

分布式事务相关
1.有遇到分布式事务?
在RPC远程调用过程中,A调用B服务的接口后,A接口报错,无法回滚B接口的事务,最终造成A事务回滚,B事务没有回滚。
注:在单体架构中,如果存在多数据源,每个数据源都有自己独立的事务管理器,那么这时也会存在多数据源事务管理分布式事务的问题。解决方案:jta+Atomikos
2.分布式事务解决方案?
- 单体架构多数据源项目,采用jta+Atomikos ;
- 采用MQ的形式解决,采用最终一致性的思想。
- Alibaba的Seata解决,基于2PC,不适用于和外部接口保证分布式事务问题。

2PC,3PC属于业务代码无入侵方案,都是基于XA规范实现的,TCC,Sega属于业务入侵的方案,2PC,3PC设计的一些角色(XA规范的角色)组成如下:
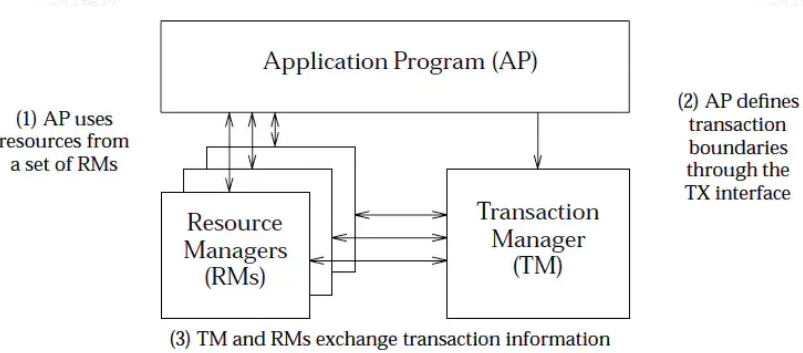
- AP:应用程序本身
- RM:资源管理器,也就是事务的参与者,大部分情况下指数据库,一个分布式事务往往涉及到多个RM。
- TM:事务管理器,负责管理全局事务,分配事务的唯一标识,负责事务的回滚,提交等。
2PC(2阶段提交)###
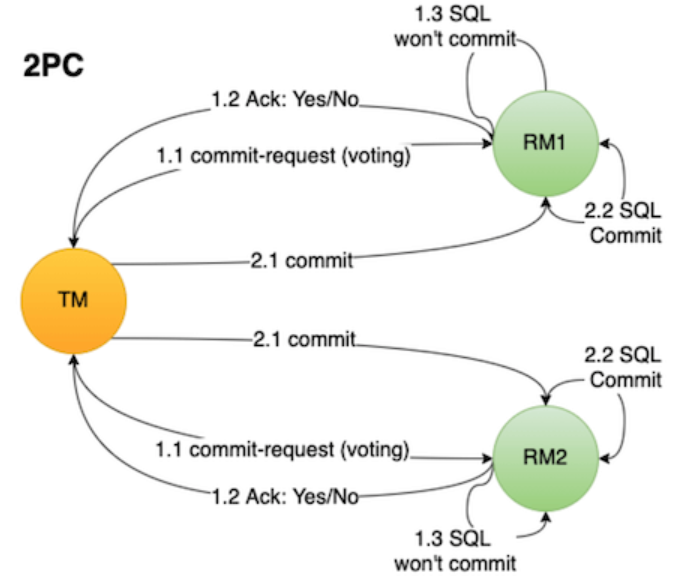
2pc将事务分为2各阶段:##准备阶段##和##提交阶段##
-
准备阶段:
1.事务管理器(TM)向所有涉及到的资源管理器(事务参与者RM)发送消息询问是否可以执行事务操作,并等待其回复。
2.资源管理器(RM)接收到消息后,开始向执行本地数据库预操作,比如写redolog/undolog日志,此时并不会提交事务。
3.资源管理器(RM)如果事务操作执行成功,就向事务管理器(TM)回复ack标识已就绪,否则就回复ack未就绪标识。 -
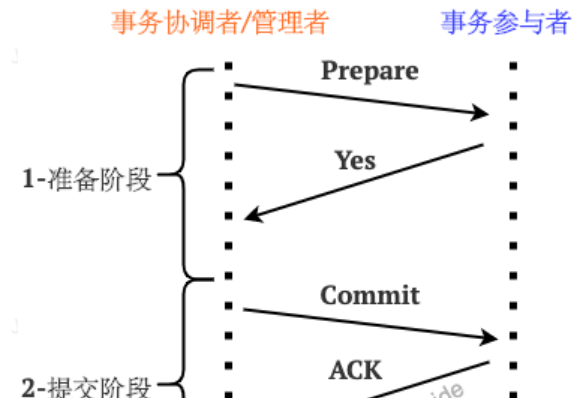
提交阶段
提交阶段的核心是询问事务的参与者是否提交本地事务成功。
当所有的事务参与者都是就绪状态的话:
1.事务管理器(TM)向所有参与者发送消息,标识可以提交事务(Commit消息)。
2.资源管理器(RM)接收到消息后提交本地事务操作,执行完之后释放整个事务期间占有的资源。
3.资源管理器(RM)发送“事务已提交”的消息(ACK消息)。
4.事务管理器(TM)接收到所有事务参与者的ACK消息之后,分布式事务结束。
-
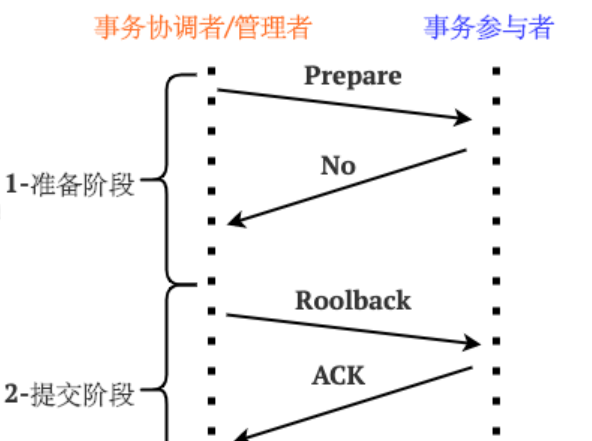
当任一事务参与者的状态是“未就绪”时:
1.TM向所有的参与者发送回滚消息(RollBack消息)。
2.RM接收到RollBack消息之后执行本地数据库回滚操作。
3.RM回复已回滚的ACK消息。
4.TM接受到所有的RM的ack消息后,中断事务。
总结:
1.准备阶段主要是测试RM能否执行本地事务(这一步并不会提交事务!!)。
