
elasticsearch使用ik中文分词器
elasticsearch使用ik中文分词器
一、背景
es自带了一堆的分词器,比如standard、whitespace、language(比如english)等分词器,但是都对中文分词的效果不太好,此处安装第三方分词器ik,来实现分词。
二、安装 ik 分词器
1、从 github 上找到和本次 es 版本匹配上的 分词器
# 下载地址
https://github.com/medcl/elasticsearch-analysis-ik/releases
2、使用 es 自带的插件管理 elasticsearch-plugin 来进行安装
- 直接从网络地址安装
cd /Users/huan/soft/elastic-stack/es/es02/bin
# 下载插件
./elasticsearch-plugin -v install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.0/elasticsearch-analysis-ik-7.12.0.zip
# 查看插件是否下载成功
./elasticsearch-plugin list
- 从本地安装
cd /Users/huan/soft/elastic-stack/es/es02/bin
# 下载插件(file后面跟的是插件在本地的地址)
./elasticsearch-plugin install file:///path/to/plugin.zip
注意:
如果本地插件的路径中存在空格,需要使用双引号包装起来。
3、重启es
# 查找es进程
jps -l | grep 'Elasticsearch'
# 杀掉es进程
kill pid
# 启动es
/Users/huan/soft/elastic-stack/es/es01/bin/elasticsearch -d -p pid01
三、测试 ik 分词
ik分词器提供了2种分词的模式
ik_max_word: 将需要分词的文本做最小粒度的拆分,尽量分更多的词。ik_smart: 将需要分词的文本做最大粒度的拆分。
1、测试默认的分词效果
语句
GET _analyze
{
"analyzer": "default",
"text": ["中文分词语"]
}
结果
{
"tokens" : [
{
"token" : "中",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<IDEOGRAPHIC>",
"position" : 0
},
{
"token" : "文",
"start_offset" : 1,
