python-常用模块
Day 25
正则模块
通用正则语法
正则表达式:一种匹配字符串的规则,由两种基本字符类型组成:原义(正常)文本字符和元字符。
程序领域的用途:
- 登录注册页的表单验证
- 爬虫
- 自动化开发 日志分析
元字符
指那些在正则表达式中具有特殊意义的专用字符
| 字符 | 描述 | 举例 |
|---|---|---|
| [] | 字符组:在一个位置上可能出现的各种字符,写法是 [可能出现的字符] | [0-9][A-Z][a-z] |
| [^] | ^在字符组开头表示非,即匹配不是这些字符的内容 | [^123abc] 匹配不是123abc的其他字符 |
| | | 或,匹配竖线任意一边的所有字符 | abc|123 表示匹配abc或者123 |
| ( ) | 分组,表示一个子表达式的作用域 | a(bc|1)3 其中|的作用域为()内的bc与1,匹配abc3与a13 |
| \w | word 匹配一个位置的数字、字母与下划线 ,相当于[0-9A-Za-z_] | |
| \d | digit 匹配一个位置的数字,相当于[0-9] | |
| \s | space 匹配一个位置的空白字符(换行符包括回车,空格,tab也叫制表符) | |
| \W | 与\w相反,相当于 [^0-9A-Za-z_] | |
| \D | 与\d相反,相当于[^0-9] | [\d\D] 匹配一个位置的所有字符,\d是数字能匹配上,\D非数字也能匹配上,类似的还有 [\w\W] [\s\S] |
| \S | 与\s相反,匹配非空白字符 | |
| \n | 匹配一个位置的回车 | |
| \t | 匹配一个位置的制表符tab | |
| \b | 匹配某个字符为一个单词的边界,\b表示边界 | \bw 匹配 word的w, h\b 匹配hello的h |
| ^ | 除了[^]其他情况都表示以什么开头,整篇开头,不是行开头 | ^w 匹配开头的w字符 |
| $ | 以什么结尾,整篇结尾,不是行结尾 | end |
| . | 匹配除换行符 \n 之外的任何单字符 | |
| \ | 将有特殊匹配意义的字符转译为普通字符 | . 表示匹配普通字符的一个点 |
补充说明:字符组
[]中可以是一个范围或者具体的字母或数字
#[XX1-XX2]必须按ASCII从小到大的顺序写,不能写成[9-2] [z-c]
#一个[]表示匹配一个字符
[0-9] 匹配某一个位置为数字
[A-Z] 匹配某一个位置为大写字母
[a-z] 匹配某一个位置为小写字母
[0-9A-Za-z]匹配某一个位置为数字与字母
[2-5] 匹配某一个位置为2-5的数字
[5sjA] 匹配某一个位置为5sjA中的一个字符
量词
| 字符 | 描述 | 举例 |
|---|---|---|
| {} | 匹配前面的子表达式多少次 | \d{5} 匹配5个数字 |
| 匹配前面的子表达式n到多次 | \d{2,} 匹配>=2个数字的字符 | |
| 匹配前面的子表达式n到z次 | \d{2,5} 匹配 >=2 <=5 个数字的字符 | |
| ? | 匹配前面的子表达式0次或一次 | do(es)? do 与 does都能匹配上 |
| + | 匹配前面的子表达式1次或多次 | do(es)+ does与doeses 能匹配上 |
| * | 匹配前面的子表达式0次或多次,是?与+的合集 | |
| 特殊用法 | ||
| 量词? | 量词后加一个?表示惰性匹配,在整个正则表达式能匹配上的情况下,匹配量词对于的子表达式的最少次数,量词后 不加?表示贪婪匹配 | a\d{2,5}?z a1234z能匹配上,虽然是惰性机制,但是以匹配上为前提,还要匹配后面的z |
- 表达式加量词 默认贪婪匹配,使用回溯算法
- 表达式加量词加? 表示惰性匹配
回溯算法
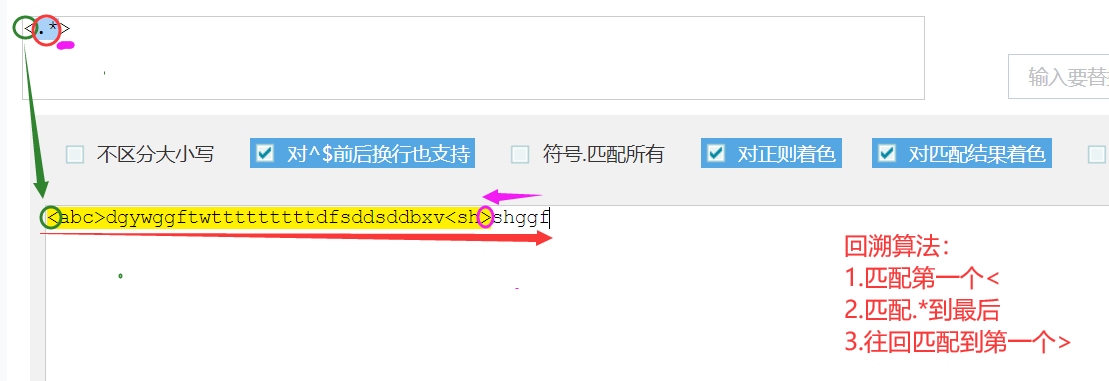
惰性机制
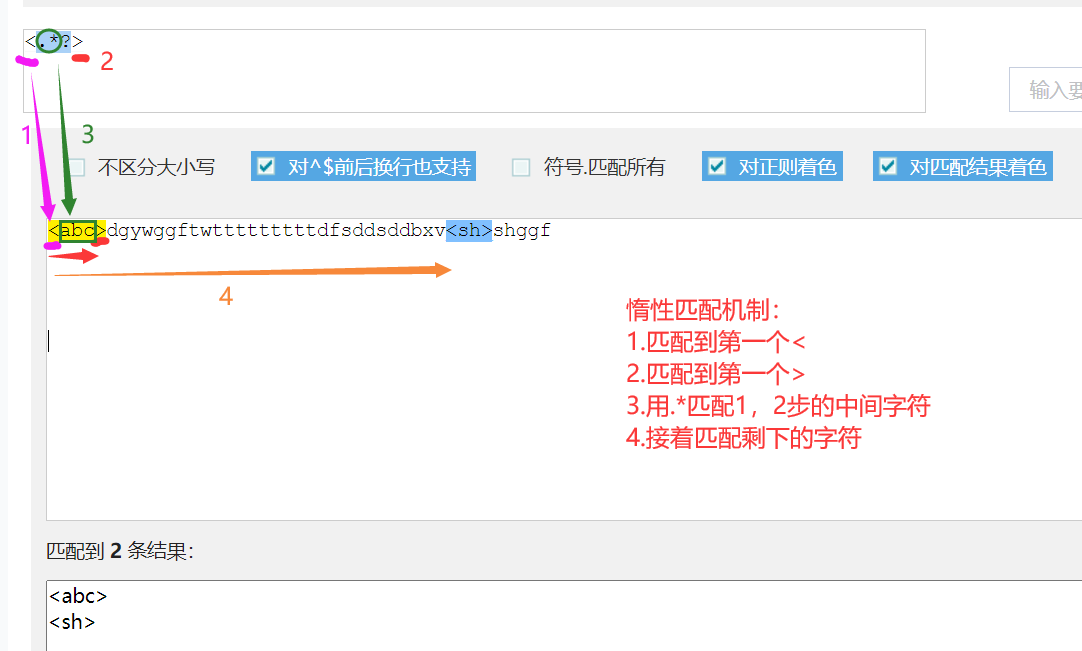
使用举例:
#匹配身份证号 有18位与15位的两种,第一位都不为0,18位最后一位为数字或x,15位的都是数字
[1-9]\d{16}[0-9X]|[1-9]\d{14}
[1-9]\d{14}(\d{2}[1-9X])?
#匹配任意长度的正整数 [1-9]\d*
#匹配小数 -?\d+\.\d+
#匹配整数或者小数 -?\d+(\.\d+)?
#匹配负数 -\d+(\.\d+)?
