
Seata的一些概念
**注意:**此篇文章大部分内容都是摘抄自 seata 的官网,写此篇文章的目的是对seata官网部分内容总结,方便日后复习。
一、什么是seata
Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。其中AT模式是Seata主推的模式,是基于二阶段提交来实现的。
术语:
-
TC (Transaction Coordinator) 事务协调者
维护全局和分支事务的状态,驱动全局事务提交或回滚。
-
TM (Transaction Manager) - 事务管理器
定义全局事务的范围:开始全局事务、提交或回滚全局事务。
-
RM (Resource Manager) - 资源管理器
管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
二、AT模式的介绍
AT模式需要保证每个业务库,都有一张undo_log表,保存着业务数据执行前和执行后的镜像数据。
1、前提条件
- 基于支持本地 ACID 事务的关系型数据库。
- Java 应用,通过 JDBC 访问数据库。
2、整体机制
两阶段提交协议的演变:
- 一阶段:业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁和连接资源。
- 二阶段:
- 提交异步化,非常快速地完成。
- 回滚通过一阶段的回滚日志进行反向补偿。
3、读写隔离的实现
1、写隔离
- 一阶段本地事务提交前,需要确保先拿到 全局锁 。
- 拿不到 全局锁 ,不能提交本地事务。
- 拿 全局锁 的尝试被限制在一定范围内,超出范围将放弃,并回滚本地事务,释放本地锁。
以一个示例来说明:
两个全局事务 tx1 和 tx2,分别对 a 表的 m 字段进行更新操作,m 的初始值 1000。
tx1 先开始,开启本地事务,拿到本地锁,更新操作 m = 1000 - 100 = 900。本地事务提交前,先拿到该记录的 全局锁 ,本地提交释放本地锁。 tx2 后开始,开启本地事务,拿到本地锁,更新操作 m = 900 - 100 = 800。本地事务提交前,尝试拿该记录的 全局锁 ,tx1 全局提交前,该记录的全局锁被 tx1 持有,tx2 需要重试等待 全局锁 。
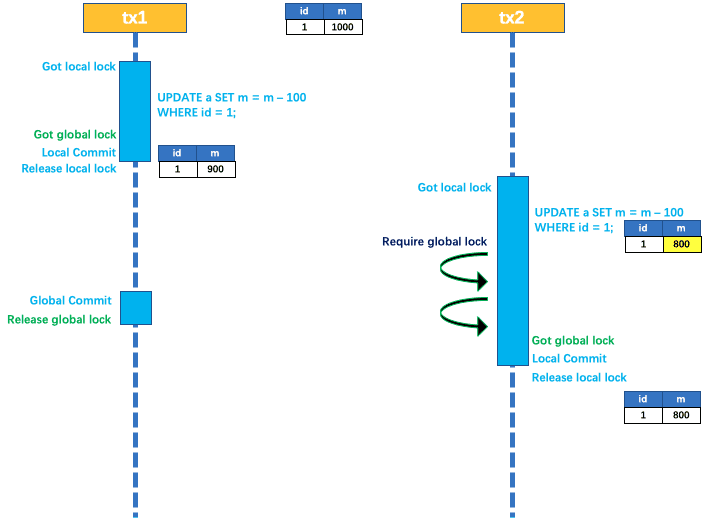
