

数据库基础
1.1 一个肤浅的定义
什么是数据库?这是一个很难回答的问题,经典的教科书往往都是从信息、数据说起,直到数据库。这里我想直接给出一个不准确的,肤浅的定义(这也是最早的FoxBASE时代,绝大多数人对数据库的认识):
【定义】:(1)一个库便是一张二维表格,表由表头(字段)与表的内容(记录)组成。(2)建立在该表上的操作主要包括:检索、插入、删除、更新。
这个定义与现有数据库存在很大差异,但并不影响作为这部分内容的开端。从上面的定义中我们可以看到,数据库中记录信息的表与建立在表上的操作是密不可分的。另外,常见的库操作有四种:检索、插入、删除、更新。
1.2 遭遇异常
在这个原始的概念驱使下,很多人就开始了数据库的设计历程,让我们来看这样一个例子:
【要求】:构建一用来描述在校学生的数据库,要求记录的学生如下属性:学号、姓名、年龄、系别。
很多人会觉得这太简单了,在上面的数据库概念的指引下,我们可以很容易的给出如下设计:
表 1-1 初始的数据库设计
| 学号 | 姓名 | 年龄 | 系别 |
| 1 | 张三 | 20 | 经管系 |
| 2 | 李四 | 22 | 机械系 |
| 3 | 王五 | 21 | 经管系 |
| 4 | 赵六 | 23 | 自动化 |
该设计很好的将学号、姓名、年龄、系别属性记录了下来,并且支持检索、插入、删除、更新操作。然而这是不是一个完美的设计呢?在讨论之前让我们先回答几个问题(尽管很多人对以下几个问题嗤之以鼻)。
问题1:学校有几个系?(答:3个)
问题2:经管系有几个学生?(答:2个)
每次讲到这里,总有很多学生对此不屑一顾,当我问到"你们是怎么知道的?"时候,很多人只是说"看出来的呗。"其实这两个问题不是用"看出来"就可以解释清楚的。最好的回答应当是"数出来的"(晕!)。问题1的答案是通过去掉系别列中的重复行后,数一数剩余的行数得到的。问题2的答案是通过数一数系别为经管系的行数得到的。那好,我们先把这两种解题方法放在这里以备后面查阅。
让我们再来看看建立在该表上的几种操作,检索已经说过了,这里不再提,我们看看插入、删除以及更新操作,这里有如下几个要求:
1、国家刚刚审批通过允许学校开设一个新的系"艺术系",然而艺术系的学生要等到两个月后才能招进来。
2、李四毕业了,不再是"在校学生"了,将其删除。
3、经管系现要更名成"经济管理学院"。
呵呵,我们已经开始遭遇"插入异常"、"删除异常"、"更新异常"了。如何插入一个没有学生的系呢?这是一个两难的问题。由于学校有艺术系,为了能够在检索"学校有几个系"时检索到4,我们不得不插入一行,该行的系别字段记录上"艺术系",而艺术系没有学生,所以我们还得让学号、姓名、年龄字段空着(如表 1 2所示)。
表 1-2 插入艺术系
| 学号 | 姓名 | 年龄 | 系别 |
| 1 | 张三 | 20 | 经管系 |
| 2 | 李四 | 22 | 机械系 |
| 3 | 王五 | 21 | 经管系 |
| 4 | 赵六 | 23 | 自动化 |
| (空) | (空) | (空) | 艺术系 |
此时如果我再问"艺术系有几个学生"时,恐怕有些人的脸色就不那么好看了吧。这回通过数一数系别为艺术系的行数就无法得到准确的艺术系人数答案了。因此解题逻辑不得不也发生变化:如果人数为1,判断学号、姓名、年龄是否为空,如果为空则为0人,否则为1人。你觉得这回的检索还那么简单吗?
再来看删除操作也不是想删就删了。如果你把李四一行删除,你会惊奇的发现机械系没有了!所以也不得不修改删除逻辑,如果某系只剩下最后一条记录,就不能删除了,而起清空学号、姓名、年龄字段的内容,这么做好吗?
更新操作似乎也存在一些问题。在上面的设计种,经管系更名需要修改两行数据,假设刚刚修改完第一行,正要修改下一行,停电了,死机了,反正机器无法正常运转。当你下次开机后数一数有几个系呢?
