
Innodb的存储及缓存
参考【mysql技术内幕】
一、mysql体系结构和存储引擎
1、数据库与数据库实例
数据库:物理操作系统文件或者其他文件组成的集合;
数据库实例:有数据库后台进程/线程和一个共享内存区域组成。
数据库就是文件,数据库实例是一个应用程序。用户对数据库的增删改查都是通过数据库实例进行的,其相当于是一个数据库管理软件。
2、mysql体系结构
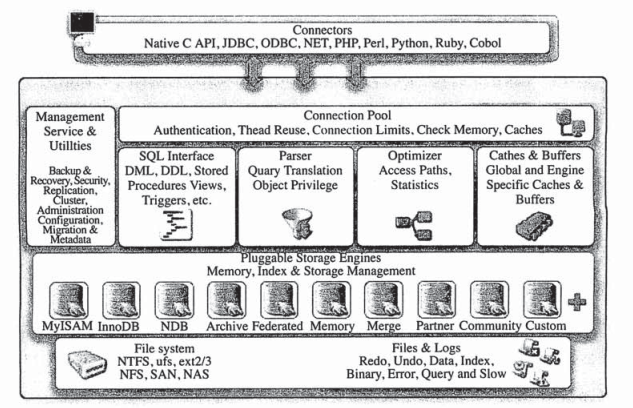
MySQL结构包括:连接池组件、管理服务工具组件、SQL接口组件、查询分析器组件、优化器组件、缓存组件、插入式表存储引擎、物理文件‘。尤其注意插入式表存储结构,这是mysql特殊于其他数据库的地方,他是基于表的,不是数据库的。
抽象一点:

从图中我们可以看出,服务器程序处理来自客户端的查询请求大致需要经过三个部分,分别是连接管理、解析与优化、存储引擎。
1、连接管理
客户端程序可以采用“link”介绍的TCP/IP、命名管道和共享内存、Unix域套接字这几种方式之一来与服务器程序建立连接,服务器程序会缓存一些线程,每当有客户端连接进来的时候,会为这个客户端程序分配一个线程来处理它发过来的请求。
创建和销毁线程会耗费很多性能,所以在服务器端维护许多线程可以减少这部分的性能损耗。但是服务器端维护的线程数目是有限的,如果在短时间内有超级多的客户端连接进来的话,会有一部分因为获取不到线程而进入等待状态,直到有的客户端断开连接后这些等待的客户端才可以被分配到线程。
在客户端程序发起连接的时候,需要携带主机信息、用户名、密码,服务器程序会对客户端程序提供的这些信息进行认证,如果认证失败,服务器程序会拒绝连接。另外,如果客户端程序和服务器程序不运行在一台计算机上,我们还可以采用使用了SSL(安全套接字)的网络连接进行通信,来保证数据传输的安全性。
2、优化与执行
当客户端程序成功的与服务器程序建立连接之后,就可以把文本命令发送到服务器程序了。这个部分大致需要需要查询缓存、语法解析、查询优化这几个步骤来完成,我们详细来看。
查询缓存:如果我问你9+8×16-3×2×17的值是多少,你可能会用计算器去算一下,或者牛逼一点用心算,最终得到了结果35,如果我再问你一遍9+8×16-3×2×17的值是多少,你还用再傻呵呵的算一遍么?我们刚刚已经算过了,直接说答案就好了。MySQL服务器程序处理查询请求的过程也是这样,会把刚刚处理过的查询请求和结果缓存起来,如果下一次有一模一样的请求过来,直接从缓存中查找结果就好了,就不用再傻呵呵的去底层的表中查找了。
当然,MySQL服务器并没有人聪明,如果两个查询请求在任何字符上的不同(例如:空格、注释),都会导致缓存不会命中。另外,如果查询请求中包含系统函数、存储函数、自定义变量、mysql库中的系统表,那这个请求就不会被缓存,以函数举例,可能同样的函数的两次调用会产生不一样的结果,比如函数NOW,每次调用都会产生最新的当前时间,如果在一个查询请求中调用了这个函数,那即使查询请求的文本信息都一样,那不同时间的两次查询也应该得到不同的结果,如果在第一次查询时就缓存了,那第二次查询的时候直接使用第一次查询的结果就是错误的!
