关于博客《BBR evaluation at a large CDN》和 《When to use and not use BBR》的理解
《BBR evaluation at a large CDN》
解决的问题
通过在 \(CDN\) (\(Content \ Delivery \ Network\)) 的环境中对 \(BBR\) 算法进行评估,量化其带来的好处以及对网络流量的影响,从而帮助内容提供商选择正确的拥塞控制算法。
方法
使用多个策略对 \(BBR\) 进行评估,先在一个 \(POP\) (\(Points \ of \ Presence\))上进行一个小规模的 \(BBR\) 测试(a large wireless provider, a large wireline provider, PoP-to-PoP and intra-PoP traffic),最后进行了一个全面的 \(POP\) 测试。
该作者使用了两个评测指标,一个是吞吐量,一个是 \(TCP\) 流的完成时间,之所以采用两个评估指标,是由于在发送目标数据大小很小的时候,再去用吞吐量去评估,可能不够精确,存在很多噪声。因此,作者定量当发送数据大小小于3\(MB\) 时候,追踪流的完成时间,是更好的指标;当发送数据大小大于3\(MB\) 时候,使用吞吐量进行衡量。
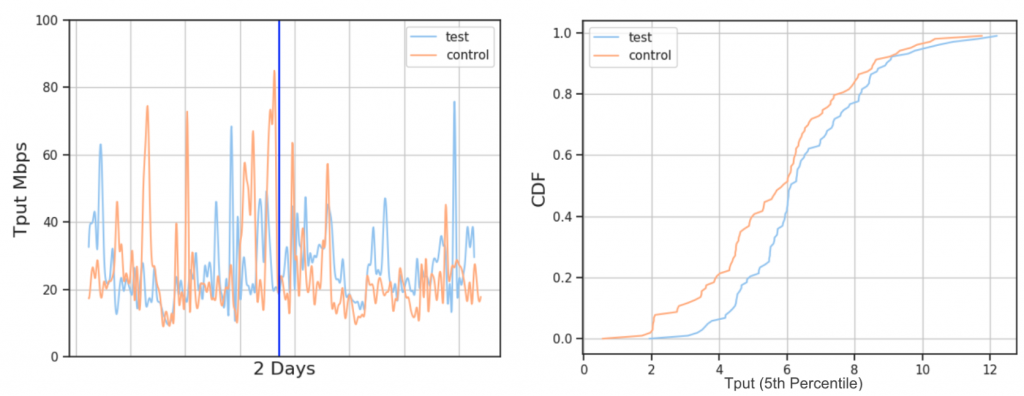
A large wireless provider
在无线提供商的环境中,启用 \(BBR\) 算法有了一个明显的提高(6%-8%),如上图所示,\(test\) 蓝线代表 \(BBR\) ,\(control\) 红线代表 \(CUBIC\) 。对于左图,我们可以发现,当在垂直蓝线时刻,激活 \(BBR\) 算法之后,\(BBR\) 算法的吞吐量很明显高于 \(CUBIC\) 算法的吞吐量。