1.3 解决异常
上面的问题有没有解决的办法呢?有!数据库规范化理论给出了我们解决的办法(关于第一范式、第二范式、第三范式等内容可以参考《数据库原理》),那就是"拆分"。我们可以通过将上表拆分成如下两表的形式解除异常:
表 1-3 学生库
| 学号 | 姓名 | 年龄 | 系别代号 |
| 1 | 张三 | 20 | 1 |
| 2 | 李四 | 22 | 2 |
| 3 | 王五 | 21 | 1 |
| 4 | 赵六 | 23 | 3 |
表 1-4 系别库
| 系别代号 | 系别 |
| 1 | 经管系 |
| 2 | 机械系 |
| 3 | 自动化 |
这两张表通过系别代号关联起来,保留了原有信息,但该设计消除了上面提到的异常。读者可以自行尝试在当前设计下重新执行上面的检索、插入、删除与更新操作,看看还有没有异常发生?
1.4 数据表述与认知矛盾
从上面的例子我们可以看到,为了消除在数据库操作过程中出现的插入异常、删除异常以及更新异常,我们必须利用数据库规范化理论对数据库的设计加以规范处理。但如果校长希望你提供一份学生名单时,你提供给校长的该是什么呢?毫无疑问,校长最希望见到的是表 1-1,而绝非表 1-3与表 1-4。因此这就引出了新的问题:数据库的使用者与数据库的设计者在对数据的认知上往往是不一致的。数据库的使用者希望看到的是直观、易懂的数据,而数据库的设计者希望设计出来的方案易于修改、便于扩充,容易进行系统开发。因此,真正的数据库设计必须很好的解决这两者之间的矛盾。现代的数据库都提供了众多的方法解决这个问题(将在1.1.5中给予说明)。我们这里不妨再看一个认知矛盾的例子。
假如需要通过数据库记录一树型结构的数据(就像Windows中的文件夹),我们如何来用二维表格加以描述呢?用户当然希望看到的是一棵树,而数据库设计者面临的问题是如何将树二维表格化。这个工作我们可以通过如下的映射关系实现:
图 1-1 需要表述的树型结构
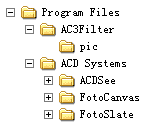
表 1-5 使用二维表格表述树形结构
| ID | ParentID | FoderName |
| 1 | 1 | Program Files |
| 2 | 1 | AC3Filter |
| 3 | 2 | pic |
| 4 | 1 | ACD Systems |
| 5 | 4 | ACDSee |
| 6 | 4 | FotoCanvas |
| 7 | 4 | FotoSlate |
我们可以看到,表 1-5利用ID字段与ParentID字段描述了文件夹间的父子关系,进而通过二维表格记录下了树型结构的内容。
总之,数据认知矛盾是不可避免的,通过各种办法,我们总能让数据库的使用者与数据库的设计者在数据表述问题上相互平衡。我们至少可以通过两种途径解决这种认知矛盾,一方面可以借助现有数据库提供的功能(例如视图等,见1.1.5)解决,另一方面我们可以设计专门的数据结构解决(例如上面树型结构记录的问题)。
1.5 数据库该是什么样?
既然在1.1.1中给出的数据库定义存在很大的问题,那么一个真正的数据库应当是什么样的呢?我们需要数据库为我们提供什么样的服务?这些服务又是通过什么形式表现出来呢?
