
Canal的简单使用
Canal的简单实用
一、背景
工作中有个需求,当数据库的数据变更时,另外一个系统中的数据要能及时感应到,通过调研知道,监听数据库的binlog可以做到一个准实时的通知,而canal主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费,正好满足需求,此处记录一下canal的简单使用。
二、canal的工作原理
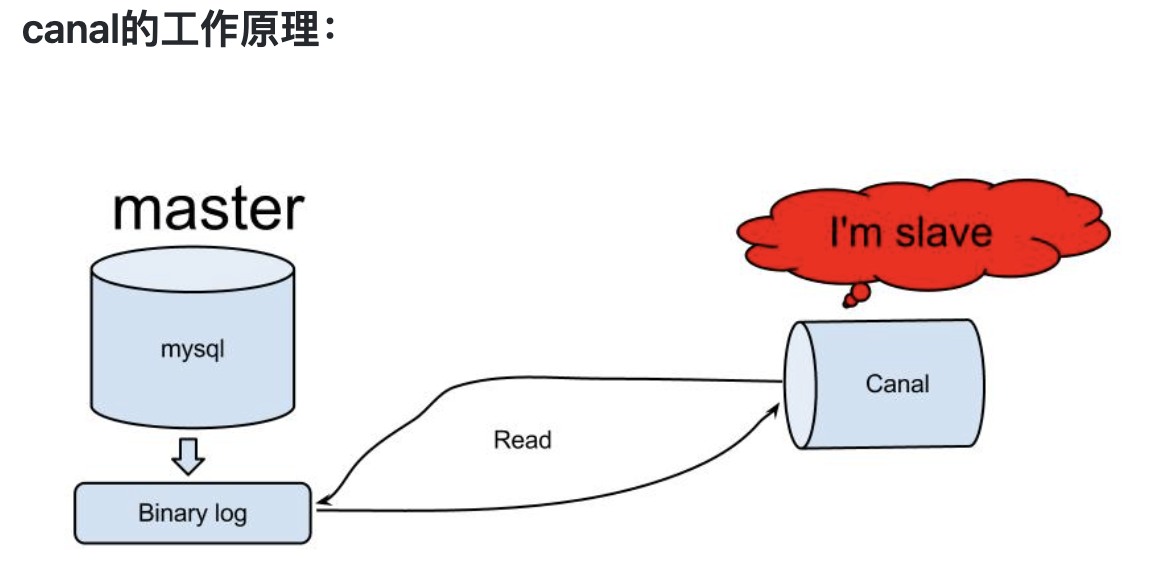
步骤:
- canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议
- mysql master收到dump请求,开始推送binary log给slave(也就是canal)
- canal解析binary log对象(原始为byte流)
三、安装canal
1、mysql配置相关
1、检测binlog是否开启
mysql> show variables like 'log_bin';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_bin | ON |
+---------------+-------+
1 row in set (0.00 sec)
log_bin的值为ON说明打开了。
2、mysql开启binlog
[mysqld]
#binlog日志的基本文件名,需要注意的是启动mysql的用户需要对这个目录(/usr/local/var/mysql/binlog)有写入的权限
log_bin=/usr/local/var/mysql/binlog/mysql-bin
# 配置binlog日志的格式
binlog_format = ROW
# 配置 MySQL replaction 需要定义,不能和 canal 的 slaveId 重复
server-id=1
# 设置中继日志的路径
relay_log=/usr/local/var/mysql/relaylog/mysql-relay
3、创建canal用户
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
FLUSH PRIVILEGES;
2、canal配置相关
1、下载canal
# 1.下载 deployer
$ wget https://github.com/alibaba/canal/releases/download/canal-1.1.5/canal.deployer-1.1.5.tar.gz
# 下载适配器,不是必须的
$ wget https://github.com/alibaba/canal/releases/download/canal-1.1.5/canal.adapter-1.1.5.tar.gz
# 下载管理台,不是必须的
$ wget https://github.com/alibaba/canal/releases/download/canal-1.1.5/canal.admin-1.1.5.tar.gz
# 下载示例程序
$ wget https://github.com/alibaba/canal/releases/download/canal-1.1.5/canal.example-1.1.5.tar.gz
# 2.解压 deployer (解压后的目录要存在)
tar -zxvf canal.deployer-1.1.5.tar.gz -C /Users/huan/soft/canal/deployer/
# 3. 查看 conf 目录结构
$ tree conf
conf
├── canal.properties
├── canal_local.properties
├── example
│ └── instance.properties
├── logback.xml
├── metrics
│ └── Canal_instances_tmpl.json
└── spring
├── base-instance.xml
├── default-instance.xml
├── file-instance.xml
├── group-instance.xml
├── memory-instance.xml
└── tsdb
├── h2-tsdb.xml
├── mysql-tsdb.xml
├── sql
│ └── create_table.sql
└── sql-map
├── sqlmap-config.xml
├── sqlmap_history.xml
└── sqlmap_snapshot.xml
2、配置一个instance
instance:一个instance就是一个消息队列,每个instance通道都有各自的一份配置,因为每个mysql的ip,帐号,密码等信息各不相同。
一个canal server可以存在多个instance。
1、复制conf/example文件夹
cp -r conf/example conf/customer
customer可以简单理解为此处我需要链接customer数据库,因此命名为这个。
2、修改instance的配置
vim conf/customer/instance.properties