"end_offset" : 2,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "分",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "词",
"start_offset" : 3,
"end_offset" : 4,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "语",
"start_offset" : 4,
"end_offset" : 5,
"type" : "<IDEOGRAPHIC>",
"position" : 4
}
]
}
可以看到默认的分词器,对中文的分词完全无法达到我们中文的分词的效果。
2、测试 ik_max_word 的分词效果
语句
GET _analyze
{
"analyzer": "ik_max_word",
"text": ["中文分词语"]
}
结果
{
"tokens" : [
{
"token" : "中文",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "分词",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "词语",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
}
]
}
可以看到基于ik分词可以达到我们需要的分词效果。
3、测试 ik_smart 的分词效果
语句
GET _analyze
{
"analyzer": "ik_smart",
"text": ["中文分词语"]
}
结果
{
"tokens" : [
{
"token" : "中文",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "分",
"start_offset" : 2,
"end_offset" : 3,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "词语",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
}
]
}
4、自定义 ik 的启用词和停用词
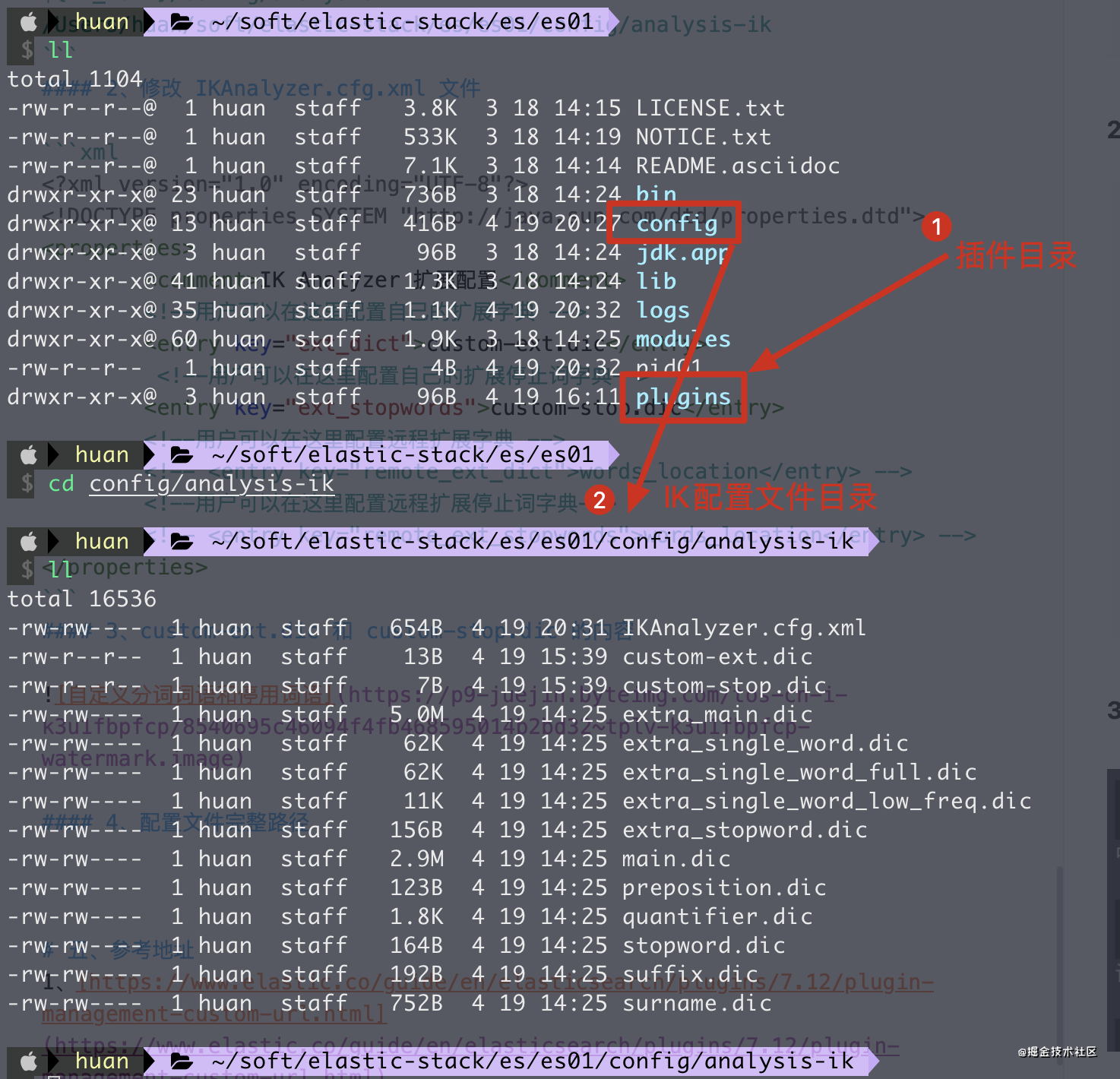
1、找到 ik 的配置目录
${IK_HOME}/config/analysis-ik
/Users/huan/soft/elastic-stack/es/es01/config/analysis-ik