要说清楚这一点,还是让我们从"在校学生"这个例子谈起。上面分析到为了消除各种异常,我们通过拆分的方式将原有设计一分为二,两表间通过系别代号相互关联。尽管异常没有了,但也带来了一系列麻烦。
1.5.1 视图
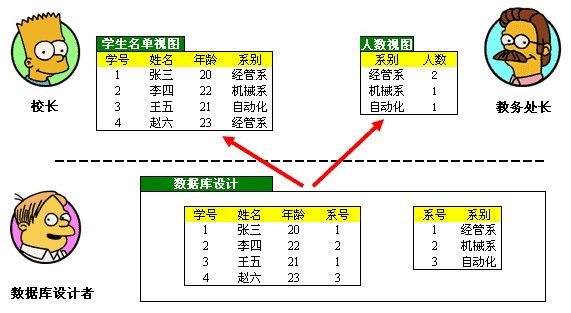
首先,数据表述上的认知矛盾使得校长在得到他的报表前不得不对数据进行一下处理,重新将两表"缝合"起来。如果教务处想了解每个系的学生人数时,就又需要另外一种数据"缝合"方式。为了让众口不再难调,数据库中引入了"视图"的概念,允许用户从不同的角度观察数据,得到自己想要的结果。"横看成岭侧成峰",山(数据库的物理设计方案)永远不会改变,通过不同的视角(视图),我们可以看到不同的数据表现形式。这就是视图的一个非常重要的作用。当然视图提供的功能远不止这些,作为初始了解就先说到这种程度。
《数据库原理》里面提到的三级模式、两级映象其实说的就是这层关系。我们抛开三级模式中的内模式(物理实现),单看外模式与模式。模式只有一个,那就是数据库设计者设计出来的表,而外模式可以有多个,每个外模式可以理解成一个"视图",想怎么看就怎么看(如图 1-2)。这么做的同时也实现的数据的"独立性",数据库的设计者可以专心的设计数据库逻辑结构,并将设计方案从不同视角的视图中独立出来。
图 1-2 通过视图解决认知矛盾
1.5.2 完整性约束
然而事情并不是象预期般进展顺利,数据库设计者在消除了各种异常的以及数据认知矛盾的困扰后,往往又陷入"数据不一致"的问题陷阱中。数据库设计者会发现数据插入、删除、更新操作不象想象中那样随心所欲,必须时刻小心的避开数据不一致的暗礁。
例如,一个不负责任的数据录入人员很可能将下面两条记录输入到数据库中:系别表(系号:3,系别:艺术系);学生表(学号:4,姓名:和二,年龄25,系号:9)。
在这里,新插入的艺术系与自动化系出现了相同的系号,而学生表与系别表靠此系号字段进行关联,于是问题就出来了,我们无法正常检索艺术系有多少人,也无法判断某系号为3的学生究竟是哪个系的。因此必须确保系别表中的系号能够唯一标识某一行记录。我们管这样的字段叫做"主键"(很不严格、不准确的定义,但我们可以暂时如此理解,详细的定义可以参考《数据库原理》)。主键的存在是为了确保实现"实体完整性" ,其取值有两点要求:(1)不允许为空;(2)不允许重复。因此,数据库需要提供某种限制性策略防止违反"实体完整性"的事情发生。不同数据库实现的手段各不相同,Visual FoxPro中我们可以在该字段上创建一个主索引或候选索引,在SQL Server中,我们可以为索引添加唯一性约束条件等。
再来看看插入的学生记录,我们给该学生的系号字段输入了数值9,而在系别表中根本没有系号为9的系别,于是该学生便"无家可归"了。为了防止类似事情发生,要求数据库还要提供某些机制,确保学生表中的系号和系别表中的系号存在某种对应关系,防止不一致现象出现。这种机制是靠实现"参照完整性" 实现的。学生表(从表)中的系号(外键)需要参照系别表(主表)中的系号(主键)。
参照完整性中所指的主表与从表不一定非是两个不同的表,也可以是同一张表。例如表 1-6:
表 1-6一张表内的参照完整性
| 学号 | 姓名 | 班长学号 |
| 1 | 张三 | 2 |
| 2 | 李四 | 2 |
| 3 | 王五 | 2 |
| 4 | 赵六 | 2 |
班长学号与学号间就构成了外键和主键的关系。班长学号的取值只能有两种情况,(1)为空,表示该班还没有选出班长。(2)为学号字段中的某个值,表示该班班长取自本班学生。
另外,在1.1.4数据表述与认知矛盾一节中,我们介绍了如何用二维表来表述一树形结构,仔细观察表 1-5,其中的ID字段与ParentID字段间也构成了主键与外键的关系,ParentID的取值必须来自ID列。
在实际应用过程中,参照完整性往往可以抽象归纳成几条原则,这里给出Visual FoxPro中的参照完整性约束供参考(以学生、系别表为例):
- 删除规则:
级联删除:如果删除系别表中经管系,则自动将学生表中系别为经管系的学生删除。
限制删除:如果发现学生表中有学生是经管系的,则禁止删除系别表中的经管系。
- 更新规则
级联更新:若更改系别表中的经管系系号,则学生表中对应经管系学生的系号也一并更改。
限制更新:如果学生表中有学生是经管系的,则禁止更改系别表中经管系的系号。
- 插入规则
限制插入:禁止在学生表中插入一条记录,该记录的系号在系别表中没有。