不过既然是缓存,那就有它缓存失效的时候。MySQL的缓存系统会监测涉及到的每张表,只要该表的结构或者数据被修改,那与该表有关的缓存都会失效!
语法解析:如果缓存没有命中,接下来就需要进入正式的查询阶段了。首先客户端程序发送过来的请求只是一段文本而已,MySQL服务器程序首先要对这段文本做分析,判断请求的语法是否正确,然后从文本中要查询的表、各种查询条件都提取出来。
查询优化:根据语法解析,服务器程序获得到了需要的信息,比如查询列表是什么,表是哪个,搜索条件是什么等等,但光有这些是不够的,因为我们写的MySQL语句可能执行起来效率并不是很高,MySQL的优化程序会对我们的语句做一些优化,如外连接转换为内连接、表达式简化、子查询的转为连接、使用索引吧啦吧啦的一堆东西,这部分我们后边会详细唠叨,现在你只需要知道在MySQL服务器程序处理请求的过程中有这么一个步骤就好了。
3、存储引擎
截止到服务器程序完成了查询优化为止,还没有真正的去访问真实的数据表,MySQL把数据的存储和提取操作都封装到了一个叫存储引擎的模块里,我们知道表是由一行一行的记录组成的,但这只是一个逻辑上的概念,物理上如何表示记录,怎么从表中读取数据,怎么把数据写入具体的物理存储器上,这都是存储引擎负责的事情。为了实现不同的功能,MySQL提供了各式各样的存储引擎,不同存储引擎管理的表结构可能不同,采用的存取算法也可能不同。不过这些存储引擎都向上边的服务层提供统一的调用接口,也就是对于我们使用者来说,如果我们需要使用某个存储引擎提供的特定功能,只需要简单的切换表的存储引擎就可以了。
所以在服务器程序完成了查询优化后,只需调用底层存储引擎提供的调用接口,获取到数据后返回给客户端程序就好了。
二、InnoDB存储引擎
MYSQL的核心就是表存储引擎。引擎接口开源,可以自己定制功能。InnoDB就是一个非常出名 的第三方引擎。

InnoDB有多个内存块,组成一个大的内存池,负责如下工作:维护所有进程/线程需要访问的多个内部数据结构;缓存磁盘上的数据,方便快速的读取;重做日志缓冲....后台线程主要作用是负责刷新内存池中的数据,保证缓存池中的数据是最新的数据,并且将已经修改的数据刷新到磁盘文件。其中,何时刷新有算法策略,不一定是实时刷新的,因为有的时候访问量太大,实时刷新难度比较大。
1、后台线程
2、内存
四、InnoDB:Buffer Pool缓存池简介
先要了解文件系统:https://mp.weixin.qq.com/s/peP-vu6lSGYWEx0MCD8pGA
1、表空间的编号
我们在唠叨数据目录的时候就已经说过,InnoDB存储引擎是使用表空间来存储页的,表空间又可以被分为系统表空间和独立表空间。为了方便管理,每个表空间都会有一个4字节的编号,值得注意的一点是,系统表空间的编号始终为0,InnoDB也会根据一定规则给其他独立表空间也编上号~
