

hdfs集群的扩容和缩容
1、背景
当我们的hadoop集群运行了一段时间之后,原有的数据节点的容量已经不能满足我们的存储了,这个时候就需要往集群中增加新的数据节点。此时我们就需要动态的对hdfs集群进行扩容操作(节点服役)。
2、集群黑白名单
在hdfs集群中是存在黑名单和白名单的。
黑名单: 该文件包含不允许连接到namenode的主机列表。必须指定文件的完整路径名。如果该值为空,则表示不排除任何主机。
白名单: 该文件包含允许连接到namenode的主机列表。必须指定文件的完整路径名。如果该值为空,则允许所有主机
黑白名单配置
vim hdfs-site.xml
<!-- 配置黑名单,使用黑名单可以下线集群 --> <property> <name>dfs.hosts.exclude</name> <value>/opt/bigdata/hadoop-3.3.4/etc/hadoop/blacklist.hosts</value> </property> <!-- 配置白名单,只有白名单中的节点才可以访问namenode --> <property> <name>dfs.hosts</name> <value>/opt/bigdata/hadoop-3.3.4/etc/hadoop/whitelist.hosts</value> </property>
注意: 第一次配置黑白名单时,需要重启集群才可以生效,之后修改了黑白名单文件,只需要执行 hdfs dfsadmin -refreshNodes命令即可。
3、准备一台新的机器并配置好hadoop环境
3.1 我们现有的集群规划

