

1 常用的Pandas函数
20个常用的函数方法
1.读取数据
marketing = pd.read_csv("DirectMarketing.csv") groceries = pd.read_csv("Groceries_dataset.csv") df = pd.read_csv("Churn_Modelling.csv" #只想展示一部分,比方说其中几行的数据 df = pd.read_csv("Churn_Modelling.csv", nrows = 5000) df.shape (5000,14)
# 其中几列的数据,例如下面的代码选中“Gender”、“Age”以及“Tensure”等几列
df1 = pd.read_csv("Churn_Modelling.csv", usecols=['Gender', 'Age', 'Tenure', 'Balance'])
2.查看缺失值
groceries.isna().sum()
Member_number 0
Date 0
itemDescription 0
dtype: int64
3. 填充缺失值
# 这里用的是众数来填充,当然也可以用平均数mean,中位数median groceries['itemDescription'].fillna(value=groceries['itemDescription'].mode()[0], inplace=True) # 或者是用"fillna"这个方法 groceries["Date"].fillna(method = "ffill", inplace = True) # 假若我们想把这些缺失值给抹去,也很好来操作,使用“drop”方法,#“inplace=True”表明原数组内容直接被改变 groceries.drop(axis = 0, how = 'any', inplace = True)
4. 查看某一列的数据类型
# 首先我们来查看一下数据集当中每一列的数据类型 groceries.dtypes Member_number int64 Date object itemDescription object dtype: object # 我们看到的是,“Date”这一列的数据类型是“object”,我们可以通过#“astype”这个方法来改变这一列的数据类型 groceries['Date'] = groceries['Date'].astype("datetime64") #当然还有“to_datetime”这个方法来尝试 groceries['Date'] = pd.to_datetime(groceries['Date']) #通过里面的参数“parse_dates”来改变这一列的数据类型 groceries = pd.read_csv("Groceries_dataset.csv", parse_dates=['Date']) groceries.dtypes Member_number int64 Date datetime64[ns] itemDescription object dtype: object
5. 筛选出数据
