
查找表中多余的重复记录(多个字段),并删除表中多余的重复记录(多个字段),只留有id最小的记录
有一个数据表userinfo,包含userid,username,userlevel字段,其中userid是唯一的,username,userlevel可能重复。
SET NAMES utf8mb4; SET FOREIGN_KEY_CHECKS = 0; -- ---------------------------- -- Table structure for userinfo -- ---------------------------- DROP TABLE IF EXISTS `userinfo`; CREATE TABLE `userinfo` ( `userid` int NOT NULL AUTO_INCREMENT, `username` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `userlevel` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, PRIMARY KEY (`userid`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; -- ---------------------------- -- Records of userinfo -- ---------------------------- INSERT INTO `userinfo` VALUES (1, '老王', '四级'); INSERT INTO `userinfo` VALUES (2, '老王', '四级'); INSERT INTO `userinfo` VALUES (3, '老李', '二级'); INSERT INTO `userinfo` VALUES (4, '老李', '五级'); INSERT INTO `userinfo` VALUES (5, '老张', '二级'); INSERT INTO `userinfo` VALUES (6, '老张', '二级'); INSERT INTO `userinfo` VALUES (7, '老张', '二级'); INSERT INTO `userinfo` VALUES (8, '小张', '四级'); SET FOREIGN_KEY_CHECKS = 1;
请写出sql查询语句,把username和userlevel重复的记录全部取出来。要求返回记录集
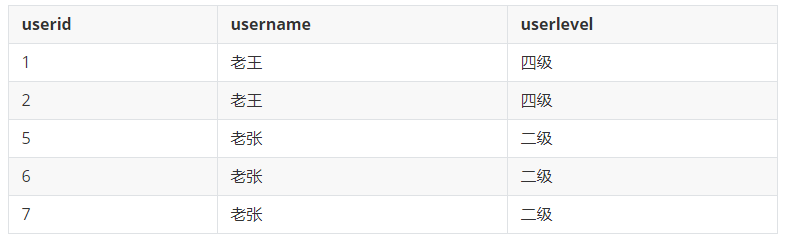
select * from userinfo a where (a.userlevel,a.username) in (select userlevel,username from userinfo group by userlevel,username having count(userid) > 1);
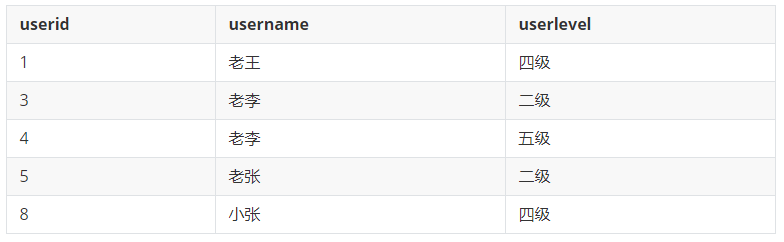
delete from userinfo where userid in (select a.userid from (select userid from userinfo where (userinfo.userlevel,userinfo.username) in (select userlevel,username from userinfo group by userlevel,username having count(userid) > 1) and userinfo.userid not in (select min(userid) from userinfo group by userlevel,username having count(userid)>1)) a);
必须要有一个中间表 a 不然会出现错误:
You can't specify target table for update in FROM clause.
含义:不能在同一表中查询的数据作为同一表的更新数据。(在同一语句中)
也就是说将select出的结果再通过中间表select一遍,这样就规避了错误。

