果代码可以进行自我分析、自我修正并且提升,且速度比认为的更快,那么技术的突破也可能来的更快。由此带来的可能性是无止境的:医学的进步、更加自然的机器人、更加智能的手机、更少bug的软件、更少的银行诈骗等等。比如:一个癌症项目的开展在目前可能需要几年的时间,但是在以后,可能只需要几个月甚至更短的时间,这将无疑是个很大的突破。
其实,代码编写或者操控其他代码的能力的有关概念已经存在了相当长的时间了。一般情况下被称为元编程(其实际上起源于20世纪50年年代末的Lisp)。
2.初步的一些工作
针对这一项工作,目前国际上的几家大公司都在努力进行突破,而且已经有了初步的结果。
google的Tensorflow可以让每个开发者都可以在其应用上构建神经网络,用以在图片上实现识别人和物体。
google的代码bug预测系统,使用机器学习和统计学习,来判断一行代码是否有瑕疵。谷歌工程师、W3C联合主席Llya Grigorik开发的开源bug预测程序,已经被下载了2万次
Siri的创始人的新项目Viv,在一篇文章中所述,Viv不仅仅局限于自然语言理解,它还可以基于英语单词构建复杂的自适应计算机程序----即用代码编写代码。因为编写的代码是有Viv的开发者训练和优化的,它不是广义的自动编写代码,但是向这个方面又进了一步。
我们还能在爱好者的社区中看到一些进展。 Emil Schutte在他的网站上留下了一个挑衅的语句:“厌倦了编写代码? 我也是!把它交给Stack Overflow吧!”他随后展示的内容证明了完整的工作代码可以在Stack Overflow的大型数据库的编程知识中自动生成。
实际上更早之前,DeepMind 团队开发了一个“神经编程解释器”(NPI),能自己学习并且编辑简单的程序,排序的泛化能力也比序列到序列的 LSTM 更高。
在2017年,更多相关的文章被发表在顶刊或者顶会上。其中,最具有代表性的为DeepCoder和AI Programmer这两篇文章。下面,详细介绍一下这两篇文章。
3.基础知识
基因遗传算法:
遗传算法是一种有指导的随机搜索算法,主要是用来被用于优化领域。和粒子群优化、模拟退火、蚁群算法、禁忌搜索算法都是主要的启发式搜索算法。这些算法不要求目标函数连续可微,因此用途比较广泛。遗传算法的思路主要是受到遗传学启发,简单的介绍一下整个流程:
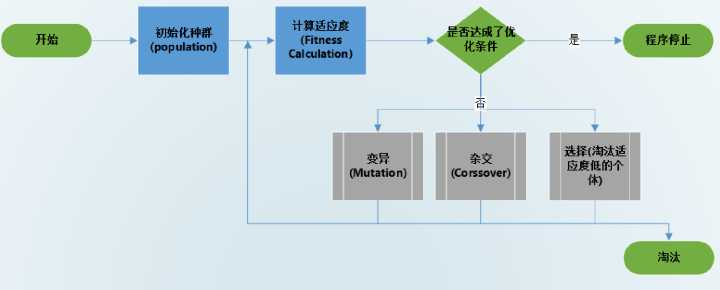
如上图所示:
(1)初始化“群体”,一般是随机出m个个体,假设每个个体携带n个特征。
(2)通过评估函数对每个个体的n个特征评估来确定适应度 F
(3)根据适应度,对不同的个体进行以下不同的操作:
i、选择:对于适应度低的个体,直接从群体中进行进行淘汰。对于表现优良的个体,则让其继续存活。
ii、交叉:对于适应度高的两个个体,交换其部分特征产生后代。在这里,就和生物繁衍的意思比较相近。
iii、变异:对于适应度高的个体,随机改变其部分特征。
(4)不断重复上述过程,一直到找到满足我们要求的个体。
遗传算法的最大好处就是可以在有限时间中得到一个相对不错的解,同时这也是大部分启发式算法的优点。选择保证我们淘汰了表现不佳的个体,杂交、遗传和变异保证了我们可以产生新的优良个体,以防止进入了局部最优,有更大的可能性获得全局最优。