"""通常来说有很多种方式方法来筛选数据以得出我们想要的结果,比方说我们可以通过一些逻辑符号“==”、“!=”或者是“>”“<”等方式,例如下面的代码便是挑选出“itemDescription”等于是“pip fruit”的数据""" groceries[groceries["itemDescription"] == "pip fruit"].head()
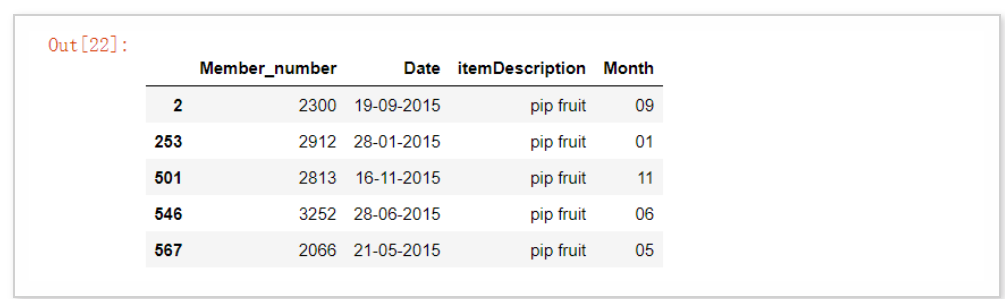
"""当然还有“isin”这个方法来从一定的范围内选出数据,我们能够传入一个列表,在列表中注明我们要筛选的数据,例如下面的代码,我们筛选出“Member_number”在这些范围当中的数据""" groceries[groceries.Member_number.isin([3737, 2433, 3915, 2625])].head()
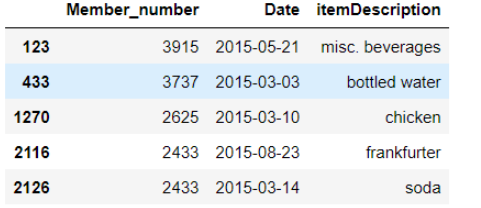
# “query”这个方法也可以帮助到我们 groceries.query('3000 < Member_number < 5000').head()
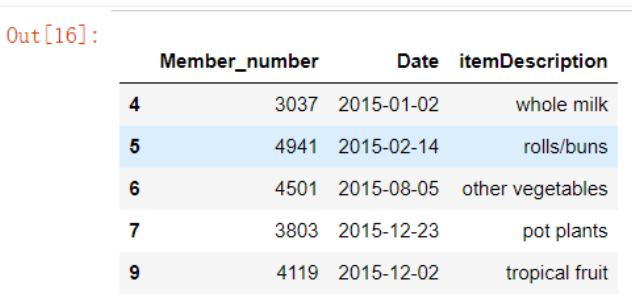
# “where”这个方法也行 groceries[['Member_number','Date', 'itemDescription']].where(groceries['Member_number'] > 2500, 0).head()
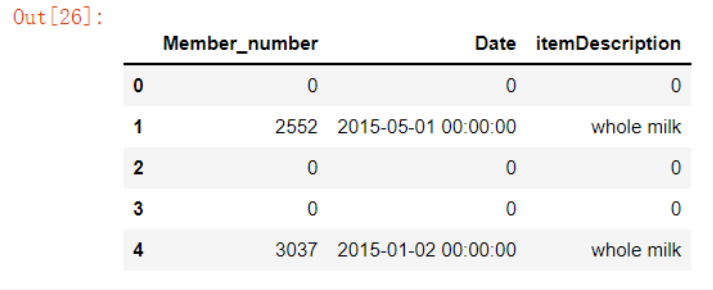
6. 排除数据
#“~”符号用来表明我们需要筛选出不再我们给定的范围之内的数据,比方说下#面的代码我们筛选出“Member_number”不再这些范围当中的数据 groceries[~groceries.Member_number.isin([3737, 2433, 3915, 2625])].head()
7. 数据统计
#“value_counts”方法是被使用最广泛的工具,在数据统计和计数当中,计算#一下该列当中每大类的离散值出现的频率 marketing["OwnHome"].value_counts() Own 516 Rent 484 Name: OwnHome, dtype: int64 #我们将其中的参数“normalize”改成“True”,它也将以百分比的形式出现, marketing.Catalogs.value_counts(normalize=True) 12 0.282 6 0.252 24 0.233 18 0.233 #除此之外,我们也可以用“nunique”这个方法来查看某一列离散值当中有#几大类,例如下面的代码中“OwnHome”这一列只有两大类 marketing["OwnHome"].nunique() 2