对于右图,在当 \(CDF\) (\(cumulative \ distribution \ function\))概率相同的时候,即同一纵坐标时,\(BBR\) 算法的吞吐大于 \(CUBIC\) 算法的吞吐量。
不过作者认为,由于无线环境中,丢包率较高,因此并不能确定该包的丢失是由于拥塞所引起的,从而对 \(BBR\) 算法的实验结果也有一定的质疑。
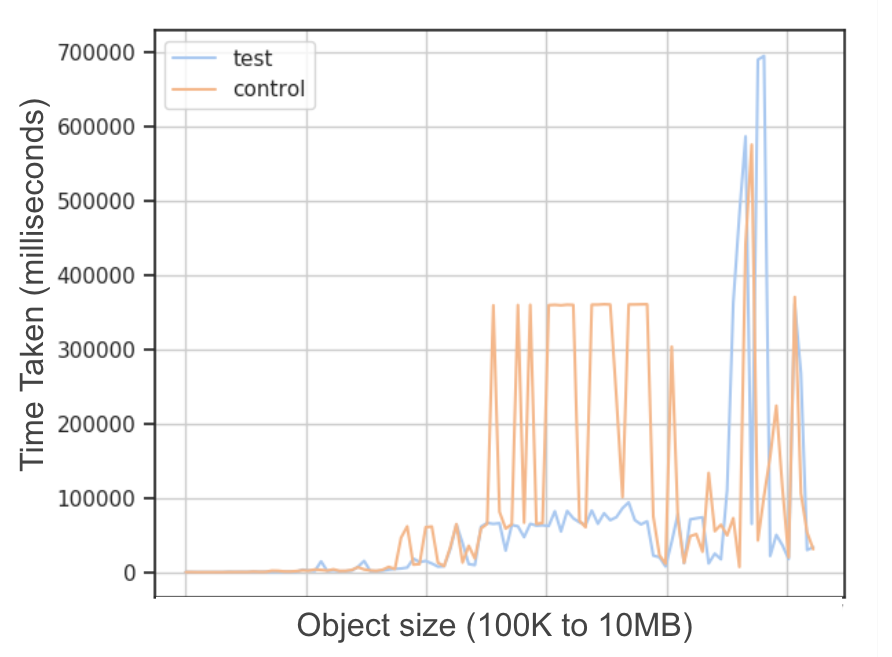
A large wireline provider
作者在有线环境中,根据不同发送数据的大小下所完成传输的时间对 \(BBR\) 做了评估,如上图所示,我们可以看见 \(BBR\) 在发送同等大小的数据时,抖动很小,并且完成的时间相比于 $CUBIC $ 算法也更短。不过,也会存在和 \(CUBIC\) 算法类似的抖动。总体而言,\(BBR\) 的性能是很好的。
不过作者认为,\(BBR\) 算法的增益,是从 \(POP-to-Client\) 的聚合视图所得出来的,无法确定该算法是否对所有的\(TCP\) 流都有增益。因此,进行了更加细化的评估。
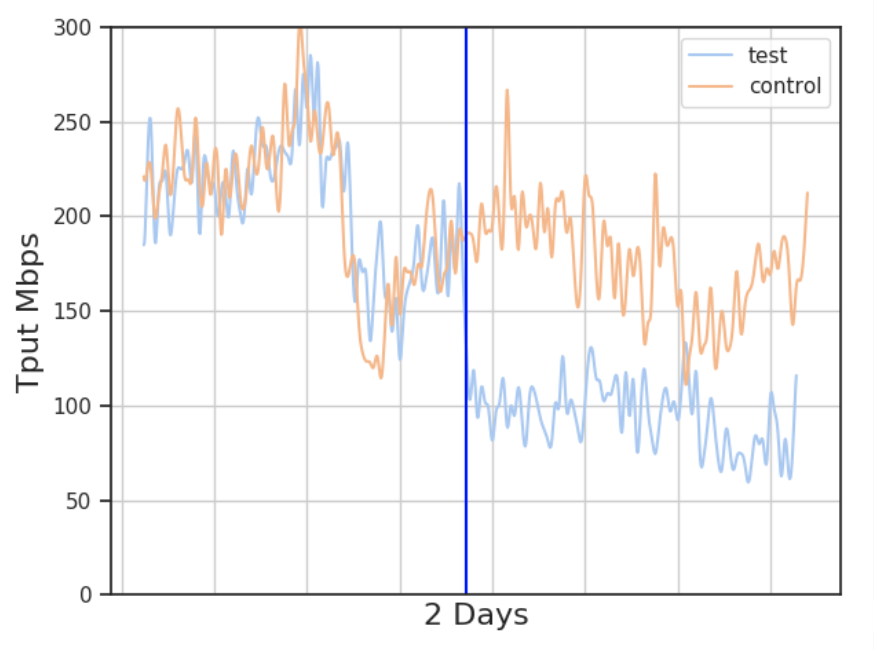
PoP-to-PoP and intra-PoP traffic
作者更为细致的在 \(poP-to-poP \ and \ intra-poP\) 中使用 \(BBR\) 算法进行了实验评估,从上图我们可以发现,当在垂直蓝线时刻处激活 \(BBR\) 算法后,\(BBR\) 的吞吐量远不如 \(CUBIC\) 算法的吞吐量。
为什么在\(POP-to-Client\) 和 \(poP-to-poP \ and \ intra-poP\) 中,\(BBR\) 算法的性能会有如此大的差异呢?