tx1 二阶段全局提交,释放 全局锁 。tx2 拿到 全局锁 提交本地事务。
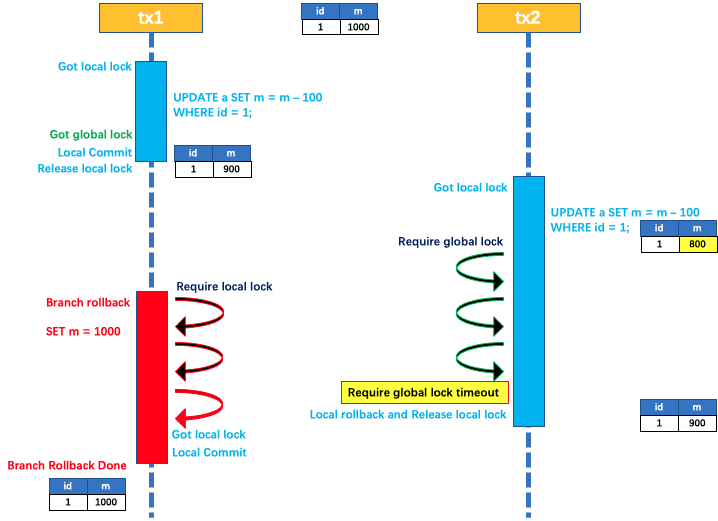
如果 tx1 的二阶段全局回滚,则 tx1 需要重新获取该数据的本地锁,进行反向补偿的更新操作,实现分支的回滚。
此时,如果 tx2 仍在等待该数据的 全局锁,同时持有本地锁,则 tx1 的分支回滚会失败。分支的回滚会一直重试,直到 tx2 的 全局锁 等锁超时,放弃 全局锁 并回滚本地事务释放本地锁,tx1 的分支回滚最终成功。
因为整个过程 全局锁 在 tx1 结束前一直是被 tx1 持有的,所以不会发生 脏写 的问题。
2、读隔离
在数据库本地事务隔离级别 读已提交(Read Committed) 或以上的基础上,Seata(AT 模式)的默认全局隔离级别是 读未提交(Read Uncommitted) 。
如果应用在特定场景下,必需要求全局的 读已提交 ,目前 Seata 的方式是通过 SELECT FOR UPDATE 语句的代理。

SELECT FOR UPDATE 语句的执行会申请 全局锁 ,如果 全局锁 被其他事务持有,则释放本地锁(回滚 SELECT FOR UPDATE 语句的本地执行)并重试。这个过程中,查询是被 block 住的,直到 全局锁 拿到,即读取的相关数据是 已提交 的,才返回。
出于总体性能上的考虑,Seata 目前的方案并没有对所有 SELECT 语句都进行代理,仅针对 FOR UPDATE 的 SELECT 语句。
三、事务分组
1、事务分组是什么?
事务分组是seata的资源逻辑,类似于服务实例。在file.conf中的my_test_tx_group就是一个事务分组。可以实现让不同的微服务注册到不同的组上。
2、通过事务分组如何找到后端集群?
- 首先程序中配置了事务分组(GlobalTransactionScanner 构造方法的txServiceGroup参数)
- 程序会通过用户配置的配置中心去寻找service.vgroupMapping .[事务分组配置项],取得配置项的值就是TC集群的名称
- 拿到集群名称程序通过一定的前后缀+集群名称去构造服务名,各配置中心的服务名实现不同
- 拿到服务名去相应的注册中心去拉取相应服务名的服务列表,获得后端真实的TC服务列表
3、为什么这么设计,不直接取服务名?