#匹配qq号 [1-9]\d{4,11}
#匹配长度为11的电话号码 1[3-9]\d{9}
#长度为8-10位的用户密码:数字字母下划线 \w{8,10}
#匹配验证码:4位数字字母组成 [\dA-Za-z]{4}
#从类似
#<a>wahaha</a>
#<b>qqxing</b>
#<h1>banana</h1>
#有些内容光靠正则表达式是不能完全截取的,还得用其他工具处理
#1)匹配 wahaha qqxing banana
匹配>\w+< 再用分组优先显示去掉 > <
#2)匹配 a,b,h1这样的内容
<\w+> 再用再用分组优先显示去掉 <>
# 1-2*((60-30+(-40/5)*(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)*(16-3*2))
#匹配出最内层的小括号及内容
\([^()]+\)
re模块
转义符
- 正则表达式中的转义
\(\) 表示匹配小括号
[()+\*?/$.] 在字符组中部分特殊字符不会被转译
[-] 只有-在字符组首位的时候表示普通的"-",在字符组的其他地方都表示范围
- python中的转义 r"xxx"
在python中所有正则规则的表达式都为字符串,而在要匹配一个换行符:
在正则中表示为"\n"
在python中,"\n"为一个回车,匹配换行符的正则表达式字符串需要写成"\\n"或 r"\n"
所以python中的正则表达式很多情况下都要加一个r
常用方法
匹配相关
findall search match
re.findall("匹配规则","字符串")
能匹配到所有结果,并以列表的类型返回
ret1 = re.findall("\d+","hdg678ha12db74g0")
print(ret1)
输出:
['678', '12', '74', '0']
------------------------------------------------------------
re.search("匹配规则","字符串")
只能匹配到第一个结果,返回为对象,可用对象.group()调用;
匹配不到结果返回为None
ret2 = re.search("\d+","hdg678ha12db74g0")
print(ret2) #ret2为一个对象
print(ret2.group())
输出:
<re.Match object; span=(3, 6), match='678'>
678
------------------------------------------------------------
re.match("匹配规则","字符串")
相当于re.search("^正则表达式","字符串"),即字符串开头就要能匹配上,否则返回None
ret3 = re.match("\d+","hdg678ha12db74g0") #字符串不以匹配规则开头,匹配不上
print(ret3)
输出:
None
ret4 = re.match("\d+","678ha12db74g0") #字符串以匹配规则开头
print(ret4)
print(ret4.group())
输出:
<re.Match object; span=(0, 3), match='678'>
678
忽略大小写:
想让匹配规则忽略大小写,可添加re.IGNORECASE 标志参数,也可简写为re.I
print(re.search("aa","AADHHF",re.I).group())
re.S 与 re.M
- 点 . 默认不能匹配换行符, re.S做的事情是: 让.也能匹配换行符。
- ^与$默认匹配的是整篇的开头与结尾, re.M做的事情是: 让^匹配每行的开头,$匹配每行的结尾。
import re
text = """First line.
Second line.
Third line."""
pattern = "^(.*?)$"
# 结尾在第三行, 而.不能匹配换行符, 因此以下的 pattern什么都匹配不到
print(re.findall(pattern, text)) # 输出为[]
# 让.匹配换行符
print(re.findall(pattern, text, re.S))
# 输出为 ['First line.\nSecond line.\nThird line.']
# 让^、$匹配每行的开头、结尾
print(re.findall(pattern, text, re.M))
# 输出为 ['First line.', 'Second line.', 'Third line.']
切割与替换
split sub subn
------------- 切割 -------------------------------------------
re.split("匹配规则","字符串")
将字符串以匹配到的内容为分隔符进行分割,返回为列表
ret5 = re.split("\d+","hdg678ha12db74g0")
print(ret5)
输出:
['hdg', 'ha', 'db', 'g','']
------------- 替换 -------------------------------------------
re.sub("匹配规则","新的内容","字符串")
将字符串中匹配到的内容替换为新的内容,返回新的字符串
ret6 = re.sub("\d+","***","hdg678ha12db74g0")
print(ret6)
输出:
hdg***ha***db***g***
re.subn("匹配规则","新的内容","字符串")
将字符串中匹配到的内容替换为新的内容,返回元组('新的字符串',替换的次数)
ret7 = re.sub("\d+","***","hdg678ha12db74g0")
print(ret7)
输出:
('hdg***ha***db***g***', 4)
进阶方法
compile finditer
compile('匹配规则')
节省时间。当匹配规则很长,且会多次匹配该规则进行操作时,可用此函数。
将匹配规则编译成字节码,后续的匹配直接使用该字节码,能节约后续每一次匹配都要编译规则的时间
例如:匹配负的整数或者小数
recode=re.compile(r'-0\.\d+|-[1-9]\d*(?:\.\d+)?')
ret1 = re.findall(recode,'-1asdada-200')
print(ret1) 输出: ['-1', '-200']
ret2 = re.search(recode,'as899dada-200')
print(ret2.group()) 输出: -200
ret3 = re.sub(recode,'---','as-899da-1.9da-200')
print(ret3) 输出: as---da---da---
#其他的split finditer等等方法也能一样使用recode变量。
--------------------------------------------------------------
finditer("匹配规则","字符串")
节省内存。findall方法会将所有匹配结果返回为一个列表,但是当匹配结果很长时,就会占用很多内存。此方法返回为迭代器,用一个取一个能节省内存,但是效率也会降低,取值用ret.group()。
ret2 = re.finditer("\d+","hdg678ha12dg")
print(ret2) #ret2为一个迭代器
for i in ret2:
print(i.group())
输出:
<callable_iterator object at 0x0000027CF5582520>
678
12
分组相关
分组在以上方法中的特殊性
当匹配规则中有分组时,以下方法会有特殊性:
取消分组的特殊性(?:匹配规则)
findall 优先显示分组匹配到的内容
#规则表示匹配小数,优先输出了分组匹配到的
ret=re.findall("[-]?\d+(\.\d+)+","hd-2h-3.58db4.61nk8dh0d")
print(ret)
输出:['.58', '.61']
#取消分组 优先
ret=re.findall("[-]?\d+(?:\.\d+)+","hd-2h-3.58db4.61nk8dh0d")
print(ret)
输出:['-3.58', '4.61']
#运用分组优先输出获取整数
ret=re.findall(r'[-]?\d+(?:\.\d+){1,}|([-]?\d+)','hd-2h-3.58db4.61nk8dh0d4.8')
print(ret)
ret2=[i for i in ret if i != ""] #去除空值
print(ret2)
输出:
['-2', '', '', '8', '0', '']
['-2', '8', '0']
search 通过group(n)来按照分组的顺序查看分钟匹配到的内容
ret1 = re.search(r"<(\w+)>(\w+)<(/\w)>","<a>hjygguyguy</a>")
print(ret1.group()) #group()就是group(0)
print(ret1.group(0))
print(ret1.group(1)) #第一个分组匹配到的内容
print(ret1.group(2)) #第二个分组匹配到的内容
print(ret1.group(3)) #第三个分组匹配到的内容
输出:
<a>hjygguyguy</a>
<a>hjygguyguy</a>
a
hjygguyguy
/a
当去掉第一个分组的特殊性,group(1)就变为以上第二个分组的内容
ret1 = re.search(r"<(?:\w+)>(\w+)<(/\w)>","<a>hjygguyguy</a>")
print(ret1.group(1))
print(ret1.group(2))
输出:
hjygguyguy
/a
split 保留分组中的内容
#将所有的小数整数为分隔符,此处分组特殊,会显示
ret5 = re.split("[-]?\d+(.\d+)?|[-]\d+","dg121.12hg567hg89hdg456g-8.9f")
print(ret5)
输出:
['dg', '.12', 'hg', None, 'hg', None, 'hdg', None, 'g', '.9', 'f']
#去掉分组特殊性
ret5 = re.split("[-]?\d+(?:.\d+)?|[-]\d+","dg121.12hg567hg89hdg456g-8.9f")
print(ret5)
输出:
['dg', 'hg', 'hg', 'hdg', 'g', 'f']
分组命名
- 对分组设置特定名字
对分组匹配到的内容进行命名(?P<组名>匹配规则)
对组名进行引用 (?P=组名)
使用场景:
后面的内容需要与前面某分组的内容一致
获取分组匹配到的内容,方便调用
ret1 = re.search(r"<(?P<title>\w+)>\w+</(?P=title)>","<a>hjygguyguy</a>")
print(ret1.group())
print(ret1.group("title"))
- 按顺序对分组进行引用
引用第m个分组就写 \m
ret1 = re.search(r"<(\w+)>\w+</\1>","<a>hjygguyguy</b>")
print(ret1.group())
输出:
<a>hjygguyguy</a>
random模块
随机: 在某个范围内取到每一个值的概率是相同的
import random
#随机小数
print(random.random()) #返回0-1之间的随机小数
print(random.uniform(4,107)) #返回自定义范围之间的随机小数
round(random.uniform(4,107),2) #对获取的随机数保留两位小数
#随机整数
print(random.randint(8,20)) #返回自定义范围[8,20]之间的随机整数
print(random.randrange(8,20)) #返回自定义范围[8,20)之间的随机整数
print(random.randrange(8,20,2)) #返回自定义范围[8,20)之间的随机整数,步长为2
#随机抽取
lis=[6,3,4,8,9,0]
print(random.choice(lis)) #随机抽取一个值