作者后面通过服务器日志发现,\(BBR\) 在较高 \(RTT\) 和 重传率下会有很好的性能表现,而 \(poP-to-poP \ and \ intra-poP\) 中,由于是低 \(RTT\) 和低 重传率,因而比较适合 \(CUBIC\)
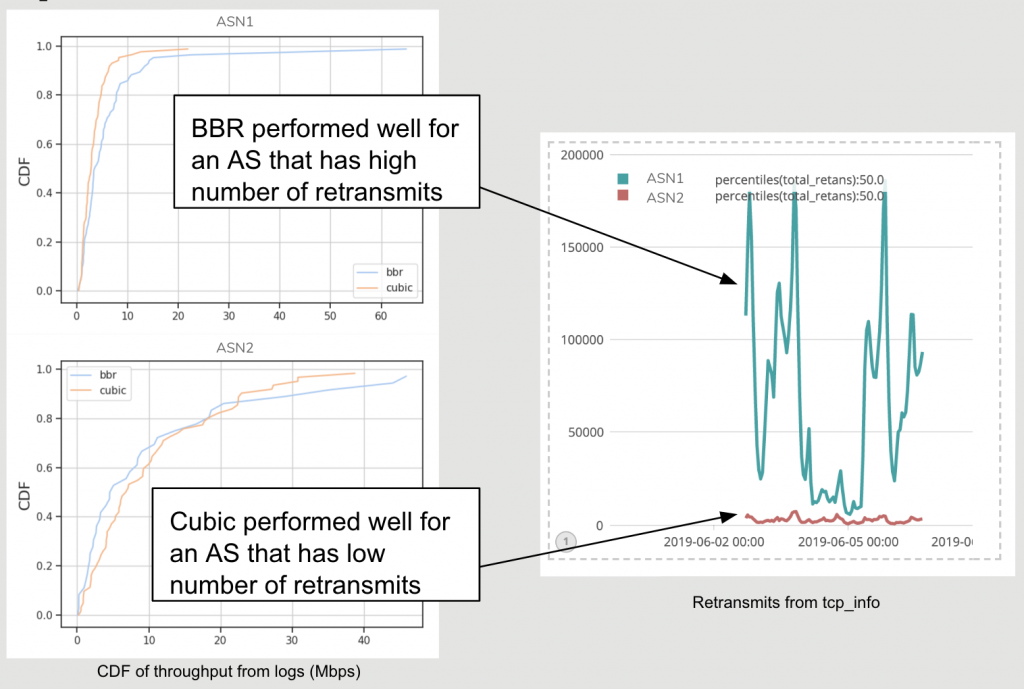
Full PoP test
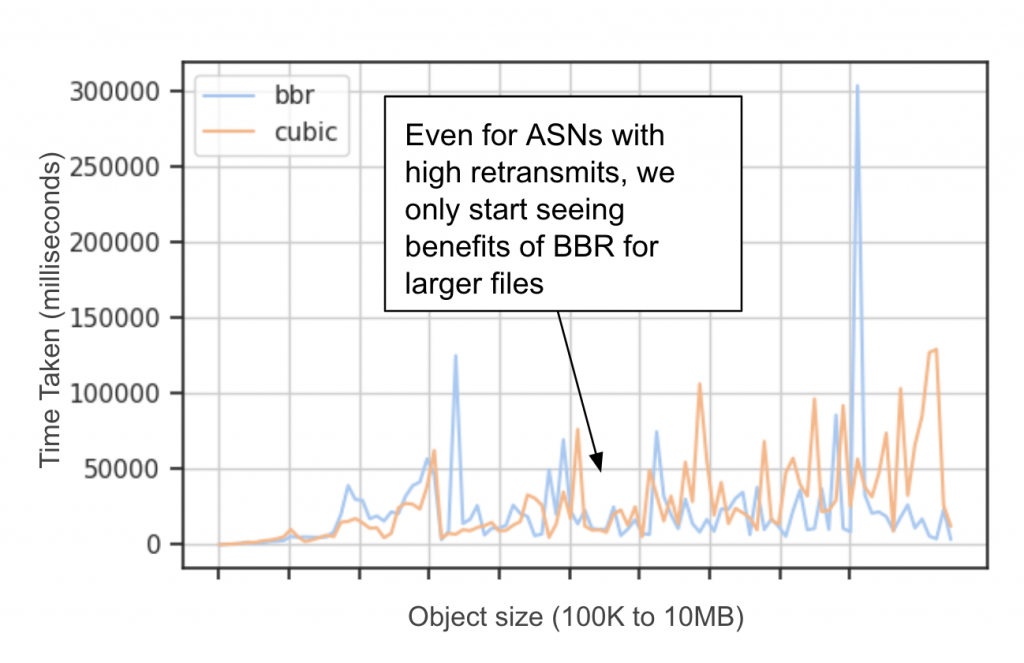
作者最后进行了一次完整的 \(PoP\) 测试,使用了两个 \(ASes\) (\(Autonomous \ Systems\)),如上右图所示,两个网络的 \(RTT\) 都比较高,其中 \(ASN1\) 的重传率较高,\(ASN2\) 的重传率较低。从上图左边两幅 关于\(throughput\) 的 \(CDF\) 可知,在关于 \(ASN1\) 的 \(CDF\) 图中,\(BBR\) 的性能较好,而在关于 \(ASN2\) 的 \(CDF\) 图中,\(CUBIC\) 的性能较好。因此,可以发现,即便在 \(RTT\) 较高的环境中,\(BBR\)也只适用于 重传率较高的情况下,才能有较好的性能表现。
接下来作者想要评测在\(ASN1\)中 \(BBR\) 是否对于所有的连接都有吞吐量的提升。
从上图分析可知,\(BBR\) 算法也只有刚开始的时候,性能优于 $CUBIC $ 算法。
结果分析
作者认为原因还是归根于 \(BBR\) 的公平性问题上。
\(CUBIC\) 与 \(BBR\)
在一个高缓存的情况下,中间设备(路由器等)可能会存在排队的情况,而 \(BBR\) 的的估计的\(RTT\) 可能会增加。而 \(CUBIC\) 则是基于丢包来判断拥塞,因此会倾向于填满缓存,导致 \(CUBIC\)能够抢占更多的带宽,从而表现较好。而在一个浅缓存的情况下,缓存容易被填满,导致缓存溢出,从而容易丢包,\(CUBIC\) 算法会轻易去降低自己的拥塞窗口,因此 \(BBR\) 能够获得更多带宽。
\(BBR\) 与 \(BBR\)
当两个不同 \(RTT\) 的 流竞争共享带宽时,\(RTT\) 较高的流可能会估量得到更高的最小 \(RTprop\),因此会获得更大的 \(BDP\),从而占有更多的带宽份额。
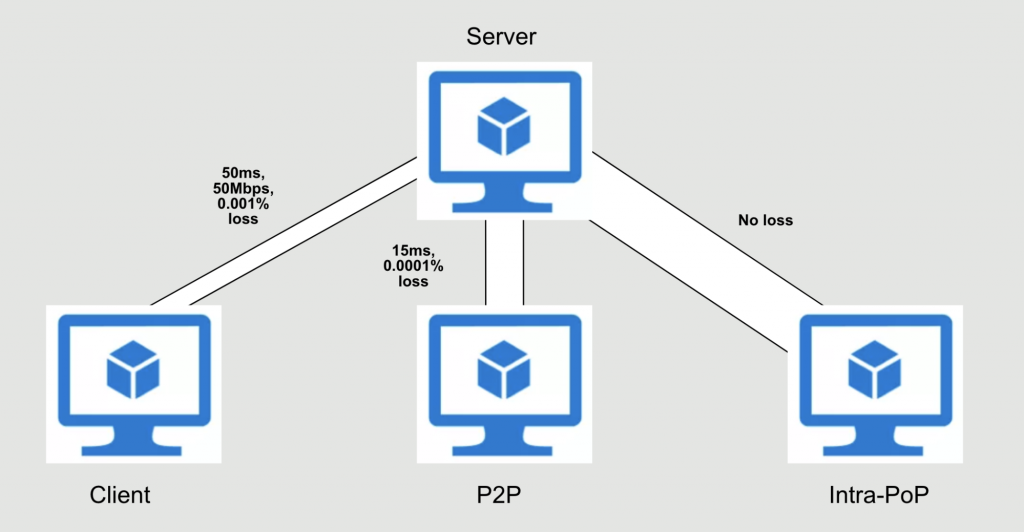
在实验室中去复现结果
作者在虚拟机上搭建了测试平台环境,在边缘服务器上去模拟不同流量类别(Client、P2P、Intra-PoP)的方法。
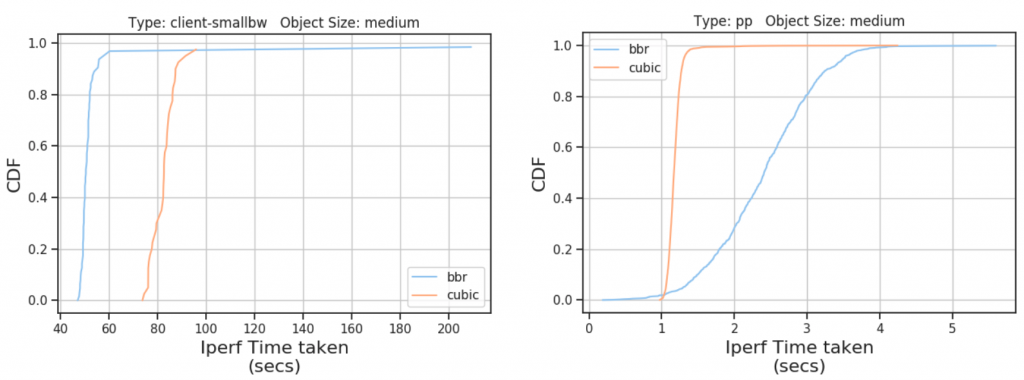
作者重现了 \(BBR\) 在不同类别下的行为表现,在 \(client-smallbw\) 情况下 \(BBR\) 流完成的时间比 \(CUBIC\) 流所完成的时间更短;由于 \(client\) 环境为 较高延迟,丢包率较高,因此 \(BBR\) 性能表现更好。
所以在\(CDN\) 上进行 \(BBR\) 的任何部署都必须意识到它可能对混合流类型产生更广泛的影响。
结论
\(BBR\) 在 \(poP-to-poP \ and \ intra-poP\) 这种低重传率的环境下,会存在降低吞吐量的风险。但是在客户端表现良好,所以可以从 \(wireless \ providers\) 开始去启用 \(BBR\) 拥塞控制算法,因为无线环境中存在浅缓存和丢包率较高的情况,所以\(BBR\) 算法会很有优势。
