

一. sqoop: mysql->hive
sqoop import -m 1 --hive-import --connect "jdbc:mysql://127.0.0.1:3306/TEST?zeroDateTimeBehavior=CONVERT_TO_NULL&useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai" --username sa --password-file /user/root/_sqoop/pwd127.txt --table user --hive-database TEST --hive-table user
这里jdbc url后面跟了一些连接参数,看情况可有可无;
二.sqoop: oracle->hive
# 使用oracle 服务名jdbc url sqoop import --connect jdbc:oracle:thin:@//127.0.0.1:1521/ORCL --username sa --password 123456 --table TEST.user--hive-import --hive-database test --hive-table user -m 1 # 使用oracle SID jdbs url sqoop import --connect jdbc:oracle:thin:@127.0.0.1:1521:ORCL --username sa --password 123456 --table TEST.user --hive-import --hive-database test --hive-table user -m 1
三.建立增量任务
1.启动sqoop metastore服务存储job
sqoop metastore
2.创建增量任务
sqoop job [metastore] --create <job_name> -- <import_task> --incremental append --check-column id --last-value <last_id> sqoop job --meta-connect jdbc:hsqldb:hsql://192.168.1.70:16000/sqoop --create sync_test -- \ import -m 1 --hive-import --connect "jdbc:mysql://192.168.1.196:3306/TEST" --username sa --password-file /user/root/_sqoop/pwd127.txt --table user --hive-database TEST --hive-table user \ --incremental append --check-column id --last-value 0
TIPS: 不指定metastore时默认使用本地的hsql,分布式的时候不可用;
--check-cloumn 须要是 not null ,有序字段
--last-value 如果是第一次导入可以是 0,(一开始就使用增量导入)
3.运行任务
sqoop job [metastore] --exec <job_name> sqoop job --meta-connect jdbc:hsqldb:hsql://192.168.1.70:16000/sqoop --exec sync_test
sqoop job [metastore] --list 可以查看任务列表
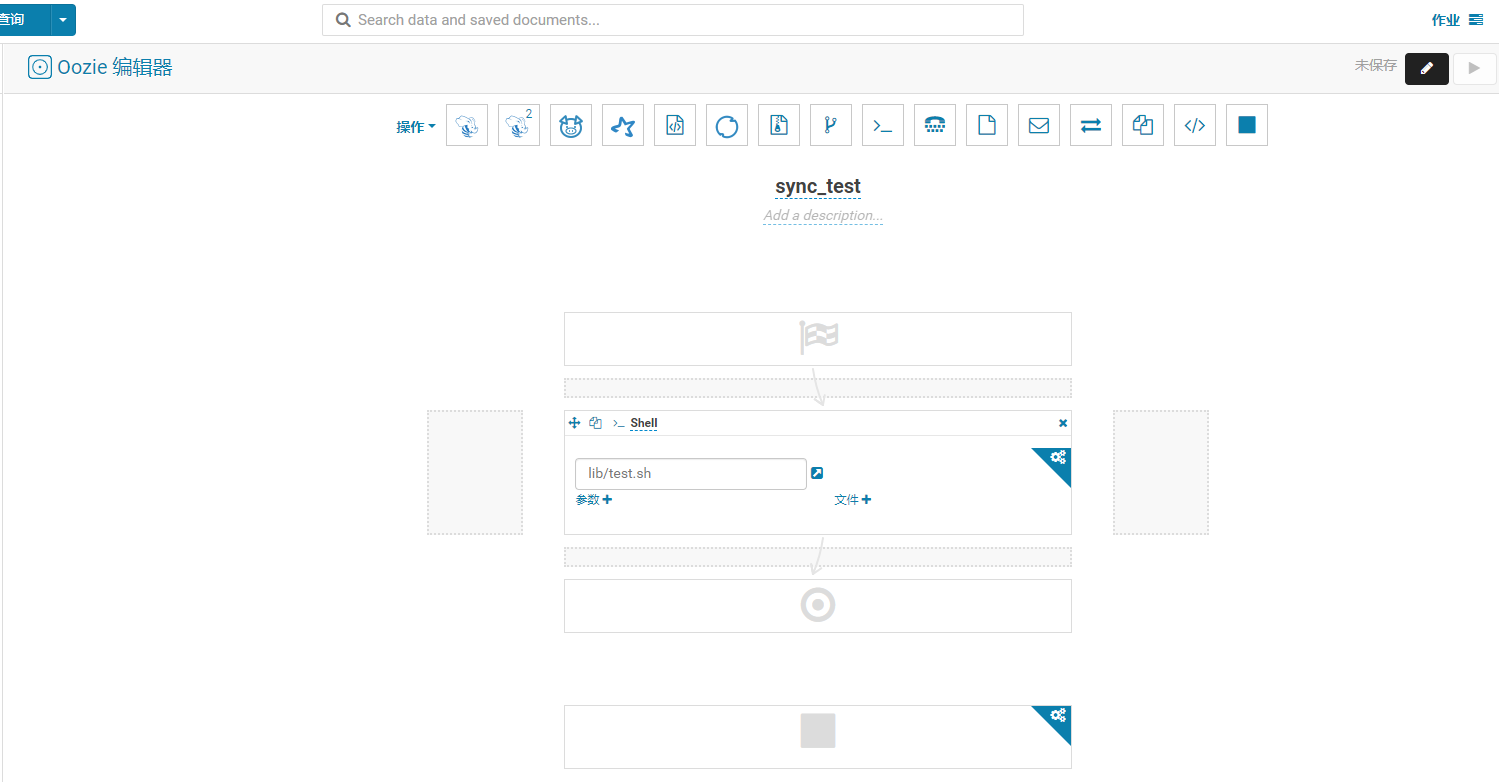
四,HUE 任务
1.建立workflow;
2.在workspace 空间中建立sh文件
3.在sh中写入增量任务命令::sqoop job --meta-connect jdbc:hsqldb:hsql://192.168.1.70:16000/sqoop --exec sync_test
4.再编辑workflow 添加shell组件,选择workspace中的sh文件, 测试
5.建立schedule,将workflow添加进来,编辑运行规则;
更多细节可参考:
https://www.cnblogs.com/canyangfeixue/p/4731520.html
.http://archive.cloudera.com/cdh/3/sqoop/SqoopUserGuide.html