print(random.sample(lis,3)) #随机抽取自定义个值,返回列表
#打乱顺序
lis2=[1,2,3,4,5,6]
random.shuffle(lis2)
print(lis2)
思考题:随机生成6位字母数字的验证码
import random
def get_code(num=6):
code=""
for i in range(num):
random_int=str(random.randint(0,9))
random_alp=chr(random.randint(97,122))
random_alp_upper=chr(random.randint(65,90))
random_one=random.choice([random_int,random_alp,random_alp_upper])
code=code+random_one
return code
print(get_code())
time模块
# 时间戳时间,格林威治时间,float数据类型 给机器用的
# 英国伦敦的时间 1970.1.1 0:0:0
# 北京时间 1970.1.1 8:0:0
# 1533693120.3467407
# 结构化时间,时间对象 上下两种格式的中间状态
# 时间对象 能够通过.属性名来获取对象中的值
# 格式化时间,字符串时间,str数据类型 给人看的
# 可以根据你需要的格式 来显示时间
结构化时间对象的属性
| 索引(Index) | 属性(Attribute) | 值(Values) |
|---|---|---|
| 0 | tm_year(年) | 比如2011 |
| 1 | tm_mon(月) | 1 - 12 |
| 2 | tm_mday(日) | 1 - 31 |
| 3 | tm_hour(时) | 0 - 23 |
| 4 | tm_min(分) | 0 - 59 |
| 5 | tm_sec(秒) | 0 - 60 |
| 6 | tm_wday(weekday) | 0 - 6(0表示周一) |
| 7 | tm_yday(一年中的第几天) | 1 - 366 |
| 8 | tm_isdst(是否是夏令时) | 默认为0不是 |
时间格式中常用的符号
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身
三种时间类型之间的转换
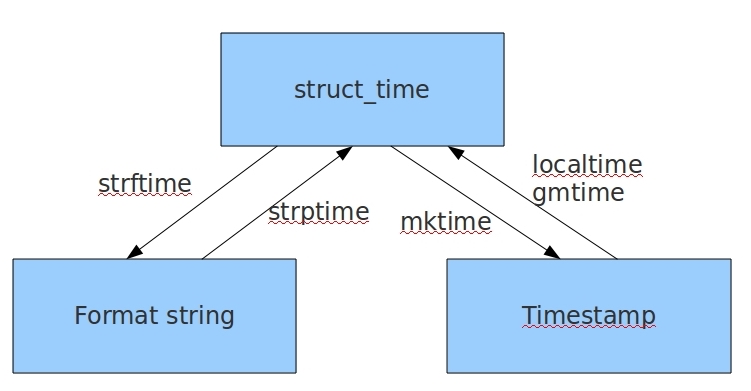
#以上四个方法:
time.gmtime(时间戳) #时间戳转为结构化 UTC伦敦 时间对象,()为空就是获取当前结构化时间对象
ret = time.localtime(时间戳) #时间戳转为结构化 北京 时间对象,()为空就是获取当前结构化时间对象
print(ret.tm_year) 获取对象各种属性值
time.strftime("时间格式",结构化时间对象) #将结构化时间转为格式化时间,结构化时间不写默认为当前
time.striptime("格式化时间","时间格式") #将格式化时间转为结构化时间
time.mktime("结构化时间对象") #将结构化时间对象转换为时间戳
其他常用方法:
time.sleep(secs) 睡眠多少秒
time.time() 获取当前时间戳
下面就以获取本月1号的时间戳来展示一下这几个函数的用法
import time
now_format_time=time.strftime("%Y-%m-%d %H:%M:%S") #获取当前格式化时间
print(now_format_time)
firstday_format_time=re.sub("[-]{1}\d{2} ","-01 ",now_format_time) #得到1号当前时间点的格式化时间
print(firstday_format_time)
firstday_struct_time=time.strptime(firstday_format_time,"%Y-%m-%d %H:%M:%S") #得到1号格式化时间
print(firstday_struct_time)
firstday_timestamp=time.mktime(firstday_struct_time) #得到1号时间戳
print(firstday_timestamp)
sys模块
sys模块是与python解释器交互的接口
常用方法:
sys.argv 用于执行脚本时传参,将参数封装为一个列表,第一个元素为程序本身
程序内部可调用:
var1=sys.argv[0]
var2=sys.argv[1]
sys.exit(n) 用于退出程序,正确退出返回值为0,错误退出为1或非0数字
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.version 返回python解释器的版本信息
sys.platfrom 返回操作系统名称,这个不准确,不要用
os模块
os模块是与操作系统交互的接口
# os.mkdir("dir1") #创建一个目录
# os.makedirs("dir1/dir2/dir3",exist_ok=True) #递归创建多个目录,加上exist_ok=True,目录存在也不会报错
# os.rmdir("dir1/dir2") #删除一个空目录dir2,当目录下有文件则会报错
# os.removedirs("dir1/dir2/dir3") #从内向外递归删除空目录,直至遇到不是空目录的停止,若一开始就没有空目录可删,则会报错
# os.remove("dir1/dir2/dir3/test.txt") #删除单个文件
# os.listdir("d:\Desktop\python_script") #以列表的形式返回绝对/相对路径的某个目录下的文件与目录
# os.rename("D:\Desktop\hwk.py","D:\Desktop\python_script\homewk.py") #修改文件/目录名与路径,相当于linux mv
# os.stat('test.py') #返回文件/目录信息
# os.sep #返回你所在的操作系统的目录分割符 \ \a\dir\dir2
# print([os.linesep]) #os.linesep返回你所在的操作系统的行终止符,win下为"\r\n",Linux下为"\n"。加[]是防止转译为看不见的终止符。
# os.pathsep #返回用于分割文件路径的字符串 win下为;,Linux下为:
# os.name # 返回字符串指示当前使用平台。win->'nt'; Linux->'posix'
#shell相关
# os.system("bash command") #运行shell命令,直接显示输出,不能返回值
# os.popen('bash command').read() #运行shell命令,返回一个对象,可用read()返回执行结果
# os.getcwd() #返回当前工作目录
# os.chdir("dirname") #改变当前脚本工作目录;相当于shell下cd
# os.path
# os.path.abspath("../") #返回某个文件夹/文件的规范化的绝对路径,也规范了目录分隔符
# os.path.split(r'Desktop\python_script\test')#切割目录/文件,返回元组('路径','文件/目录名')
# os.path.dirname(r'Desktop\python_script\test') #返回文件/目录路径,不带本身名字,就是 os.path.split()的第一个元素
# os.path.basename(r'Desktop\python_script\test') #返回文件/目录名本身,不带路径,就是 os.path.split()的第二个元素
# os.path.exists(r'd:\Desktop') #判断文件/目录是否存在,返回True & False
# os.path.isabs(r'd:\Desktop') #判断是否为绝对路径,返回True & False
# os.path.isfile(r'd:\Desktop\test.py') #判断是否为存在的文件,返回True & False
# os.path.isdir(r'd:\Desktop') #判断是否为存在的目录,返回True & False
# os.path.getsize(r'd:\Desktop\python_script\test.py') #返回文件本身大小,无法计算文件夹总大小
# os.path.join("d:/Desktop","aaa","bbb.txt") #将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
序列化模块
序列化:将对象的状态信息转换为可以存储或传输的形式的过程。
反序列化: 将存储或网络接受的信息转换为对象原本类型的过程。
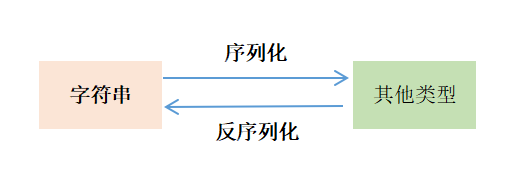
哪里会用到序列化:
- 将内容写入文件(只有字符串才能写入文件);
- 网络传输数据:需要网络发送的数据需要转化为字符串才能发送
信号传输:字符串-->字节码-->二进制-->电信号(高低压电区分01)-->光信号(光的明暗区分01)
信号接收:与传输相反
json模块
json只支持字典、列表、数字、字符串和字符串之间的转化
转化后的字符串数据支持其他多种语言的识别
json格式中的字符串用双引号,python中的str类型用单引号
特殊类型=字典、列表、数字、字符串
json.dumps(字典) #可以将特殊类型 转化为字符串 写入内存
json.loads(字符串类型) #可以将字符串类型转化为特殊类型 写入内存
json.dump(字典,文件句柄) #将特殊类型写入某文件(在内部实现了字典到字符串的转换)
json.load(文件句柄) #读取某文件内容的结果为特殊类型
以上方法的使用
import json
obj={"aa":"11","bb":"22"}
# obj=[1,3,"qq"]
# obj=1
#obj="aabbcc"
#1.将特殊类型转化为字符串
print(obj)
dumps1=json.dumps(obj)
print([dumps1],type(dumps1))
#2.将特殊类型格式的字符串转化为特殊类型
loads1=json.loads(dumps1)
print(loads1,type(obj))
#3.直接将特殊类型数据写入文件
with open("json_test.txt","w") as f:
json.dump(obj,f)
#4.从文件读取将特殊类型格式的字符串的为特殊类型
# with open("json_test.txt","r") as f:
# ret=json.load(f)
# print(ret,type(ret))
json模块中的使用限制
1. json格式的key必须是字符串数据类型。
# 如果是字典中数字为key,那么dump之后会强行转成字符串数据类型
dic = {1:2,3:4}
str_dic = json.dumps(dic)
print(str_dic,type(str_dic))
new_dic = json.loads(str_dic)
print(new_dic,type(new_dic))
输出:
{"1": 2, "3": 4} <class 'str'>
{'1': 2, '3': 4} <class 'dict'>
2. 使用loads或load将内容转为特殊格式时,严格区分json字符串的双引号与python字符串的单引号,否则会报错
#str_dic = "{'1': 2, '3': 4}" #会报错
str_dic = '{"1": 2, "3": 4}'
new_dic = json.loads(str_dic)
print(new_dic,type(new_dic))
3.对元组类型进行dump(s)操作,会转换为列表
dic = ("a","b")
str_dic = json.dumps(dic)
print(str_dic,type(str_dic))
输出:
["a", "b"] <class 'str'>
4. 能不能多次dump数据到文件里,可以多次dump但是不能load出来了
lst1 = ['aaa',123,'bbb',12.456]
lst2 = ["a","b"]