所以,当我们查看或修改某个页的数据的时候,实际上需要同时知道表空间的编号和该页的编号,也就是表空间号 + 页号的组合才能定位到某一个具体的页。如果你有认真看前边唠叨InnoDB页结构的那篇文章,肯定记得每个页的编号也是占用4个字节,而在一个表空间内页的编号是不能重复的,4个字节是32个二进制位,也就是说:一个表空间最多拥有 2³² 个页,默认情况下一个页的大小为16KB,也就是说一个表空间最多存储 64TB 的数据~
2、缓存的重要性
所谓的表空间只不过是InnoDB对文件系统上一个或几个实际文件的抽象,我们的数据说到底还是存储在磁盘上的。但是各位也都知道,磁盘的速度慢的跟乌龟一样,怎么能配得上“快如风,疾如电”的CPU呢?所以将内存作为缓存也是无奈之举。MySQL服务器在处理客户端的请求时,当需要访问某个页的数据时,就会把完整的页的数据全部加载到内存中,也就是说即使我们只需要访问一个数据页的一条记录,那也需要先把整个页的数据加载到内存中。这是为了不必每次请求都去访问一下磁盘,那得多慢啊~
对某个页的访问类型分为两种,一种是只读访问,一种是写入访问。只读访问好办,就是把磁盘上的页加载到内存中读而已;而如果需要修改该页的数据就有点尴尬了,首先会把数据写到内存中的页中,然后在某个合适的时刻将修改过的页 同步 到磁盘上,同步的时候断电咋办?数据就丢了么?那支付宝或者微信支付的童鞋们还不得紧张死,天天祈祷神千万不要宕机,宕机的话好多人就要家破人亡了?当然不是了,凡是成熟的数据库系统都会有一套完整的机制来保证写入过程要么完整的完成,要么就把已经写入的数据恢复到之前没写的情况,总之不会家破人亡的~ 我们后边几篇文章的内容就是仔细唠叨这个过程是怎么实现的,哈哈,是不是有点儿小刺激~ 不过本篇文章作为先导篇,大家先得搞清楚这块缓存是个神马玩意儿,InnoDB是用啥方式来管理这块儿缓存的~
3、InnoDB的Buffer Pool
啥是个Buffer Pool
设计InnoDB的大叔为了缓存磁盘中的页,向操作系统申请了一片连续的内存,他们给这片内存起了个名,叫做Buffer Pool(中文名是缓存池),那它有多大呢?这个其实看我们机器的配置,如果你是土豪,你有512G内存,你分配个几百G作为Buffer Pool也可以啊,当然你要是没那么有钱,设小点也行呀~ 默认情况下Buffer Pool只有128M大小。当然如果你嫌弃这个太大或者太小,可以在启动服务器的时候配置innodb_buffer_pool_size参数的值,它表示Buffer Pool的大小,就像这样:
[server]
innodb_buffer_pool_size = 268435456
其中,268435456的单位是字节,也就是我指定Buffer Pool的大小为256M。需要注意的是,Buffer Pool也不能太小,最小值为5M(当小于该值时会自动设置成5M)。
Buffer Pool内部组成
我们已经知道这个Buffer Pool其实是一片连续的内存空间,那现在就面临这个问题了:怎么将磁盘上的页缓存到内存中的Buffer Pool中呢?直接把需要缓存的页向Buffer Pool里一个一个往里怼么?不不不,为了更好的管理这些被缓存的页,InnoDB为每一个缓存页都创建了一些所谓的控制信息,这些控制信息包括该页所属的表空间编号、页号、页在Buffer Pool中的地址,一些锁信息以及LSN信息(锁和LSN我们之后会具体唠叨,现在可以先忽略),当然还有一些别的控制信息,我们这就不全唠叨一遍了,挑重要的说嘛哈哈~
