


elasticsearch父子文档处理(join)
elasticsearch父子文档处理 join
一、背景
在我们工作的过程中,有些时候我们需要用到父子文档的关系映射。**比如:**一个问题有多个答案、一本书籍有多个评论等等。此处我们可以使用 es 的 jion数据类型或 nested来实现。此处我们使用join来建立es中的父子文档关系。
二、需求
我们需要创建一个计划(plan),计划下存在活动(activity)和书籍(book),书籍下存在评论(comments)。
即层级结构为:
plan
/ \
/ \
activity book
|
|
comments
三、前置知识
- 每一个
mapping下只能有一个join类型的字段。 - 父文档和子文档必须在同一个分片(
shard)上。即: 增删改查一个子文档都必须和父文档使用相同的 routing key。 - 每个元素只能有一个父,但是可以存在多个子。
- 可以为一个已经存在的 join 字段增加新的关联关系。
- 可以为一个已经是父的元素增加一个子元素。
join数据类型在elasticsearch中不应该像关系型数据库那种使用。而且has_child和has_parent都是比较消耗性能的。只有当 子的数据 远远大于 父的数据时,使用
join才是有意义的。比如:一个博客下,有多个评论。
四、实现步骤
1、创建 mapping
PUT /plan_index
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"plan_id":{
"type": "keyword"
},
"plan_name":{
"type": "text",
"fields": {
"keyword":{
"type" : "keyword",
"ignore_above" : 256
}
}
},
"act_id":{
"type": "keyword"
},
"act_name":{
"type": "text",
"fields": {
"keyword":{
"type" : "keyword",
"ignore_above" : 256
}
}
},
"comment_id":{
"type": "keyword"
},
"comment_name":{
"type": "text",
"fields": {
"keyword":{
"type" : "keyword",
"ignore_above" : 256
}
}
},
"creator":{
"type": "keyword"
},
"create_time":{
"type": "date",
"format": "yyyy-MM-dd||yyyy-MM-dd HH:mm:ss"
},
"plan_join": {
"type": "join",
"relations": {
"plan": ["activity", "book"],
"book": "comments"
}
}
}
}
}
注意⚠️