3.2 准备一台新的机器
- ip地址: 192.168.121.143
- 主机名: hadoop04
3.2.1 查看新机器的ip

3.2.2 修改主机名和host映射
[root@appbasic ~]# vim /etc/hostname [root@appbasic ~]# cat /etc/hostname hadoop04 [root@appbasic ~]# vim /etc/hosts [root@appbasic ~]# cat /etc/hosts 192.168.121.140 hadoop01 192.168.121.141 hadoop02 192.168.121.142 hadoop03 192.168.121.143 hadoop04 [root@appbasic ~]#
3.2.3 配置时间同步
hadoop集群中的各个机器之间的时间最好都保持一致
[root@hadoop04 ~]# ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime [root@hadoop04 ~]# yum install ntp 已加载插件:fastestmirror Loading mirror speeds from cached hostfile base | 3.6 kB 00:00:00 extras | 2.9 kB 00:00:00 updates | 2.9 kB 00:00:00 (1/2): extras/7/aarch64/primary_db | 252 kB 00:00:00 (2/2): updates/7/aarch64/primary_db | 3.5 MB 00:00:03 软件包 ntp-4.2.6p5-29.el7.centos.2.aarch64 已安装并且是最新版本 无须任何处理 [root@hadoop04 ~]# systemctl enable ntpd [root@hadoop04 ~]# service ntpd restart Redirecting to /bin/systemctl restart ntpd.service [root@hadoop04 ~]# ntpdate asia.pool.ntp.org 29 Mar 21:42:52 ntpdate[1697]: the NTP socket is in use, exiting [root@hadoop04 ~]# /sbin/hwclock --systohc [root@hadoop04 ~]# timedatectl Local time: 三 2023-03-29 21:43:03 CST Universal time: 三 2023-03-29 13:43:03 UTC RTC time: 三 2023-03-29 13:43:03 Time zone: Asia/Shanghai (CST, +0800) NTP enabled: yes NTP synchronized: no RTC in local TZ: no DST active: n/a [root@hadoop04 ~]# timedatectl set-ntp true [root@hadoop04 ~]#
3.2.4 关闭防火墙
[root@hadoop04 ~]# systemctl stop firewalld systemctl stop firewalld [root@hadoop04 ~]# systemctl disable firewalld.service Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service. Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service. [root@hadoop04 ~]#
3.2.5 新建hadoop部署用户
[root@hadoop04 ~]# useradd hadoopdeploy [root@hadoop04 ~]# passwd hadoopdeploy 更改用户 hadoopdeploy 的密码 。 新的 密码: 无效的密码: 密码包含用户名在某些地方 重新输入新的 密码: passwd:所有的身份验证令牌已经成功更新。 [root@hadoop04 ~]# vim /etc/sudoers [root@hadoop04 ~]# cat /etc/sudoers | grep hadoopdeploy -C 3 ## Same thing without a password # %wheel ALL=(ALL) NOPASSWD: ALL hadoopdeploy ALL=(ALL) NOPASSWD: ALL ## Allows members of the users group to mount and unmount the ## cdrom as root [root@hadoop04 ~]#
3.2.6 复制hadoop04机器上的/etc/hosts文件到集群的另外3台机器上
[root@hadoop04 ~]# scp /etc/hosts root@hadoop01:/etc/hosts [root@hadoop04 ~]# scp /etc/hosts root@hadoop02:/etc/hosts [root@hadoop04 ~]# scp /etc/hosts root@hadoop03:/etc/hosts
3.2.7 配置集群间的免密登录
此处配置 namenode(hadoop01)与hadoop04之间的免密登录。
[hadoopdeploy@hadoop01 ~]$ ssh-copy-id hadoop04 /usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/hadoopdeploy/.ssh/id_rsa.pub" The authenticity of host 'hadoop04 (192.168.121.143)' can't be established. ECDSA key fingerprint is SHA256:4GL0zHVCdSl3czA0wqcuLT60lUljyEq3DqwPFxNwYsE. ECDSA key fingerprint is MD5:3e:42:a6:50:0d:fb:f0:41:a8:0d:fb:cc:fd:20:2c:c8. Are you sure you want to continue connecting (yes/no)? yes /usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed /usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys hadoopdeploy@hadoop04's password: Number of key(s) added: 1 Now try logging into the machine, with: "ssh 'hadoop04'" and check to make sure that only the key(s) you wanted were added. [hadoopdeploy@hadoop01 ~]$
3.2.8将 namenode上的hadoop复制到hadoop04上
[root@hadoop04 ~]# sudo mkdir /opt/bigdata mkdir: cannot create directory ‘/opt/bigdata’: No such file or directory [root@hadoop04 ~]# sudo mkdir -p /opt/bigdata [root@hadoop04 ~]# sudo chown -R hadoopdeploy:hadoopdeploy /opt/bigdata/ [root@hadoop04 ~]# su - hadoopdeploy Last login: Wed Mar 29 22:19:54 CST 2023 on pts/0 [hadoopdeploy@hadoop04 ~]$ scp -r hadoopdeploy@hadoop01:/opt/bigdata/hadoop-3.3.4/ /opt/bigdata/ [hadoopdeploy@hadoop04 hadoop]$ rm -rvf /opt/bigdata/hadoop-3.3.4/data/* rm -rvf /opt/bigdata/hadoop-3.3.4/logs/*
注意 目录的创建用户、执行scp命令的用户
注意: 如果hadoop-3.3.4目录下存在我们之前配置的数据目录,则需要删除,否则启动这个节点的时候会有问题。日志目录也相应的删除
3.2.9 配置 workers文件
配置这个文件是为了方便集群的一键启动。
[hadoopdeploy@hadoop04 hadoop]$ vim /opt/bigdata/hadoop-3.3.4/etc/hadoop/workers [hadoopdeploy@hadoop04 hadoop]$ cat /opt/bigdata/hadoop-3.3.4/etc/hadoop/workers hadoop01 hadoop02 hadoop03 hadoop04 [hadoopdeploy@hadoop04 hadoop]$
注意: 将这个workers文件分发到集群的各个机器上。
[hadoopdeploy@hadoop04 hadoop]$ scp /opt/bigdata/hadoop-3.3.4/etc/hadoop/workers hadoopdeploy@hadoop01:/opt/bigdata/hadoop-3.3.4/etc/hadoop/workers [hadoopdeploy@hadoop04 hadoop]$ scp /opt/bigdata/hadoop-3.3.4/etc/hadoop/workers hadoopdeploy@hadoop02:/opt/bigdata/hadoop-3.3.4/etc/hadoop/workers [hadoopdeploy@hadoop04 hadoop]$ scp /opt/bigdata/hadoop-3.3.4/etc/hadoop/workers hadoopdeploy@hadoop03:/opt/bigdata/hadoop-3.3.4/etc/hadoop/workers
3.2.10 配置环境变量
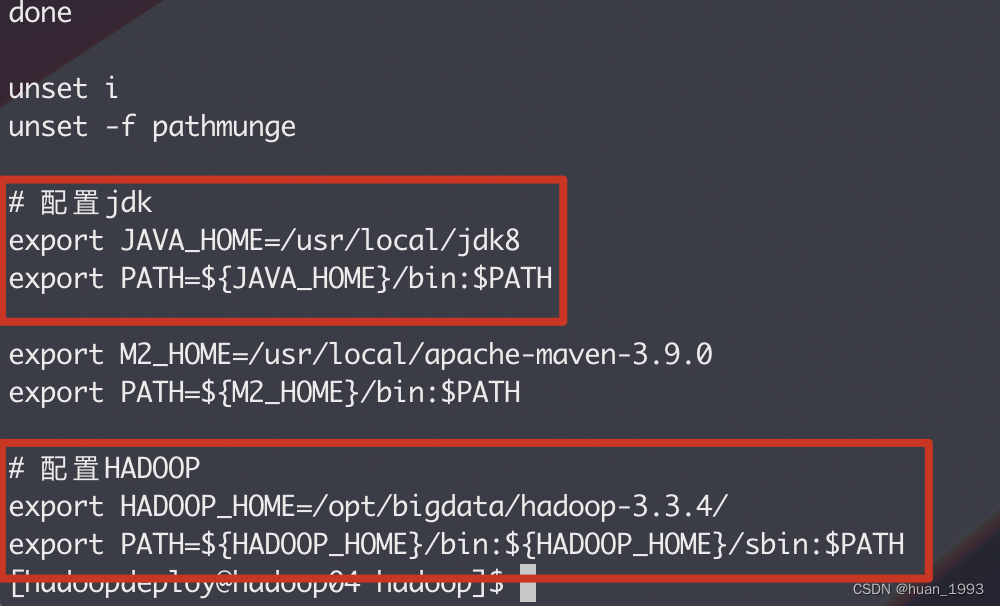
[hadoopdeploy@hadoop04 hadoop]$ source /etc/profile
3.2.11 查看之前集群的节点