每个缓存页对应的控制信息占用的内存大小是相同的,我们就把每个页对应的控制信息占用的一块内存称为一个控制块吧,控制块和缓存页是一一对应的,它们都被存放到 Buffer Pool 中,其中控制块被存放到 Buffer Pool 的前边,缓存页被存放到 Buffer Pool 后边,所以整个Buffer Pool对应的内存空间看起来就是这样的:

咦?控制块和缓存页之间的那个碎片是个什么玩意儿?你想想啊,每一个控制块都对应一个缓存页,那在分配足够多的控制块和缓存页后,可能剩余的那点儿空间不够一对控制块和缓存页的大小,自然就用不到喽,这个用不到的那点儿内存空间就被称为碎片了。当然,如果你把Buffer Pool的大小设置的刚刚好的话,也可能不会产生碎片~
4、FREE链表的管理
当我们最初启动MySQL服务器的时候,需要完成对Buffer Pool的初始化过程,就是分配Buffer Pool的内存空间,把它划分成若干对控制块和缓存页。但是此时并没有真实的磁盘页被缓存到Buffer Pool中(因为还没有用到),之后随着程序的运行,会不断的有磁盘上的页被缓存到Buffer Pool中,那么问题来了,从磁盘上读取一个页到Buffer Pool中的时候该放到哪个缓存页的位置呢?或者说怎么区分Buffer Pool中哪些缓存页是空闲的,哪些已经被使用了呢?我们最好在某个地方记录一下哪些页是可用的,我们可以把所有空闲的页包装成一个节点组成一个链表,这个链表也可以被称作Free链表(或者说空闲链表)。因为刚刚完成初始化的Buffer Pool中所有的缓存页都是空闲的,所以每一个缓存页都会被加入到Free链表中,假设该Buffer Pool中可容纳的缓存页数量为n,那增加了Free链表的效果图就是这样的:
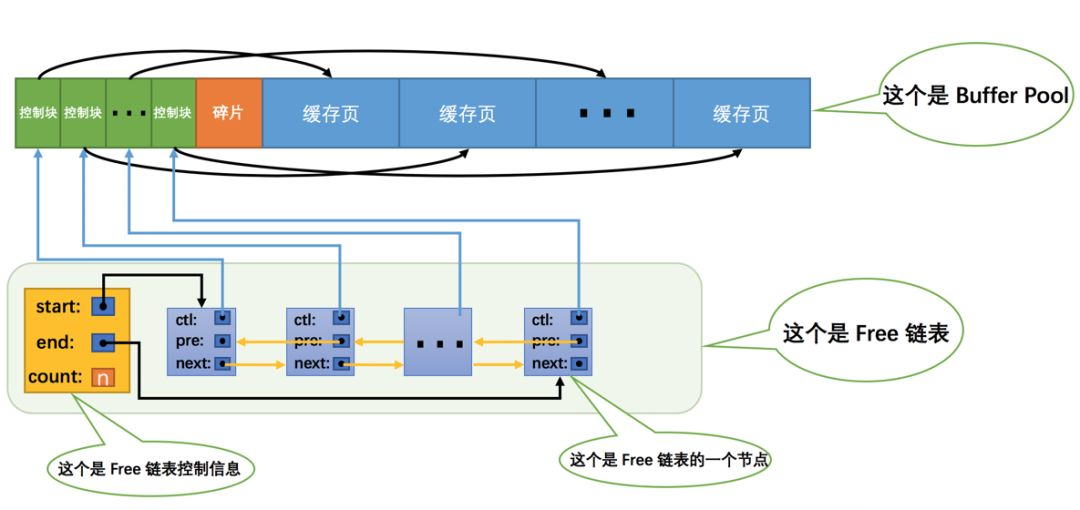
从图中可以看出,我们为了管理好这个Free链表,特意为这个链表定义了一个控制信息,里边儿包含着链表的头节点地址,尾节点地址,以及当前链表中节点的数量等信息。我们在每个Free链表的节点中都记录了某个缓存页控制块的地址,而每个缓存页控制块都记录着对应的缓存页地址,所以相当于每个Free链表节点都对应一个空闲的缓存页。
有了这个Free链表事儿就好办了,每当需要从磁盘中加载一个页到Buffer Pool中时,就从Free链表中取一个空闲的缓存页,并且把该缓存页对应的控制块的信息填上,然后把该缓存页对应的Free链表节点从链表中移除,表示该缓存页已经被使用了~
5、缓存页的哈希处理
我们前边说过,当我们需要访问某个页中的数据时,就会把该页加载到Buffer Pool中,如果该页已经在Buffer Pool中的话直接使用就可以了。那么问题也就来了,我们怎么知道该页在不在Buffer Pool中呢?难不成需要依次遍历Buffer Pool中各个缓存页么?一个Buffer Pool中的缓存页这么多都遍历完岂不是要累死?