2、添加父文档数据
此处添加的是 (plan) 数据。
PUT /plan_index/_doc/plan-001
{
"plan_id": "plan-001",
"plan_name": "四月计划",
"creator": "huan",
"create_time": "2021-04-07 16:27:30",
"plan_join": {
"name": "plan"
}
}
PUT /plan_index/_doc/plan-002
{
"plan_id": "plan-002",
"plan_name": "五月计划",
"creator": "huan",
"create_time": "2021-05-07 16:27:30",
"plan_join": "plan"
}
注意⚠️:
1、如果是创建父文档,则需要使用 plan_join 指定父文档的关系的名字(此处为plan)。
2、plan_join为创建索引的 mapping时指定join的字段的名字。
3、指定父文档时,plan_join的这2种写法都可以。
3、添加子文档
PUT /plan_index/_doc/act-001?routing=plan-001
{
"act_id":"act-001",
"act_name":"四月第一个活动",
"creator":"huan.fu",
"plan_join":{
"name":"activity",
"parent":"plan-001"
}
}
PUT /plan_index/_doc/book-001?routing=plan-001
{
"book_id":"book-001",
"book_name":"四月读取的第一本书",
"creator":"huan.fu",
"plan_join":{
"name":"book",
"parent":"plan-001"
}
}
PUT /plan_index/_doc/book-002?routing=plan-001
{
"book_id":"book-002",
"book_name":"编程珠玑",
"creator":"huan.fu",
"plan_join":{
"name":"book",
"parent":"plan-001"
}
}
PUT /plan_index/_doc/book-003?routing=plan-002
{
"book_id":"book-003",
"book_name":"java编程思想",
"creator":"huan.fu",
"plan_join":{
"name":"book",
"parent":"plan-002"
}
}
# 理论上 comment 的父文档是 book ,但是此处routing使用 plan 也是可以的。
PUT /plan_index/_doc/comment-001?routing=plan-001
{
"comment_id":"comment-001",
"comment_name":"这本书还可以",
"creator":"huan.fu",
"plan_join":{
"name":"comments",
"parent":"book-001"
}
}
PUT /plan_index/_doc/comment-002?routing=plan-001
{
"comment_id":"comment-002",
"comment_name":"值得一读,棒。",
"creator":"huan.fu",
"plan_join":{
"name":"comments",
"parent":"book-001"
}
}
注意⚠️:
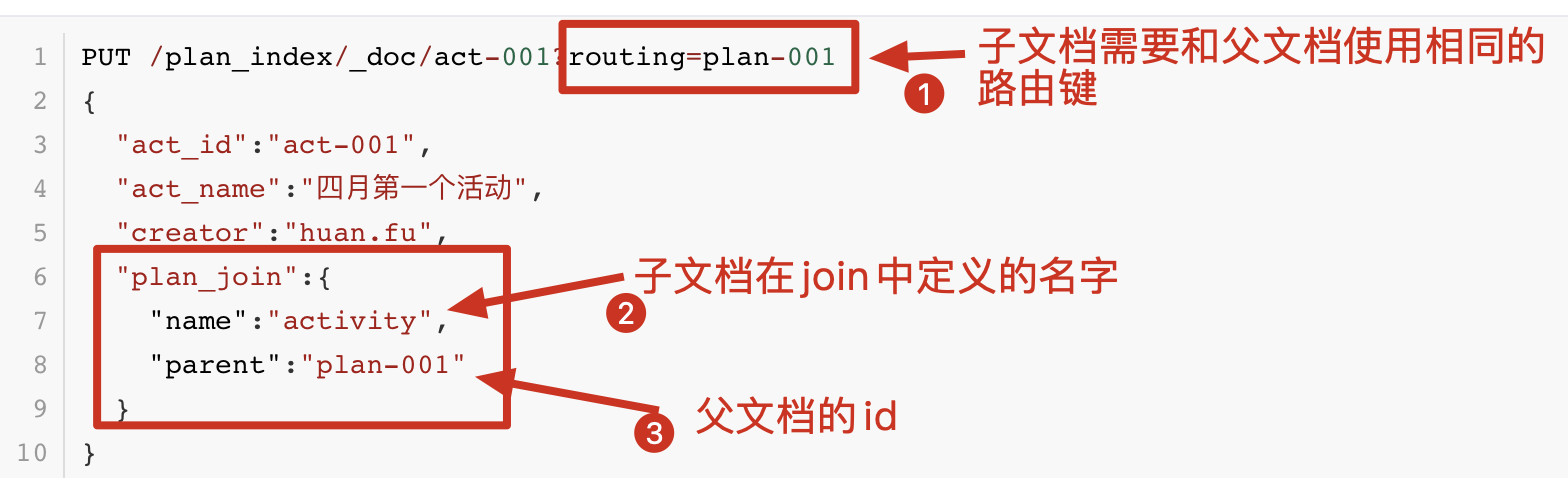
1、子文档(子孙文档等)需要和父文档使用相同的路由键。
2、需要指定父文档的id。
3、需要指定join的名字。
4、查询文档
1、根据父文档id查询它下方的子文档
**需求:**返回父文档id是plan-001下的类型为book的所有子文档。
GET /plan_index/_search
{
"query":{
"parent_id": {
"type":"book",
"id":"plan-001"
}
}
}

2、has_child返回满足条件的父文档
**需求:**返回创建者(creator)是huan.fu,并且子文档最少有2个的父文档。
GET /plan_index/_search
{
"query": {
"has_child": {
"type": "book",
"min_children": 2,
"query": {
"match": {
"creator": "huan.fu"
}
}
}
}
}

3、has_parent返回满足父文档的子文档
**需求:**返回父文档(book)的创建者是huan.fu的所有子文档
GET /plan_index/_search
{
"query": {
"has_parent": {
"parent_type": "book",
"query": {
"match": {
"creator":"huan.fu"
}
}
}
}
}

五、Nested Object 和 join 对比
| Nested Object | join (Parent/Child) |
|---|---|
| 1、文档存储在一起,读取性能高 | 1、父子文档单独存储,互不影响。但是为了维护join的关系,需要占用额外的内容,读取性能略差。 |
| 2、更新父文档或子文档时,需要更新整个文档。 | 2、父文档和子文档可以单独更新。 |
| 3、适用于查询频繁,子文档偶尔更新的情况。 | 3、适用于更新频繁的情况,且子文档的数量远远超过父文档的数量。 |
六、参考文档
1、join数据类型
本文来自博客园,作者:huan1993,转载请注明原文链接:https://www.cnblogs.com/huan1993/p/15416095.html