# mysql集群配置中的serverId概念,需要保证和当前mysql集群中id唯一 (v1.1.x版本之后canal会自动生成,不需要手工指定)
# canal.instance.mysql.slaveId=0
# mysql主库链接地址
canal.instance.master.address=127.0.0.1:3306
# mysql主库链接时起始的binlog文件
canal.instance.master.journal.name=
# mysql主库链接时起始的binlog偏移量
canal.instance.master.position=
# mysql主库链接时起始的binlog的时间戳
canal.instance.master.timestamp=
# mysql数据库帐号(此处的用户名和密码为 安装canal#mysql配置相关#创建canal用户 这一步创建的用户名和密码)
canal.instance.dbUsername=canal
# mysql数据库密码
canal.instance.dbPassword=canal
# mysql 数据解析编码
canal.instance.connectionCharset = UTF-8
# mysql 数据解析关注的表,Perl正则表达式,即我们需要关注那些库和那些表的binlog数据,也可以在canal client api中手动覆盖
canal.instance.filter.regex=.*\\..*
# table black regex
# mysql 数据解析表的黑名单,表达式规则见白名单的规则
canal.instance.filter.black.regex=mysql\\.slave_.*
3、instance注意事项
1、配置需要关注那个库和那个表的binlog
修改 instance.properties文件的这个属性canal.instance.filter.regex,规则如下:
- 所有表:.* or .*\\..*
- canal schema下所有表: canal\\…*
- canal下的以canal打头的表:canal\\.canal.*
- canal schema下的一张表:canal\\.test1
- 多个规则组合使用:canal\\..*,mysql.test1,mysql.test2 (逗号分隔)
2、mysql链接时的起始位置
- canal.instance.master.journal.name + canal.instance.master.position : 精确指定一个binlog位点,进行启动
- canal.instance.master.timestamp : 指定一个时间戳,canal会自动遍历mysql binlog,找到对应时间戳的binlog位点后,进行启动
- 不指定任何信息:默认从当前数据库的位点,进行启动。(show master status)
3、mysql解析关注表定义
- 标准的Perl正则,注意转义时需要双斜杠:\
4、mysql链接的编码
目前canal版本仅支持一个数据库只有一种编码,如果一个库存在多个编码,需要通过filter.regex配置,将其拆分为多个canal instance,为每个instance指定不同的编码
5、instance.properties配置参考链接:
https://github.com/alibaba/canal/wiki/AdminGuide
3、canal.properties配置相关
vim conf/canal.properties
# canal server绑定的本地IP信息,如果不配置,默认选择一个本机IP进行启动服务
canal.ip = 127.0.0.1
# canal server提供socket服务的端口
canal.port = 1111
# metrics 端口
canal.metrics.pull.port = 11112
# canal 服务的用户名(客户端连接的时候需要这个用户名和密码,也可以不配置)
canal.user = canal
# canal 服务的密码
canal.passwd = 123456
# tcp, kafka, rocketMQ, rabbitMQ(如果我们要将数据发送到kafka中,则此处写kafka,然后配置kafka的配置,此处以tcp演示)
canal.serverMode = tcp
# 当前server上部署的instance列表,此处写 customer ,则和 conf 目录同级下必须要有一个 customer 文件夹,即上一步我们创建的,如果有多个instance说,则以英文的逗号隔开
canal.destinations = customer
# 如果系统是1个cpu,那么需要将这个并行设置成false
canal.instance.parser.parallel = true
注意事项:
1、canal.destinations配置
在canal.properties定义了canal.destinations后,需要在canal.conf.dir对应的目录下建立同名的文件
比如:
canal.destinations = example1,example2
这时需要创建example1和example2两个目录,每个目录里各自有一份instance.properties.