再回头想想,我们其实是根据表空间号 + 页号来定位一个页的,也就相当于表空间号 + 页号是一个key,缓存页就是对应的value,怎么通过一个key来快速找着一个value呢?哈哈,那肯定是哈希表喽~
所以我们可以用表空间号 + 页号作为key,缓存页作为value创建一个哈希表,在需要访问某个页的数据时,先从哈希表中根据表空间号 + 页号看看有没有对应的缓存页,如果有,直接使用该缓存页就好,如果没有,那就从Free链表中选一个空闲的缓存页,然后把磁盘中对应的页加载到该缓存页的位置。
6、FLU链表的管理
如果我们修改了Buffer Pool中某个缓存页的数据,那它就和磁盘上的页不一致了,这样的缓存页也被称为脏页(英文名:dirty page)。当然,最简单的做法就是每发生一次修改就立即同步到磁盘上对应的页上,但是频繁的往磁盘中写数据会严重的影响程序的性能(毕竟磁盘慢的像乌龟一样)。所以每次修改缓存页后,我们并不着急立即把修改同步到磁盘上,而是在未来的某个时间点进行同步,至于这个同步的时间点我们后边的文章会特别详细的说明的,现在先不用管哈~
但是如果不立即同步到磁盘的话,那之后再同步的时候我们怎么知道Buffer Pool中哪些页是脏页,哪些页从来没被修改过呢?总不能把所有的缓存页都同步到磁盘上吧,假如Buffer Pool被设置的很大,比方说300G,那一次性同步这么多数据岂不是要慢死!所以,我们不得不再创建一个存储脏页的链表,凡是修改过的缓存页都会被包装成一个节点加入到这个链表中,因为这个链表中的页都是需要被刷新到磁盘上的,所以也叫FLUSH链表,有时候也会被简写为FLU链表。链表的构造和Free链表差不多,这就不赘述了。
LRU链表的管理
缓存不够的窘境
Buffer Pool对应的内存大小毕竟是有限的,如果需要缓存的页占用的内存大小超过了Buffer Pool大小,也就是Free链表中已经没有多余的空闲缓存页的时候岂不是很尴尬,发生了这样的事儿该咋办?当然是把某些旧的缓存页从Buffer Pool中移除,然后再把新的页放进来喽~ 那么问题来了,移除哪些缓存页呢?
为了回答这个问题,我们还需要回到我们设立Buffer Pool的初衷,我们就是想减少和磁盘的I/O交互,最好每次在访问某个页的时候它都已经被缓存到Buffer Pool中了。假设我们一共访问了n次页,那么被访问的页已经在缓存中的次数除以n就是所谓的缓存命中率,我们的期望就是让缓存命中率越高越好~ 从这个角度出发,回想一下我们的微信聊天列表,排在前边的都是最近很频繁使用的,排在后边的自然就是最近很少使用的,假如列表能容纳下的联系人有限,你是会把最近很频繁使用的留下还是最近很少使用的留下呢?废话,当然是留下最近很频繁使用的了~
简单的LRU链表
管理Buffer Pool的缓存页其实也是这个道理,当Buffer Pool中不再有空闲的缓存页时,就需要淘汰掉部分最近很少使用的缓存页。不过,我们怎么知道哪些缓存页最近频繁使用,哪些最近很少使用呢?呵呵,神奇的链表再一次派上了用场,我们可以再创建一个链表,由于这个链表是为了按照最近最少使用的原则去淘汰缓存页的,所以这个链表可以被称为LRU链表(Least Recently Used)。当我们需要访问某个页时,可以这样处理LRU链表:
-
如果该页不在
Buffer Pool中,在把该页从磁盘加载到Buffer Pool中的缓存页时,就把该缓存页包装成节点塞到链表的头部。 -
如果该页在
Buffer Pool中,则直接把该页对应的LRU链表节点移动到链表的头部。
也就是说:只要我们使用到某个缓存页,就把该缓存页调整到LRU链表的头部,这样LRU链表尾部就是最近最少使用的缓存页喽~ 所以当Buffer Pool中的空闲缓存页使用完时,到LRU链表的尾部找些缓存页淘汰就OK啦,真简单,啧啧…
划分区域的LRU链表
高兴的太早了,上边的这个简单的LRU链表用了没多长时间就发现问题了,有的小伙伴可能会写一些需要扫描全表的查询语句(比如没有建立合适的索引或者压根儿没有WHERE子句的查询),扫描全表意味着什么?意味着将访问到该表所在的所有数据页!假设这个表中记录非常多的话,那该表会占用特别多的页,当需要访问这些页时,会把它们统统都加载到Buffer Pool中,这也就意味着吧唧一下,Buffer Pool中的所有数据页都被换了一次血,其他查询语句在执行时又得执行一次从磁盘加载到Buffer Pool的操作。而这种全表扫描的语句执行的频率也不高,每次执行都要把Buffer Pool中的缓存页换一次血,这严重的影响到其他查询对 Buffer Pool 的使用,严重的降低了 缓存命中率 !这能忍么?这肯定不能忍啊!再想想办法,把这个LRU链表按照一定比例分成两截,分别是:
-
