

6.3 OrderBy 优化
1. 创建实例
create table tblA( age int, birth TIMESTAMP not null ); insert into tblA(age,birth) values(22,now()); insert into tblA(age,birth) values(23,now()); insert into tblA(age,birth) values(24,now()); create index idx_A_ageBirth no tblA(age,birth); select * from tblA;
2.查询实例
a.
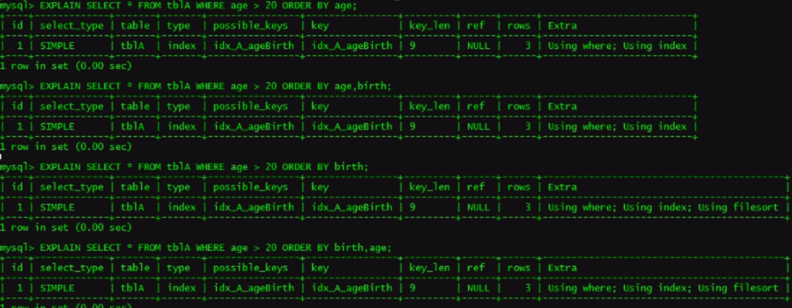
b.
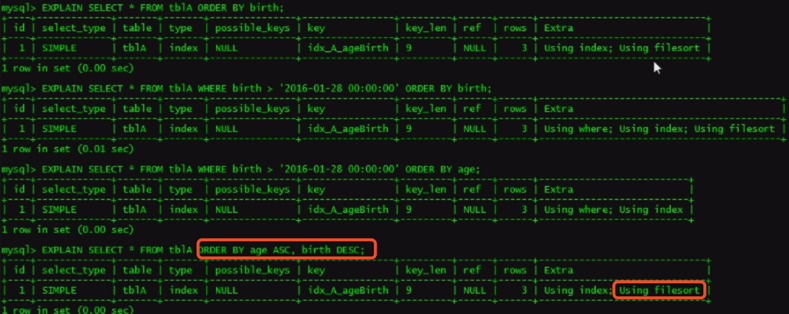
小总结:OrderBy满足两种情况,会使用Index方式排序
order by 语句使用索引最左前列。 使用where子句与Order by 子句条件列组合满足索引最左前列。
3. 如果不在索引列上,filesort有两种算法(双路排序、单路排序)
双路排序: mysql4.1之前是使用双路排序,字面意思就是两次扫描磁盘,最终得到数据, 读取行指针和orderby列,对他们进行排序,然后扫描已经排好序的列表,按照列表中的值重新从列表中读取对应的数据输出。 取一批数据,要对磁盘惊进行两次扫描,众所周知,I/O是很耗时间,所以在mysql4.1之后,出现了第二种改进的算法,就是单路排序。 单路排序: 从磁盘读取查询需要的所有列,按照orderby列在buffer对他们进行排序,然后扫描排序后的列表进行输出, 它的效率更快一些,避免了第二次读取数据。并且把随机IO变成了顺序IO,但是它会使用等多的空间,因为他的每一行数据都是保存在内存中。 单路排序引发的问题: 在sort_buffer中,单路比双路要多占用很多空间,因为单路是把所有的数据都去出来,所以可能取出的数据总大小超出了sort_buffer的容量,导致每次只能取sort_buffer容量大小的数据,进行排序(创建tmp文件,多路合并),排完再取sort_buffer容量大小,再排……从而多次I/O。 本来想省一次I/O操作,反而导致了大量的I/O操作,反而得不偿失。
优化策略:
增大sort_buffer_size参数的设置 增大max_length_for_sort_data参数设置 why? 1. Order by时select * 是一个大忌Query需要的字段,这点非常重要。在这里的影响是: a. 当Query的字段大小总和小于max_length_for_sort_data而且排序字段不是TEXT|BLOB类时,会用改进后的算法——单路排序,否则用老算法——多路排序。 b. 两种算法的数据都有可能超出sort_buffer的容量,超出之后,会创建tmp文件进行合并排序,导致多次I/O,但是用单路排序算法的风险会更大一些,所以要提高sort_buffer_size。 2. 尝试提高sort_buffer_size 不管用哪种算法,提高这个参数都会提高效率,当然,要根据系统的能力去提高,因为这个参数是针对每个进程的。 3.尝试提高max_length_for_sort_data 提高这个参数,会增加用改进算法的概率,但是如果设的太高,数据总容量超出sort_buffer_size的概率就会增大,明显症状就是高的磁盘I/O活动和低的处理器使用率。
小总结:


关注我的公众号,精彩内容不能错过
作者:程序员果果
出处:blog.itwolfed.com
欢迎关注公众号——《程序员果果》 ,分享SpringBoot、SpringCloud、Dubbo、Golang、Docker相关知识与技巧。
原创 Java 博客,点我看看?

