
SQL深度分页及其优化
当查询语句的偏移量特别大的时候,查询效率就会变的很差,比如limit 10 offset 100 和limit 10 offset 100000的效率肯定是不一样的,后者会慢的多
那怎么解决呢?
先模拟一个例子,表结构如下
1 2 3 4 5 6 7 8 9 10 | CREATE TABLE account ( id int(11) NOT NULL AUTO_INCREMENT COMMENT '主键', name varchar(255) DEFAULT NULL COMMENT '账户名', balance int(11) DEFAULT NULL COMMENT '余额', create_time datetime NOT NULL COMMENT '创建时间', update_time datetime NOT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间', PRIMARY KEY (id), KEY idx_name (name), KEY idx_update_time (update_time)) |
查询语句如下
1 | select id,name,balance from account where update_time < '2024-04-15' limit 10 offset 2000000; |

花了7.172秒,速度挺慢的,看下执行计划,走的是普通索引ids_update_time, 类型是range,Extra是Using index condition, 存在回表行为
链接: 执行计划怎么看
1 | sql的执行顺序:from -> where -> group by -> having -> select -> order by -> limit |
mysql先是执行from 和where,然后执行select,最后执行limit,所以这里会先根据where条件,通过index(ids_update_time)查出2000000+10条记录的主键(id),然后执行select,又因为select里面还包含了name和balance,这两个字段不会存在索引(ids_update_time)中,需要回表根据主键去查出这2000000+10条记录的id+name+balance,回表次数2000010次,最后进行limit(offset),丢弃掉2000000条,取最后的10条
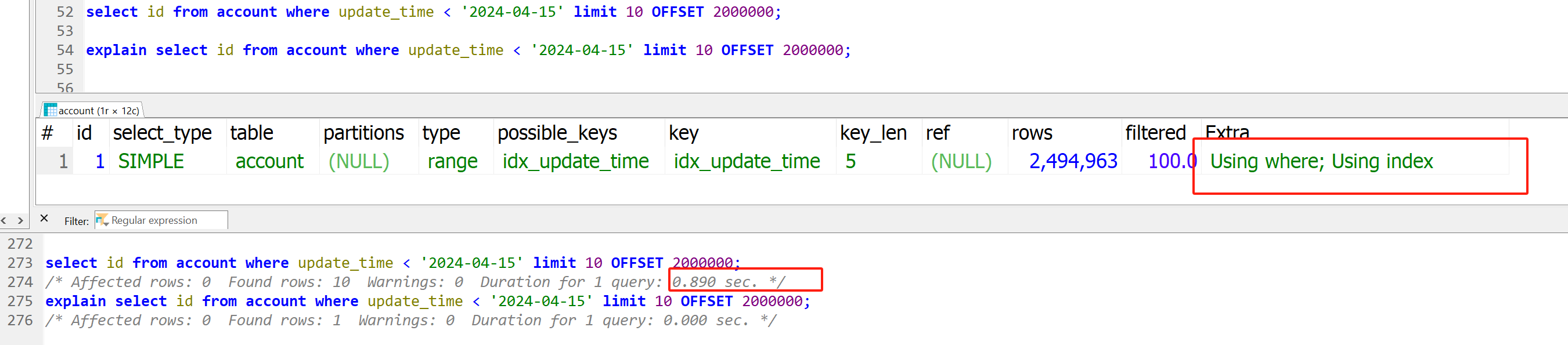
回表次数太多了,我们可以试着从回表次数来优化,如下,我们如果只取出id呢,只花了0.89s, 看下执行计划,不回表了,因为id直接就能在这个index里面拿到
我们已经得到了id,要得到id对应的name和balance,可以使用in或者inner join
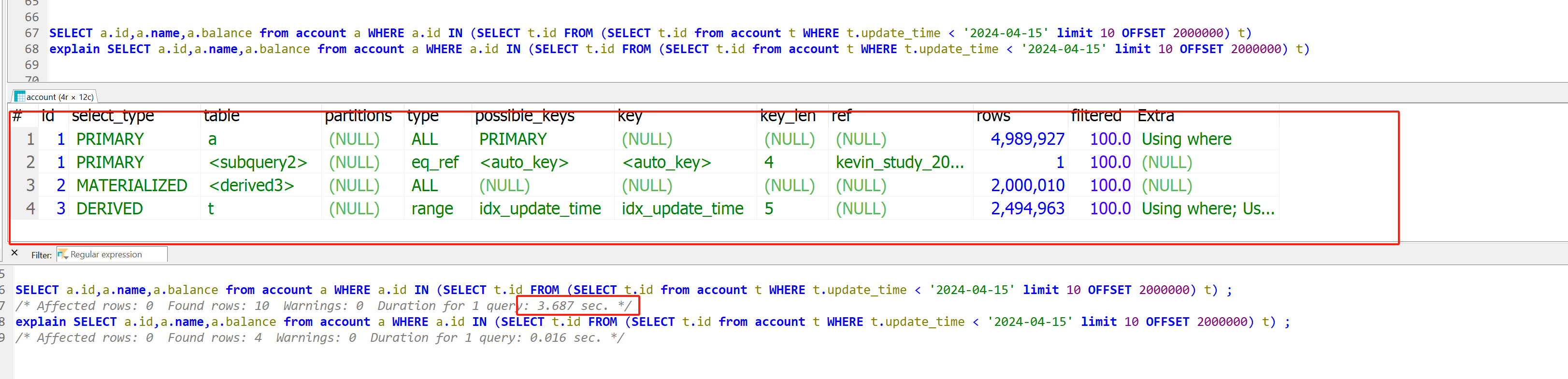
先用in来试试(因为in子查询里面不能使用 limit,所以又套了一层),花了3.68秒,快了那么一点,还是不够,执行计划里挺复杂的
改用inner join 试试,只花了0.875秒,执行计划里面,先执行查询走idx_update_time索引(type为range,并且不回表),然后通过id进行inner join走的是主键索引(type为eq_ref)
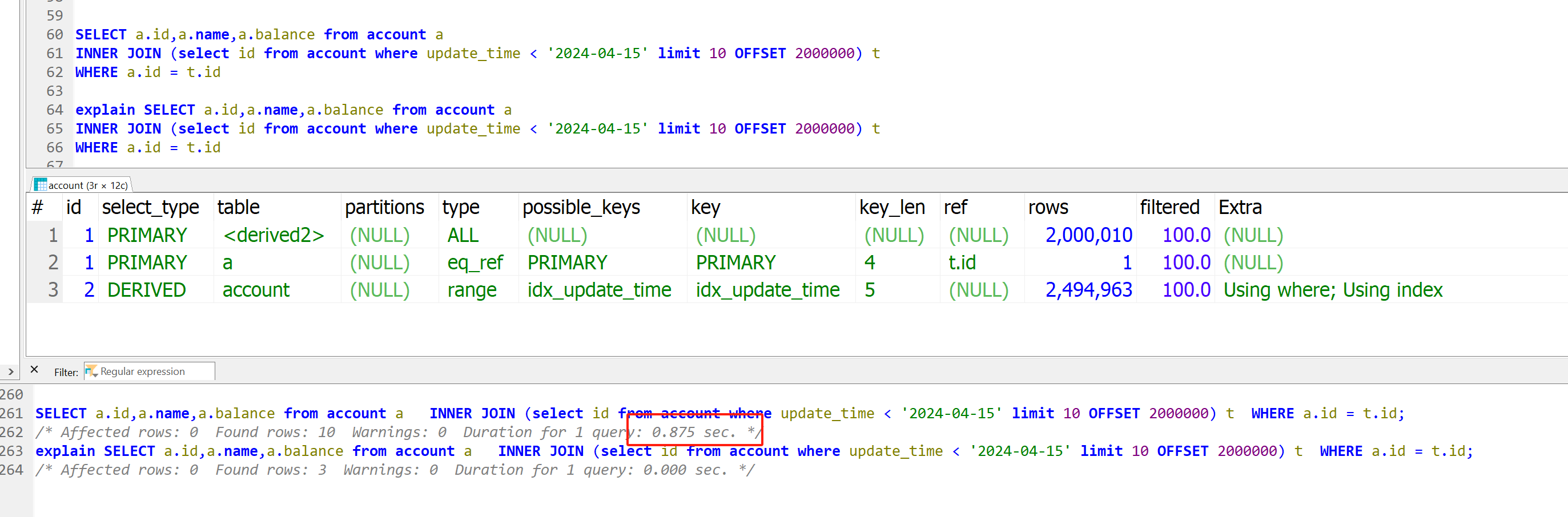
到此为止,这个优化应该可以了,从7.172s优化到了0.875s
如果这里的查询条件从update_time改成create_time, 而且id是自增的,所以任何两条记录都会满足下面这个条件
记录a的create_time比记录b的create_time小,则一定存在a的id比b的id小