这里多了一层获取事务分组到映射集群的配置。这样设计后,事务分组可以作为资源的逻辑隔离单位,出现某集群故障时可以快速failover,只切换对应分组,可以把故障缩减到服务级别,但前提也是你有足够server集群。
4、事物分组的例子
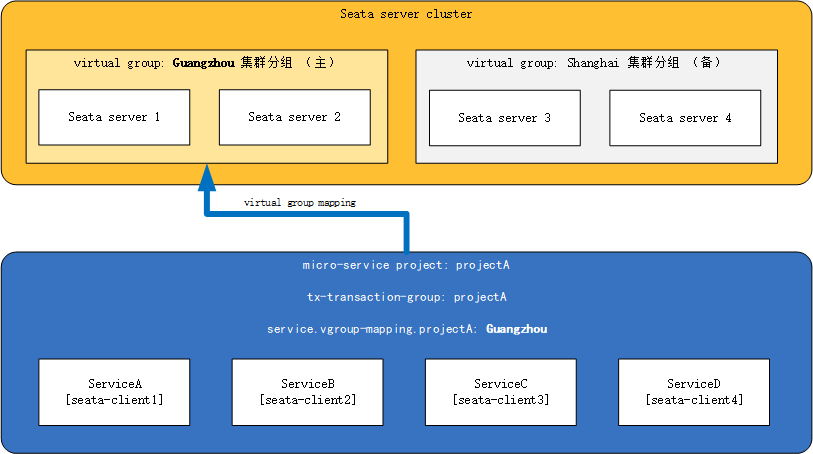
1、TC的异地多机房容灾
- 假定TC集群部署在两个机房:guangzhou机房(主)和shanghai机房(备)各两个实例
- 一整套微服务架构项目:projectA
- projectA内有微服务:serviceA、serviceB、serviceC 和 serviceD
其中,projectA所有微服务的事务分组tx-transaction-group设置为:projectA,projectA正常情况下使用guangzhou的TC集群(主)
那么正常情况下,client端的配置如下所示:
seata.tx-service-group=projectA
seata.service.vgroup-mapping.projectA=Guangzhou
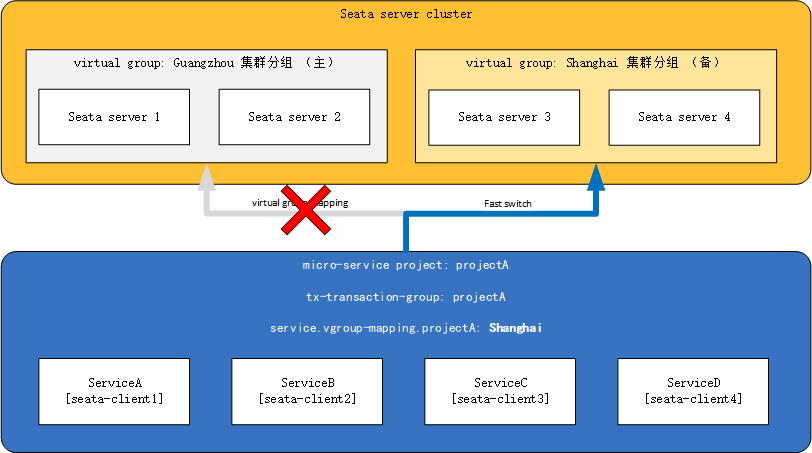
假如此时guangzhou集群分组整个down掉,或者因为网络原因projectA暂时无法与Guangzhou机房通讯,那么我们将配置中心中的Guangzhou集群分组改为Shanghai,如下:
seata.service.vgroup-mapping.projectA=Shanghai
并推送到各个微服务,便完成了对整个projectA项目的TC集群动态切换。
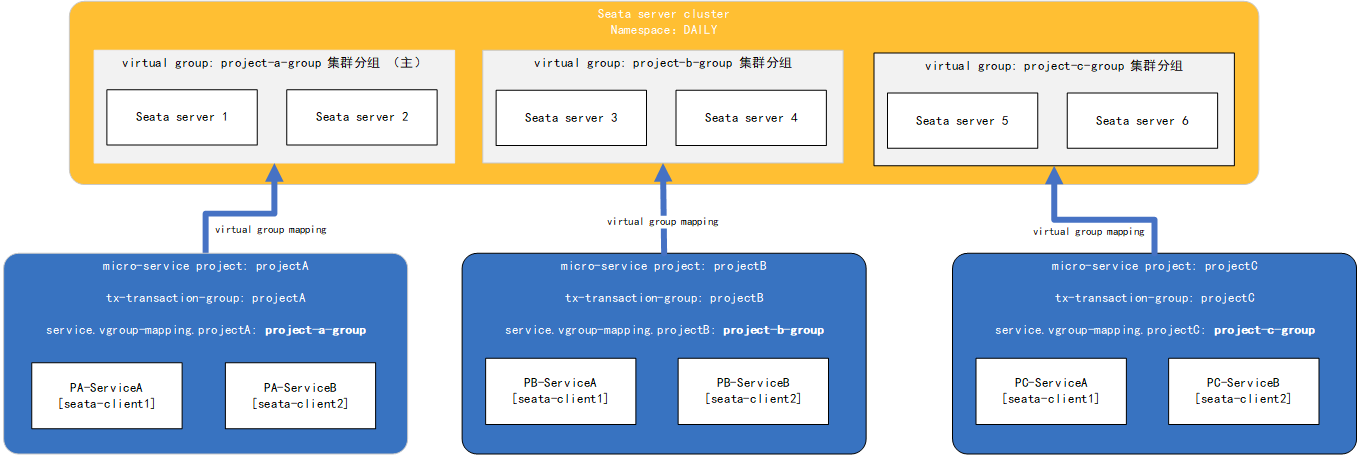
2、单一环境多应用接入
- 假设现在开发环境(或预发/生产)中存在一整套seata集群
- seata集群要服务于不同的微服务架构项目projectA、projectB、projectC
- projectA、projectB、projectC之间相对独立
我们将seata集群中的六个实例两两分组,使其分别服务于projectA、projectB与projectC,那么此时seata-server端的配置如下(以nacos注册中心为例):
registry {
type = "nacos"
loadBalance = "RandomLoadBalance"
loadBalanceVirtualNodes = 10
nacos {
application = "seata-server"
serverAddr = "127.0.0.1:8848"