with open('json_demo','w') as f:
json.dump(lst1,f)
json.dump(lst2,f)
with open('json_demo') as f:
ret = json.load(f)
print(ret)
cat json_demo
["aaa", 123, "bbb", 12.456]["a", "b"]
5.想dump多个数据进入文件,用dumps
lst1 = ['aaa',123,'bbb',12.456]
lst2 = ["a","b"]
with open('json_demo','w') as f:
str1=json.dumps(lst1)
str2=json.dumps(lst2)
f.write("%s\n%s" %(str1,str2))
with open('json_demo') as f:
for line in f:
ret = json.loads(line)
print(ret)
6. 中文格式字符dump之后为bytes类型,可ensure_ascii = False正常显示
dic = {'abc':[1,2,3],'country':'中国'}
str_dic = json.dumps(dic)
#str_dic = json.dumps(dic,ensure_ascii = False)
print(str_dic,type(str_dic))
输出:
{"abc": [1, 2, 3], "country": "\u4e2d\u56fd"} <class 'str'>
#人性化展示json格式,为了方便用户看,存储时不建议为这种格式
data = {'username':['李华','二愣子'],'sex':'male','age':16}
json_dic2 = json.dumps(data,sort_keys=True,indent=4,separators=(',',':'),ensure_ascii=False)
print(json_dic2)
其他参数说明
Skipkeys:默认值是False,如果dict的keys内的数据不是python的基本类型(str,unicode,int,long,float,bool,None),设置为False时,就会报TypeError的错误。此时设置成True,则会跳过这类key
ensure_ascii:,当它为True的时候,所有非ASCII码字符显示为\uXXXX序列,只需在dump时将ensure_ascii设置为False即可,此时存入json的中文即可正常显示。)
indent:应该是一个非负的整型,如果是0就是顶格分行显示,如果为空就是一行最紧凑显示,否则会换行且按照indent的数值显示前面的空白分行显示,这样打印出来的json数据也叫pretty-printed json
separators:分隔符,实际上是(item_separator, dict_separator)的一个元组,默认的就是(‘,’,’:’);这表示dictionary内keys之间用“,”隔开,而KEY和value之间用“:”隔开。
sort_keys:将数据根据keys的值进行排序。
pickle模块
支持多种类型(包括自定义类型,对象)和字符串之间的转化
转化后的字符串数据只支持python语言的识别
4个方法 dumps、loads、dump、load功能和json中的方法类似,但还是有些细节不同
1. dump的结果是bytes,所以dump用的文件句柄要以wb的模式打开,load时用rb模式。
2. 支持对对象序列化,在对对象进行序列化与反序列化时需要对象对应的类存在于内存中。
class A:
def __init__(self,name,age):
self.name = name
self.age = age
obj1=A("王二",16)
import pickle
with open('pickle_demo','wb') as f:
pickle.dump(obj1,f) #将对象存在了'pickle_demo文件中
当某时刻需要取这个obj1时,需要内存中有这个类,少了类的这几行代码就会报错
class A:
def __init__(self,name,age):
self.name = name
self.age = age
import pickle
with open('pickle_demo','wb') as f:
pickle.dump(obj1,f)
3. 对于多次dump/load的操作做了良好的处理
lst1 = ['aaa',123,'bbb',12.456]
lst2 = ["a","b"]
with open('pickle_demo','wb') as f:
pickle.dump(lst1,f)
pickle.dump(lst2,f)
with open('pickle_demo',"rb") as f:
print(pickle.load(f))
print(pickle.load(f))
#此处pickle.load(f)一次,返回一个特俗类型的数据,那当不清楚文件中有多少个数据时,怎么获取呢?使用异常处理。
with open('pickle_demo',"rb") as f:
while True:
try:
print(pickle.load(f))
except EOFError:
break
hashlib模块
hashlib提供了常见的摘要算法,如MD5,SHA系列等等
摘要算法:摘要算法又称哈希算法、散列算法。它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16进制的字符串表示)。这个函数是一个单项函数,很难根据数据串反推出原始数据。
特点:只有完全一样的数据才能得出相同的数据串。
使用场景:
- 重要数据的加密
- 判断两个文件是否完全一致
md5算法:计算 结果为32位的字符串,每个字符都是一个十六进制,效率快 算法相对sha1简单
sha1算法:计算 结果为40位的字符串,每个字符都是一个十六进制,没有md5普及,相对更安全,也更慢。
数据加密
这里用md5算法展示一下数据加密,如果要用其他算法,只需要修改代码中的算法名即可:
#加密一个字符串
import hashlib
str1="我家猫咪"
obj=hashlib.md5() 使用哪种算法就修改这里的算法名字
#obj=hashlib.sha1()
obj.update(str1.encode("utf-8")) #传入bytes类型数据
ret=obj.hexdigest()
print(ret)
加盐处理
由于md5在任何时候计算相同数据得出加密串都一致,为了防止类似撞库问题发生,可在生成加密对象时,传入一个自定义的数据串,也称为盐,盐不同,加密相数据得出的加密串也不同。
import hashlib
passwd = "123"
salt_str="aa"
obj = hashlib.md5(salt_str.encode("utf-8"))
obj.update(passwd.encode("utf-8"))
secretd_str=obj.hexdigest()
print(secretd_str)
动态加盐
当你的系统使用固定的盐去加密密码时,某用户恶意注册很多账户,当他拿到别人加密后的密码数据串和自己的相同时,就能知道别人的密码是什么,所以,当盐为具有唯一性的用户id时,就能避免这个问题
import hashlib
username = input("请输入用户名:")
passwd = input("请输入用户密码:")
def secret_pwd(username,passwd):
obj = hashlib.md5(username.encode("utf-8"))
obj.update(passwd.encode("utf-8"))
secretd_str=obj.hexdigest()
return secretd_str
ret=secret_pwd(username,passwd)
print(ret)
对比文件一致性
import hashlib
with open("d:\Desktop\python_script\homework\calculator.py","rb") as f1:
obj1 = hashlib.md5()
obj1.update(f1.read())
secretd_str1=obj1.hexdigest()
with open("d:\Desktop\python_script\homework\calculator_bak.py","rb") as f2:
obj2 = hashlib.md5()
obj2.update(f2.read())
secretd_str2=obj2.hexdigest()
if secretd_str1==secretd_str2:
print("文件一致")
else:
print("文件不一致")
当文件过大,需要在内存中多次加载才能读完,怎么处理?
#在update这一步可多次读入原数据的切片,只要数据完整,加密结果不变,例如
import hashlib
str1="abcdef"
obj1 = hashlib.md5()
obj1.update(str1.encode()) 这一行和打开 下面三行的结果是一样的
##obj1.update(b"a")
##obj1.update(b"bc")
##obj1.update(b"def")
secretd_str1=obj1.hexdigest()
print(secretd_str1)
所以可以根据这个知识点完成大文件的多次加载加密:
#可以输入多个文件,只有每个文件完全一致才返回一致
#可以自定义每次读的文件长度
import hashlib
def compare_files(file,length):
lis=[]
for i in file:
with open(i,"rb") as f1:
obj1 = hashlib.md5()
while True:
ret=f1.read(length)
if ret == b'':
break
else:
obj1.update(ret)
secretd_str1=obj1.hexdigest()
lis.append(secretd_str1)
if len(set(lis))==1:
return ("一致")
else:
return ("不一致")
ret=compare_files(["d:\Desktop\python_script\homework\calculator.py","d:\Desktop\python_script\homework\calculator_bak.py"],1024)
print(ret)
hmac模块
此模块也可以进行数据加密,底层就是hashlib
obj=hmac.new(bytes类型盐,bytes类型要加密的内容,digestmod='加密算法')
ret=obj.digest() 获取到bytes类型加密字符串
#sal="haha"
#random_str="这是一个随机字符"
# secret_obj=hashlib.md5(sal.encode("utf-8"))
# secret_obj.update(random_str.encode("utf-8"))
# se_str=secret_obj.hexdigest() #得到str类型加密字符串
可以改写为
sal="haha"
random_str="这是一个随机字符"
secret_obj=hmac.new(sal.encode("utf-8"),random_str.encode("utf-8"),digestmod='md5')
se_str=secret_obj.digest() #得到bytes类型的加密字符串
configparser模块
适用于ini格式的配置文件的创建、增删改查操作
例如:example.ini
#[DEFAULT]是一个全局的组,可以通过其他组查到改组的key:value
[DEFAULT]
ServerAliveInterval = 45
Compression = yes
CompressionLevel = 9
ForwardX11 = yes
[bitbucket.org]
User = hg
[topsecret.server.com]
Port = 50022
ForwardX11 = no
那么如何创建一个example.ini文件呢?
