python爬虫总结
为什么要写这篇文章?
之前也写过爬虫,用过python,也用过java,但对其原理一直是不求甚解,本着一种非要完全搞清楚的心态,对爬虫进行了更具体的学习,并写下此文章作为记录。
此文章以爬取微博热搜内容为例
需要哪些库?
requests
- 作用:获取网页的html源码
- 参考:Python requests 模块 | 菜鸟教程 (runoob.com)
BeautifulSoup4
-
作用:按照标签规则查找网页内容
流程总览
- 获取网页html源码
- 按照标签规则查找指定(自己想要爬取的)数据
- 将数据存储到指定文件中
代码实现
获取网页html源码
需要注意的是,获取网页源码时,访问的网页可能会需要登录认证或者验证User-Agent是否为浏览器,从而导致获取失败。这种情况就要修改请求头,来对访问网页进行“欺骗”。
不需要验证的网页
import requests
# 获取html源码
res = requests.get('https://www.baidu.com')
# 指定解析方式,一般有两种:
# 1、gbk
# 2、utf-8
res.encoding = 'utf-8'
# 打印到控制台
print(res.text)
需要验证的网页
本次示例,爬取微博热搜是需要验证的
import requests
# 修改请求头,对服务器进行“欺骗”
headers = {
# 此处的两个参数需要自己修改
'User-Agent': '***',
'Cookie': '***'
}
# 获取请求的session
session = requests.Session()
# 获取html源码
response = session.get('https://s.weibo.com/top/summary/', headers=headers)
response.encoding ='utf-8'
print(response.text)
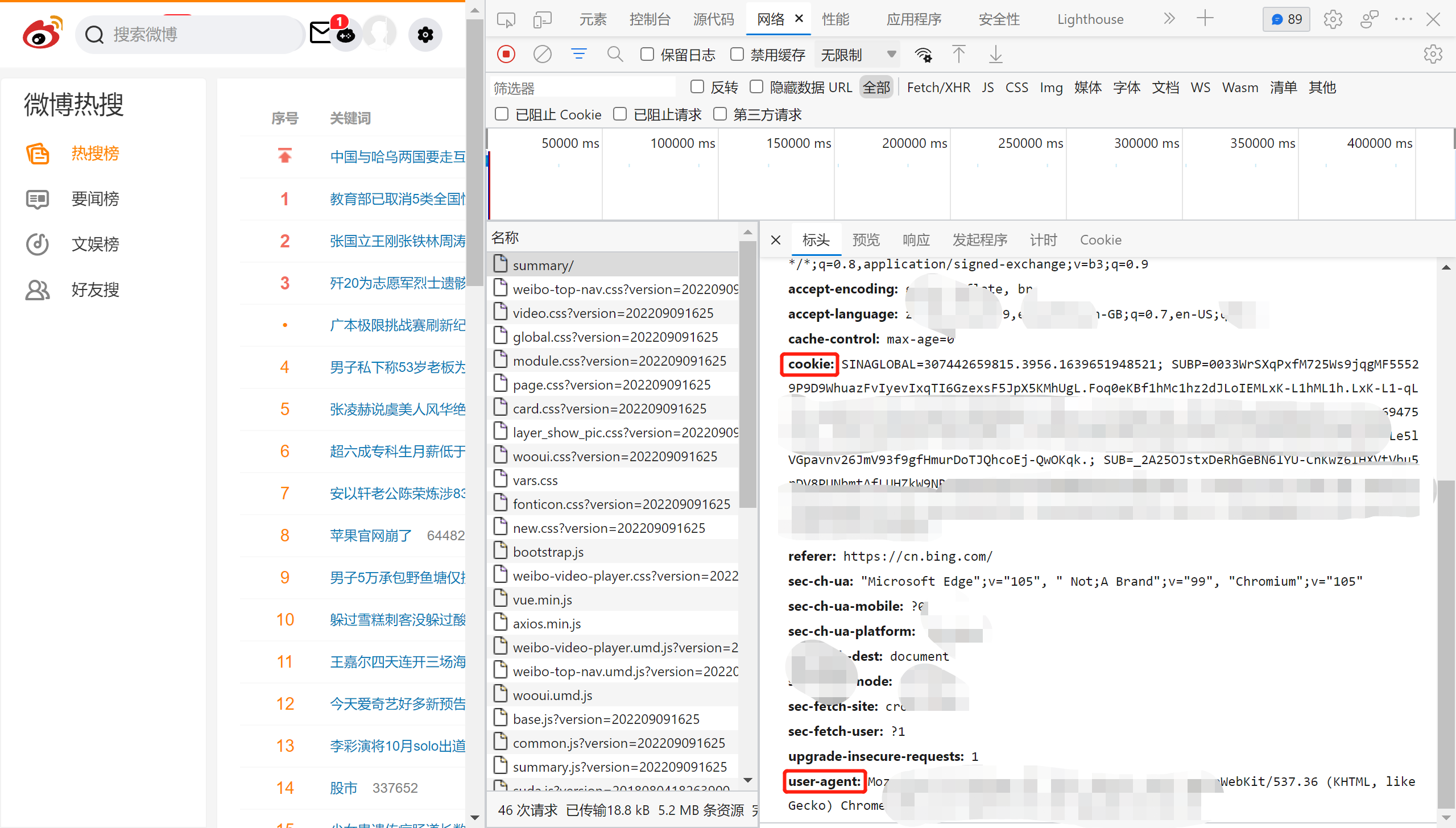
关于User-Agent和Cookie的修改值