4.DeepCoder
这篇文章是微软和剑桥大学联合发表的,说是能够编写并解决简单数学问题的代码的算法。该论文在被今年最大的人工智能会议认可之后,获得了极高知名度。
在这边文章中,作者主要是解决两个问题:(1)学习引导程序:也就是说,使用程序归纳问题的语料库来学习跨越问题的策略 。(2)将神经网络与基于搜索的技术想结合起来,而不是利用神经网络将搜索进行取代。
在这里,作者将归纳程序合成从新定义成一个数据问题,我们可以利用深度学习模型和搜索技术来解决这个数据问题。在这里,我们大概需要三个合理的方法:
(1)我们把这个问题训练一个监督模型
(2)我们通过搜索空间技术,而不是单纯的预测,来减轻神经网络的失败的可能性。
(3)利用神经网络来指导现有的程序合成系统,从而使我们可以从编程语言社区中获得更好的求解。
总的来说,我们是定义一个框架来使用深度学习进行代码合成问题。主要的工作为:
(1)定义一种具有足够表现力的编程语言,以包含真实世界的编程问题,同时足以满足输入输出的要求。
(2) 用于映射一组输入输出示例以编程属性的模型
(3)实验显示出相对于标准程序综合技术有数量级加速,这使得这种方法可以解决一些类似于编程竞赛网站上出现的最简单的问题这种困难的问题。
下面,介绍一下该模型的主要步骤:
首先,制度特定领域的语言和属性
由于本次实验的特殊性,在我们制定的这个特殊的语言(记为DSL),其使用的编程语言是一种原创的、极其精简的语言,其中只有整数数据类型,内置了基本的四则运算以及一些基本函数,例如排序,或者对数组中的元素依次执行某种操作等等。
其次,我们要对输入和输出进行分析。如下图所示,我们选了四个分析函数对结果进行分析:

如上图所示。在DSL中,我们定义了很多函数来刻画输入输出的特征。在函数中,稍低级的函数有:HEAD,LAST,TAKE,DROP,ACCESS,MINIMUN,MAXIMUM,REVERSE,SORT,SUM;更高级的函数有MAP,FILTER,COUNT,ZIPWITH,SCANL1。
其次:进行数据生成
为了更好利用我们所拥有的数据,我们需要对我们手上的数据进行进一步刻画。我们需要生成一个数据集:((P(n),a(n),ε(n)))Nn=1 ,其中P(n)指的是所代表的程序,a(n) 指的是程序所代表的特征,ε(n) 指的是所对应的输入输出案例。在特定的语言域中,利用不用的方法对数据集进行刻画对于后期的机器学习的训练有很大的作用。同时,所对应的数据集越大,产生的效果就越好。
第三步:进行机器学习模型的搭建

第四步:搜索模型的搭建
在这一步中,我们需要构建相关的搜索模型。在这里,我们主要是采用前人所发现的一些模型:Depth-first search(DFS)模型,“Sort and add” enumeration模型,Sketch模型,λ2模型。
第五步:训练损失函数
5.AI Programmer
在这篇文章中,作者采用基因遗传算法来进行代码的自动生成。先说明一下本篇文章的工作重点:
(1)它提供了一个利用AI产生的,独一无二的软件生成框架,它使用遗传算法构建了具有新颖增强功能的程序以及简约的编程语言。