group = "DEFAULT_GROUP"
namespace = "8f11aeb1-5042-461b-b88b-d47a7f7e01c0"
#同理在其他几个分组seata-server实例配置 project-b-group / project-c-group
cluster = "project-a-group"
username = "username"
password = "password"
}
}
client端的配置如下:
seata.tx-service-group=projectA
#同理,projectB与projectC配置 project-b-group / project-c-group
seata.service.vgroup-mapping.projectA=project-a-group
完成配置启动后,对应事务分组的TC单独为其应用服务,整体部署图如下:
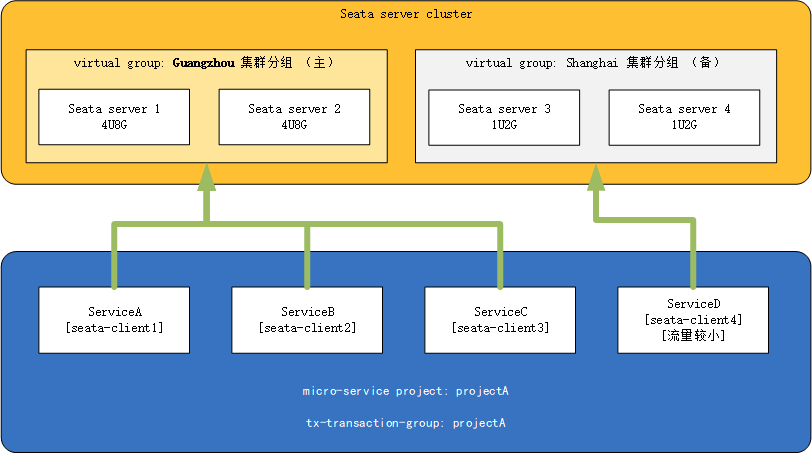
3、client的精细化控制
- 假定现在存在seata集群,Guangzhou机房实例运行在性能较高的机器上,Shanghai集群运行在性能较差的机器上
- 现存微服务架构项目projectA、projectA中有微服务ServiceA、ServiceB、ServiceC与ServiceD
- 其中ServiceD的流量较小,其余微服务流量较大
那么此时,我们可以将ServiceD微服务引流到Shanghai集群中去,将高性能的服务器让给其余流量较大的微服务(反之亦然,若存在某一个微服务流量特别大,我们也可以单独为此微服务开辟一个更高性能的集群,并将该client的virtual group指向该集群,其最终目的都是保证在流量洪峰时服务的可用)
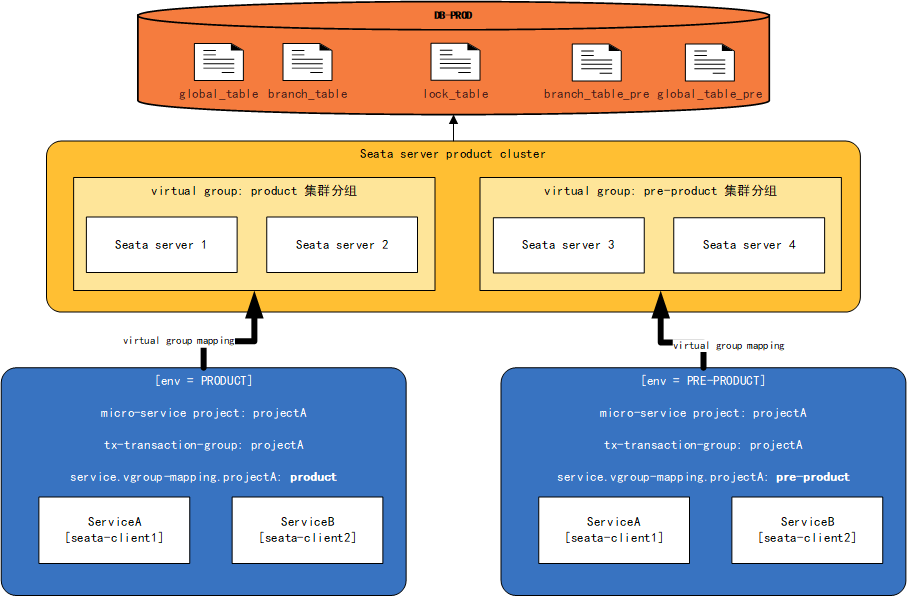
4、Seata的预发与生产隔离
- 大多数情况下,预发环境与生产环境会使用同一套数据库。基于这个条件,预发TC集群与生产TC集群必须使用同一个数据库保证全局事务的生效(即生产TC集群与预发TC集群使用同一个lock表,并使用不同的branch_table与global_table的情况)
- 我们记生产使用的branch表与global表分别为:global_table与branch_table;预发为global_table_pre,branch_table_pre
- 预发与生产共用lock_table
此时,seata-server的 file.conf 配置如下
store {
mode = "db"
db {
datasource = "druid"
