

寒假——热词爬取
今天结合之前找的资料以及询问同学,我在百度百科中找到了一个科学技术的分类,里面是信息技术领域的一些热词,今天完成了相关任务的爬取。
首先是原网页:https://baike.baidu.com/wikitag/taglist?tagId=76607
然后检查该网页,发现其实用post发送的ajax请求,这次模仿前几天的爬取相关的内容完成了数据的爬取。

使用post方法,还是首先建立scrapy项目,之后在spriders中新建一个爬虫文件这是创建的爬虫文件。


import json import random import string import scrapy class WordSpider(scrapy.Spider): name = 'reci' allowed_domains = ['baike.baidu.com'] # custome_setting可用于自定义每个spider的设置,而setting.py中的都是全局属性的,当你的 # scrapy工程里有多个spider的时候这个custom_setting就显得很有用了 custom_settings = { "DEFAULT_REQUEST_HEADERS": { 'authority': 'baike.baidu.com', # 请求报文可通过一个“Accept”报文头属性告诉服务端 客户端接受什么类型的响应。 'accept': 'application/json, text/javascript, */*; q=0.01', # 指定客户端可接受的内容编码 'accept-encoding': 'gzip, deflate, br', # 指定客户端可接受的语言类型 'accept-language': 'zh-CN,zh;q=0.9', 'Connection': 'keep-alive', 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8', 'Content - Length': '200', # 跨域的时候get,post都会显示origin,同域的时候get不显示origin,post显示origin,说明请求从哪发起,仅仅包括协议和域名 'origin': 'http://baike.baidu.com', # 表示这个请求是从哪个URL过来的,原始资源的URI 'referer': 'http://baike.baidu.com/wikitag/taglist?tagId=76607', # 设置请求头信息User-Agent来模拟浏览器 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/79.0.3945.130 Safari/537.36', 'x-requested-with': 'XMLHttpRequest', # cookie也是报文属性,传输过去 'cookie': 'BIDUPSID=374B0B97932138402979026442704DFC; PSTM=1563937805; ' 'BAIDUID=A9C6FBA10593FC60D42D1EE950683FBE:FG=1; ' 'Hm_lvt_55b574651fcae74b0a9f1cf9c8d7c93a=1581650018; ' 'Hm_lpvt_55b574651fcae74b0a9f1cf9c8d7c93a=1581650018; delPer=0; ' 'H_PS_PSSID=30745_1445_21080_26350_30494; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; PSINO=2 ', # 就是告诉服务器我参数内容的类型 'Sec - Fetch - Mode': 'cors', 'Sec - Fetch - Site': 'same - origin' } } # 需要重写start_requests方法 def start_requests(self): # 网页里ajax链接 url = "http://baike.baidu.com/wikitag/api/getlemmas" # 所有请求集合 requests = [] # 这里只模拟一页range(0, 1) for i in range(0, 19700,100): # 15967 random_random = random.random() # 封装post请求体参数 my_data="limit=100&timeout=3000&filterTags=[]&tagId=76607&fromLemma=false&page="+str(i/100) #my_data = {'limit': '24', 'timeout': '3000', 'filterTags': [], 'tagId': '76607', 'fromLemma': 'false', # 'contentLength': '40', 'page': str(i)} # my_data = {'PageCond/begin': i, 'PageCond/length': 1000, 'PageCond/isCount': 'true', 'keywords': '', # 'orgids': '', 'startDate': '', 'endDate': '', 'letterType': '', 'letterStatue': ''} # 模拟ajax发送post请求 print(my_data) request = scrapy.Request(url, method='POST', callback=self.parse_model, body=my_data, encoding='utf-8' ) requests.append(request) return requests def parse_model(self, response): # 可以利用json库解析返回来得数据,在此省略 jsonBody = json.loads(response.body) # 拿到数据,再处理就简单了。不再赘述 #print(jsonBody) # size = jsonBody['PageCond']['size'] data = jsonBody['lemmaList'] listdata = {} for i in range(100): print(i) listdata['lemmaId'] = data[i]['lemmaId'] listdata['lemmaTitle'] = data[i]['lemmaTitle'] listdata['lemmaUrl'] = data[i]['lemmaUrl'] yield listdata print(listdata)
之后修改setting文件
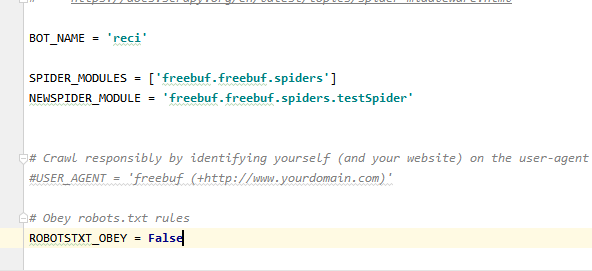
注意 ROBOTSTXT_OBEY = False 这一项要修改为false 这个的含义是 爬虫在爬取的时候会先请求一个robots.txt 这是一个robots协议,也叫爬虫协议,这个协议为真时,当我们爬取数据时就会先请求这个文件,如果这个文件不允许爬取,那么你就爬取不到这个网站的内容。就是如下这个错误。