一部分存储使用频率非常高的缓存页,所以也叫做
热数据,或者称young区域。 -
另一部分存储使用频率不是很高的缓存页,所以也叫做
冷数据,或者称old区域。
为了方便大家理解,我们把示意图做了简化,各位领会精神就好:
大家要特别注意一个事儿:我们是按照某个比例将 LRU链表 分成两半的,不是某些节点固定是young区域的,某些节点固定式old区域的,随着程序的运行,某个节点所属的区域也可能发生变化。所以把一个完整的LRU链表分成了young和old两个部分之后,修改LRU链表的方式也就可以变一变了:
-
如果某个页第一次从磁盘加载到
Buffer Pool中,则放到old区域的头部。 -
如果该页已经在
Buffer Pool中,则将其放到young区域的头部,也就是LRU链表的头部。
这样搞有啥好处呢?在没有空闲的缓存页时,我们可以从old区域中淘汰一些页,而不影响young区域中的缓存页。这样全表扫描的页虽然也会进入Buffer Pool中,但是由于首次缓存时只会放到old区域,young区域不受影响,也就是只会对Buffer Pool造成部分换血,而不是全部换血,这在一定程度上降低了全表扫描对Buffer Pool的缓存命中率的影响。
那这个划分成两截的比例怎么确定呢?对于InnoDB存储引擎来说,我们可以通过查看系统变量innodb_old_blocks_pct的值来确定old区域在LRU链表中所占的比例,比方说这样:
mysql> SHOW VARIABLES LIKE 'innodb_old_blocks_pct';
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| innodb_old_blocks_pct | 37 |
+-----------------------+-------+
1 row in set (0.01 sec)
mysql>
从结果可以看出来,默认情况下,old区域在LRU链表中所占的比例是37%,也就是说old区域大约占LRU链表的3/8。这个比例我们是可以设置的,我们可以在启动时修改innodb_old_blocks_pct参数来控制old区域在LRU链表中所占的比例,比方说这样修改配置文件:
[server]
innodb_old_blocks_pct = 40
这样我们在启动服务器后,old区域占LRU链表的比例就是40%。当然,如果在服务器运行期间,我们也可以修改这个系统变量的值,不过需要注意的是,这个系统变量属于全局变量,一经修改,会对所有客户端生效,所以我们只能这样修改:
SET GLOBAL innodb_old_blocks_pct = 40;
更进一步优化LRU链表
LRU链表这就说完了么?没有,早着呢~ 首次从磁盘上加载到Buffer Pool的页会放到old区域,第二次访问该页的时候便会被放到young区域,那如果在很短的时间内进行了两次全表扫描操作岂不是会把old区域的节点都移动到young区域了,那相当于又把Buffer Pool给破坏掉了,咋办?
我们可以设置一个间隔时间,当第二次访问old区域的某个缓存页时(该缓存页没有被淘汰掉),如果距离上一次访问的时间小于这个时间,那就不把这个缓存页放到young区域,这个过程称之为page not made young;而如果距离上一次访问的时间不小于这个时间,那就把这个缓存页放到young区域,这个过程称之为page made young。这样就可以降低在短时间内有大量全表扫描对Buffer Pool的缓存命中率的影响。InnoDB中这个间隔时间是由系统变量innodb_old_blocks_time控制的,你看:
mysql> SHOW VARIABLES LIKE 'innodb_old_blocks_time';
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| innodb_old_blocks_time | 1000 |
+------------------------+-------+
1 row in set (0.01 sec)
mysql>
在我的电脑上innodb_old_blocks_time的值是1000,它的单位是毫秒,也就意味着如果在1秒内发生了多次全表扫描,这些在old区域的页也不会被加入到young区域的~ 当然,像innodb_old_blocks_pct一样,我们也可以在服务器启动或运行时设置innodb_old_blocks_time的值,这里就不赘述了,你自己试试吧~