dbType = "mysql"
driverClassName = "com.mysql.jdbc.Driver"
url = "jdbc:mysql://127.0.0.1:3306/seata"
user = "username"
password = "password"
minConn = 5
maxConn = 100
globalTable = "global_table" ----> 预发为 "global_table_pre"
branchTable = "branch_table" ----> 预发为 "branch_table_pre"
lockTable = "lock_table"
queryLimit = 100
maxWait = 5000
}
}
seata-server的 registry.conf 配置如下(以nacos为例)
registry {
type = "nacos"
loadBalance = "RandomLoadBalance"
loadBalanceVirtualNodes = 10
nacos {
application = "seata-server"
serverAddr = "127.0.0.1:8848"
group = "DEFAULT_GROUP"
namespace = "8f11aeb1-5042-461b-b88b-d47a7f7e01c0"
cluster = "pre-product" -->同理生产为 "product"
username = "username"
password = "password"
}
}
其部署图如下所示:
不仅如此,你还可以将以上四个最佳实践依据你的实际生产情况组合搭配使用
四、api支持
此处记录一下低级别api的使用
1. 远程调用事务上下文的传播
远程调用前获取当前 XID:
String xid = RootContext.getXID();
远程调用过程把 XID 也传递到服务提供方,在执行服务提供方的业务逻辑前,把 XID 绑定到当前应用的运行时:
RootContext.bind(rpcXid);
2. 事务的暂停和恢复
在一个全局事务中,如果需要某些业务逻辑不在全局事务的管辖范围内,则在调用前,把 XID 解绑:
String unbindXid = RootContext.unbind();
待相关业务逻辑执行完成,再把 XID 绑定回去,即可实现全局事务的恢复:
RootContext.bind(unbindXid);
五、可能遇到的问题
1、undo_log表log_status=1的记录是做什么用的?