ps. canal自带了一份instance.properties demo,可直接复制conf/example目录进行配置修改
cp -R example example1/
cp -R example example2/
2、canal.auto.scan配置
如果canal.properties未定义instance列表,但开启了canal.auto.scan时
- server第一次启动时,会自动扫描conf目录下,将文件名做为instance name,启动对应的instance
- server运行过程中,会根据canal.auto.scan.interval定义的频率,进行扫描
- 发现目录有新增,启动新的instance
- 发现目录有删除,关闭老的instance
- 发现对应目录的instance.properties有变化,重启instance
3、参考链接
参考链接:https://github.com/alibaba/canal/wiki/AdminGuide
4、启动canal
1、启动canal
# 启动canal server
sh bin/startup.sh
2、查看日志
# canal查看日志
tail -f -n200 logs/canal/canal.log
# 如果canal启动失败则需要查看此日志
tail -f -n200 logs/canal/canal_stdout.log
# 查看instance日志,由上面的配置可知,我们的instance的名字是customer,所以看这个日志.
tail -f -n200 logs/customer/customer.log
3、jdk版本
启动的时候需要注意一下本地JDK的版本,测试时发现使用jdk11不能启动,使用jdk8可以启动。
四、客户端消费canal数据
1、引入依赖
<dependencies>
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.5</version>
</dependency>
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.protocol</artifactId>
<version>1.1.5</version>
</dependency>
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.common</artifactId>
<version>1.1.5</version>
</dependency>
</dependencies>
2、编写客户端代码
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry;
import com.alibaba.otter.canal.protocol.Message;
import java.net.InetSocketAddress;
import java.util.List;
import java.util.concurrent.TimeUnit;
/**
* canal client api 的使用
* https://github.com/alibaba/canal/wiki/ClientExample
* 测试过程中发现,如果修改一个sql语句,但是修改的值没有发生变化,则此处不会监控到。
* 同一个客户端启动多次,只有一个客户端可以获取到数据
*
* @author huan.fu 2021/5/31 - 上午10:31
*/
public class CanalClientApi {
public static void main(String[] args) {
String destination = "customer";
// 创建一个 canal 链接
CanalConnector canalConnector = CanalConnectors.newSingleConnector(new InetSocketAddress("127.0.0.1", 11111), destination, "admin", "admin");
// 链接对应的canal server
canalConnector.connect();
// 订阅那个库的那个表等
/**
* 订阅规则
* 1. 所有表:.* or .*\\..*
* 2. canal schema下所有表: canal\\..*
* 3. canal下的以canal打头的表:canal\\.canal.*
* 4. canal schema下的一张表:canal\\.test1
* 5. 多个规则组合使用:canal\\..*,mysql.test1,mysql.test2 (逗号分隔)
*/
canalConnector.subscribe("temp_work\\.customer");
// 回滚到未进行 #ack 的地方,下次fetch的时候,可以从最后一个没有 #ack 的地方开始拿
canalConnector.rollback();
int batchSize = 1000;
while (true) {
// 获取一批数据,不一定会获取到 batchSize 条
Message message = canalConnector.getWithoutAck(batchSize);
// 获取批次id
long batchId = message.getId();
// 获取数据
List<CanalEntry.Entry> entries = message.getEntries();
if (batchId == -1 || entries.isEmpty()) {
System.out.println("没有获取到数据");
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
continue;
}
for (CanalEntry.Entry entry : entries) {