import configparser
config_obj=configparser.ConfigParser()
config_obj["DEFAULT"]={"ServerAliveInterval":"45","Compression":"yes","CompressionLevel":"9","ForwardX11":"yes"}
config_obj["bitbucket.org"]={"User":"hg"}
config_obj["topsecret.server.com"]={"Port":"50022","ForwardX11":"no"}
with open("example.ini","w") as f:
config_obj.write(f)
查询
section为分组 option为分组下的key
import configparser
config_obj=configparser.ConfigParser()
config_obj.read('example.ini')
# print(config_obj.sections()) #返回所有分组([DEFAULT]不显示)为一个列表
# print(config_obj.options("bitbucket.org")) #返回某个分组的key为一个列表
# print(config_obj['bitbucket.org']) #<Section: bitbucket.org>
# for key in config_obj['bitbucket.org']: # 注意,有default会默认default的键
# print(key) #依次返回某个分组的key
# print(config_obj.options("DEFAULT")) #[DEFAULT]无法查询
# print('bitbucket.org' in config_obj) #判断某个组名是否属于该配置文件
# print(config_obj['bitbucket.org']["user"]) #输出某个组名中某个key对应的value
# print(config_obj['DEFAULT']["compressionlevel"]) #[DEFAULT]能查询key对应的value
# print(config_obj.items('bitbucket.org')) #返回某个分组的key,value为一个列表
# print(config_obj.get('bitbucket.org','compression')) #返回某个组下的某个key对应的value
增删改
config_obj=configparser.ConfigParser()
config_obj.read('example.ini')
#新增某个组
# config_obj.add_section('aaa.com')
# 为某个组新增 key,value,或更改某个组的key的value
# config_obj.set("bitbucket.org","user","dahuang")
# config_obj.set("DEFAULT","language","english")
#删除某个组
# config_obj.remove_section("topsecret.server.com") #删除某个组
# config_obj.remove_section("DEFAULT") #这里DEFAULT组删不掉
#删除某个组中的某个key
# config_obj.remove_option("DEFAULT","forwardx11") #DEFAULT的key可以删
# config_obj.remove_option("topsecret.server.com","port")
#以上操作必须写入文件才会生效
config_obj.write(open('example.ini', "w"))
logging模块
功能:
- 日志格式的规范
- 操作的简化
- 日志的分级管理
日志的分级: CRITICAL > ERROR > WARNING > INFO > DEBUG
| 级别 | 数字值 | 说明 |
|---|---|---|
| DEBUG | 10 | 详细信息,一般只在调试问题时使用。 |
| INFO | 20 | 证明事情按预期工作。 |
| WARNING | 30 | 某些没有预料到的事件的提示,或者在将来可能会出现的问题提示。例如:磁盘空间不足。但是软件还是会照常运行。 |
| ERROR | 40 | 由于更严重的问题,软件已不能执行一些功能了。 |
| CRITICAL | 50 | 严重错误,表明软件已不能继续运行了。 |
logging初识
logging库采取了模块化的设计,提供了许多组件:记录器、处理器、过滤器和格式化器。
-Logger 暴露了应用程序代码能直接使用的接口。
-Handler将(记录器产生的)日志记录发送至合适的目的地。
-Filter提供了更好的粒度控制,它可以决定输出哪些日志记录。
-Formatter 指明了最终输出中日志记录的布局。
Logger
logger对象要做三件事情。
- 它们向应用代码暴露了许多方法,这样应用可以在运行时记录消息。
- 记录器对象通过严重程度(默认的过滤设施)或者过滤器对象来决定哪些日志消息需要记录下来。
- 记录器对象将相关的日志消息传递给所有感兴趣的日志处理器。
常用的记录器对象的方法:
logger.setLevel(logging.DEBUG) 设置日志输出级别
logger.addHandler() && Logger.removeHandler() 从记录器对象中添加和删除处理程序对象
Logger.addFilter()和Logger.removeFilter() 从记录器对象添加和删除过滤器对象
Handler
处理程序对象负责将适当的日志消息(基于日志消息的严重性)分派到处理程序的指定目标。Logger 对象可以通过addHandler()方法增加零个或多个handler对象。举个例子,一个应用可以将所有的日志消息发送至日志文件,所有的错误级别(error)及以上的日志消息发送至标准输出,所有的严重级别(critical)日志消息发送至某个电子邮箱。在这个例子中需要三个独立的处理器,每一个负责将特定级别的消息发送至特定的位置。
常用的4种处理器:
- 控制台输出
logging.StreamHandler()
这个Handler可以向类似与sys.stdout或者sys.stderr的任何文件对象(file object)输出信息。
StreamHandler([strm])
其中strm参数是一个文件对象。默认是sys.stderr
- 文件输出
logging.FileHandler()
用于向一个文件输出日志信息。不过FileHandler会帮你打开这个文件。
FileHandler(filename[,mode])
filename是文件名,必须指定一个文件名。
mode是文件的打开方式。默认是’a',即添加到文件末尾。
- 按size轮询输出到文件
from logging import handlers
handlers.RotatingFileHandler()
RotatingFileHandler(filename,mode,maxBytes,backupCount)
类似于上面的FileHandler,但是它可以根据文件大小进行轮询。
filename和mode两个参数和FileHandler一样;
maxBytes用于指定日志文件的最大文件大小;
backupCount用于指定保留的存档文件的个数,默认的0是不会自动删除掉日志。
- 按时间轮询输出到文件
from logging import handlers
handlers.TimedRotatingFileHandler()
TimedRotatingFileHandler(filename,when,interval,backupCount)
when参数是一个字符串。表示时间间隔的单位,不区分大小写。它有以下取值:
S 秒/M 分/H 小时/D 天/W 每星期(interval==0时代表星期一)/midnight 每天凌晨
interval 是指等待多少个单位when的时间后,Logger会自动重建文件
handler的配置方法:
setLevel()方法和日志对象的一样,指明了将会分发日志的最低级别。为什么会有两个setLevel()方法?记录器的级别决定了消息是否要传递给处理器。每个处理器的级别决定了消息是否要分发。
setFormatter()为该处理器选择一个格式化器。
addFilter()和removeFilter()分别配置和取消配置处理程序上的过滤器对象。
Formatters
Formatter对象设置日志信息最后的规则、结构和内容,有默认格式
%(name)s Logger的名字
%(levelno)s 数字形式的日志级别
%(levelname)s 文本形式的日志级别
%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
%(filename)s 调用日志输出函数的模块的文件名
%(module)s 调用日志输出函数的模块名
%(funcName)s 调用日志输出函数的函数名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d 线程ID。可能没有
%(threadName)s 线程名。可能没有
%(process)d 进程ID。可能没有
%(message)s用户输出的消息
Filter
这里就不作过多介绍。
使用
简单打印日志内容
默认只显示>=warning的内容,即默认level=logging.warning
默认打印日志的格式为:日志级别:登录者名称:日志输出信息
默认输入到标准输出
import logging
logging.debug("这是debug日志内容")
logging.info("这是info日志内容")
logging.warning("这是warning日志内容")
logging.error("这是warning日志内容")
logging.critical("这是critical日志内容")
输出:
WARNING:root:这是warning日志内容
ERROR:root:这是warning日志内容
CRITICAL:root:这是critical日志内容
那么如何自定义日志格式,显示等级,输入方式呢?