- 场景 : 分支事务a注册TC后,a的本地事务提交前发生了全局事务回滚
- 后果 : 全局事务回滚成功,a资源被占用掉,产生了资源悬挂问题
- 防悬挂措施: a回滚时发现回滚undo还未插入,则插入一条log_status=1的undo记录,a本地事务(业务写操作sql和对应undo为一个本地事务)提交时会因为undo表唯一索引冲突而提交失败。
2、如何保证事物的隔离性?
因seata一阶段本地事务已提交,为防止其他事务脏读脏写需要加强隔离。
- 脏读 select语句加for update,代理方法增加@GlobalLock+@Transactional或@GlobalTransaction
- 脏写 必须使用@GlobalTransaction
注:如果你查询的业务的接口没有GlobalTransactional 包裹,也就是这个方法上压根没有分布式事务的需求,这时你可以在方法上标注@GlobalLock+@Transactional 注解,并且在查询语句上加 for update。 如果你查询的接口在事务链路上外层有GlobalTransactional注解,那么你查询的语句只要加for update就行。设计这个注解的原因是在没有这个注解之前,需要查询分布式事务读已提交的数据,但业务本身不需要分布式事务。 若使用GlobalTransactional注解就会增加一些没用的额外的rpc开销比如begin 返回xid,提交事务等。GlobalLock简化了rpc过程,使其做到更高的性能。
3、脏数据会滚失败如何处理?
- 脏数据需手动处理,根据日志提示修正数据或者将对应undo删除(可自定义实现FailureHandler做邮件通知或其他)
- 关闭回滚时undo镜像校验,不推荐该方案。
注:建议事前做好隔离保证无脏数据
4、使用 AT 模式需要的注意事项有哪些 ?
- 必须使用代理数据源,有 3 种形式可以代理数据源:
- 依赖 seata-spring-boot-starter 时,自动代理数据源,无需额外处理。
- 依赖 seata-all 时,使用 @EnableAutoDataSourceProxy (since 1.1.0) 注解,注解参数可选择 jdk 代理或者 cglib 代理。
- 依赖 seata-all 时,也可以手动使用 DatasourceProxy 来包装 DataSource。
- 配置 GlobalTransactionScanner,使用 seata-all 时需要手动配置,使用 seata-spring-boot-starter 时无需额外处理。
- 业务表中必须包含单列主键,若存在复合主键,请参考问题 13 。
- 每个业务库中必须包含 undo_log 表,若与分库分表组件联用,分库不分表。
- 跨微服务链路的事务需要对相应 RPC 框架支持,目前 seata-all 中已经支持:Apache Dubbo、Alibaba Dubbo、sofa-RPC、Motan、gRpc、httpClient,对于 Spring Cloud 的支持,请大家引用 spring-cloud-alibaba-seata。其他自研框架、异步模型、消息消费事务模型请结合 API 自行支持。
- 目前AT模式支持的数据库有:MySQL、Oracle、PostgreSQL和 TiDB。
- 使用注解开启分布式事务时,若默认服务 provider 端加入 consumer 端的事务,provider 可不标注注解。但是,provider 同样需要相应的依赖和配置,仅可省略注解。
- 使用注解开启分布式事务时,若要求事务回滚,必须将异常抛出到事务的发起方,被事务发起方的 @GlobalTransactional 注解感知到。provide 直接抛出异常 或 定义错误码由 consumer 判断再抛出异常。
5、AT 模式和 Spring @Transactional 注解连用时需要注意什么 ?
