ELK入门
1.什么是ELK?
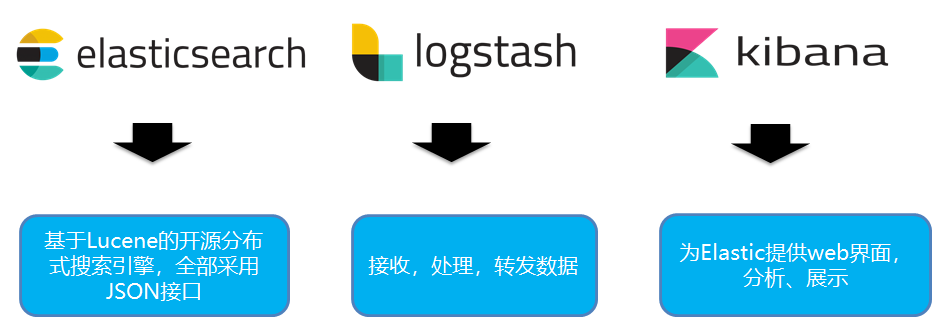
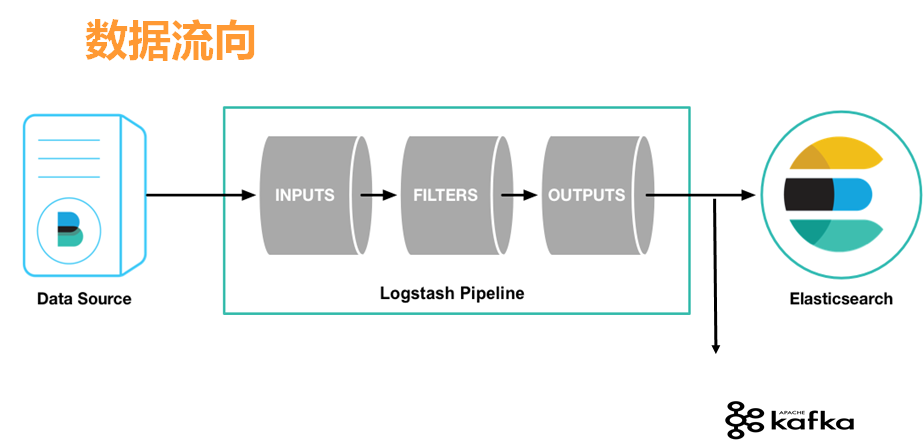
ELK日志采集流程:
-
Filebeat负责从各个数据源采集数据,发送到Logstash
-
Logstash将数据再写入Elasticsearch
-
Elasticsearch对采集的数据创建索引
-
Kinbana对数据以图表形式进行展现
2.ELK可以解决那些问题?
-
统计web日志中的某一时段的IP排行榜,URL、浏览器分布
-
查询数据可视化展示,无需繁琐的操作即可
-
整合现有的运维自动化平台可以轻易对接WAF、日志告警系统等
-
支持目前最流行的机器学习框架,更好的为智能运维而服务
3.日志收集工具
-
rsyslog
-
syslog-ng
-
flume
-
logtash
-
filebeat
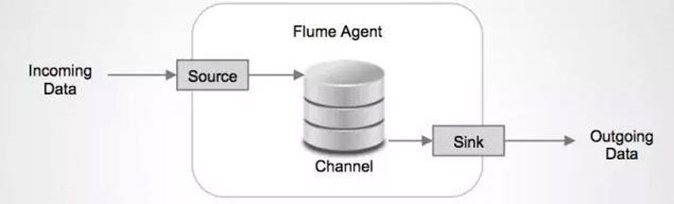
(1)Flume
Flume 是Apache旗下使用JRuby来构建,所以依赖Java运行环境。Flume本身最初设计的目的是为了把数据传入HDFS中(并不是为了采集日志而设计,这和Logstash有根本的区别)。

(2)Logstash
Logstash 是一款强大的数据处理工具,它可以实现实时数据传输,格式处理,格式化输出,还有强大的插件功能,常用于日志处理。
它可以统一过滤来自不同源的数据,并按照开发者的制定的规范输出到目的地。
Logstash整体架构
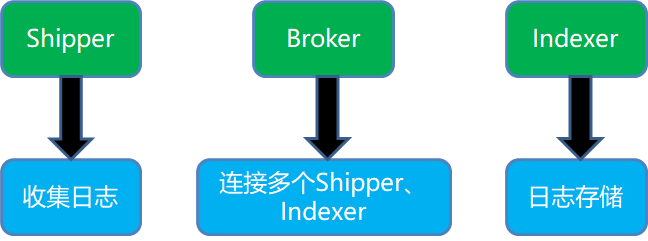
-