有两种使用方法:
- 较为简单的函数式配置,适用于简单的场景
- 较为复杂的logger对象配置更为灵活,适用多样复杂的场景
函数式配置
logging提供了一些便利的函数用于简单的日志配置。
logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有:
filename:用指定的文件名创建FiledHandler,这样日志会被存储在指定的文件中。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式,会覆盖format中的%(asctime)s。
level:设置rootlogger的日志级别
stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件(f=open(‘test.log’,’w’)),默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。
使用:
import logging
logging.basicConfig(level=logging.DEBUG,
format="%(asctime)s %(levelname)s: %(filename)s %(lineno)d %(message)s",
datefmt='%Y-%m-%d %H:%M:%S', #对应format中的%(asctime)s
filename='test.log') #有filename输出到文件,没有则输出到标准输出
logging.debug("这是debug日志内容")
logging.info("这是info日志内容")
logging.warning("这是warning日志内容")
logging.error("这是warning日志内容")
logging.critical("这是critical日志内容")
结果:在当前路径下新增了test.log文件,输入了日志内容:
2021-09-24 15:31:34 DEBUG: test.py 339 ����debug��־����
2021-09-24 15:31:34 INFO: test.py 340 ����info��־����
2021-09-24 15:31:34 WARNING: test.py 341 ����warning��־����
2021-09-24 15:31:34 ERROR: test.py 342 ����warning��־����
2021-09-24 15:31:34 CRITICAL: test.py 343 ����critical��־����
问题1:
输入到文件的中文显示为乱码,但是可以通过f.read()正常读取;
问题2:
无法输入到文件的同时打印到标准输出。
这些可以用logger对象配置解决
logger对象配置
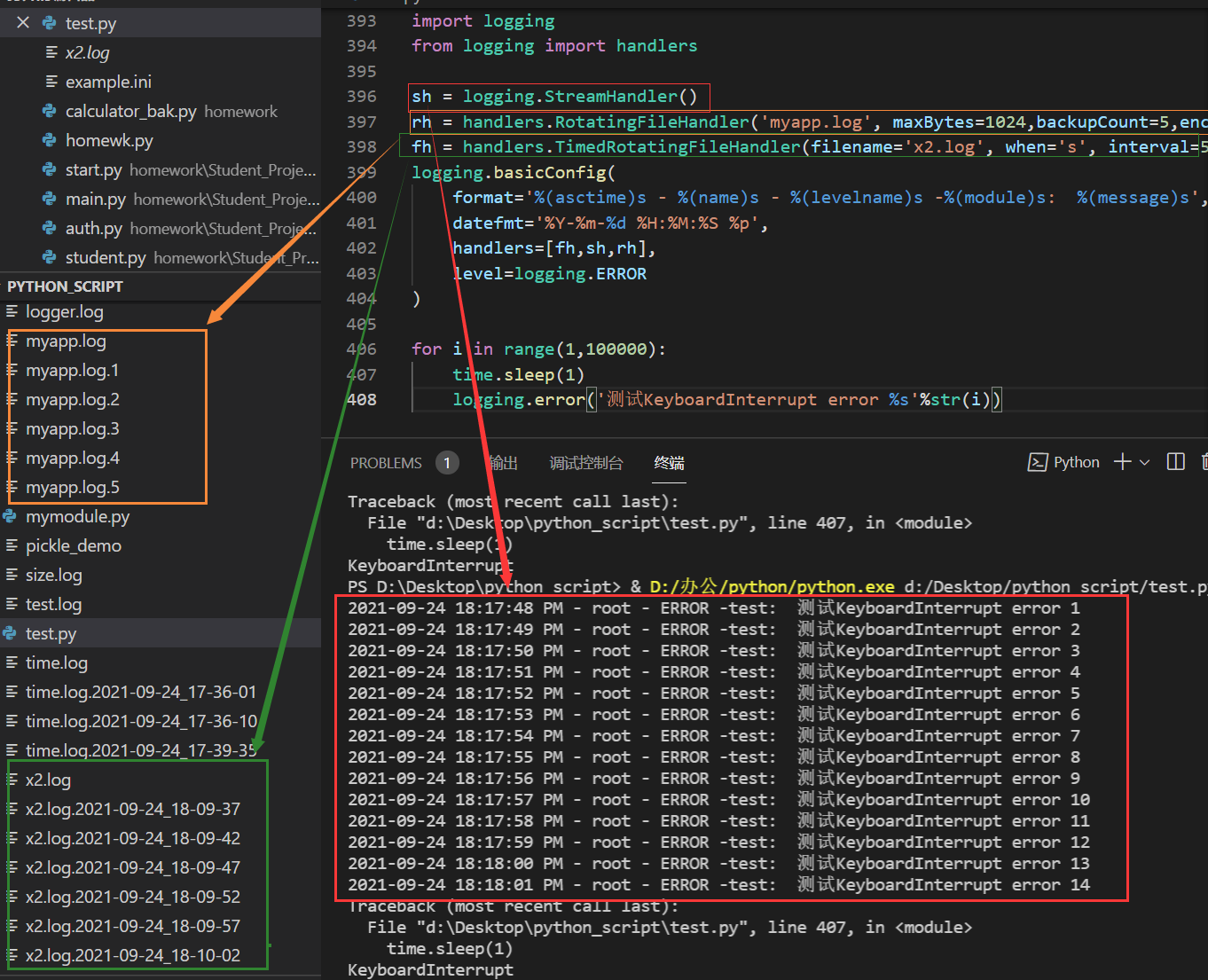
仅使用handler对象:
import time
import logging
from logging import handlers
sh = logging.StreamHandler()
rh = handlers.RotatingFileHandler('myapp.log', maxBytes=1024,backupCount=5,encoding='utf-8')
fh = handlers.TimedRotatingFileHandler(filename='x2.log', when='s', interval=5, encoding='utf-8')
logging.basicConfig(
format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
handlers=[fh,sh,rh],
level=logging.ERROR
)
for i in range(1,100000):
time.sleep(1)
logging.error('测试KeyboardInterrupt error %s'%str(i))
输出结果:
完全面向对象的使用方式
import logging
from logging import handlers
# 1.创建一个logger对象 logging.Logger(这个日志对象的名字,level)
logger1 = logging.Logger('log1', level=logging.ERROR)
logger2 = logging.Logger('log2', level=logging.DEBUG)
# 2.创建Handler对象
# 创建一个文件管理处理器
fh = logging.FileHandler('logger.log',encoding='utf-8')
# 创建一个屏幕管理处理器
sh=logging.StreamHandler()
#创建一个可根据文件大小轮询的处理器
f_sizeh=handlers.RotatingFileHandler("size.log",maxBytes=500,backupCount=3,encoding='utf-8')
#创建一个可根据时间轮询的处理器
f_timeh=handlers.TimedRotatingFileHandler("time.log",when="S",interval=5, encoding='utf-8',backupCount=3)
f_timeh.setLevel(logging.WARNING) #logger与handler都有level参数,日志由 logger--> handler这样过滤的,参数不冲突。
# 3.创建Formatter对象
# 创建一个日志输出的格式
format1 = logging.Formatter("%(asctime)s %(levelname)s: %(filename)s %(lineno)d %(message)s",datefmt='%Y-%m-%d %H:%M:%S')
# format2 =
# 4.handler绑定formatter
# 文件管理操作符 绑定一个 格式
fh.setFormatter(format1)
# 屏幕管理操作符 绑定一个 格式
sh.setFormatter(format1)
#文件大小轮询的操作符 绑定一个 格式
f_sizeh.setFormatter(format1)
#时间轮询的操作符 绑定一个 格式
f_timeh.setFormatter(format1)
# logger对象 绑定 文件管理操作符
logger1.addHandler(fh)
# logger 对象 绑定 屏幕管理操作符
logger1.addHandler(sh)
# logger对象 绑定 文件大小轮询的操作符
logger2.addHandler(f_sizeh)
# logger对象 绑定 时间轮询的操作符
logger2.addHandler(f_timeh)
# 输入日志到 logger1 日志对象
logger1.debug("这是debug日志内容")
logger1.info("这是info日志内容")
logger1.warning("这是warning日志内容")
logger1.error("这是error日志内容")
logger1.critical("这是critical日志内容")
# 输入日志到 logger2 日志对象
logger2.debug("这是debug日志内容")
logger2.info("这是info日志内容")
logger2.warning("这是warning日志内容")
logger2.error("这是error日志内容")
logger2.critical("这是critical日志内容")
在项目中使用logging
原理: 以 加载模块 的方式使用单例类, 先实例化了,直接使用
在文件 utils/log.py 中定义一个日志类
import logging
from settings import LOGGING_PATH
# LOGGING_PATH = "logs/xxx.log"
class Logger(object):
def __init__(self,file_path,logger_name,logger_level):
# 创建一个文件输出的handler
file_handler = logging.FileHandler(file_path,'a',encoding='utf-8')
# 创建格式化器
fmt = logging.Formatter("%(asctime)s %(levelname)s: %(filename)s %(lineno)d %(message)s",datefmt='%Y-%m-%d %H:%M:%S')
# 绑定handler 与格式化器
file_handler.setFormatter(fmt)
# 创建日志处理器
self.logger = logging.Logger(logger_name,level=logger_level)
# 绑定日志处理器与 文件输出的handler
self.logger.addHandler(file_handler)
# 错误日志通过日志处理器输入
def error(self,msg):
self.logger.error(msg)
logger = Logger(LOGGING_PATH,'cmdb',logging.WARN)
