矩阵快速幂
快速幂。
快速幂顾名思义,就是快速算某个数的多少次幂。其时间复杂度为 O(log₂N), 与朴素的O(N)相比效率有了极大的提高。
以求a的n次方为例子。
原理:
把n转换成2进制数
该2进制数第i位的权为(2i−1)
例如
a11=a23+21+20
因为,1的二进制是1 0 1 1,也就是11=23∗1+22∗0+21∗1+20∗1
快速幂可以用位运算这个强大的工具实现。
n & 1,就是取n的二进制的最末尾,事实上, 就是相当于n % 2。
n = n >> 1 就是右移一位,就是n = n / 2.
重要的两句就是这样了。
其实,思路就是,本来是a乘a一直乘n次,现在就变成了a = a * a,然后n = n / 2.an=(a∗a)n/2,然后重复下去,本来要进行n次的运算,现在就变成了log2n次了。这就是快速幂啦。
下面是计算an%k的一个模板。
int quickpow(int a,int n,int k)
{
int b = 1;
while (n)
{
if (n & 1)
b = (b*a)%k;
n = n >> 1 ;
a = (a*a)%k;
}
return b;
} 矩阵快速幂
两矩阵相乘,朴素算法的复杂度是O(N3)。
如果求一次矩阵的M次幂,按朴素的写法就是O(N3∗M)。
既然是求幂,不免想到快速幂取模的算法,在快速幂中,ab%m 的复杂度可以降到O(logb)。
如果矩阵相乘是不是也可以实现O(N3∗logM)的时间复杂度呢?答案是肯定的。
思想
矩阵快速幂的思想就是跟数的快速幂一样,假如我们要求2的11次方,我们可以把 11 写成 1+2+8 ,也就是20+21+23。那么把一个O(n)的时间复杂度降到了log(n)
。
比如说,我们要求一个矩阵A的11次方,那就变成A11=A(20+21+23) 。
参照上面的写法:
while(n)
{
if(n & 1)
res = res * A;
n = n >> 1;
A = A * A;
}不过这里的乘法是矩阵乘法而不是数的乘法。
//Mat a是矩阵,k是指数
int MATRIX(Mat a, int k)
{
Mat TEM;
for(int i = 0; i < n; i++)
for(int j = 0; j < n; j++)
TEM.matrix[i][j] = (i == j);//初始化为单位矩阵,任何矩阵乘以单位矩阵,其值不改变。
while(k)
{
if(k & 1)
TEM = TEM * A;
k = k >> 1;
A = A * A;
}
return TEM;
}Fibonacci 2

这是题目,斐波那契的超大计算,用递归是一定超时的了。所以要用速度更快的方法。这里的矩阵快速幂就可以用上了。
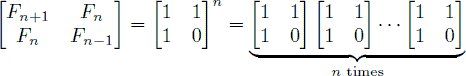
从个公式,我们可以知道,就算Fn,可以用A的n次方来计算。
其中A=[1110](3)
#include <iostream>
#include <cstdio>
#include<cmath>
using namespace std;
const long long MOD = pow(10,9) + 7;
struct matrix
{
int m[2][2];
}ans, base;
//定义矩阵乘法
matrix multi(matrix a, matrix b)
{
matrix tmp;
for(int i = 0; i < 2; ++i)
{
for(int j = 0; j < 2; ++j)
{
tmp.m[i][j] = 0;
for(int k = 0; k < 2; ++k)
tmp.m[i][j] = (tmp.m[i][j] + a.m[i][k] * b.m[k][j]) % MOD;
}
}
return tmp;
}
int fast_mod(int n) // 求矩阵 base 的 n 次幂
{
base.m[0][0] = base.m[0][1] = base.m[1][0] = 1;
base.m[1][1] = 0;
ans.m[0][0] = ans.m[1][1] = 1; // ans 初始化为单位矩阵
ans.m[0][1] = ans.m[1][0] = 0;
while(n)
{
if(n & 1)
{
ans = multi(ans, base);
}
base = multi(base, base);
n >>= 1;
}
return ans.m[0][1];
}
int main()
{
int n;
//scanf比cin快
while(scanf("%d", &n) && n != EOF)
{
printf("%d\n", fast_mod(n));
}
return 0;
}
 浙公网安备 33010602011771号
浙公网安备 33010602011771号