Shipper:日志收集者。负责监控本地日志文件的变化,及时把日志文件的最新内容收集起来,输出到Redis暂存。
-
Broker:日志Hub,用来连接多个Shipper和多个Indexer。
-
Indexer:日志存储者。负责从Redis接收日志,写入到本地文件。
Logstash架构数据流图
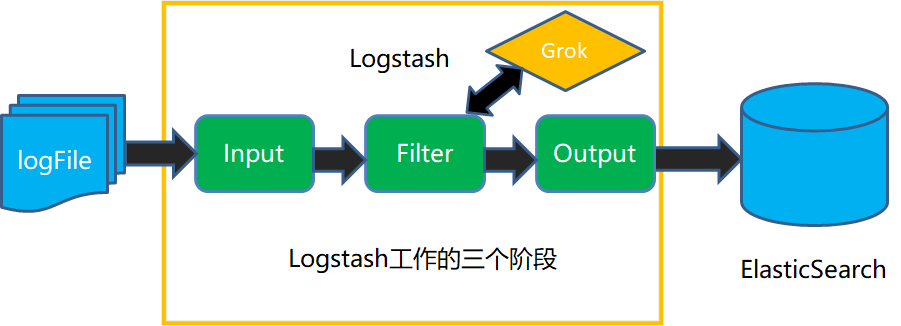
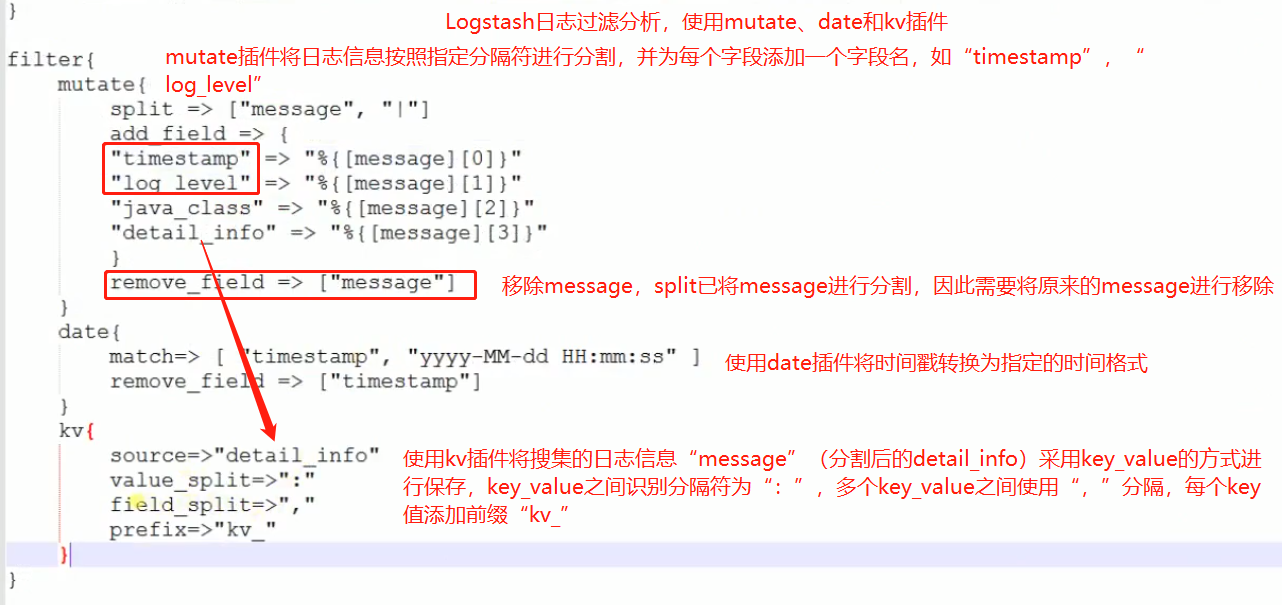
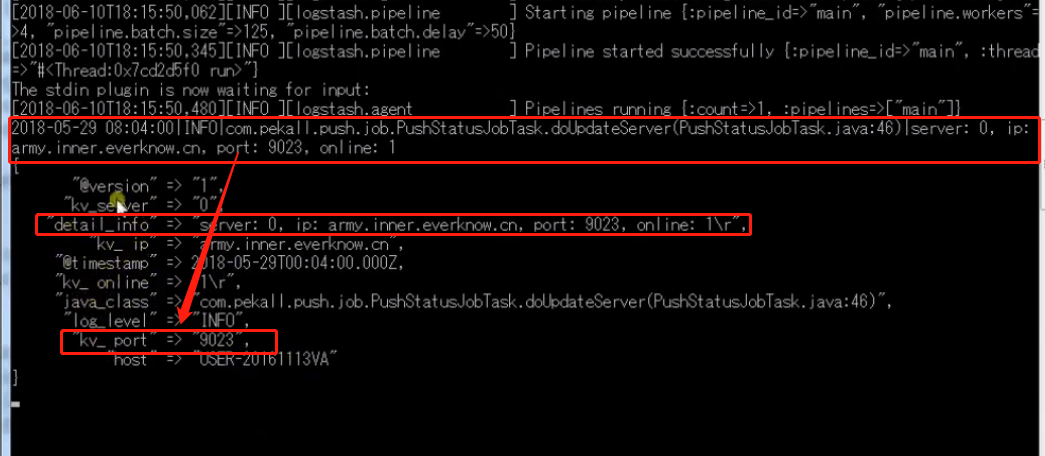
Logstash配置文件解析
-
input输入插件:file,stdin,filebeat,redis,ftp等
-
filter过滤插件:grok,date,mutate等
-
output输出插件:标准输出stdout,file,Elasticsearch,redis,ftp等。
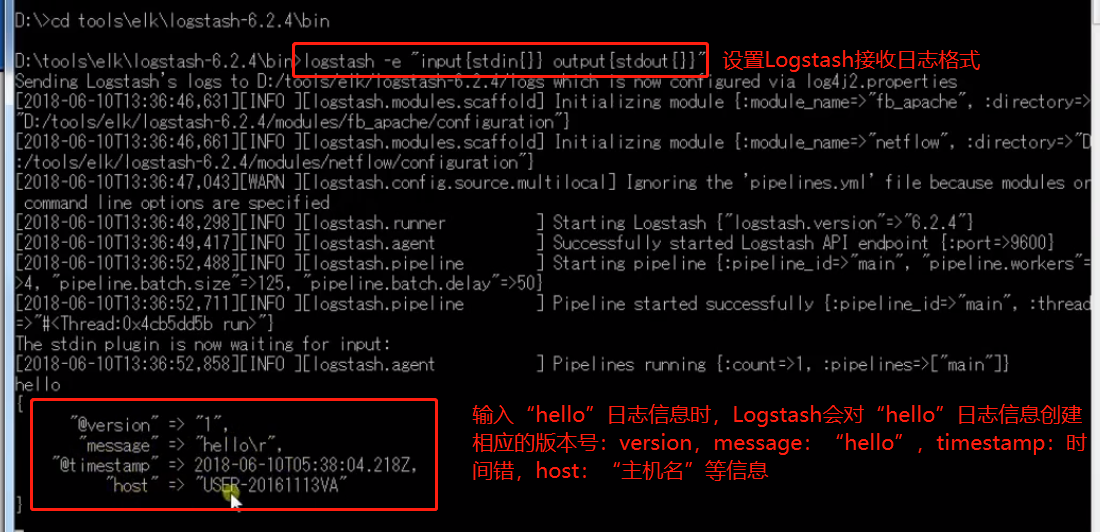
点击查看代码
input{
beats {
port => 5044
}
}
filter{
grok {
match => { "message" => "%{IP:client} .* \[%{DATA:timestamp}\] \"%{WORD:
verb} %{URIPATHPARAM:request} .*\/%{GREEDYDATA:httpversion}\" %{NUMBER:
response} %{NUMBER:duration:int} \"%{DATA:referrer}\" \"%{DATA:agent}\"" }
}
#04/Jan/2015:05:13:45 +0000
date{
match=> [ "timestamp", "dd/MMM/yyyy:HH:mm:ss Z" ]
remove_field => [stimestamp]
}
}
output{
elasticsearch {
hosts => "http://localhost:9200"
index => "logstash-hello2"
}
stdout{}
}hosts:配置Elasticsearch对应的IP地址,端口号默认9200
index:指定存储在Elasticsearch中的数据库名称,logstash是Elasticsearch默认的数据库模板,所以index必须是“logstash-*”的格式。如果指定为其他格式,则需手动在Elasticsearch创建模板。
Logstash支持数据类型
-
bool : debug=>true
-
string : host=>”hostname”
-
number : port => 514
-
array : match=>[“datetime”,”unix”:”ISO8601”]
-
hash : option =>{key1=>”value1”,key2=>”value2”}
(3)Filebeat
Filebeat是一个开源的日志文件收集器,主要用于获取日志文件,并把他们发送到Logstash或Elasticsearch中。Filebeat一般安装在需要收集日志的服务器上,filebeat会监控日志目录或者指定的日志文件,追踪读取这些文件(追踪文件的变化,不停的读),并且转发这些信息到es或者logstash中存放。
Filebeat日志收集架构

Filebeat执行命令:./filebeat -e -c filebeat.yml -d "publish"
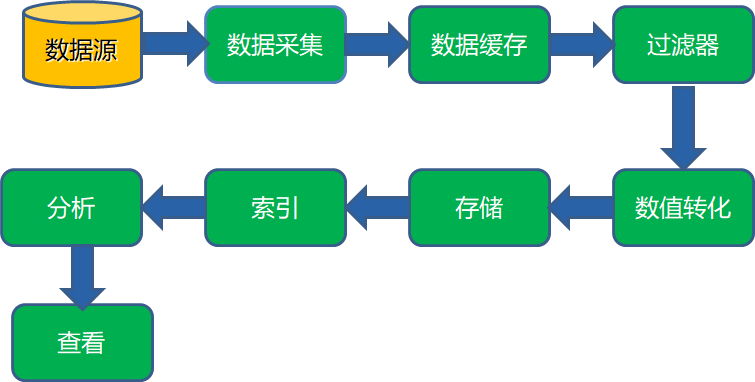
4.数据采集通用模型
5.Kibana日志查询
-
全文本搜索:在搜索框中直接输入搜索文字,可带通配符,比如:abc或 *abc*
-
按字段搜索:device:“按字段搜索”
-
按字段组合搜索AND:time:“2021-11-14” AND text:“test”
-
按字段组合搜索OR:time:“2021-11-14” OR text:“test”
-
按字段组合搜索NOT:time:“2021-11-14” NOT text:“test”
-
分组搜索:time:(“2021-11-14” or “2021-11-15”) AND text:“test”
-
数字比较:num:100,num:>100,num:<100
******************************************************************************************************************************************************
******************************************************************************************************************************************************