# logger2 = Logger(LOGGING_PATH,'cmdb',logging.WARN)
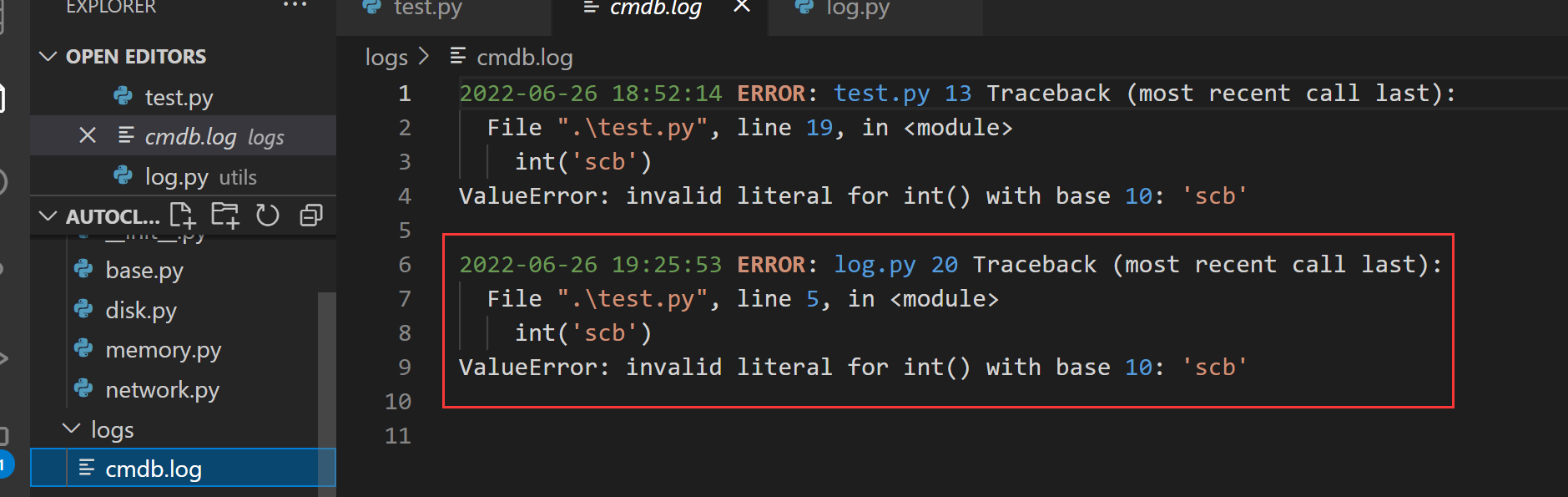
在 test.py 使用日志类演示:
# 加载 logger 实例
from utils.log import logger
import traceback
try:
int('scb')
except Exception as e:
# 输入错误信息到日志对象
logger.error(traceback.format_exc())
结果:
collections模块
在内置数据类型(dict、list、set、tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter、deque、defaultdict、namedtuple和OrderedDict等。
namedtuple
namedtuple: 命名元组,可以用来定义某种数据结构的元组,例如 坐标(x,y)
from collections import namedtuple
# 创建一个命名元组,元组类型名为places(自定义的),元组中包含两个元素x与y,
point=namedtuple("places",["x","y"]) # 相当于创建了一个名为point的类
p1=point(1,2) # 实例化这个类
print(p1) #places(x=1, y=2)
print(p1.x) #1
print(p1.y) #2
Counter
Counter:计数器,Counter(可迭代对象)
c=Counter("666778666")
print(c) # Counter({'6': 6, '7': 2, '8': 1})
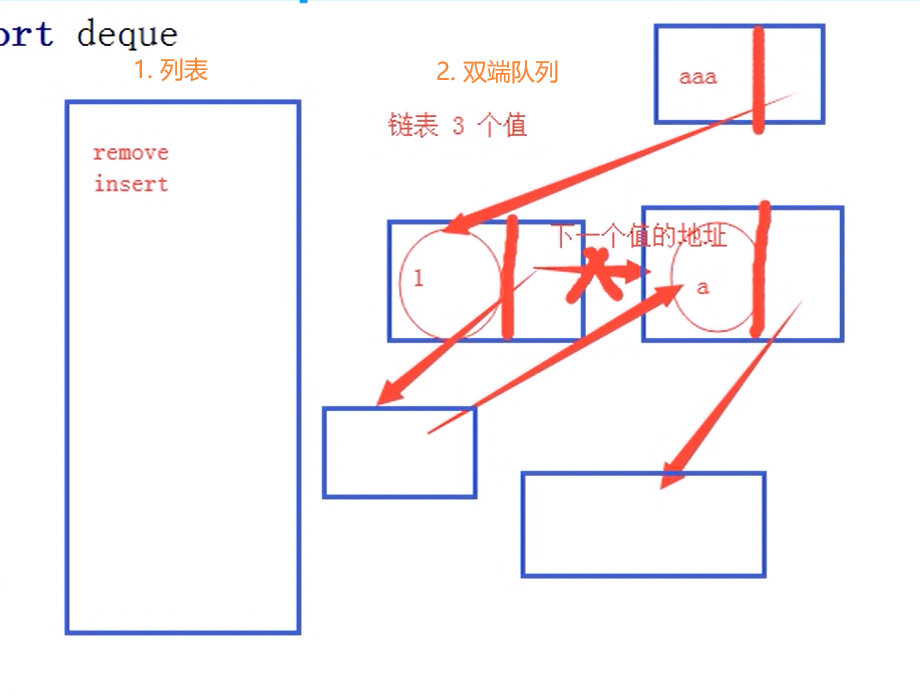
deque
deque: 双端队列,可以快速的从另外一侧追加和推出对象
使用list存储数据时,按索引访问元素很快,但是插入和删除中间的元素就很慢了,因为list是线性存储,数据量大的时候,插入和删除效率很低。
deque是一种能实现高效实现插入和删除操作的双向列表,适合用于队列和栈:
方法:
append() 和列表一样,从列表右边末尾添加某个元素
appendleft() 从列表左边开头添加某个元素
pop() 删除列表右边的第一个元素
popleft() 删除列表左边的第一个元素
remove("b") 删除指定元素"b"
insert(1,'123') 在index为1的地方插入元素"123"
使用:
from collections import deque
dq = deque()
dq.append(1)
dq.append(2)
dq.append("a")
print(dq) #输出 deque([1, 2, 'a'])
dq.appendleft("b")
dq.appendleft("c")
print(dq) #输出 deque(['c', 'b', 1, 2, 'a'])
dq.pop()
print(dq) #输出 deque(['c', 'b', 1, 2])
dq.popleft()
print(dq) #输出 deque(['b', 1, 2])
dq.remove("b")
print(dq) #输出 deque([1, 2])
dq.insert(1,'123')
print(dq) #输出 deque([1, '123', 2])
列表和双端队列存储的数据结构方式的不同:
-
列表在一块连续的内存空间里存储数据,删除其中某一个中间的元素,其他都要往前移动一位,在中间插入一个元素,其他元素也要往后移动一位,给新插入的元素空出一个位置。
-
双端队列是链表的结构。每一个值都有自己的内存空间,并有一个链接指向下一个值的内存地址。插入或删除中间元素,只要修改链接的指向就行,所以效率更高。
注:部分内容来源于网络
队列queue
用于同一进程内的队列,不能做多进程之间的通信。
这里介绍三种队列:
q = queue.Queue() 先进先出队列
q.put(数据)
q = queue.LifoQueue() 后进先出队列
q.put(数据)
q = queue.PriorityQueue() 优先级队列
所有数据的优先级必须是同一种类型,如果是数字,就比较大小,越小越优先被取出;如果是字符串,就比较ASCII码的位置,越靠前越优先。
q.put((优先级,数据)) 优先级队列,put()方法接收的是一个元组(),第一个位置是优先级,第二个位置是数据
三种队列都用q.get()取值
使用
import queue
q1=queue.Queue() #先进先出
q1.put("zz")
q1.put(2)
q1.put("A")
print(q1.get())
print(q1.get())
print(q1.get())
# 输出:
# zz
# 2
# A
q2=queue.LifoQueue() #后进先出
q2.put("hhh")
q2.put(1)
q2.put("**#")
print(q2.get())
print(q2.get())
print(q2.get())
# 输出:
# **#
# 1
# hhh
q3=queue.PriorityQueue() #优先级比较数字
q3.put((2,"c"))
q3.put((-4,"b"))
q3.put((12,"a"))
print(q3.get())
print(q3.get())
print(q3.get())
# 输出:
# (-4, 'b')
# (2, 'c')
# (12, 'a')
q4=queue.PriorityQueue() #优先级比较字符
q4.put(("CCA","c")) #C ASCII 67的位置
q4.put(("a","b")) #a 97
q4.put(("CFa","a")) #F 70
print(q4.get())
print(q4.get())
print(q4.get())
# 输出:
# ('CCA', 'c')
# ('CFa', 'a')
# ('a', 'b')
subprocess模块
可以用来在python中执行系统命令
# ret=subprocess.Popen("cmd",shell=True,stdout=subprocess.PIPE,stderr=subprocess.PIPE)
# stdout=ret.stdout.read().decode()
# stderr=ret.stderr.read().decode()
#cmd为系统命令
#shell=True 就是将cmd当成系统命令执行
struct模块
这里只是记录其中的一个小功能。
可以将数字或浮点数转换为固定长度的bytes类型。
在网络传输中,需要告知对方传输内容的长度,可以将长度的字段使用此模块转换为固定的4个字节,方便服务端获取。
p=struct.pack("x类型",value) 将x类型的value转换为4个字节长度的bytes类型。i为int类型,f为float类型。
unp=struct.unpack("x类型",p) 将pack转换的对象转回x类型,返回为元组。unp[0]可获取。
import struct
c=struct.pack("i",12)
print(c,len(c)) #=> b'\x0c\x00\x00\x00' 4
s=struct.unpack("i",c)
print(s) # => (12,)
print(s[0],type(s[0])) #=> 12 <class 'int'>
c=struct.pack("f",4.3)
print(c,len(c)) #=> b'\x9a\x99\x89@' 4
s=struct.unpack("f",c)
print(s) # => (4.300000190734863,) 这里多的那些小数位应该是里面算法或系统的问题,不用纠结
print(s[0],type(s[0])) #=> 4.300000190734863 <class 'float'>
importlib
正常import方式加载模块
#在同级目录中有个mylib\b.py
name = 'yxf'
#在当前脚本中加载b文件
from mylib import b
print(b.name) #yxf
使用importlib可以以字符串的形式加载b
# 此方法最小只能加载到文件名,不能到文件名中的方法或类
import importlib
ret = importlib.import_module('mylib.b')
print(ret) # <module 'mylib.b' from 'd:\\ѧϰ\\python_script\\homework\\mylib\\b.py'>
print(ret.name) # yxf
在很多地方都能使用此模块,在配置中添加/注释 字符串 来决定加载哪些功能,例如django的中间件。
PIL模块(图片处理)
模块安装
pip3 install pil
# 如果上面安装不成功尝试以下命令
pip install Pillow
PIL处理图片功能很丰富,这里只简单演示生成一个图片验证码
from PIL import Image,ImageDraw,ImageFont
'''
Image - 生成图片
ImageDraw - 能在图片上写与画
ImageFont - 控制字体样式
# 生成一个图片对象
img_obj = Image.new(模式,尺寸,颜色)
# 模式: 'RGB'为(3x8 位像素,真彩色),
# 'L'为(8 位像素,黑白), 还有其他模式,可自行了解
# 尺寸: (长,宽)
# 颜色: 可以写 'red'这种类型,也可以用 (255,123,66)
# 生成一个画笔对象
img_draw = ImageDraw.Draw(img_obj)