(2)作者提出了几个重要的方案,包括嵌入式解释器和模拟器解决方案,用于安全和优化ML生成的软件。
(3)作者提供实证结果,证明了AI程序员在商品硬件上完全生成的几个软件程序的有效性和效率。
在这篇文章中,作者的主要目的是实现以下几个功能:
(1)简单程序比如输出一行字符串,如"Hello World"、"Hi"等
(2)相对复杂的程序比如:反转字符串、斐波那契数列等
同时,这篇文章的主要的说明点为:
(1)提出了一个“人工智能程序员”模型 (2)使用了遗传算法(Genetic Algorithm)进行优化搜索 (3)模型可以在大部分普通机器上运行且仅需要最低限度的人类指导
下面详细说明一下这篇文章的工作:
1.首先,说明一下这篇文章中所生成的语言:文章所使用的语言不是给人类设计的那一种,比如说Java和python,而是一个叫做BrainFxxK的极小编程语言。在这种语言中,所有的指令集都是由以下这八个指令组成,分别用这8个符号对应:

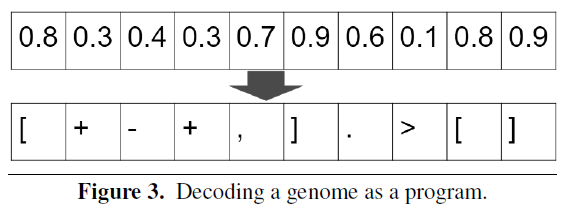
同时,作者所用的指令集是图灵完备的。我们都知道,在计算理论中我们通常会这样定义,如果一个编程语言是图灵完备的,那么理论上这个语言可以在无限的时间和内存需求下完成任何计算机可完成的任务。所以,作者就用这八个指令来代表所有程序,例如Hello World经过这个语言的诠释就可以为文中那一串长长的符号:

在实际的计算中,作者通常用数字来代表符号,[0,0.125]代表符号>,即指针加一。将符号平均取在0-1之间是为了易于遗传算法进行优化,但是如果采用更多的符号,则对遗传算法来说是一个挑战。因此,正如下图所示,所有的符号通常都使用0-1之间的数字所示:
根据文章所示,在使用AI之前,处理必要的硬件和准备工作,我们还需要提供一些必要的条件:
(1)定义程序的格式要求:例如给出输入格式和输出格式。在文章中,如果只是输出一句话,则不需要输入,只需要输出格式即可;对于更加复杂的操作,则需要输入和输出格式。
(2)定义自适应函数:对于产生的程序,我们需要判断这个函数是否就是我们所需要的,这个时候我们需要一个自适应函数进行判断。例如:最简单的就是我们可以通过输出啊字符长度是否为11来判断是否与“Hello World”相符。对于更加复杂的程序,需要用户给出更为复杂的评判标砖。
对于自适应函数,作者给出了一个工具,被称为沙盒解释器(Sand)
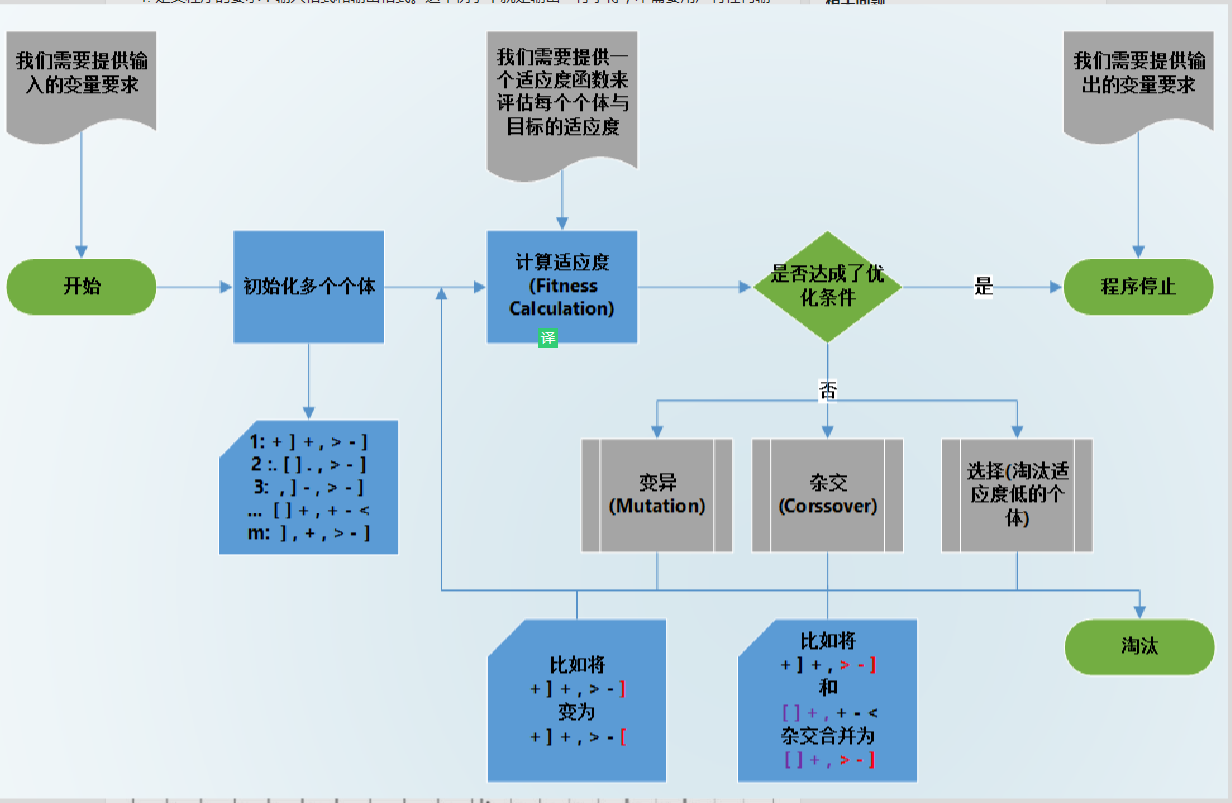
简单的说,就是初始化一系列“种子代码”,每次用适应度函数计算每个“种子代码”的质量。抛弃表现差的“种子代码”,保留优秀的“种子”进行变异和杂交操作,产生后代。重复以上过程直到有符合我们需求的代码出现。再一次,这个程序的核心就是用遗传算法进行启发式随机搜索。我图中表示的一样,不良的个体会被去除(被斜线划去)优秀的个体会保留;异过程中,某个基因从0.1变到了0.2,从">"成为了"<"。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号