
RetinaNet基础概念
1.目标检测算法
一般的步骤包括:输入图片--->得到候选框--->根据候选框提取特征-->对框内的特征进行分类(回归)
2. 视觉检测器
1.1One-stage
以YOLO和SSD为代表的单级结构,它们摒弃了提取proposal的过程,只用一级就完成了识别/回归,虽然速度较快但准确率稍差。
1.2Two-stage
以Faster RCNN为代表的两级识别方法,这种结构的第一级专注于proposal的提取,第二级则对提取出的proposal进行分类。两级结构准确度较高,但因为第二级需要单独对 每个proposal进行分类/回归,速度比较慢。
那么,有没有只用单级结构又能提高准确率的方法呢?
3. focal loss
针对one-stage在训练时会被易于分类的背景示例所支配。作者提出了一种新的损失函数,它可以作为处理类不平衡的先前方法的一种更有效的替代方法。
(1)定义cross entropy :
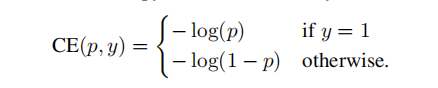
作者提出了一种新的针对二分类问题的loss。其中,y是0,1标签。P是模型输出的概率(即估计y=1的概率)。
为了符号方便表示:
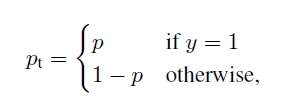
即:
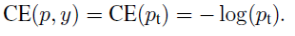
(2)Balanced Cross Entropy
解决类不平衡的常用方法是引入加权因子a,其中a属于[0,1]
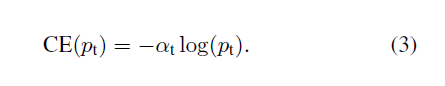
(3)定义focal loss
虽然a平衡positive/negative的案例,但它没有区分easy/hard examples。通过定义一个可调聚焦参数(1 − pt)γ,定义了focal loss:
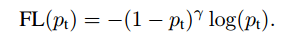
在实践中,添加了一个a平衡变量,得到以下形式:
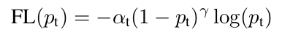
总之,本质上讲,Focal Loss 就是一个解决分类问题中类别不平衡、分类难度差异的一个损失函数。
比如:在训练时,前景类和背景类之间的极度不平衡(如:1:1000)
4.RetinaNet
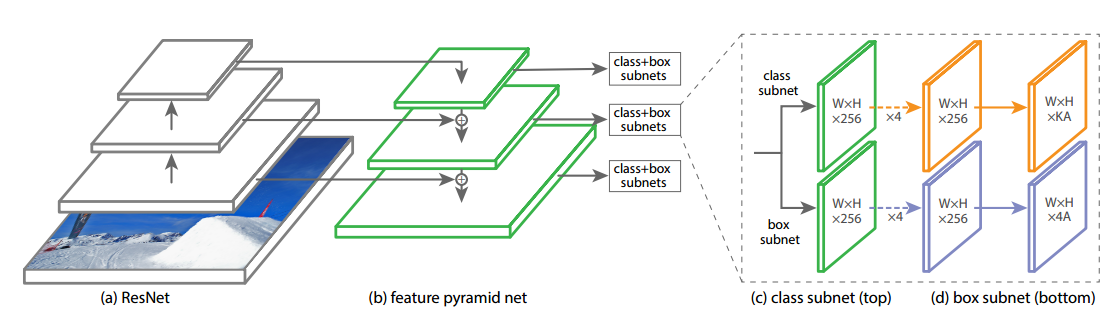
RetinaNet是一个统一的网络,由骨干网和两个特定于任务的子网组成。骨干负责计算整个输入图像上的卷积特征图,并且是一种自卷积网络。第一个子网在主干的输出上执行卷积对象分类;第二个子网执行卷积边界框回归。
(1)FPN (Feature Pyramid Network)
FPN通过自上而下的路径和横向连接增强了标准卷积网络,因此网络从单个分辨率输入图像有效地构建了丰富的多尺度特征。详细见:
https://www.cnblogs.com/huajing/p/13651175.html
(2) 分类子网
分类子网预测每个A anchors和K个对象类在每个空间位置处对象存在的概率。
设计很简单:
输入是C通道的多层特征图--->4个3×3的卷积核(通道数为C)--->relu激活函数--->3×3卷积核(通道数为A)--->sigmoid激活函数
(一般C=256,A=9)
(3)box回归子网
大体上同分类子网,只是最后是一个线性输出。如上图(d)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号