
1 yolov5介绍
yolov5介绍
git 链接:https://github.com/ultralytics/yolov5
文档链接:https://docs.ultralytics.com/
#文章学习参考
1 https://zhuanlan.zhihu.com/p/172121380
2 yolov-数据集-资源等:https://blog.csdn.net/nan355655600/article/details/107852288
#Tools
1 标注工具:labelImg (pip install labelImg)

#Tutorials
1 detect.py



if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument('--weights', nargs='+', type=str, default='yolov5s.pt', help='model.pt path(s)') # 模型选择 链接地址:https://github.com/ultralytics/yolov5/releases # parser.add_argument('--source', type=str, default='data/images', help='source') # file/folder, 0 for webcam #文件(图片或者视频,rtsp)路径 parser.add_argument('--source', type=str, default='data/video/niu.mp4', help='source') # file/folder, 0 for webcam #视频 parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)') parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold') #显示界限,>=0.25才会显示 parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS') # =0,框有交集时只选择一个框,一般不动 parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu') parser.add_argument('--view-img', action='store_true', help='display results') #显示实时结果,需要启动时添加此参数(python detect.py --view-img) parser.add_argument('--save-txt', action='store_true', help='save results to *.txt') #保存label parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels') #保存可信度 parser.add_argument('--nosave', action='store_true', help='do not save images/videos') parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3') #只保留某一类 parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS') parser.add_argument('--augment', action='store_true', help='augmented inference') #检测增强,容易过拟合 parser.add_argument('--update', action='store_true', help='update all models') parser.add_argument('--project', default='runs/detect', help='save results to project/name') #修改保存结果的存储位置 parser.add_argument('--name', default='exp', help='save results to project/name') #保存文件夹名字,默认 exp parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment') opt = parser.parse_args() print(opt) check_requirements(exclude=('pycocotools', 'thop')) with torch.no_grad(): if opt.update: # update all models (to fix SourceChangeWarning) for opt.weights in ['yolov5s.pt', 'yolov5m.pt', 'yolov5l.pt', 'yolov5x.pt']: detect() strip_optimizer(opt.weights) else: detect()
1.1 推理单个图片-返回json数据
import json import time import argparse import os import sys from pathlib import Path import numpy as np import cv2 import torch import torch.backends.cudnn as cudnn import subprocess from models.common import DetectMultiBackend from utils.datasets import IMG_FORMATS, VID_FORMATS, LoadImages, LoadStreams from utils.general import (LOGGER, check_file, check_img_size, check_imshow, check_requirements, colorstr, increment_path, non_max_suppression, print_args, scale_coords, strip_optimizer, xyxy2xywh) from utils.plots import Annotator, colors, save_one_box from utils.torch_utils import select_device, time_sync from utils.augmentations import letterbox ####### 参数设置 # weights = "/project/train/src_repo/yolov5s.pt" # en_weights = "/project/train/src_repo/yolov5s.engine" # weights = "/project/train/models/yolov5s.engine" weights = "/project/train/models/last3-1.pt" en_weights = "/project/train/models/last3-1.engine" imgsz = 864 device = '' stride = 32 names = ["head"] conf_thres = 0.20 iou_thres = 0.30 prob_thres = 0.20 def init(): # 转化pt为engine模型 command =f"sudo python3.8 /project/train/src_repo/export.py --half --weights {weights} --imgsz {imgsz}" ret = subprocess.run(command,shell=True,stdout=subprocess.PIPE,stderr=subprocess.PIPE,encoding="utf-8",timeout=1200) if ret.returncode == 0: print("success:",ret) else: print("error:",ret) global device_obj global stride global pt device_obj = select_device(device) half = device_obj.type != 'cpu' # half precision only supported on CUDA model = DetectMultiBackend(en_weights, device=device_obj, dnn=False) stride, pt, jit, engine = model.stride, model.pt, model.jit, model.engine print(stride,pt,jit,engine) imgsz_obj = check_img_size(imgsz, s=stride) # check image size 尺寸为32的倍数 model.eval() #不启用 Batch Normalization 和 Dropout model.warmup(imgsz=(1, 3, imgsz,imgsz), half=half) # warmup [batch, channel, h, w](nchw) return model def process_image(handle=None, input_image=None, args=None, **kwargs): model =handle input_image =input_image # resize img = letterbox(input_image,imgsz,stride=stride,auto=pt)[0] # Convert img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB [batch, channel, h, w](nchw) img = np.ascontiguousarray(img) img = torch.from_numpy(img).to(device_obj) img = img.half() #to FP16 # img = img.float() img /= 255.0 # 0 - 255 to 0.0 - 1.0 if len(img.shape) == 3: img = img[None] # pred = model(img, augment=False, val=True)[0] pred = model(img, augment=False) # Apply NMS pred = non_max_suppression(pred, conf_thres, iou_thres, None,agnostic=False) fake_result = {} fake_result["algorithm_data"] = { "is_alert": False, "target_count": 0, "target_info": [] } fake_result["model_data"] = {"objects": []} # Process detections cnt = 0 for i, det in enumerate(pred): # detections per image gn = torch.tensor(input_image.shape)[[1, 0, 1, 0]] # normalization gain whwh if det is not None and len(det): # Rescale boxes from img_size to im0 size det[:, :4] = scale_coords(img.shape[2:], det[:, :4], input_image.shape).round() for *xyxy, conf, cls in det: if conf < prob_thres: continue cnt += 1 xmin =xyxy[0] ymin =xyxy[1] xmax =xyxy[2] ymax =xyxy[3] w = xmax-xmin h = ymax-ymin fake_result["model_data"]['objects'].append({ "x":int(xmin), "y":int(ymin), "width":int(w), "height":int(h), "confidence":float(conf), "name":"head" }) # fake_result["algorithm_data"]["target_info"].append({ # "xmin":int(xyxy[0]), # "ymin":int(xyxy[1]), # "xmax":int(xyxy[2]), # "ymax":int(xyxy[3]), # "confidence":float(conf), # # "name":names[int(cls) # "name":"head" # } # ) if cnt: fake_result ["algorithm_data"]["is_alert"] = True fake_result ["algorithm_data"]["target_count"] = cnt return json.dumps(fake_result, indent = 4) if __name__ == '__main__': import glob jpg_list =glob.glob("/project/train/src_repo/datasets/918/images/*.jpg") jpg_list =glob.glob("/project/train/src_repo/data/images/*.jpg") handle=init() start_time =time.time() for jpg in jpg_list: img=cv2.imread(jpg) a =process_image(handle=handle,input_image=img) print(a) end_time =time.time() s =end_time-start_time print("spend _time:",s)
import json import time import argparse import os import sys from pathlib import Path import numpy as np import cv2 import torch import torch.backends.cudnn as cudnn import subprocess from models.common import DetectMultiBackend from utils.datasets import IMG_FORMATS, VID_FORMATS, LoadImages, LoadStreams from utils.general import (LOGGER, check_file, check_img_size, check_imshow, check_requirements, colorstr, increment_path, non_max_suppression, print_args, scale_coords, strip_optimizer, xyxy2xywh) from utils.plots import Annotator, colors, save_one_box from utils.torch_utils import select_device, time_sync from utils.augmentations import letterbox ####### 参数设置 # weights = "/project/ev_sdk/src/models/yolov5s6.pt" weights = "/project/train/src_repo/yolov5s.pt" imgsz = 960 device = '0' stride = 32 # stride = 64 names = ["head"] conf_thres = 0.20 iou_thres = 0.30 prob_thres = 0.20 def init(): global device_obj device_obj = select_device(device) half = device_obj.type != 'cpu' # half precision only supported on CUDA model = DetectMultiBackend(weights, device=device_obj, dnn=False) stride, pt, jit, engine = model.stride, model.pt, model.jit, model.engine # print(stride,pt,jit,engine) # time.sleep(10) imgsz_obj = check_img_size(imgsz, s=stride) # check image size 尺寸为32的倍数 model.half() # to FP16 model.eval() #不启用 Batch Normalization 和 Dropout # model.warmup(imgsz=(1, 3, imgsz,imgsz), half=half) # warmup [batch, channel, h, w](nchw) return model def process_image(handle=None, input_image=None, args=None, **kwargs): model =handle input_image =input_image # resize img = letterbox(input_image,stride=stride,new_shape=imgsz,auto=True)[0] # Convert