# 定义字体样式
img_font = ImageFont.truetype(字体文件ttf,字体尺寸)
# 在图片上书写
img_draw.text(坐标,文本内容,文字颜色,字体样式)
# 坐标: (x,y)
# 保存图片
img_obj.save(文件句柄,图片格式)
图片格式: 常见的包括JPEG,PNG等格式,不写此参数默认用文件后缀名的格式
'''
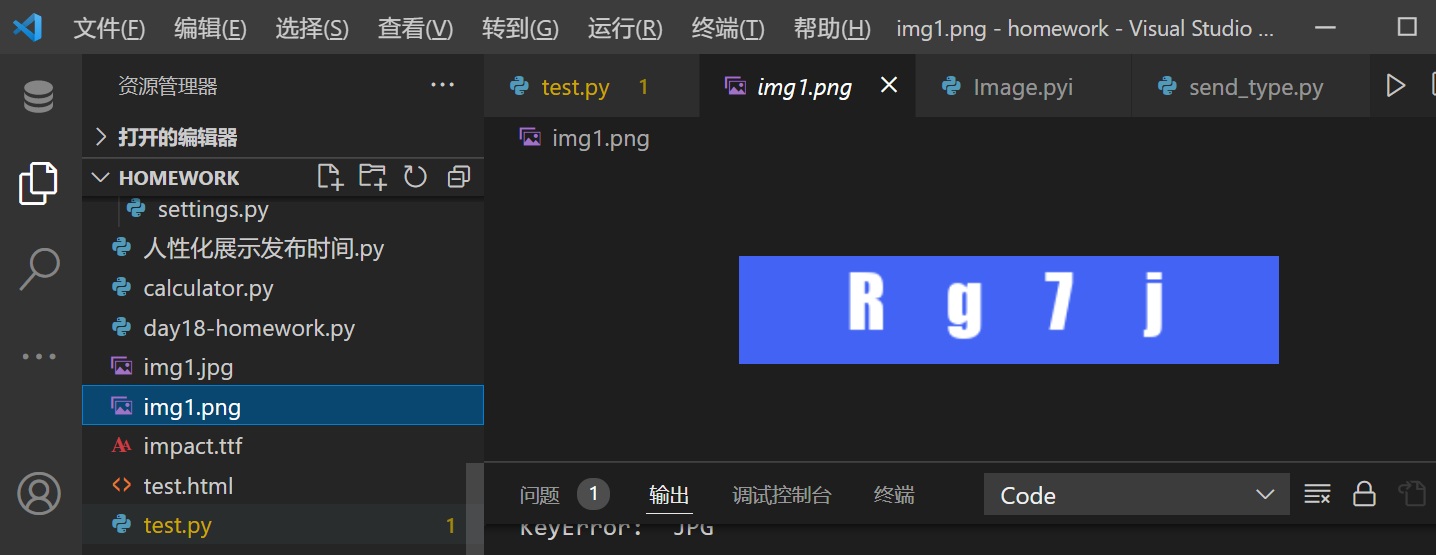
img_obj = Image.new('RGB',(300,60),(66,99,244))
img_draw = ImageDraw.Draw(img_obj)
img_font = ImageFont.truetype('impact.ttf',40)
code='Rg7j'
# 这里为什么不直接写,而是用for循环一个字符一个字符的写?
# 因为这样才能定义字符间距
for i in range(len(code)):
img_draw.text((55*i+60,0),code[i],(255,255,255),img_font)
# jpeg和jpg都是一种格式,jpg是简称,img_obj.save(f,format='jpeg'),这里的format必须是jpeg,简称将不被识别
# with open('img1.jpg','wb') as f:
# img_obj.save(f,'jpeg')
with open('img1.png','wb') as f:
img_obj.save(f,'png')
io 内存管理模块
将某对象临时存储到内存
from io import BytesIO,StringIO
'''
BytesIO 临时存储数据到内存,返回的数据是二进制
StringIO 临时存储数据到内存,返回的数据是字符串
'''
# 生成一个BytesIO类型的文件句柄对象
io_obj = BytesIO()
# 存储图片对象 这个.save是(from PIL import Image) img_obj的方法,不是BytesIO的。
img_obj.save(io_obj,'png')
#.getvalue()拿取数据,返回二进制格式数据
ret = io_obj.getvalue()
print(ret)
beautifulsoup4
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库。
功能很多,这里只列举我用到几种用法。
官方文档: https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
安装
pip3 install beautifulsoup4
使用
# 加载模块
from bs4 import BeautifulSoup
# content是一个前端页面 有一个script标签
content = '''<p style='font-family:"font-size:1rem;color:#7F8C93;background-color:#FFFFFF;'> <img alt="" class="medium-zoom-image" src="https://img2022.cnblogs.com/blog/1314872/202203/1314872-20220320174905289-517097646.png" style="height:auto;"/> </p> <p style='font-family:"font-size:1rem;color:#7F8C93;background-color:#FFFFFF;'> <strong>建表</strong> </p> <p style='font-family:"font-size:1rem;color:#7F8C93;background-color:#FFFFFF;'> 模型层 app01\models.py </p><script>alert(123)</script>'''
# bs4的使用 'html.parser'为python自带的html解析器
soup = BeautifulSoup(content,'html.parser')
# 获取到所有标签
content_eles = soup.find_all()
# content_tag是一个一个的标签对象
for content_ele in content_eles:
# 将提交内容中的script标签删掉,防止xss攻击
if content_ele.name == 'script':
content_ele.decompose()
# 获取到内容中的纯文本,截取前10个字符为desc字段
# print(type(soup)) # <class 'bs4.BeautifulSoup'> 存储上要用str(soup)
desc = soup.text[0:10]
# 获取到净化后的页面代码
content=str(soup)
print(content)
paramiko
远程连接服务器,执行命令,获取结果
用户名密码连接
import paramiko
# 创建 ssh 对象
ssh = paramiko.SSHClient()
# 允许连接不在 know_hosts文件中的主机(不用输入yes)
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
# 连接远程服务器
ssh.connect(hostname='192.168.1.10',port=22,username='root',password='123')
# 在远程服务器执行命令
stdin,stdout,stderr = ssh.exec_command('df')
# 获取命令结果
result = stdout.read()
# 关闭连接
ssh.close()
print(result.decode('utf-8'))
key连接
执行以下命令, 将在用户家目录的 .ssh/ 下生成一对key (windows 在powershell 中执行, git bash 中执行生成的key会有问题)
PS C:\Users\User> ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (C:\Users\User/.ssh/id_rsa):
Created directory 'C:\Users\User/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in C:\Users\User/.ssh/id_rsa.
Your public key has been saved in C:\Users\User/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:AkXGHS0tGK7jKAw833fGFna44c2s1KdPXG5ppsNbjSQ user@DESKTOP-UFNH581
The key's randomart image is:
+---[RSA 3072]----+
| o=+.+ |
| +o + o |
| . . o |
|. o . |
|.o o . S= .E .. |
|o oo.. .+ X .oo.o|
|...... . O =.+.B.|
| . . = . +o* |
| . ..+o |
+----[SHA256]-----+
然后将公钥 复制到要连接的远程机 (powershell 中找不到此命令,可尝试用 git bash 执行)
# 拷贝公钥到远程机器
$ ssh-copy-id root@192.168.1.10
# 连接远程机试试
$ ssh 'root@192.168.1.10'
Last login: Fri Jun 24 14:24:46 2022 from 192.168.1.7
[root@vm3 ~]#
# 查看远程机的~/.ssh/authorized_keys,可以看到公钥已经追加到此文件中
[root@vm3 ~]# cat ~/.ssh/authorized_keys
paramiko 使用 key连接远程机器
import paramiko
# 指定私钥路径
private_key = paramiko.RSAKey.from_private_key_file(r'C:\\Users\\User\\.ssh\\id_rsa')
# 创建 ssh 对象
ssh = paramiko.SSHClient()
# 允许连接不在 know_hosts文件中的主机(不用输入yes)
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
# 连接远程服务器
ssh.connect(hostname='192.168.1.10',port=22,username='root',pkey=private_key)
# 在远程服务器执行命令
stdin,stdout,stderr = ssh.exec_command('df')
# 获取命令结果
result = stdout.read()
# 关闭连接
ssh.close()
print(result.decode('utf-8'))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号