还有一个问题,对于young区域的缓存页来说,我们每次访问一个缓存页就要把它移动到LRU链表的头部,这样开销是不是太大啦,毕竟在young区域的缓存页都是热点数据,也就是可能被经常访问的,这样频繁的对LRU链表进行节点移动操作是不是不太好啊?是的,为了解决这个问题其实我们还可以提出一些优化策略,比如只有被访问的缓存页其于young区域的1/4(这个值可调节)之后,才会被移动到LRU链表头部,这样就可以降低调整LRU链表的频率,从而提升性能。
还有木有什么别的针对LRU链表的优化措施呢?当然有啊,你要是好好学,写篇论文,写本书都不是问题,可是我们毕竟是一个介绍MySQL基础知识的文章,再说多了篇幅就受不了了,适可而止,想了解更多的优化知识,自己去看源码或者更多关于LRU链表的知识喽~ 另外,不同的大公司,可能会针对自己的业务对LRU链表进行自己的定制,优化是无穷尽的,但是千万别忘了我们的初心:尽量提高 Buffer Pool 的缓存命中率。
其他的一些链表
为了更好的管理Buffer Pool中的缓存页,除了我们上边提到的一些措施,设计InnoDB的大叔们还引进了其他的一些链表,比如Unzip LRU链表用于管理解压页,Zip Clean链表用于管理存储没有被解压的压缩页,Zip Free链表用来管理被压缩的页等等,反正是为了更好的管理这个Buffer Pool引入了各种链表,构造和我们介绍的链表都差不多,具体的使用方式就不啰嗦了,大家有兴趣深究的再去找些更深的书或者直接看源代码吧~
InnoDB中对各种列表的处理
上边对各种链表的介绍,只是从我们初学者的学习原理的角度去看的,设计InnoDB的大叔在真正实现这些链表上又下了一番苦功夫,都是为了节省内存和挺高性能而做的努力。比方说
-
实际的链表节点并不是独立于
Buffer Pool的而存在的,而是被放在了缓存页控制块中。 -
虽然为了不同的目的我们提出了很多的链表,但是每个缓存页控制块其实只有一个
LRU链表节点和一个通用的链表节点。为了节省内存,针对缓存页所处于的不同状态,对缓存页控制块的通用链表节点进行了复用,比方说在该缓存页空闲时,该节点代表Free链表的节点;比方说该缓存页被修改时,该节点代表FLU链表的节点,吧啦吧啦~
当然,如果你看不懂我上边在说啥(本来也没打算让你看懂),那就不用看了,这只是设计InnoDB的大叔在针对具体的场景做的优化方案,待你真正动手去设计一个存储引擎时,你才会考虑如何更好地实现我们上边的这些原理,现在可以先跳过,设计InnoDB的大叔们为了更好地实现Buffer Pool,使用了好几万行代码,要说清楚这些,怎么也得好几篇文章了,我没那个时间,等以后牛逼有空了,我再来仔细说清楚InnoDB针对这些链表实现的具体细节~
多个Buffer Pool实例
我们上边说过,Buffer Pool本质是InnoDB向操作系统申请的一块连续的内存空间,在多线程环境下,为了保护缓存页可能会对缓存页进行加锁处理啥的(具体怎么锁我们后边的文章会唠叨),在Buffer Pool特别大而且多线程并发访问特别高的情况下,单一的Buffer Pool可能会影响请求的处理速度。所以在Buffer Pool特别大的时候,我们可以把它们拆分成若干个小的Buffer Pool,每个Buffer Pool都称为一个实例,它们都是独立的,独立的去申请内存空间,独立的管理各种链表,独立的吧啦吧啦,所以在多线程并发访问时并不会相互影响,从而提高并发处理能力。我们可以在服务器启动的时候通过设置innodb_buffer_pool_instances的值来修改Buffer Pool的个数,比方说这样:
[server]
innodb_buffer_pool_instances = 2
这样就表明我们要创建2个Buffer Pool。那每个Buffer Pool实际占多少内存空间呢?其实使用这个公式算出来的:
innodb_buffer_pool_size/innodb_buffer_pool_instances
也就是总共的大小除以个数,结果就是每个Buffer Pool占用的大小。
不过也不是说Buffer Pool实例创建的越多越好,分别管理各个Buffer Pool也是需要性能开销的,设计InnoDB的大叔们规定:Buffer Pool 的大小小于1G的时候设置多个实例是无效的,InnoDB会默认把innodb_buffer_pool_instances 的值修改为1。而我们鼓励在Buffer Pool大小大于1G的时候设置多个Buffer Pool实例。
InnoDB中查看Buffer Pool的状态信息
作为MySQL的管理人员,我们有时候需要查看一下Buffer Pool中的情况,设计InnoDB的大叔们给我们提供了这样的查询请求,就像这样(为了突出重点,我们只把输出中关于Buffer Pool的部分提取了出来):
(...省略前边的许多状态)
----------------------