3.3 启动新加入的namenode
[hadoopdeploy@hadoop04 logs]$ hdfs --daemon start datanode [hadoopdeploy@hadoop04 logs]$ jps 2278 DataNode 2349 Jps [hadoopdeploy@hadoop04 logs]$

注意: 如果我们不想让任意一台机器随便就加入到了我们的集群中,那么我们通过白名单来控制。
3.3.1 节点之间的数据平衡
新加入的节点磁盘空间比较大,这个时候我们就可以将别的节点的数据均衡到这个节点中来。
# 设置数据传输带宽 [hadoopdeploy@hadoop04 logs]$ hdfs dfsadmin -setBalancerBandwidth 10485760 Balancer bandwidth is set to 10485760 # 执行banalce [hadoopdeploy@hadoop04 logs]$ hdfs balancer -policy datanode -threshold 5
3.4 集群节点下线
3.4.1 编辑dfs.hosts.exclude配置指定的文件
注意: 只需要在NameNode或者ResourceManager上执行即可。
vim hdfs-site.xml
<!-- 配置黑名单,使用黑名单可以下线集群 --> <property> <name>dfs.hosts.exclude</name> <value>/opt/bigdata/hadoop-3.3.4/etc/hadoop/blacklist.hosts</value> </property>
注意: 这个配置文件如果之间没有配置过,则需要重启集群才生效,如果之前配置过,则在NameNode或ResourceManager节点上执行hdfs dfsadmin -refreshNodes命令即可。
3.4.2 下线节点
编辑blacklist.hosts文件,加入需要下线的节点。(NameNode或ResourceManager上操作 )
[hadoopdeploy@hadoop01 ~]$ cd /opt/bigdata/hadoop-3.3.4/etc/hadoop/ [hadoopdeploy@hadoop01 hadoop]$ vim blacklist.hosts [hadoopdeploy@hadoop01 hadoop]$ cat blacklist.hosts hadoop04 [hadoopdeploy@hadoop01 hadoop]$ hdfs dfsadmin -refreshNodes Refresh nodes successful [hadoopdeploy@hadoop01 hadoop]$

在hdfs集群上可以看到hadoop04已经下线了.
节点移除后,可以考虑再次均衡集群中的数据。
注意: 此时可以看到我们的集群中有4台机器,假设我们集群的副本设置为4,那么此时是不可下线节点的,需要修改集群的副本<4。
3.4.3 关闭下线的datanode节点
[hadoopdeploy@hadoop04 logs]$ hdfs --daemon stop datanode [hadoopdeploy@hadoop04 logs]$
3.4.4 清空黑名单里的内容
本文来自博客园,作者:huan1993,转载请注明原文链接:https://www.cnblogs.com/huan1993/p/17286012.html



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?