@Transactional 可与 DataSourceTransactionManager 和 JTATransactionManager 连用分别表示本地事务和XA分布式事务,大家常用的是与本地事务结合。当与本地事务结合时,@Transactional和@GlobalTransaction连用,@Transactional 只能位于标注在@GlobalTransaction的同一方法层次或者位于@GlobalTransaction 标注方法的内层。这里分布式事务的概念要大于本地事务,若将 @Transactional 标注在外层会导致分布式事务空提交,当@Transactional 对应的 connection 提交时会报全局事务正在提交或者全局事务的xid不存在。
6、SpringCloud xid无法传递 ?
1.首先确保你引入了spring-cloud-alibaba-seata的依赖.
2.如果xid还无法传递,请确认你是否实现了WebMvcConfigurer,如果是,请参考com.alibaba.cloud.seata.web.SeataHandlerInterceptorConfiguration#addInterceptors的方法.把SeataHandlerInterceptor加入到你的拦截链路中.
7、使用mybatis-plus 动态数据源组件后undolog无法删除 ?
dynamic-datasource-spring-boot-starter 组件内部开启seata后会自动使用DataSourceProxy来包装DataSource,所以需要以下方式来保持兼容
1.如果你引入的是seata-all,请不要使用@EnableAutoDataSourceProxy注解.
2.如果你引入的是seata-spring-boot-starter 请关闭自动代理
seata:
enable-auto-data-source-proxy: false
8、数据库开启自动更新时间戳导致脏数据无法回滚?
由于业务提交,seata记录当前镜像后,数据库又进行了一次时间戳的更新,导致镜像校验不通过。
**解决方案1: **关闭数据库的时间戳自动更新。数据的时间戳更新,如修改、创建时间由代码层面去维护,比如MybatisPlus就能做自动填充。
解决方案2: update语句别把没更新的字段也放入更新语句。
9、Seata 使用注册中心注册的地址有什么限制?
Seata 注册中心不能注册 0.0.0.0 或 127.0.0.1 的地址,当自动注册为上述地址时可以通过启动参数 -h 或容器环境变量SEATA_IP来指定。当和业务服务处于不同的网络时注册地址可以指定为 NAT_IP或公网IP,但需要保证注册中心的健康检查探活是通畅的。
10、seata服务自检
首先通过读取 client.tm.degradeCheck 是否为true,决定是否开启自检线程.随后读取degradeCheckAllowTimes和degradeCheckPeriod,确认阈值与自检周期. 假设degradeCheckAllowTimes=10,degradeCheckPeriod=2000 那么每2秒钟会进行一个begin,commit的测试,如果失败,则记录连续失败数,如果成功则清空连续失败数.连续错误由用户接口及自检线程进行累计,直到连续失败次数达到用户的阈值,则关闭Seata分布式事务,避免用户自身业务长时间不可用. 反之,假如当前分布式事务关闭,那么自检线程继续按照2秒一次的自检,直到连续成功数达到用户设置的阈值,那么Seata分布式事务将恢复使用
11、设置mysql的连接参数rewriteBatchedStatements=true
在store.mode=db,由于seata是通过jdbc的executeBatch来批量插入全局锁的,根据MySQL官网的说明,连接参数中的rewriteBatchedStatements为true时,在执行executeBatch,并且操作类型为insert时,jdbc驱动会把对应的SQL优化成insert into () values (), ()的形式来提升批量插入的性能。 根据实际的测试,该参数设置为true后,对应的批量插入性能为原来的10倍多,因此在数据源为MySQL时,建议把该参数设置为true。
六、参考资料
本文来自博客园,作者:huan1993,转载请注明原文链接:https://www.cnblogs.com/huan1993/p/15416070.html