BUFFER POOL AND MEMORY
----------------------
Total memory allocated 13218349056;
Dictionary memory allocated 4014231
Buffer pool size 786432
Free buffers 8174
Database pages 710576
Old database pages 262143
Modified db pages 124941
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 6195930012, not young 78247510485
108.18 youngs/s, 226.15 non-youngs/s
Pages read 2748866728, created 29217873, written 4845680877
160.77 reads/s, 3.80 creates/s, 190.16 writes/s
Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
LRU len: 710576, unzip_LRU len: 118
I/O sum[134264]:cur[144], unzip sum[16]:cur[0]
--------------
(...省略后边的许多状态)
虽然这里头的参数我们并不能全部看懂,但是有一些还是很眼熟的:
-
Buffer pool size代表该Buffer Pool可以容纳多少缓存页,注意,单位是页! -
Free buffers代表当前Buffer Pool还有多少空闲缓存页,也就是Free链表中还有多少个节点。 -
Database pages代表LRU链表中的页的数量,包含young和old两个区域的节点数量。 -
Old database pages代表LRU链表old区域的节点数量。 -
Modified db pages代表脏页数量,也就是FLU链表中节点的数量。 -
Pages made young代表从old区域移动到young区域的节点数量,not young代表old区域没有移动到young区域就被淘汰的节点数量。后边跟着移动的速率。 -
Pages read、created、written代表innodb读取,创建,写入了多少页。后别跟着读取、创建、写入的速率。 -
LRU len代表LRU链表中节点的数量。 -
unzip_LRU代表非16K大小的页的数量,这些非16K大小的页都是被unzip_LRU链表管理的,我们也没多唠叨它,看不懂就忽略它吧~
其他的参数我们目前不需要理解,之后遇到的话会仔细说的~
总结
-
我们可以通过
表空间号 + 页号的组合可以定位到某一个具体的页。 -
磁盘太慢,用内存作为缓存很有必要。
-
Buffer Pool本质上是InnoDB向操作系统申请的一段连续的内存空间,可以通过innodb_buffer_pool_size来调整它的大小。 -
Buffer Pool由控制块和缓存页组成,每个控制块和缓存页都是一一对应的,在填充足够多的控制块和缓存页的组合后,Buffer Pool剩余的空间可能产生不够填充一组控制块和缓存页,这部分空间不能被使用,也被称为碎片。 -
InnoDB使用了许多链表来管理Buffer Pool。 -
Free链表中每一个节点都代表一个空闲的缓存页,在将磁盘中的页加载到Buffer Pool时,会从Free链表中寻找空闲的缓存页。 -
为了快速定位某个页是否被加载到
Buffer Pool,使用表空间号 + 页号作为key,缓存页作为value,建立哈希表。 -
在
Buffer Pool中被修改的页称为脏页,脏页并不是立即刷新,而是被加入到FLU链表中,待之后的某个时刻同步到磁盘上。 -
LRU链表分为young和old两个区域,可以通过innodb_old_blocks_pct来调节old区域所占的比例。首次从磁盘上加载到Buffer Pool的页会被放到old区域的头部,如果在innodb_old_blocks_time间隔时间后该页该页没有被淘汰掉并且仍在old区域时,会把它放到LRU链表的头部,也就是young区域的头部。在Buffer Pool没有可用的空闲缓存页时,会首先淘汰掉old区域的一些页。 -
我们可以通过指定
innodb_buffer_pool_instances来控制Buffer Pool的个数,每个Buffer Pool中都有各自独立的链表,互不干扰。 -
可以用下边的命令查看
Buffer Pool的状态信息:SHOW ENGINE INNODB STATUS\G