2、修改 IKAnalyzer.cfg.xml 文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">custom-ext.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">custom-stop.dic</entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
3、custom-ext.dic 和 custom-stop.dic 的内容

注意:
1、自定义分词的文件必须是UTF-8的编码。
4、配置文件完整路径
5、查看分词结果

5、热更新IK分词
1、修改 IKAnalyzer.cfg.xml 文件,配置远程字典。
$ cat /Users/huan/soft/elastic-stack/es/es01/config/analysis-ik/IKAnalyzer.cfg.xml 11.87s 16.48G 2.68
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">http://localhost:8686/custom-ext.dic</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<entry key="remote_ext_stopwords"></entry>
</properties>
注意:
1、此处的 custom-ext.dic 文件在下方将会配置到 nginx中,保证可以访问。
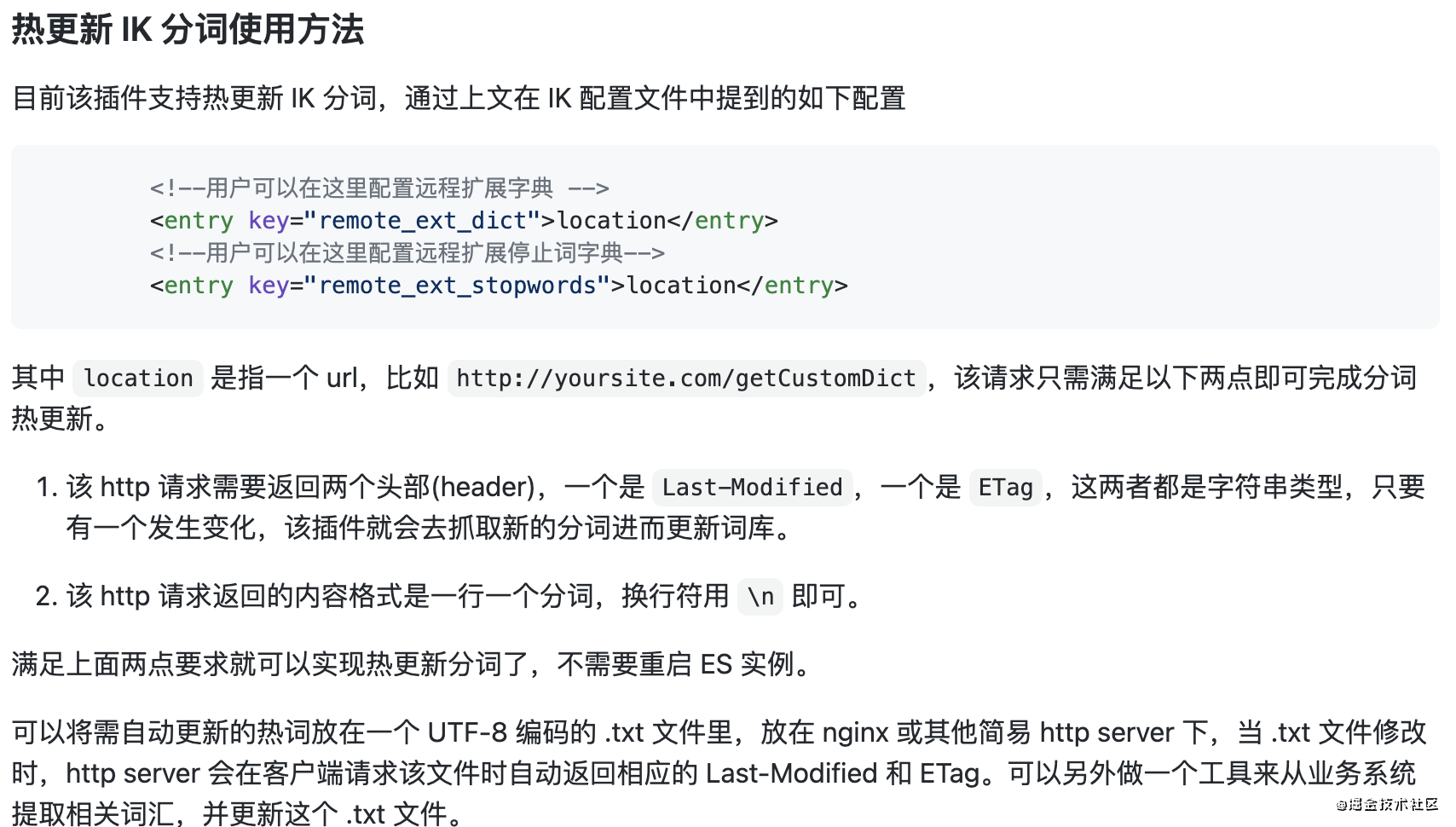
2、http 请求需要返回两个头部(header),一个是 Last-Modified,一个是 ETag,这两者都是字符串类型,只要有一个发生变化,该插件就会去抓取新的分词进而更新词库。
3、http 请求返回的内容格式是一行一个分词,换行符用 \n 即可。
4、在 nginx 的目录下放置一个 custom-ext.dic 文件
多次修改 custom-ext.dic 文件,可以看到分词的结果也会实时变化,如此就实现了分词的热更新。
五、参考地址
1、https://www.elastic.co/guide/en/elasticsearch/plugins/7.12/plugin-management-custom-url.html
2、https://github.com/medcl/elasticsearch-analysis-ik/releases
3、https://github.com/medcl/elasticsearch-analysis-ik
本文来自博客园,作者:huan1993,转载请注明原文链接:https://www.cnblogs.com/huan1993/p/15416100.html