首先CUBIC与BBR共存于共享链路,在瓶颈带宽被占满之后,CUBIC会继续发包填充队列,造成BBR被动排队。由于BBR的被动排队,所以rtt也会显著上升。但是这在短时间内不会影响BBR的发包,因为BBR的测量RTT的是10秒内的最小RTT。也就是说,只要BBR能够坚持10s不划走,CUBIC一旦丢包就会出现乘性减窗。BBR在回复到干净状态的同时也可以迅速占据空闲的带宽,从而达到压制CUBIC的效果。而相反在另一种情况,如果队列足够深,rtt足够长,足以让CUBIC填充10s还不满时,CUBIC丢包前BBR就退到4个包发送速度了,这反而说CUBIC压制了BBR。
所以这里可以顺理成章地得出结论结论是,浅队列时,CUBIC受BBR的影响比较小,深队列时,BBR会受到CUBIC的影响。
《When to use and not use BBR》
这一篇博客主要也是分析了 \(BBR\) 地公平性问题,同样认为 \(BBR\) 算法比较适用于浅缓存,重传率较高地情况下,不过作者对丢包率做了定量分析。
当丢包率超过20%的时候,\(BBR\)算法的吞吐量有一个断崖式的下跌,而右边的图说明了这个断崖点是与 \(pacing\_gain\)有密切关系的,所以作者认为\(BBR\) 的性能对参数是非常敏感的,可以使用参数的自动调整,以应对不同的网络环境。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号