*** stack smashing detected ***: ./server terminated
该类错误是修改了返回指针,一般是由于
1. 数组越界赋值。(数组没有边界检查)int a[8]; a[8],a[9],a[-1]。。都能正常编译,连接,运行时可能出错。
2.使用 strcpy等不安全(不带长度检测的函数),char a[1], char *b="aaa"; strcpy(a,b);
局部变量(函数内的变量)存在栈中,应为栈是先下(低地址)生长的,故 函数返回指针 要比局部变量的地址高,像类似的a[8]之类的就有机会访问到 函数返回指针了。
首先运行第一个程序:
#include “string.h”
void fun1(const char *str)
{
char buffer[5];
strcpy((char*)buffer, (char*)str);
}
int main()
{
fun1(”AAAAAAAAAAAAAAAAAAAAAAAAA”);
}
程序执行结果是“段错误”。用GDB调试,在从fun1函数返回时出现“Cannot access memory at address 0×41414145”的错误提示,这大致符合期望。但有一点搞不明白的是被改写的返回地址是’AAAA’,即应该是0×41414141才对,实际情况 怎么会多了4个字节 (0×41414145)?
这个程序是由于返回地址无效导致错误,那么我就写一个有效的地址上去吧。运行第二个程序:
void fun1()
{
int i;
const char buffer[] = “111111111″;
for (i = 0; i < 20; i++)
*((int*)(buffer+i)) = (int)buffer;
}
int main()
{
fun1();
}
程序的返回地址被改写成“有效”的地址“buffer”,只是内容确实无效的指令“11111111”,结果程序的运行结果是:
*** stack smashing detected ***: ./a.out terminated
GCC的缓冲区溢出保护
通过查阅资料知道,GCC有一种针对缓冲区溢出的保护机制,可通过选项“-fno-stack-protector”来将其关闭。实验中出现的错误信息,就正好是检测到缓冲区溢出而导致的错误信息。见出错程序的汇编代码:
<fun1>:
push %ebp
mov %esp,%ebp
sub $0×28,%esp
mov %gs:0×14,%eax
mov %eax,-0×4(%ebp) ; 把%gs:0×14保存到-0×4(%ebp) 中
xor %eax,%eax
movl $0×31313131,-0xe(%ebp)
movl $0×31313131,-0xa(%ebp)
movw $0×31,-0×6(%ebp)
movl $0×0,-0×14(%ebp)
jmp 8048423 <fun1+0×3f>
lea -0xe(%ebp),%edx
mov -0×14(%ebp),%eax
add %eax,%edx
lea -0xe(%ebp),%eax
mov %eax,(%edx)
addl $0×1,-0×14(%ebp)
cmpl $0×13,-0×14(%ebp)
jle 8048412 <fun1+0×2e>
mov -0×4(%ebp),%eax
xor %gs:0×14,%eax ; 检查%gs:0×14与-0×4(%ebp)的值是否相同
je 804843a <fun1+0×56> ; 如果相同则退出函数
call 804831c <__stack_chk_fail@plt> ; 检测到缓冲区溢出,跳转到__stack_chk_fail@plt函数
leave
ret
<main>:
lea 0×4(%esp),%ecx
and $0xfffffff0,%esp
pushl -0×4(%ecx)
push %ebp
mov %esp,%ebp
push %ecx
sub $0×4,%esp ; 在栈上分配4字节空间。在进入函数之后,其地址相当于-0×4(%ebp)
add $0×4,%esp
pop %ecx
pop %ebp
lea -0×4(%ecx),%esp
从汇编代码看出,func2比func1只是多出了一条指令来为临时变量申请存储空间,这与其C代码相吻合;func3比func2却多出了一大片 代码,而其C代码的不同却只是临时数组的类型的不同而已。通过分析可知,这些多出的代码就是用来检查缓冲区溢出的。在调用函数之前,在栈上分配4字节的存 储空间。在进入函数之后,一个数(%gs:0×14)保存到这4字节空间中。在退出函数之前做一次检查,如果刚才保存的数被修改,那可以肯定是发生了缓冲 区溢出。
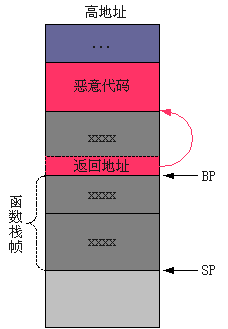
GS是附加段寄存器,我也没搞明白是干什么用的,更加不清楚%gs:0×14的值什么时候被确定。这种检测方法的思路很简单,就是在栈上放置一个随 机数,然后检查这个随机数有没有被改写。由于随机数放置在返回地址之前,聪明的黑客应该可以通过图3的方式植入恶意代码。但对黑客来说,这样有两个不便: (1)恶意代码需植入到当前函数的栈帧上,空间很小,很难植入攻击性强的代码;(2)由于主要是利用字符串拷贝来植入恶意恶意代码,而字符串拷贝是遇到 ’/0′才结束的,这样就要求恶意代码起始地址的低8位必须为全0,这样才可以刚好改写返回地址,而不会进入“雷区”(随机数)。在狭小的空间内,完成这 样的操作实在难于登天;如果可用空间很大的话,这两个问题其实也不难克服。
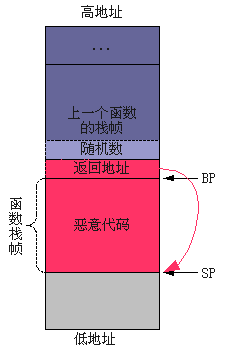
图3. 缓冲区溢出攻击
关于CPU和操作系统
我一直有个疑问:程序代码加载在代码段上,程序数据保存在数据段与堆栈段上,本来是河水不犯井水。缓冲区溢出只发生在数据段与堆栈段,只要规定这两 个段的内容可读写但不可执行,不就不需要担心缓冲区溢出攻击了吗?但事实上,许多程序为了提高效率,会在堆栈段上动态地生成可执行代码,比如Linux本 身就这样做,所以“数据段和堆栈段不可执行”这样的说法是错的。
Intel和AMD已经在一些CPU上加入了“防病毒”功能,这种CPU可区分哪些地址空间可以执行代码、而哪些地址空间不可以执行。
小结
通过实验,知道GCC有一定的保护机制,可防止缓冲区溢出攻击的发生。但这种方法有一定的局限性,所以仍有攻击的可能。我汇编很懒,有很多问题没有 完全搞明白。由于我很懒也没有毅力(我很痛恨自己的这种作风),不明白的地方留待“以后”研究。至于用Firefox浏览网页究竟会不会中毒的问题,应该 也还是会吧?

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步