- 在浏览器中进入网址:https://s.weibo.com/top/summary/(如需登录,需要先登录进去)
- 然后按F12,点击network(网络)
- 刷新一下网页
- 点击一个网络请求查看两个值,并复制粘贴到代码中
按照标签规则获取指定内容
先把网页内容用beautifulsoup处理一下
from bs4 import BeautifulSoup
html_str = response.text
soup = BeautifulSoup(html_str, 'html.parser')
获取指定内容(热搜内容)
# 标题以及网址
url_titles = soup.select('#pl_top_realtimehot>table>tbody>tr>.td-02>a')
# 热度
hotness = soup.select('#pl_top_realtimehot>table>tbody>tr>.td-02>span')
# 列表,用于存储爬取信息
news = []
# 处理内容
for i in range(len(url_titles) - 1):
# 先把信息放到字典中
# 因为第一个是置顶内容,所以需要i+1来排除掉
hot_news = {'title': url_titles[i+1].get_text(), 'url': 'https://s.weibo.com' + url_titles[i+1]['href'],
'hotness': hotness[i].get_text()}
# 有些热度为空,不属于热榜,排除掉
if hot_news['hotness'] != ' ':
#需要的数据存在列表中
news.append(hot_news)
存储爬取内容
本例采用csv格式保存信息
f = open('./微博热搜榜.csv', 'w', encoding='utf-8')
for item in news:
f.write(item['title'] + ',' + item['url'] + ',' + item['hotness'] + '\n')