除了了解参照完整性约束条件外,我们还应当注意应用参照完整性后数据处理的先后顺序。仍然以学生表和系别表为例子,假设用户为两表间建立了"限制删除、限制更新、限制插入"的参照完整性规则,那么当删除经管系及所有学生时,要先删学生表,再删系别表,更新也是相同,当插入艺术系及其学生时,要先插入系别表再插入学生表。此时两表操作的先后顺序是不同的。请大家完成【实验 1-1 Visual FoxPro中参照完整性的设置及数据操作顺序】步骤1、2、3、4以加深理解。
 实验 1-1 Visual FoxPro中参照完整性的设置及数据操作顺序
实验 1-1 Visual FoxPro中参照完整性的设置及数据操作顺序
1.5.3 触发器与存储过程
在实验 1-1中,我们实现了在Visual FoxPro中设置参照完整性,到底是什么神奇的力量使得级联删除得以实现的呢?在Visual FoxPro中是靠触发器与存储过程实现的(不同数据库使用的技术不尽相同)。触发器通常分为插入触发器、删除触发器和更新触发器,通过对这些触发器的设置可以确保在数据库表执行插入、删除、更新时自动执行某些代码。Visual FoxPro中,这些代码存贮在数据库中,我们管它们叫做"存储过程"。我们暂时可以这样理解存储过程:它是一段存储在数据库中、经过预先编译的,可被外部直接调用的程序代码。随着我们内容的逐步深入,对存储过程的认识还会进一步加深。请大家完成【实验 1-1 Visual FoxPro中参照完整性的设置及数据操作顺序】步骤5。
1.5.4 约束条件
上面我们学习了完整性约束中的实体完整性约束与参照完整性约束,还有一项叫做用户定义完整性约束,顾名思义,就是用户自行定义的完整性约束条件。在数据库中通常提供了两类用户定义完整性约束,(1)字段级完整性约束,(2)记录级完整性约束。
在我们进行库表的设计过程中,我们可以定义字段类型、字段长度与小数位数,但这对某些应用而言是不够的。例如某字段"年龄"。通常我们使用整形作为该字段的数据类型,然而"-5"、"1000"都是整数,可显然不是年龄,如何确保在字段级别上设置完整性呢?这就靠字段级完整性约束实现了。通过字段完整性约束,我们可以设置年龄字段中的数据必须是0到150之间的整数,以确保年龄数据的正确性。请大家完成【实验 1-2 在Visual FoxPro中实现字段级完整性约束】以加深对字段完整性的认识。
字段完整性仅仅对某个字段的数据进行完整性校验,如果多个字段中存在相互关联,字段级约束就显得力不从心了。例如某表中包含着"年龄"和"工龄"两个字段,年龄的字段约束为0~150间的整数,工龄的约束条件是0~60间的整数。我们完全可以插入一条记录,年龄为10而工龄为30。尽管这些数据并不违反单独某个字段上的约束条件,但一个10岁的小孩怎么会有30年工龄呢?为了保证字段间数据完整一致,就得靠记录级完整性约束实现了。通过设定约束条件"工龄<=年龄-18"就可以确保这两个字段间数据的一致性。请大家完成【实验 1-3 在Visual FoxPro中实现记录级完整性约束】以加深对字段完整性的认识。
1.5.5 数据库事务处理
上面说了很多关于数据库应该具备的功能,也许有人早就新存疑惑了:"在参照完整性中有个概念叫级联更新,也就是如果把系别代号改了,学生表中对应的系别代号也自动改,问题是如果改到一半时停电了,那岂不是数据出现不一致问题,更新异常又来了吗?"。
确实如此,如果没有一套有效的机制防止类似事情发生,数据库仍然面临很大的威胁。现有的数据库基本都支持"事务",那么什么是事务呢?简单的说,就是确保"同时成功则成功,任何一个失败则失败"的一种机制。一个事务往往包括三种动作行为:开始事务(Begin Transaction),提交事务(Commit)和回滚(Rollback)。从开始事务到提交事务过程中所发生的一切数据库修改要么同时成功(被Commit,固化在数据库中),要么一个失败,大家同时回复原有状态(Rollback,数据库回复到事务开始时的状态)。一个典型的事务程序可能如下:
当执行BeginTransaction时,我们可以认为是给数据库照了张快照,记录当前状态。然后开始更新系别表与学生表,如果都能正确执行,则提交修改,快照也就没有什么用处了。但如果其中任何一个表出现更新异常,程序将落入catch段中,我们在这里对数据库进行回滚,还原到快照时的状态。
出处:http://www.cnblogs.com/huangcong/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