2.提交阶段****TM会根据准备阶段中RM的ACK消息来决定是执行数据的回滚还是提交操作。
3.提交阶段之后一定会结束当前的分布式事务。
2PC优点:
1.实现简单,各大主流数据库都有自己的实现。
2.针对的是数据的强一致性。
2PC缺点:
1.同步阻塞:在事务参与者提交事务之前会一直占有相关资源,其他事务要操作资源的话就会阻塞。
2.数据不一致:由于网络问题或者TM宕机或造成数据不一致的情况,如在第二阶段提交阶段时,网络问题导致部分参与者接受不到commit/rollback的话会造成数据不一致。
3.单点问题:如果TM在准备阶段完成之后挂掉了,那个参与者会一直卡在提交阶段。
3PC(3阶段提交)
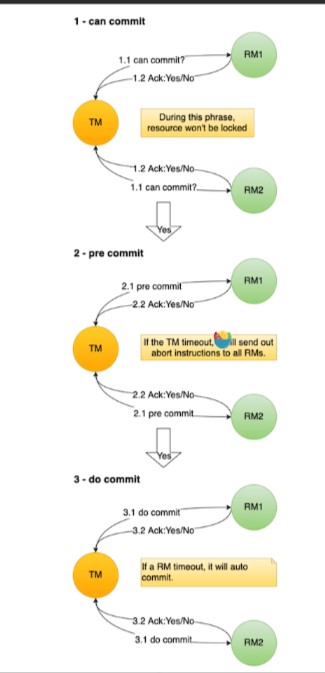
3pc是在2pc的基础上做了一些优化,将2pc的准备阶段做了细分,分为准备阶段(canCommit)和预提交阶段(preCommit)
-
准备阶段(canCommit):这一步不会执行事务操作,只是像资源管理器(RM)发送准备请求,询问事务的参与者能否执行本地事务操作,RM回复y或者n或者超时。若果任一RM回复n,则中断事务操作(像所有参与者发送Abort消息),否则进入预提交阶段。
-
预提交阶段(preCommit):TM向所有的RM发送预提交请求,RM收到消息后执行本地事务操作,如写undolog/redolog操作。
如果RM执行预提交事务成功,则返回ACK,如果任一RM返回N,则中断事务操作(向所有参与者发送Abort消息),否则进入执行事务提交阶段。 -
执行事务提交阶段(doCommit):开始执行真正的事务提交,TM向所有的RM发送事务提交请求,RM收到消息后开始正式的提交任务,并释放占用的资源。
若任一RM没有正确的提交事务,就中断事务,TM向所有的RM发送Abort消息,RM收到消息后开始本地事务回滚。
3pc的改进:
在事务管理器和事务的参与者之间引入了超时机制,在一定时间内没有收到事务参与者的消息,就会默认失败,避免事务参与者一直阻塞占用资源,2pc中只有事务管理器才有超时机制,当事务参与者长时间与事务管理器没有通讯的情况下,就会一直阻塞无法释放资源。
TCC(try,confirm,cancel)补偿机制
TCC分为三个阶段:
1.Try尝试阶段:尝试执行,完成业务检查,并预留好业务资源。
2.Confirm确认阶段:确认执行,当所有事务参与者的try阶段都成功执行才会执行confirm,confirm阶段会处理try阶段预留的业务资源,否则就会执行cancel。
3.Cancel取消阶段:取消执行,释放try阶段预留的业务资源。
每个阶段由业务代码控制,避免长事务,性能更好。一般情况下使用TCC机制来实现时,需要我们自己来实现Try,Confirm,Cancel三个方法,来达到最终一致性。
-
Try阶段阶段如果出现问题,可以执行Cancel,如果Confirm或者Cancel阶段失败了会怎么办?