8. 将某一列作为索引
"""一般数据集中的索引大家可以理解为就是“行数”,也就是“第一行”、“第二行”,当然我们可以通过“set_index”这个方法来将任意某一列设置为我们需要的索引,比方说数据集中的“Date”字段被设置成了索引""" groceries.set_index('Date', inplace=True)
9. 重新设置索引
# 我们可以通过“reset_index”来重新设置索引,例如下面的数据集的索引并不#是连续的 groceries.reset_index(drop=True, inplace=True)

10. 关于“loc”和“iloc”
# “loc”方法和“iloc”方法用法想类似,其中比较重要的一点是“loc”方法一般可以接受标签,例如 groceries.loc[:,["Member_number", "Date"]].head()

# 而“iloc”里面要是放标签的话,则会报错,一般“iloc”里面放的则是索引 # 取第一列和第二列两列的数据 groceries.iloc[:,[0, 1]].head()
11. 提取“月份”和“年份”
# 我们可以通过“dt”这个方法来提取时间类型的数据中的年份和月份,例如 groceries['Year'] = groceries['Date'].dt.year groceries['Month'] = groceries['Date'].dt.month
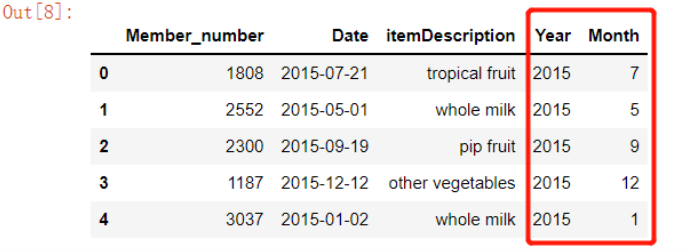
12. 去除某几列的数据
#要是碰到我们想去除掉某几列的数据的时候,可以使用“drop”方法,例如,我#们去除掉“Year”和“Month”这两列 groceries.drop(['Year','Month'], axis=1, inplace=True)

13. 增加某几列的数据
# 要是想在数据集当中增加几列的时候,我们可以使用“insert”方法,例如,我#们再第一列和第二列的位置插入“Month”数据和“Year”的数据 year = groceries['Date'].dt.year month = groceries['Date'].dt.month groceries.insert(1, 'Month', month) groceries.insert(2, 'Year', year)

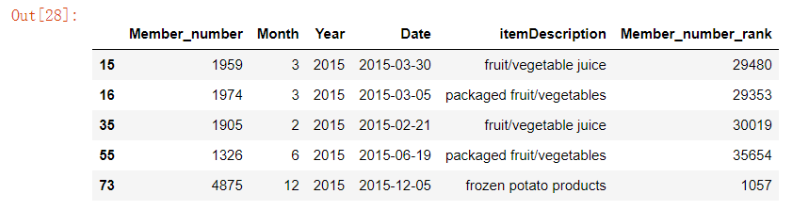
14. 排名统计