img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB [batch, channel, h, w](nchw) img = np.ascontiguousarray(img) img = torch.from_numpy(img).to(device_obj) img = img.half() #to FP16 # img = img.float() img /= 255.0 # 0 - 255 to 0.0 - 1.0 if len(img.shape) == 3: img = img[None] pred = model(img, augment=False, val=True)[0] # Apply NMS pred = non_max_suppression(pred, conf_thres, iou_thres, agnostic=False) fake_result = {} fake_result["algorithm_data"] = { "is_alert": False, "target_count": 0, "target_info": [] } fake_result["model_data"] = {"objects": []} # Process detections cnt = 0 for i, det in enumerate(pred): # detections per image gn = torch.tensor(input_image.shape)[[1, 0, 1, 0]] # normalization gain whwh if det is not None and len(det): # Rescale boxes from img_size to im0 size det[:, :4] = scale_coords(img.shape[2:], det[:, :4], input_image.shape).round() for *xyxy, conf, cls in det: if conf < prob_thres: continue cnt += 1 xmin =xyxy[0] ymin =xyxy[1] xmax =xyxy[2] ymax =xyxy[3] w = xmax-xmin h = ymax-ymin fake_result["model_data"]['objects'].append({ "x":int(xmin), "y":int(ymin), "width":int(w), "height":int(h), "confidence":float(conf), "name":"head" }) # fake_result["algorithm_data"]["target_info"].append({ # "xmin":int(xyxy[0]), # "ymin":int(xyxy[1]), # "xmax":int(xyxy[2]), # "ymax":int(xyxy[3]), # "confidence":float(conf), # # "name":names[int(cls) # "name":"head" # } # ) if cnt: fake_result ["algorithm_data"]["is_alert"] = True fake_result ["algorithm_data"]["target_count"] = cnt return json.dumps(fake_result, indent = 4) if __name__ == '__main__': import glob jpg_list =glob.glob("/project/train/src_repo/datasets/918/images/*.jpg") jpg_list =glob.glob("/project/train/src_repo/data/images/*.jpg") handle=init() start_time =time.time() for jpg in jpg_list: img=cv2.imread(jpg) a =process_image(handle=handle,input_image=img) print(a) end_time =time.time() s =end_time-start_time print("spend _time:",s)
2 train.py
weights:权重文件路径,如果是''则重头训练参数,如果不为空则做迁移学习,权重文件的模型需与cfg参数中的模型对应 cfg:存储模型结构的配置文件 data:训练、验证数据配置文件 hyp:超参数配置文件,其中的参数意义下面会解释 epochs:指的就是训练过程中整个数据集将被迭代多少次 batch-size:每次梯度更新的批量数,太大会导致显存不足 img-size:训练图片的尺寸 rect:进行矩形训练 resume:恢复最近保存的模型开始训练 nosave:仅保存最终checkpoint notest:仅测试最后的epoch noautoanchor:不进行anchors的k-means聚类 evolve:进化超参数 bucket:gsutil bucket cache-images:缓存图像以加快训练速度 image-weights:给图片加上权重进行训练 device:cuda device, i.e. 0 or 0,1,2,3 or cpu multi-scale:多尺度训练,img-size +/- 50% single-cls:单类别的训练集 adam:使用adam优化器 name:重命名results.txt to results_name.txt
def parse_opt(known=False): parser = argparse.ArgumentParser() parser.add_argument('--weights', type=str, default='', help='initial weights path') #初始化网络参数 (yolov5s.py,youlov5m.py,yolov5l.py,yolov5x.py) parser.add_argument('--cfg', type=str, default='models/yolov5s.yaml', help='model.yaml path') #采用模型结构 parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path') #数据集的配置文件 parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch.yaml', help='hyperparameters path') parser.add_argument('--epochs', type=int, default=300) #训练的轮数,默认300轮 parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch') #每次读取图片 parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)') parser.add_argument('--rect', action='store_true', help='rectangular training') #矩形训练 parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training') #指定从之前训练的模型 开始 parser.add_argument('--nosave', action='store_true', help='only save final checkpoint') parser.add_argument('--noval', action='store_true', help='only validate final epoch') parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor') #默认开启 parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations') #超参数进化(超参数调优的方式) parser.add_argument('--bucket', type=str, default='', help='gsutil bucket') parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"') parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training') parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu') parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%') #图片尺寸的变换 parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class') parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer') parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode') #多GPU训练 # parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)') parser.add_argument('--workers', type=int, default=4, help='max dataloader workers (per RANK in DDP mode)') parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name') parser.add_argument('--name', default='exp', help='save to project/name') parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment') parser.add_argument('--quad', action='store_true', help='quad dataloader') #四数据加载器 parser.add_argument('--linear-lr', action='store_true', help='linear LR') #线性回归 LR parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon') #标签平滑,防止过拟合 parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)') parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2') parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)') parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify') # Weights & Biases arguments parser.add_argument('--entity', default=None, help='W&B: Entity') parser.add_argument('--upload_dataset', nargs='?', const=True, default=False, help='W&B: Upload data, "val" option') parser.add_argument('--bbox_interval', type=int, default=-1, help='W&B: Set bounding-box image logging interval') parser.add_argument('--artifact_alias', type=str, default='latest', help='W&B: Version of dataset artifact to use') opt = parser.parse_known_args()[0] if known else parser.parse_args() return opt
-原始pic与label对应关系 dataset/images/im0.jpg # image dataset/labels/im0.txt # label
3 hpy超参数
超参数配置文件./data/hyp.scratch.yaml参数解释:
lr0:学习率,可以理解为模型的学习速度
lrf:OneCycleLR学习率变化策略的最终学习率系数
momentum:动量,梯度下降法中一种常用的加速技术,加快收敛
weight_decay:权值衰减,防止过拟合。在损失函数中,weight decay是正则项(regularization)前的一个系数
warmup_epochs:预热学习轮数
warmup_momentum:预热学习初始动量
warmup_bias_lr:预热学习初始偏差学习率
giou:GIoU损失收益
cls:类别损失收益
cls_pw:类别交叉熵损失正类权重
obj:是否有物体损失收益
obj_pw:是否有物体交叉熵正类权重
iou_t:iou阈值
anchor_t:多尺度anchor阈值
fl_gamma:focal loss gamma系数
hsv_h:色调Hue,增强系数
hsv_s:饱和度Saturation,增强系数
hsv_v:明度Value,增强系数
degrees:图片旋转角度
translate:图片转换
scale:图片缩放
shear:图片仿射变换
perspec:透视变换
mosaic:mosaic数据增强
mixup:mixup数据增强
lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3) lrf: 0.1 # final OneCycleLR learning rate (lr0 * lrf) momentum: 0.937 # SGD momentum/Adam beta1 weight_decay: 0.0005 # optimizer weight decay 5e-4 权重衰减 warmup_epochs: 3.0 # warmup epochs (fractions ok) warmup_momentum: 0.8 # warmup initial momentum warmup_bias_lr: 0.1 # warmup initial bias lr box: 0.05 # box loss gain cls: 0.5 # cls loss gain cls_pw: 1.0 # cls BCELoss positive_weight obj: 1.0 # obj loss gain (scale with pixels) obj_pw: 1.0 # obj BCELoss positive_weight iou_t: 0.20 # IoU training threshold anchor_t: 4.0 # anchor-multiple threshold # anchors: 3 # anchors per output layer (0 to ignore) fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5) hsv_h: 0.015 # image HSV-Hue augmentation (fraction) 色调 hsv_s: 0.7 # image HSV-Saturation augmentation (fraction) 饱和度 hsv_v: 0.4 # image HSV-Value augmentation (fraction) 明度 degrees: 0.0 # image rotation (+/- deg) translate: 0.1 # image translation (+/- fraction) 平移 scale: 0.5 # image scale (+/- gain) 缩放(扩大)比例 shear: 0.0 # image shear (+/- deg) 裁剪 perspective: 0.0 # image perspective (+/- fraction), range 0-0.001 透视变换参数 flipud: 0.0 # image flip up-down (probability) 上下翻转 fliplr: 0.5 # image flip left-right (probability) 左右翻转 mosaic: 1.0 # image mosaic (probability) 马赛克 mixup: 0.0 # image mixup (probability) 图片融合 copy_paste: 0.0 # segment copy-paste (probability)
知识补充:
1 --half 的理解 (FP32,FP16)

2 detect.py
model =model.eval() #不启用 Batch Normalization 和 Dropout
model.eval()是保证BN层能够用全部训练数据的均值和方差,即测试过程中要保证BN层的均值和方差不变。对于Dropout,model.eval()是利用到了所有网络连接,即不进行随机舍弃神经元
训练完train样本后,生成的模型model要用来测试样本。在model(test)之前,需要加上model.eval(),否则的话,有输入数据,即使不训练,它也会改变权值。这是model中含有BN层和Dropout所带来的的性质。
dropout:
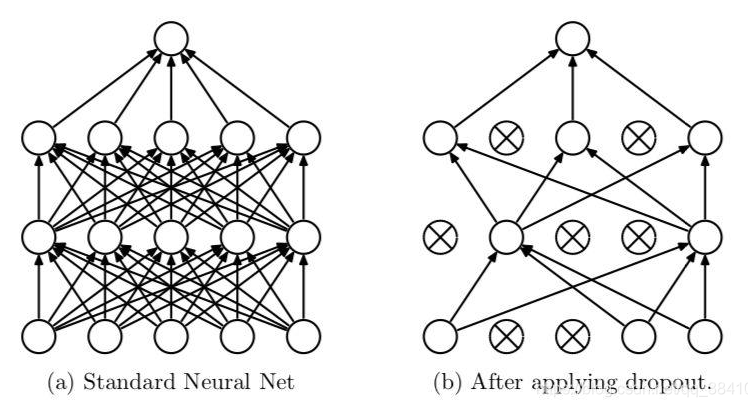
作者:华王
博客:https://www.cnblogs.com/huahuawang/


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理