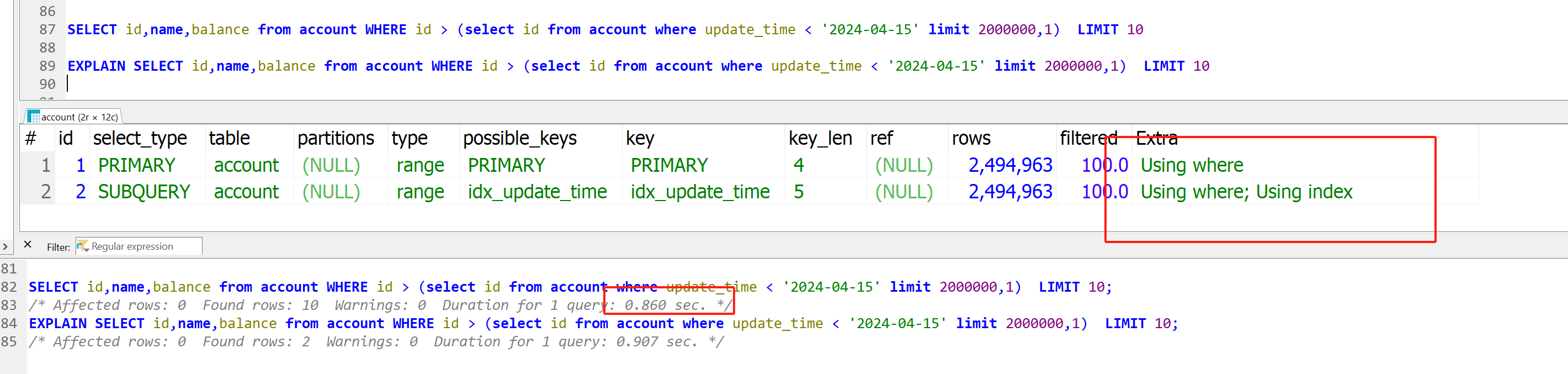
那我们可以只查出第一条满足记录的id,然后通过id比较来得到接下来的10条记录,同样的,看下执行计划,也是走索引idx_update_time没有回表,然后走主键索引,时间也是差不多的0.86s
另外,如果id的变化情况和create_time是一致的(即任何两条记录,id较大的那条记录的create_time也较大),还可以这样
第一次查询是通过update_time来比较,并加上限制 limit 10 offset 0,
第二次查询可以通过传上一次返回值的最后一条记录的id(previous_id),可以通过where id > #{previous_id} limit 10 offset 10来查询
还有第二种方案,这种方案更偏向于后端批量处理数据时候的分页处理
分页获取一批数据,获取第一批次数据的时候lastId为空,后面批次获取的时候传一个lastId(lastId是上一批次的最后一条数据的主键id),如下面的sql所示。
如果是批量处理数据,而不涉及前端交互的话,更推荐下面这种方式,不会随着数据量的增加而性能急剧下降。
1 2 3 4 5 6 7 8 9 10 | -- 分页获取数据select A.* from Awhere A.update_time > #{startTime}and A.update_time < #{endTime}<if test="lastId !=null"> and id > #{lastId} </if>order by A.id asclimit #{pageSize} |
参考:
聊聊如何解决 MySQL 深分页问题 - 捡田螺的小男孩:https://juejin.cn/post/7012016858379321358
1 | //普通索引 |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人