# 我们可以为某一列数据做一个排名,使用“rank”这个方法 groceries['Member_number_rank'] = groceries['Member_number'].rank(method = 'first', ascending = False).astype('int')
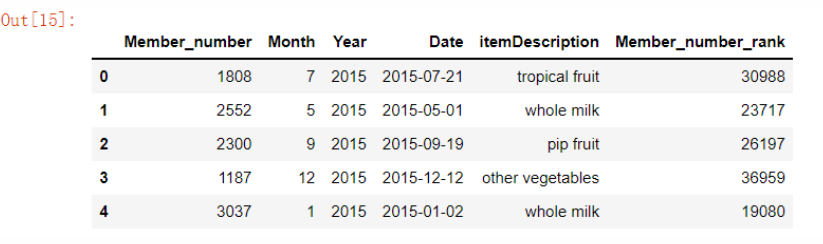
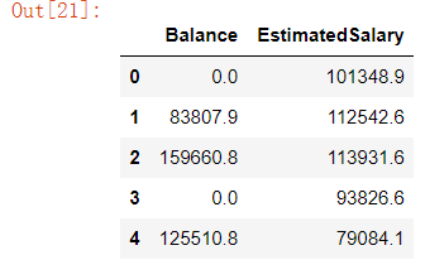
15. 展示小数点后面的几位小数
# 数据集当中对于浮点型的数字,小数点后面可能仍然会有很多的数字,我们可以通过“round”方法来进行调整,例如我们保留一位小数 df.round(1).head()
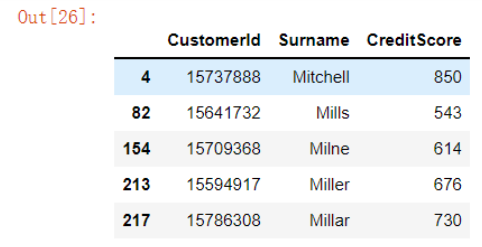
16. 基于字符串去筛选数据
# 我们有时候需要基于字符串去进行数据的筛选,例如,我们要筛选出下面的数据集当中顾客的名字是以“Mi”开头的顾客,我们可以这么来做 df[df['Surname'].str.startswith('Mi')].head()
17. 基于字符串的长度来筛选数据
# 有时候我们也可以通过字符串的长度来筛选数据,例如我们通过下面的代码筛选出“itemDescription”这个字段长度大于20的数据 groceries[groceries.itemDescription.str.len() > 20].head()
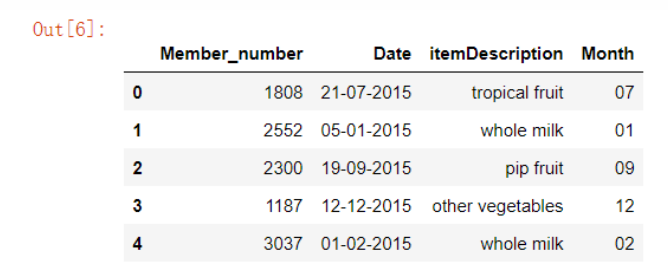
18. 对离散值类型的数据进行分离
#“Date”这一列当中的数据是字符串,然后我们可以通过“split”这个方法来进行字符串的分离,例如下面的代码将“Date”这一列当中的月份数据给分离出来了 groceries['Month'] = groceries['Date'].str.split('-', expand=True)[1]
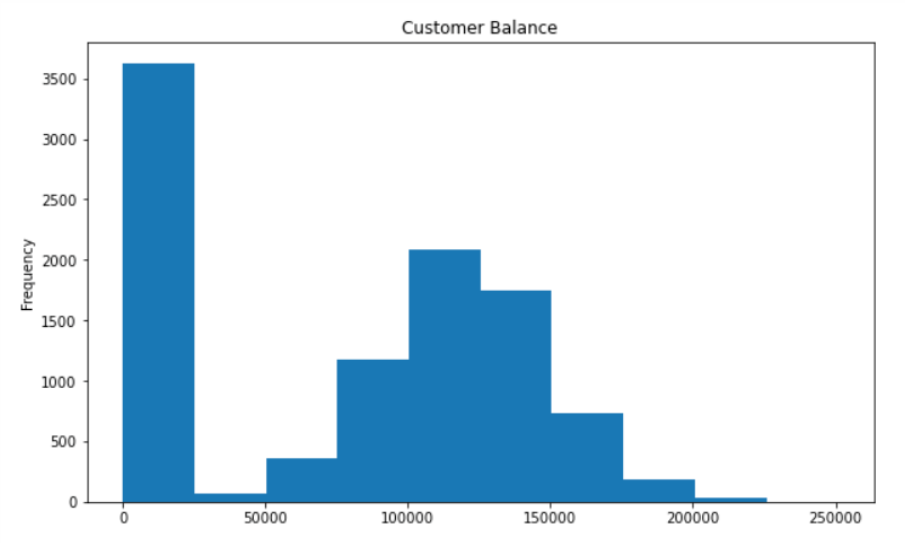
19. 画图
# 我们可以在已有数据集的基础上,通过“plot”这个方法以及里面的参数“kind”来进行可视化,例如我们想要话直方图的话 df['Balance'].plot(kind='hist', figsize=(10,6), title='Customer Balance')
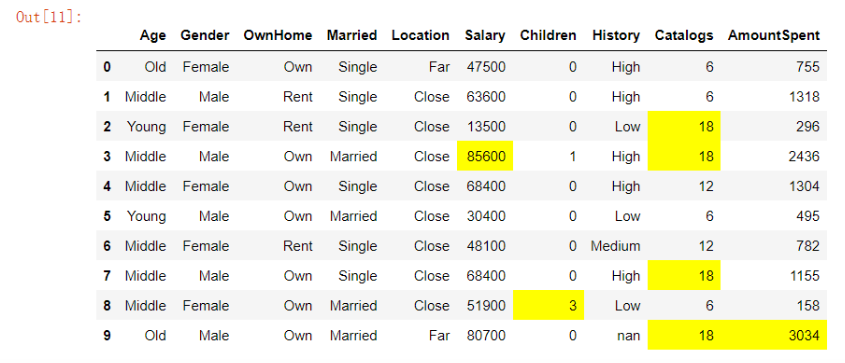
20. 标注重点
# 有时候可能需要对数据集当中某些数据打标签,表上颜色来显示其重要性,在“Pandas”模块中有“style”这个方法可以使用,例如下面的代码将“Salary”以及“Catalogs”这两列的最大值标出来了 df_new.style.highlight_max(axis = 0, color = "yellow")
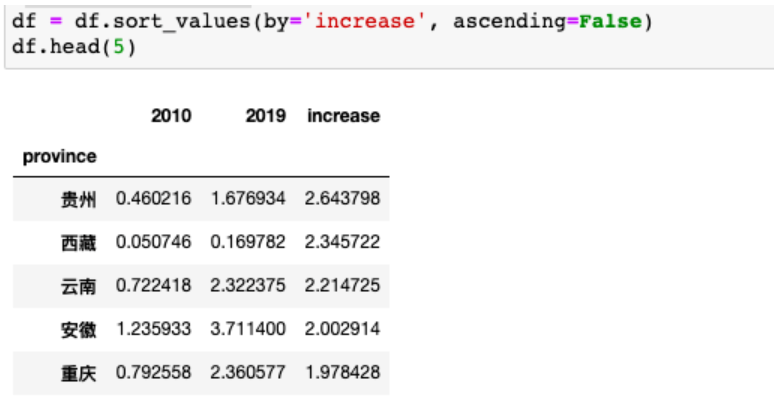
21 .根据字段排序
作者:华王
博客:https://www.cnblogs.com/huahuawang/