TCC会记录事务日志并持久化到某种存储介质上,如本地文件,数据库,zookeeper等,事务日志包含了事务的执行状态,如执行成功或者失败,以及在哪一步失败,如果发现是Confirm或者Cancel阶段失败的话,会进行重试,重试次数通常为6次,如果超过6次还没成功,就需要人工介入。 -
TCC和2PC/3PC的区别?
1.TCC对代码有侵入,2PC/3PC对代码无侵入。
2.TCC追求的是最终一致性,不会一直持有业务资源的锁,2PC/3PC追求的是强一致性,在两阶段提交的整个过程中,会一直持有数据库的锁。
Seata分布式事务解决方案:
Seata为用户提供了AT,TCC,SAGA和XA事务模式,以AT事务模式分支举例:
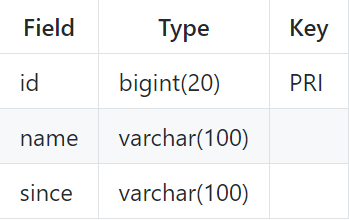
业务表:product:
AT分支事务逻辑:
update product set name = 'GTS' where name = 'TXC';
sql```
- 第一阶段:
1.解析sql:得到sql的类型(update),表(product),条件(name = 'TXC');
2.查询前置镜像,根据解析的信息,生成查询语句,定位数据;
select id, name, since from product where name = 'TXC';
sql```
得到的前置镜像:
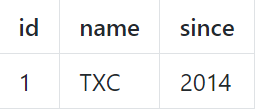
3.执行业务SQL,更新记录的name为'GTS'。
4.查询后置镜像,根据前置镜像的结果,通过主键定位数据。
select id, name, since from product where id = 1;
得到后置镜像:
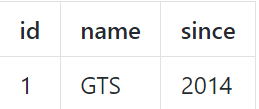
5.插入回滚日志:将后置镜像数据以及业务信息的sql组成一条回滚日志,插入到undo_log表中。
{
"branchId": 641789253,
"undoItems": [{
"afterImage": {
"rows": [{
"fields": [{
"name": "id",
"type": 4,
"value": 1
}, {
"name": "name",
"type": 12,
"value": "GTS"
}, {
"name": "since",
"type": 12,
"value": "2014"
}]
}],
"tableName": "product"
},
"beforeImage": {
"rows": [{
"fields": [{
"name": "id",
"type": 4,
"value": 1
}, {
"name": "name",
"type": 12,
"value": "TXC"
}, {
"name": "since",
"type": 12,
"value": "2014"
}]
}],
"tableName": "product"
},
"sqlType": "UPDATE"
}],
"xid": "xid:xxx"
}
6.提交前,向TC注册分支,申请product表中主键id=1的全局锁。
7.本地事务提交。
8.本地事务提交结果上报给TC。
- 两阶段-回滚
1.收到TC的回滚请求,本地开启一个事务。
2.通过XID和Branch ID查找相应的un_dolog记录。
3.拿undolog中的后置镜像与当前数据比较,如果不同,说明当前数据已被修改,这种情况需要根据配置的策略来处理。
4.根据undolog中的前置镜像和业务sql来生成回滚语句。
update product set name = 'TXC' where id = 1;
5.提交本地事务,并将回滚结果上报给TC。

