from sklearn import datasets
iris = datasets.load_iris()
from sklearn.naive_bayes import GaussianNB #高斯
gnb =GaussianNB() #构造
pred =gnb.fit(iris.data,iris.target) #拟合
y_pred =pred.predict(iris.data) #预测
print(iris.data.shape[0],(iris.target !=y_pred).sum())
from sklearn import datasets
iris = datasets.load_iris()
from sklearn.naive_bayes import BernoulliNB #贝叶斯模型
gnb =BernoulliNB() #构造
pred =gnb.fit(iris.data,iris.target) #拟合
y_pred =pred.predict(iris.data) #预测
print(iris.data.shape[0],(iris.target !=y_pred).sum())
from sklearn import datasets
iris = datasets.load_iris()
from sklearn.naive_bayes import MultinomialNB #多项式模型
gnb =MultinomialNB() #构造
pred =gnb.fit(iris.data,iris.target) #拟合
y_pred =pred.predict(iris.data) #预测
print(iris.data.shape[0],(iris.target !=y_pred).sum())
from sklearn.naive_bayes import GaussianNB ##交叉验证(高斯)
from sklearn.model_selection import cross_val_score
gnb =GaussianNB()
scores= cross_val_score(gnb,iris.data,iris.target,cv=10)
print("Acouracy:%.3f"%scores.mean())
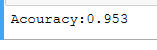
from sklearn.naive_bayes import GaussianNB ##交叉验证(高斯)
from sklearn.model_selection import cross_val_score
gnb =GaussianNB()
scores= cross_val_score(gnb,iris.data,iris.target,cv=10)
print("Acouracy:%.3f"%scores.mean())
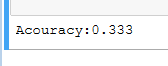
from sklearn.naive_bayes import MultinomialNB ##交叉验证(多项式)
from sklearn.model_selection import cross_val_score
gnb =MultinomialNB()
scores= cross_val_score(gnb,iris.data,iris.target,cv=10)
print("Acouracy:%.3f"%scores.mean())
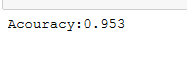
import csv
file_path = r"D:\SMSSPamCollection.txt"
sms=open(file_path,'r',encoding='utf-8')
sms_data=[]
sms_label=[]
csv_reader=csv.reader(sms,delimiter='\t')
for line in csv_reader:
sms_label.append(line[0])
sms_data.append(line[1])
sms.close()
sms_data