if (entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONBEGIN || entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONEND) {
continue;
}
CanalEntry.RowChange rowChange;
try {
rowChange = CanalEntry.RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("解析binlog数据出现异常 , data:" + entry.toString(), e);
}
CanalEntry.EventType eventType = rowChange.getEventType();
System.out.println(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),
eventType));
if (eventType == CanalEntry.EventType.QUERY || rowChange.getIsDdl()) {
System.out.println("sql => " + rowChange.getSql());
}
for (CanalEntry.RowData rowData : rowChange.getRowDatasList()) {
if (eventType == CanalEntry.EventType.DELETE) {
printColumn(rowData.getBeforeColumnsList());
} else if (eventType == CanalEntry.EventType.INSERT) {
printColumn(rowData.getAfterColumnsList());
} else {
System.out.println("-------> before");
printColumn(rowData.getBeforeColumnsList());
System.out.println("-------> after");
printColumn(rowData.getAfterColumnsList());
}
}
}
canalConnector.ack(batchId);
}
}
private static void printColumn(List<CanalEntry.Column> columns) {
for (CanalEntry.Column column : columns) {
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
}
}
}
注意⚠️:
经测试,同一个客户端代码,启动多份,模拟多个客户端同时消费,只有一个客户端可以消费数据。
3、测试结果
没有获取到数据
没有获取到数据
================> binlog[mysql-bin.000014:5771] , name[temp_work,customer] , eventType : UPDATE
-------> before
id : 12 update=false
phone : 123 update=false
address : abcdefg update=false
column_4 : update=false
-------> after
id : 12 update=false
phone : 123 update=false
address : 数据改变 update=true
column_4 : update=false
没有获取到数据
没有获取到数据
可以看到获取到了,改变后的数据。
五、消费的binlog不存在
1、单机部署
1、查看数据库中binlog文件的位置
show variables like 'log_bin_basename';
2、找到binlog文件和位置
# 查询 mysql-bin.000026 这个binlog文件,从pos点: 4 开始查起,一共查询查询5条
show binlog events in 'mysql-bin.000026' from 4 limit 5;
3、停止canal-server
4、修改instance下的 instance.properties下的如下配置
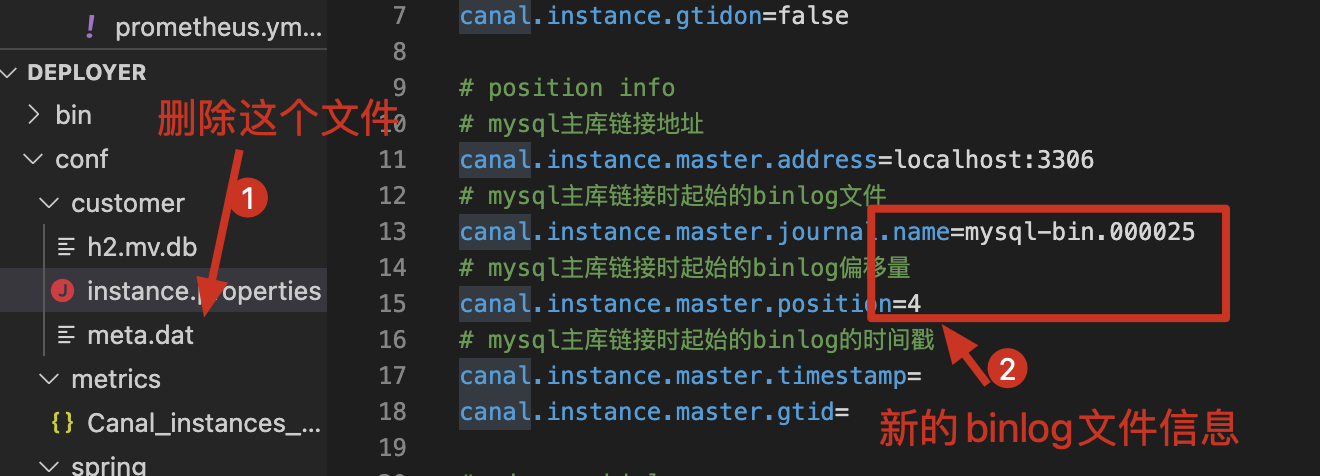
# mysql主库链接时起始的binlog文件
canal.instance.master.journal.name=mysql-bin.000026
# mysql主库链接时起始的binlog偏移量
canal.instance.master.position=4
# mysql主库链接时起始的binlog的时间戳
canal.instance.master.timestamp=
5、删除meta.data文件。
注意⚠️:
可能会出现的一个问题: column size is not match for table:temp_work.customer,4 vs 3,这个是因为binlog中的表结构和我们真实库中的表结构对不起来,如果发生了这个问题,参考如下链接:https://github.com/alibaba/canal/wiki/TableMetaTSDB 解决。
2、集群部署
1、停止 canal server、canal client
2、删除 zookeeper 上的 /otter/canal/destination/{instanceId} 目录
六、完整代码
七、参考链接
1、https://github.com/alibaba/canal/wiki/简介
2、https://github.com/alibaba/canal/wiki/AdminGuide
本文来自博客园,作者:huan1993,转载请注明原文链接:https://www.cnblogs.com/huan1993/p/15416084.html