如果设置为false则代表不遵守这个协议,就可以爬取到了,这是网站的防爬取的一种方式。(这是我爬取遇到的一个问题)
爬取的结果如下:(一共爬取的一万多数据)

这个网站上只有每个热词的url,所以我有爬取了每个url 中的一部分简介。下面这个就是通过BeautifulSoup来解析网页的。
源代码:
# -*- coding: utf-8 -*- """ Created on Fri Feb 14 17:27:06 2020 @author: 九离 """ import requests from bs4 import BeautifulSoup def ReadFile(): f=open('url.csv','r',encoding = 'utf-8-sig') Text=f.readlines() Text2=[] for i in range(len(Text)): x=Text[i].split(',',1) Text2.append(x[1].replace('\n','')) return Text2 def ReadFile2(): f=open('url.csv','r',encoding = 'utf-8-sig') Text=f.readlines() Text2=[] for i in range(len(Text)): x=Text[i].split(',',1) Text2.append(x[0]) return Text2 def WriteFile(data): f=open('jianjie.csv','a+',encoding = 'utf-8') for i in range(len(data)): print(data) if(i<(len(data)-1)): f.write(data[i]+"\t") else : f.write(data[i]+"\n") URLAll=ReadFile() Lemmid=ReadFile2() time =1; error=[] ''' #根据url获得数字 Text=[] for i in range(len(URLAll)): x=URLAll[i].split('/') Text.append(x[len(x)-1]) for i in range(0,len(URLAll)): if(Text[i]!=Lemmid[i]): print(i) print(Text[i]) print(Lemmid[i]) ''' headers = { # 假装自己是浏览器 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/73.0.3683.75 Chrome/73.0.3683.75 Safari/537.36', # 把你刚刚拿到的Cookie塞进来 'cookie': 'BIDUPSID=374B0B97932138402979026442704DFC; PSTM=1563937805; BAIDUID=A9C6FBA10593FC60D42D1EE950683FBE:FG=1; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; Hm_lvt_55b574651fcae74b0a9f1cf9c8d7c93a=1581650018,1581672559; delPer=0; H_PS_PSSID=; PSINO=2; Hm_lpvt_55b574651fcae74b0a9f1cf9c8d7c93a=1581677533',} session = requests.Session() for i in URLAll: try: print(time) time+=1 print(i) url=i[0:len(i)] #url="http://www.beijing.gov.cn/hudong/hdjl/com.web.consult.consultDetail.flow?originalId=10000037" print(url) response = session.get(url, headers=headers) response.encoding='utf-8' html = response.text #将网页内容以html返回 soup = BeautifulSoup(html,'lxml')#解析网页的一种方法 LetterPerson =soup.find_all('div',class_="lemma-summary")#简介 print(LetterPerson[0].text) x=i.split('/') data=[] data.append(x[len(x)-1]) re=LetterPerson[0].text re=re.replace('\n','') re=re.replace('\xa0','') re=re.replace('[1]','') re=re.replace('[2]','') data.append(re) WriteFile(data) except IndexError: error.append(time-1) continue print(error)
最终爬取结果:

很明显这其中少了几个,这就是表明这结果的网址有些问题,我也记录下来其相关的位置: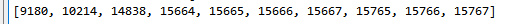 是在这几行出现问题的,所以说我打算明天将这几个添加进去,之后在进行相关的清洗,做下一步任务。
是在这几行出现问题的,所以说我打算明天将这几个添加进去,之后在进行相关的清洗,做下一步任务。