代码总览
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': '***',
'Cookie': '***'
}
session = requests.Session()
response = session.get('https://s.weibo.com/top/summary/', headers=headers)
html_str = response.text
soup = BeautifulSoup(html_str, 'html.parser')
url_titles = soup.select('#pl_top_realtimehot>table>tbody>tr>.td-02>a')
hotness = soup.select('#pl_top_realtimehot>table>tbody>tr>.td-02>span')
news = []
for i in range(len(url_titles) - 1):
hot_news = {'title': url_titles[i+1].get_text(), 'url': 'https://s.weibo.com' + url_titles[i+1]['href'],
'hotness': hotness[i].get_text()}
if hot_news['hotness'] != ' ':
news.append(hot_news)
f = open('./微博热搜榜.csv', 'w', encoding='utf-8')
for item in news:
f.write(item['title'] + ',' + item['url'] + ',' + item['hotness'] + '\n')
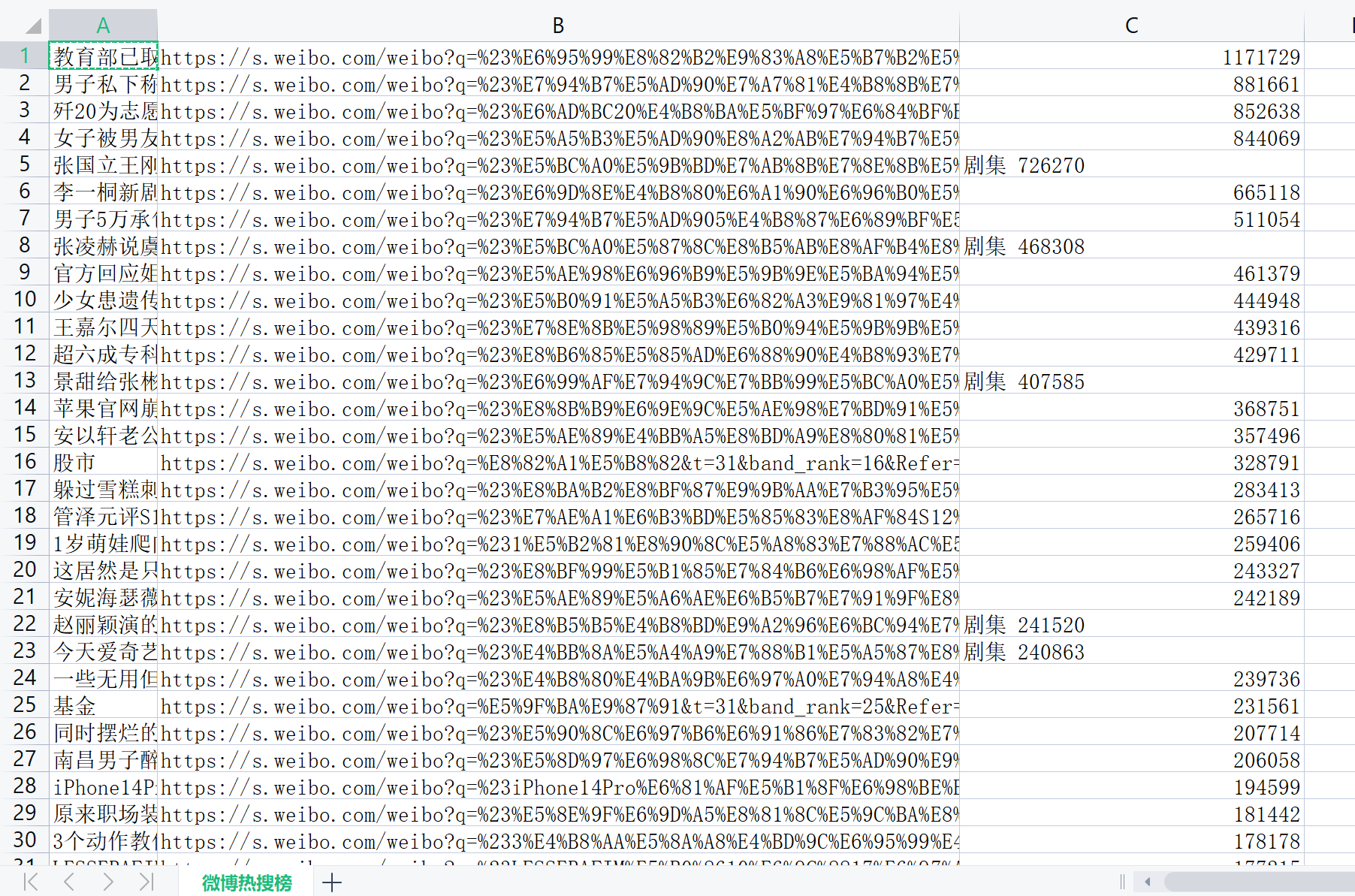
爬取结果展示
写在后面
欢迎访问本人网站:HGS的小站


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY